4B Model Rivals 235B Performance in Mathematical Reasoning: Seed’s Latest RL Training Recipe Fully Open-Sourced
4B Model Rivals 235B Performance in Mathematical Reasoning: Seed’s Latest RL Training Recipe Fully Open-Sourced
Date
2025-07-15
Category
Seed Research
Recently, ByteDance Seed, in collaboration with the University of Hong Kong and Fudan University, unveiled POLARIS, a novel Reinforcement Learning (RL) training method. This carefully designed scaling RL method enables small models to achieve mathematical reasoning capabilities comparable to super-large models.
Experimental results demonstrate POLARIS's effectiveness: By employing model-centric data and training parameter configurations, the open-source 4B-parameter model Qwen3-4B achieved accuracies of 79.4% on AIME25 and 81.2% on AIME24, outperforming some larger closed-source models. Meanwhile, POLARIS-4B features lightweight designs, enabling deployment on consumer-grade GPUs.
The team has fully open-sourced the training methodology, data, code, and experimental models. Join us in exploring POLARIS and sharing your insights!
GitHub: https://github.com/ChenxinAn-fdu/POLARIS
Hugging Face: https://huggingface.co/POLARIS-Project
Previous RL training recipes, such as DeepScaleR, have demonstrated the powerful effects of scaling RL in weak base models. However, whether such significant improvements can be replicated on current state-of-the-art open-source models remains uncertain. The POLARIS joint research team now provides a clear affirmative answer: they can.
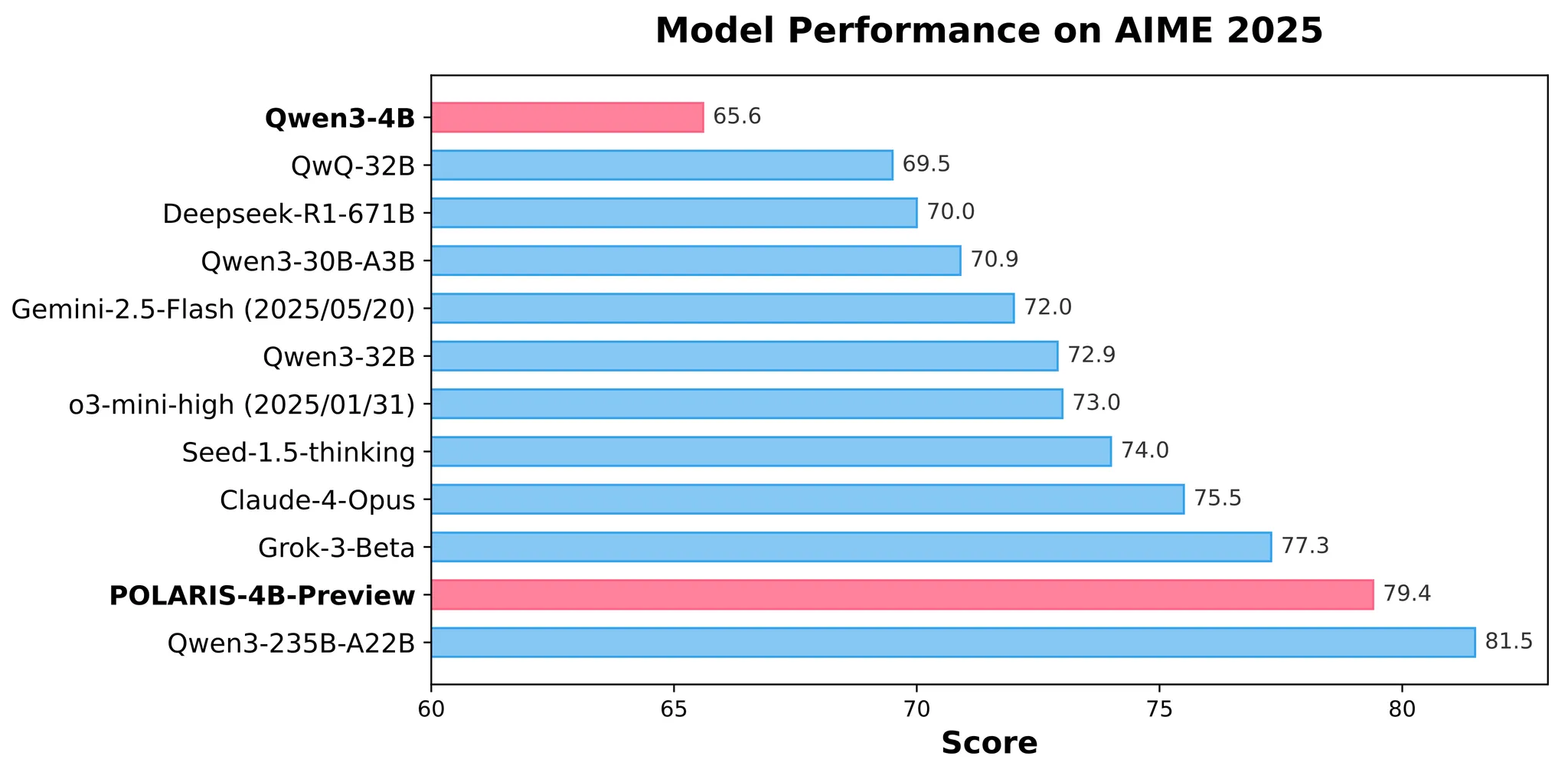
Model Performance on AIME 2025
Specifically, with just 700 steps of RL training, POLARIS enables the Qwen3-4B model to achieve mathematical reasoning performance close to that of the Qwen3-235B model. This indicates that RL training still harbors immense development potential as long as proper methods are used.
The team's key insight from their exploration is that training data and hyperparameter configurations must be tailored to the specific model being trained.
1. Dynamic Increase of Sample Difficulty During Training Data Construction
Training Data Initialization
The team discovered that foundation models of differing capabilities exhibit mirrored difficulty distributions when evaluated on the same dataset. Using the DeepScaleR-40K training dataset, the team assessed each sample by having two models—R1-Distill-Qwen-1.5B and R1-Distill-Qwen-7B—perform reasoning 8 times. The number of correct answers was counted to quantify the difficulty of each sample.
