Seed-1.6-Embedding Launched: A Powerful Embedding Model Built on Seed1.6-Flash
Seed-1.6-Embedding Launched: A Powerful Embedding Model Built on Seed1.6-Flash
Date
2025-06-28
Category
Technology Launch
We launched Seed-1.6-Embedding, a powerful embedding model built on Seed1.6-Flash. It stands out with the following key features:
- Multimodal Hybrid Retrieval: Supports hybrid retrieval among text, image, and video modalities.
- SOTA Performance: Achieved a new SOTA score on the CMTEB leaderboard for plain text tasks and MMEB-V2 leaderboard for multimodal tasks.
- Flexibility: Supports multiple embedding dimensions -[2048, 1024] with minimal performance degradation at lower dimensions.
Seed1.6-Embedding's API is available on Volcengine(Model ID: doubao-embedding-vision-250615).
Model Architecture
The model architecture is based on Seed1.6-Flash, which fully preserves and enhances the model's multimodal understanding capabilities for text, images, videos, and mixed modalities. It is based on a dual-tower structure, with the embedding vector extracted corresponding to the last hidden layer vector of the [EOS] token.