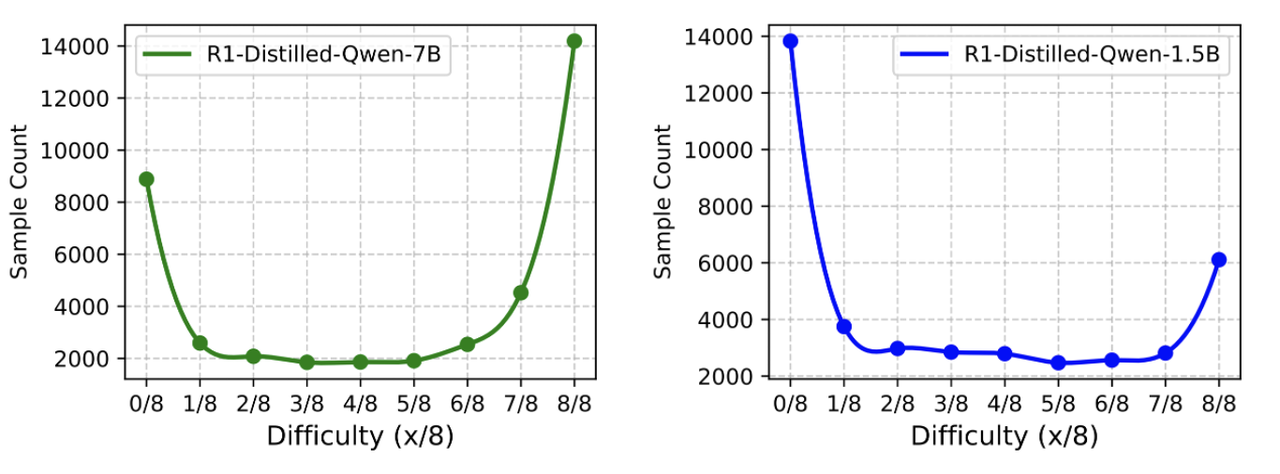
DeepScaleR-40K Data Difficulty Distribution, Estimated by DeepSeek-R1-Distill-Qwen-1.5B and DeepSeek-R1-Distill-Qwen-7B
Experiment results show that most samples are clustered at the extremes—either too hard (0/8 correct) or too easy (8/8 correct). The 1.5B model's distribution is skewed toward hard problems, whereas the 7B model's is skewed toward easy problems. This indicates that DeepScaleR-40K is challenging for the 1.5B model but insufficient for effectively training the 7B model.
In POLARIS, the team proposed constructing data with a distribution slightly skewed toward hard problems, which exhibits a mirrored J-shaped distribution. Distributions excessively skewed toward either easy or hard problems will cause batches to contain disproportionately large numbers of unproductive samples. Following this principle, the team curated the open-source datasets DeepScaleR-40K and AReaL-boba-106k, removing all samples solved perfectly (8/8 correct). This results in a final 53K-scale dataset.
Dynamic Adjustment of Training Data
Is training on this well-initialized data truly the best choice?
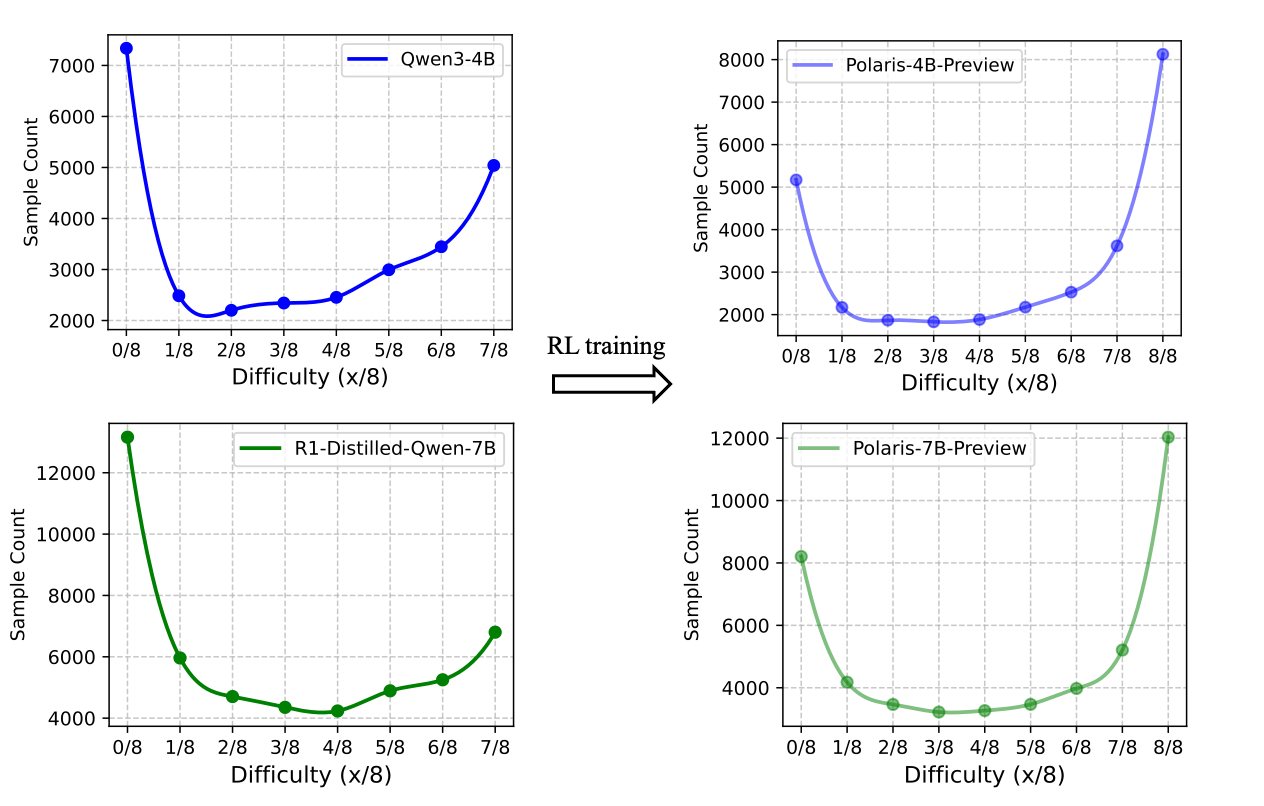
Data Difficulty Distribution Gradually Skewed Toward Easier Problems as RL Training Progressed
The answer is no. As RL training progresses, the model's "mastery rate" on training samples increases, causing hard problems to become easier. To address this, the team implemented a dynamic data update strategy. During training, each sample's pass rate is updated in real time based on reward calculations. At the end of each training stage, samples that achieve exceptionally high accuracy are removed from the training dataset.
2. Focus on Diversity Enhancement in Sampling Control
In RL training, diversity is regarded as a crucial factor for improving model performance. High diversity enables models to explore a greater variety of reasoning paths, preventing premature convergence to overly deterministic strategies in the early stages of training.
During the rollout stage, diversity is primarily regulated by topp, topk, and t (sampling temperature). Most current open-source projects use topp=1.0 and topk=-1, which yields maximum diversity, leaving only the sampling temperature adjustable.
Temperature is typically established by either following the recommended decoding temperature (e.g., Qwen3 uses t=0.6 in its demos) or simply setting it to 1.0. However, neither approach proved to be optimal in the POLARIS experiments.
Balance Between Temperature, Performance, and Diversity
Through a series of experiments, the team analyzed the relationship between sampling temperature, model performance, and rollout diversity. To quantify the diversity of the sampled trajectories, the team used the Distinct 4-gram metric to measure the proportion of unique 4-grams (contiguous sequences of 4 words) in the generated outputs. A score closer to 1.0 indicates higher diversity, while a score closer to 0 reflects greater repetition.
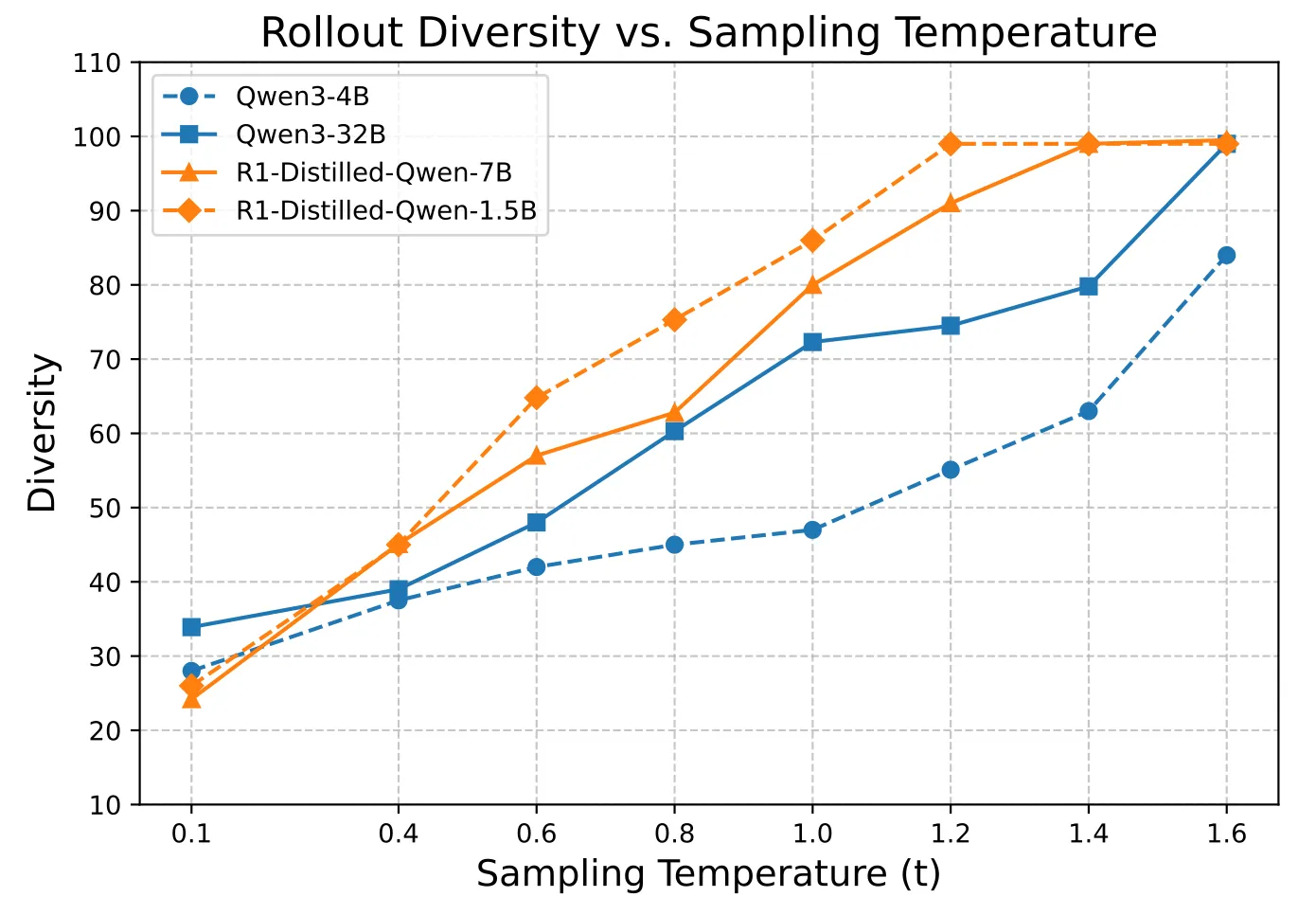
Relationship Between Rollout Diversity and Sampling Temperature
Results reveal that higher temperatures significantly enhance diversity. At the same temperature, performance varies greatly across models. As illustrated above, t=0.6 results in clearly insufficient diversity for both models.
Notably, higher temperatures are not universally beneficial, as they involve performance trade-offs.
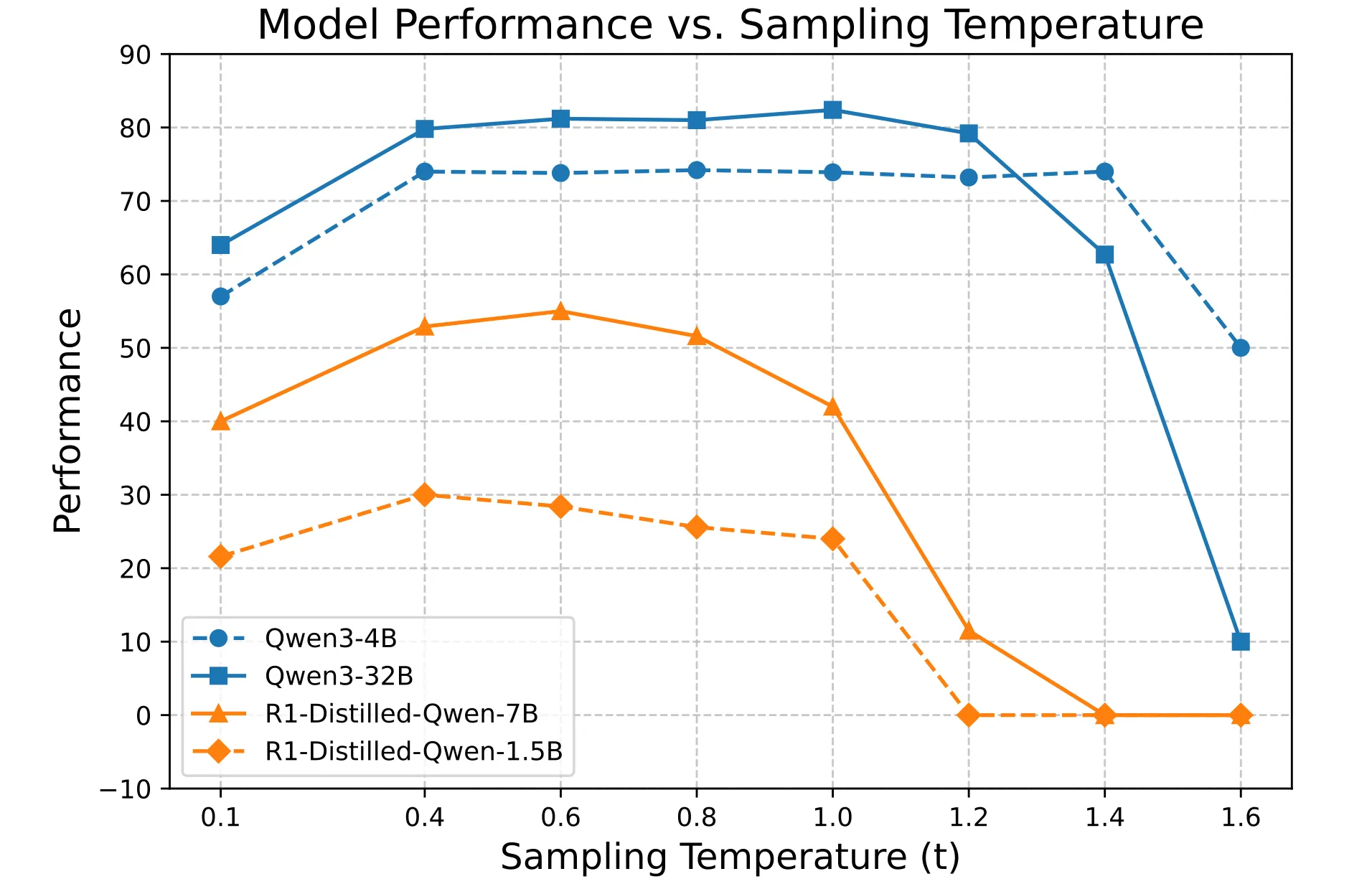
Relationship Between Model Performance and Sampling Temperature
The team observed a "low-high-low" performance trend as the temperature increased. Setting t=1.0 proved excessively high for the DeepSeek-R1-Distill models while a bit low for Qwen3 models. This indicates that the optimal temperature for achieving a desired level of diversity requires meticulous calibration specific to the target model—no one-size-fits-all hyperparameter exists.
Definition of Temperature Zones
Based on experimental trends, the team categorized model sampling temperatures into three zones:
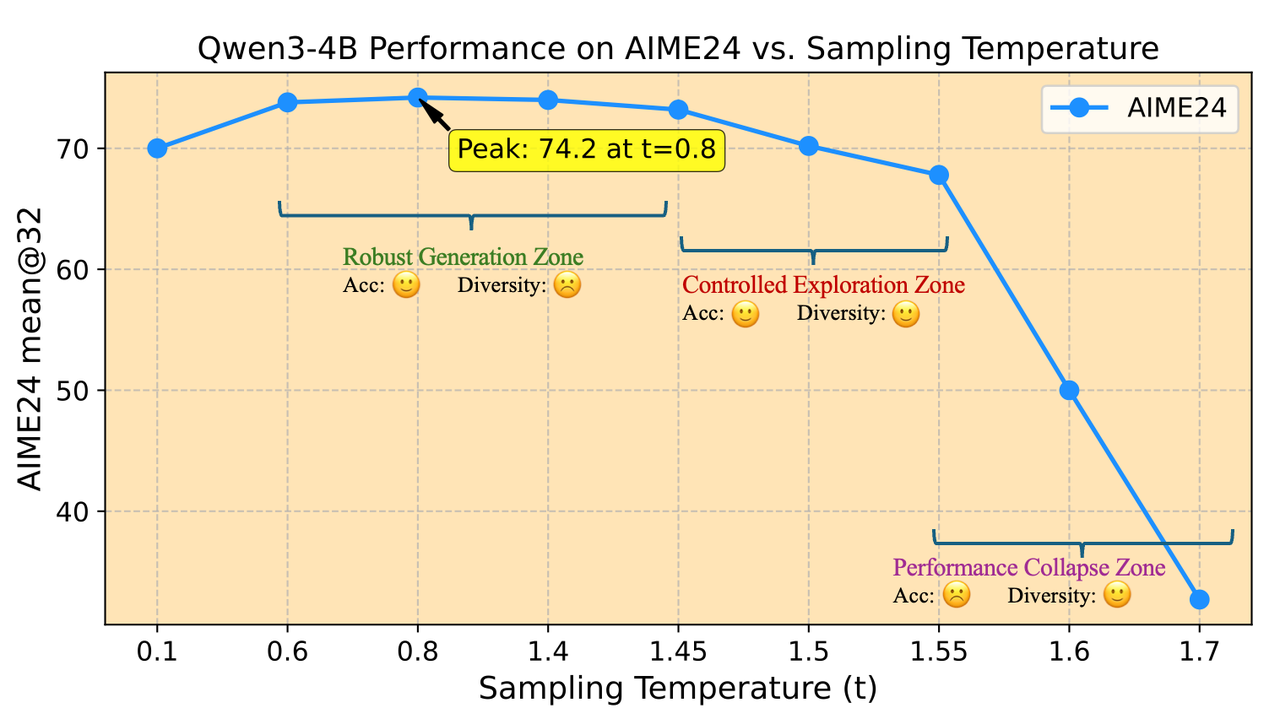
Qwen3-4B Model Performance and Sampling Temperature
- Robust Generation Zone: Within this zone, performance fluctuations are minimal. The decoding temperature for testing stages is typically selected from this zone.
- Controlled Exploration Zone: Temperatures in this region cause a slight performance drop compared to the Robust Generation Zone, but the decrease remains within an acceptable range. Importantly, these temperatures significantly boost diversity, making them suitable for training.
- Performance Collapse Zone: When the sampling temperature exceeds a certain threshold, model performance deteriorates sharply.
Temperature Initialization from the Controlled Exploration Zone
Following the pattern shown in the figure above, the team proposed initializing temperatures within the Controlled Exploration Zone in the POLARIS project. For Qwen3-4B, POLARIS sets the initial training temperature to 1.4. Experiments demonstrate that typical settings like t=0.6 and t=1.0 are too low to allow the model to explore better trajectories, thus failing to fully exploit RL potential.
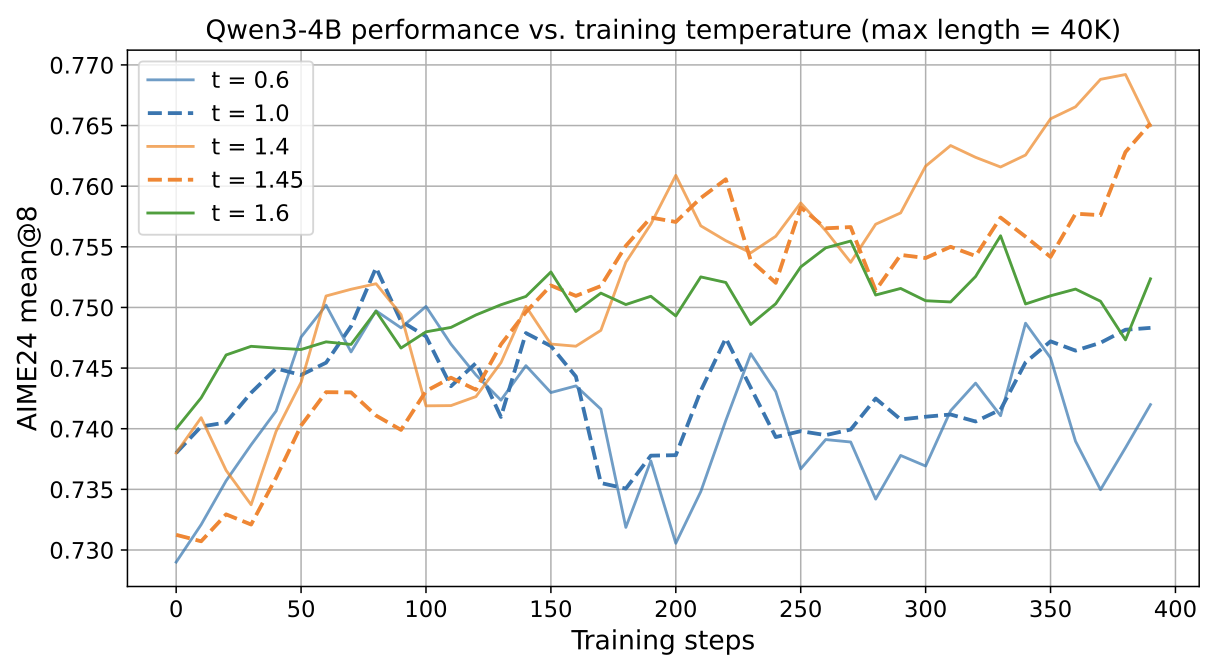
Qwen3-4B Model Performance and Training Temperature
Dynamic Temperature Adjustment
Diversity shifts alongside improvements in model performance. As the training process converges, the proportion of N-grams shared among trajectories increases, leading to a contraction of the exploration space.
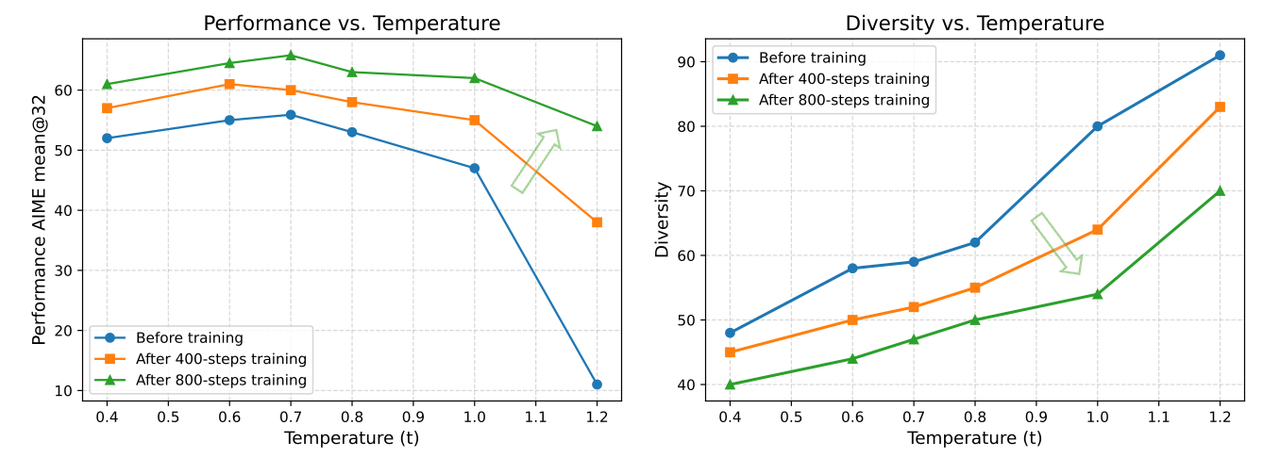
Impacts of Temperature on Model Performance and Rollout Diversity
Using the initial temperature throughout the training process can lead to insufficient diversity at later training stages. Therefore, the team proposed a strategy to dynamically update the sampling temperature during RL training. Before each stage begins, a search method similar to that used during temperature initialization is executed. This ensures that the starting diversity score of subsequent stages remains comparable to Stage 1. For example, if Stage 1 begins with a diversity score of 60, the team will select a temperature that elevates the diversity score to 60 for all subsequent stages.
Comparative experiments demonstrate that multi-stage temperature adjustment outperforms a constant temperature throughout training. This multi-stage approach not only achieves superior RL performance but also stabilizes the increase in response length.
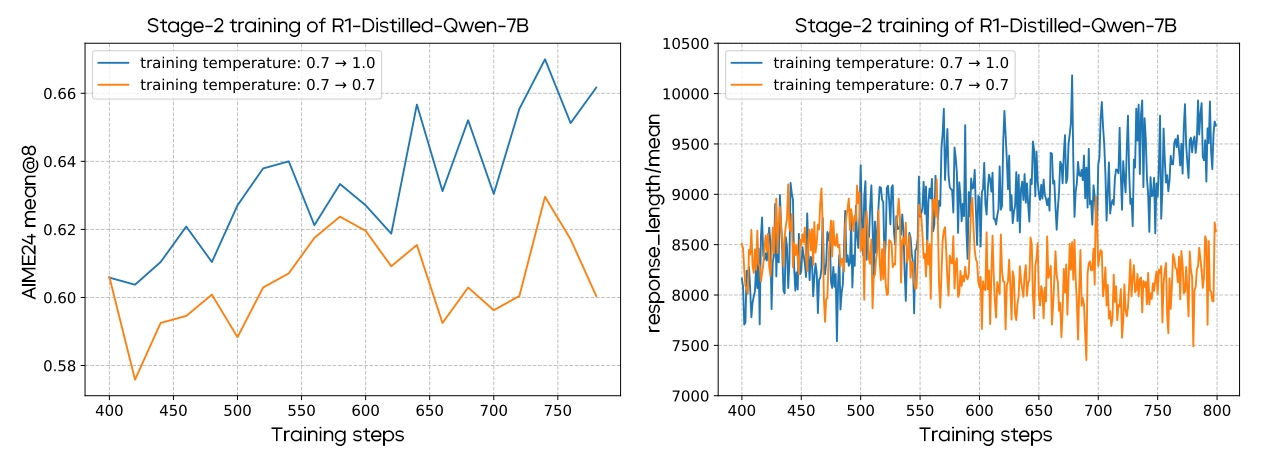
Effects of Multi-Stage Temperature Adjustment
3. Introduction of Length Extrapolation to Extend Chains of Thought in RL
Long context training is a significant challenge in Qwen3-4B training. As the model's responses are already lengthy, further training for longer outputs incurs prohibitive computational costs. While Qwen3-4B's pre-training context length is 32K, POLARIS sets the maximum training length to 52K during RL training. However, fewer than 10% of training samples actually reached this maximum sequence length, indicating severely limited long-text training exposure.
Model Performance Degrades Beyond Pre-Training Length
To evaluate POLARIS-4B-Preview's long-text generation capability, the team selected 60 problems from AIME 2024 and AIME 2025 and conducted 32 reasoning attempts per problem, totaling 1,920 samples. These samples were classified into three groups by response length:
- Short Rollouts: The response length is less than 16K.
- Mid-Length Rollouts: The response length is between 16K and 32K.
- Long Rollouts: The response length exceeds the pre-training length of 32K.
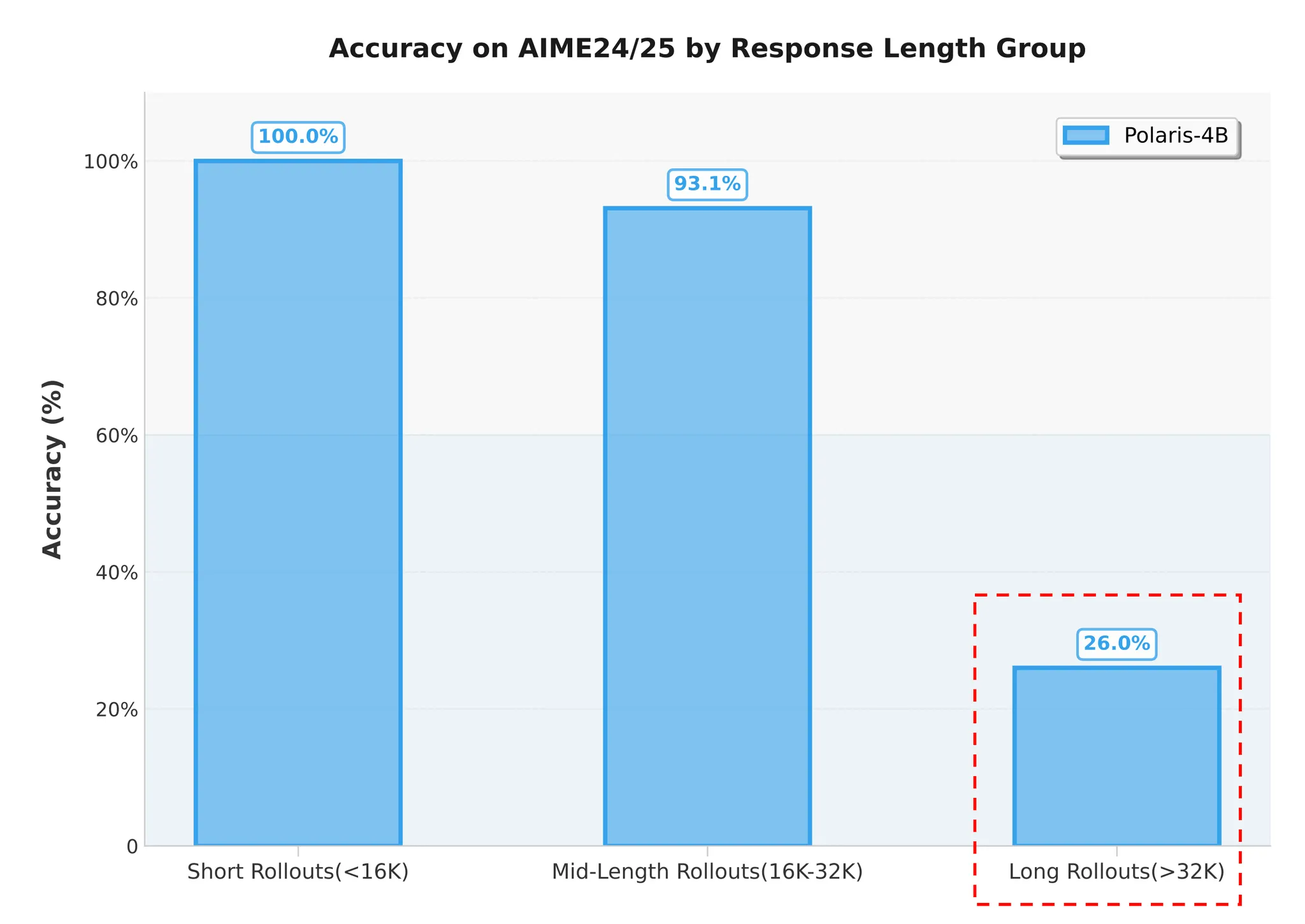
Model Accuracy by Response Length Group
Statistical results show an accuracy of only 26% in the Long Rollouts group, confirming significant performance degradation when the model generates a Chain of Thought (CoT) beyond the pre-training length.
Training-Free Length Extrapolation
Given RL's limitations in long-context scenarios, the poor performance of long CoTs likely stems from insufficient long-text training. To mitigate this data scarcity, the team introduced a length extrapolation method. By adjusting the model's Rotary Position Embedding (RoPE), this approach allows the model to sustain its reasoning performance on sequences longer than those seen in training, effectively compensating for insufficient long-context training. For practical implementation, the team used YaRN extrapolation with a scaling factor of 1.5. The configuration is as follows:
"rope_scaling": {
"attn_factor": 1.0,
"factor": 1.5,
"rope_type": "yarn"
}
Experiment results demonstrate that this strategy almost doubled the model's accuracy (from 26% to over 50%) on responses longer than 32K tokens.
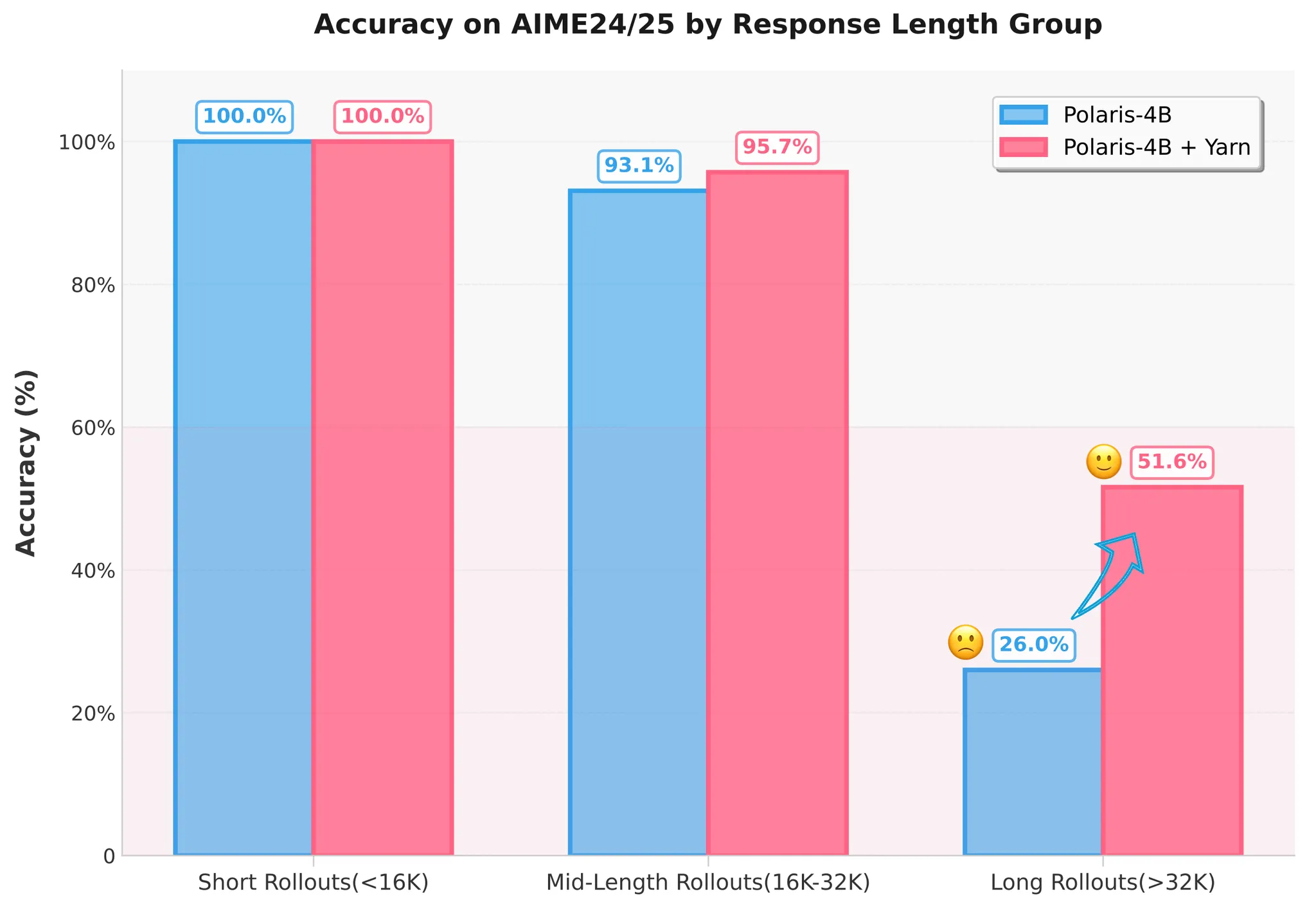
Impact of YaRN on Model Accuracy
4. Direct "Think Longer" in Multi-Stage RL Training for Greater Reliability
POLARIS employs a multi-stage training strategy. Specifically, early stages use shorter context windows. Once the model's performance converges, the context window length gradually increases to expand the model's reasoning capability.
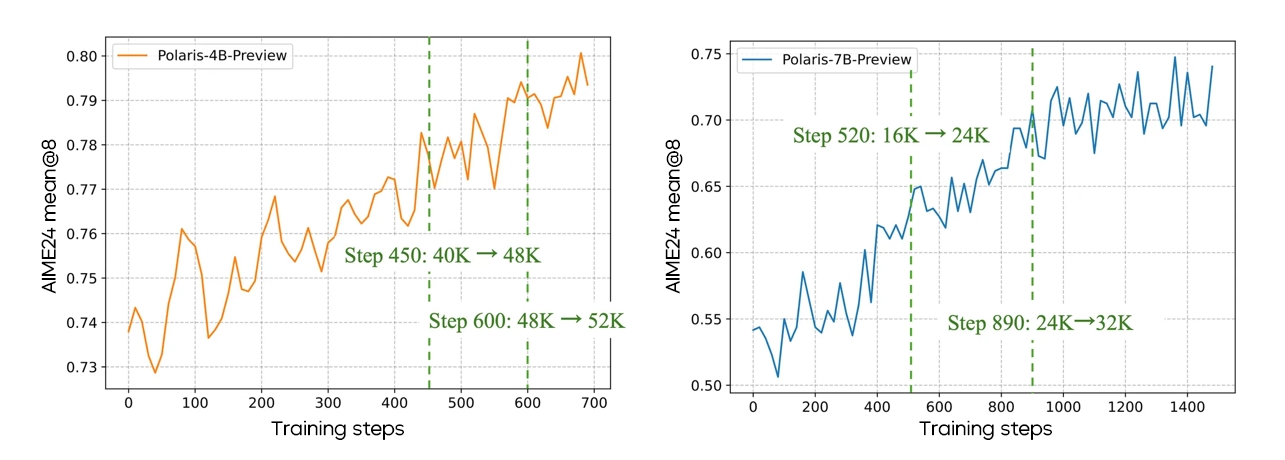
Qwen3-4B Model Trained From a Higher Benchmark Due to Its Better Performance Compared to DeepSeek-R1-Distill-Qwen-7B
“Does "Think Shorter, Then Longer" Apply to All Models??
Although this strategy is effective for some models, it is critical to select the appropriate maximum response length at the first stage in multi-stage training. The token utilization efficiency varies across foundation models. The team found that training at a small response length worked well for DeepSeek-R1-Distill-Qwen-1.5B/7B but not for Qwen3-4B. Qwen3-4B suffered sharp performance declines even at a response length of 24K and a response clip ratio lower than 15%. Such performance degradation was irreversible at later stages. Thus, direct "Think Longer" is preferable.
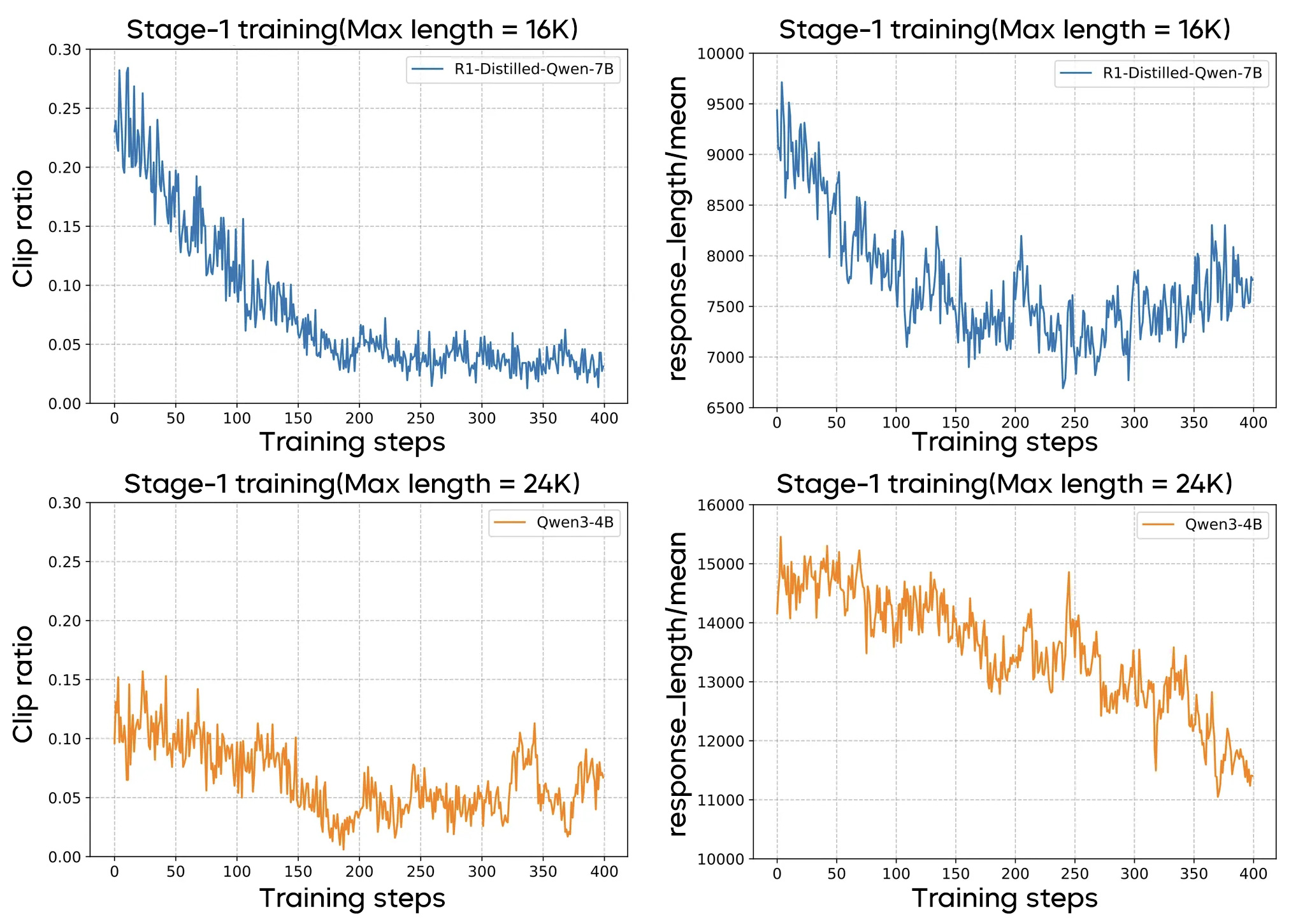
Model Performance Across Stage-1 Training Lengths
For Qwen3-4B, starting directly with the maximum length of 40K yielded stable performance improvements, whereas starting at 24K then upgrading to 40K proved suboptimal.
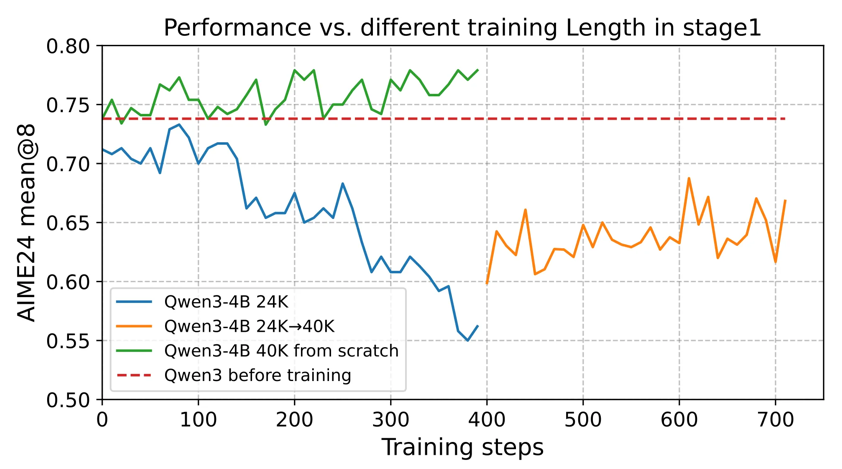
Model Performance Across Stage-1 Training Lengths
5. POLARIS Training Performance
The team trained three models with POLARIS, including Qwen3-1.7B, Deepseek-R1-Distill-Qwen-7B, and Qwen3-4B. Their algorithm performance was all verified on five mainstream reasoning benchmark datasets.
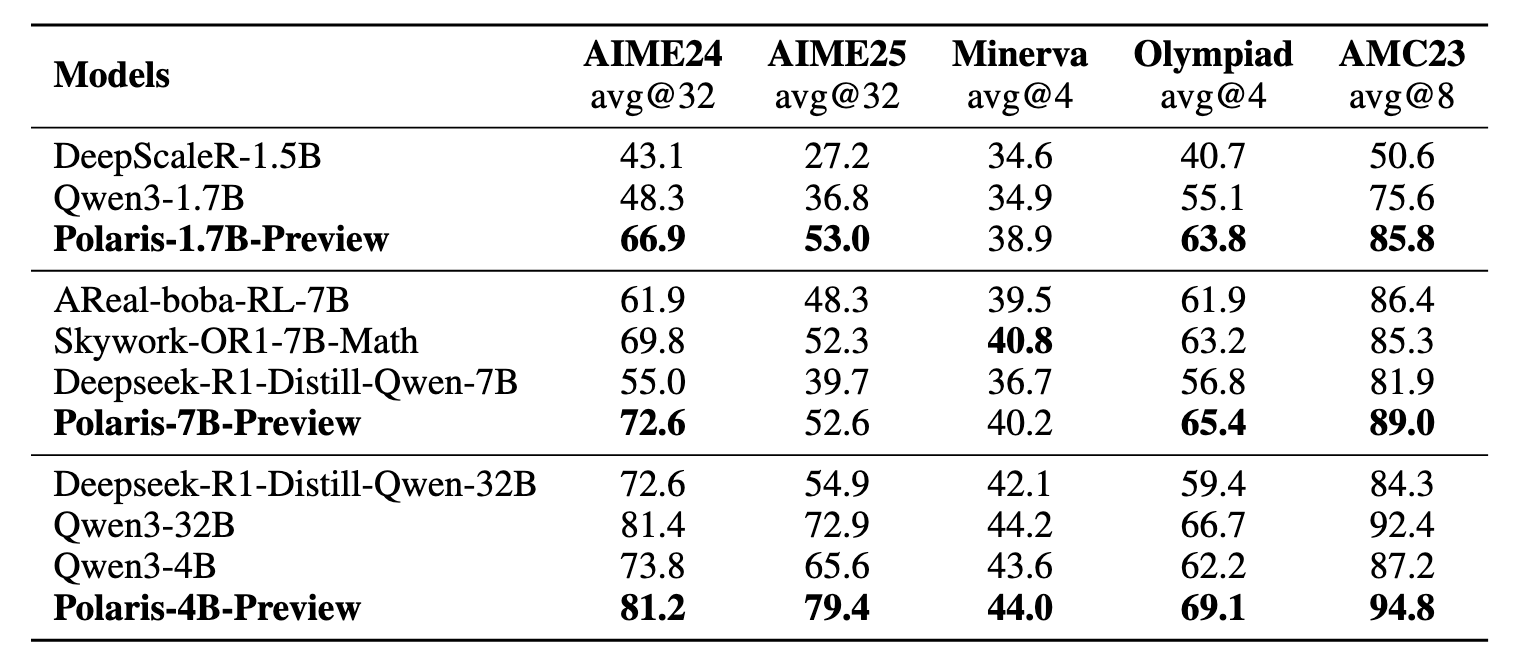
Results show significant improvements across model scales and model families after POLARIS training. Particularly on math benchmark datasets, AIME24 and AIME25, all three models achieved a score increase of over 10 points. Currently, all POLARIS training scripts have been open-sourced. For detailed training parameters, please visit the project homepage on GitHub at: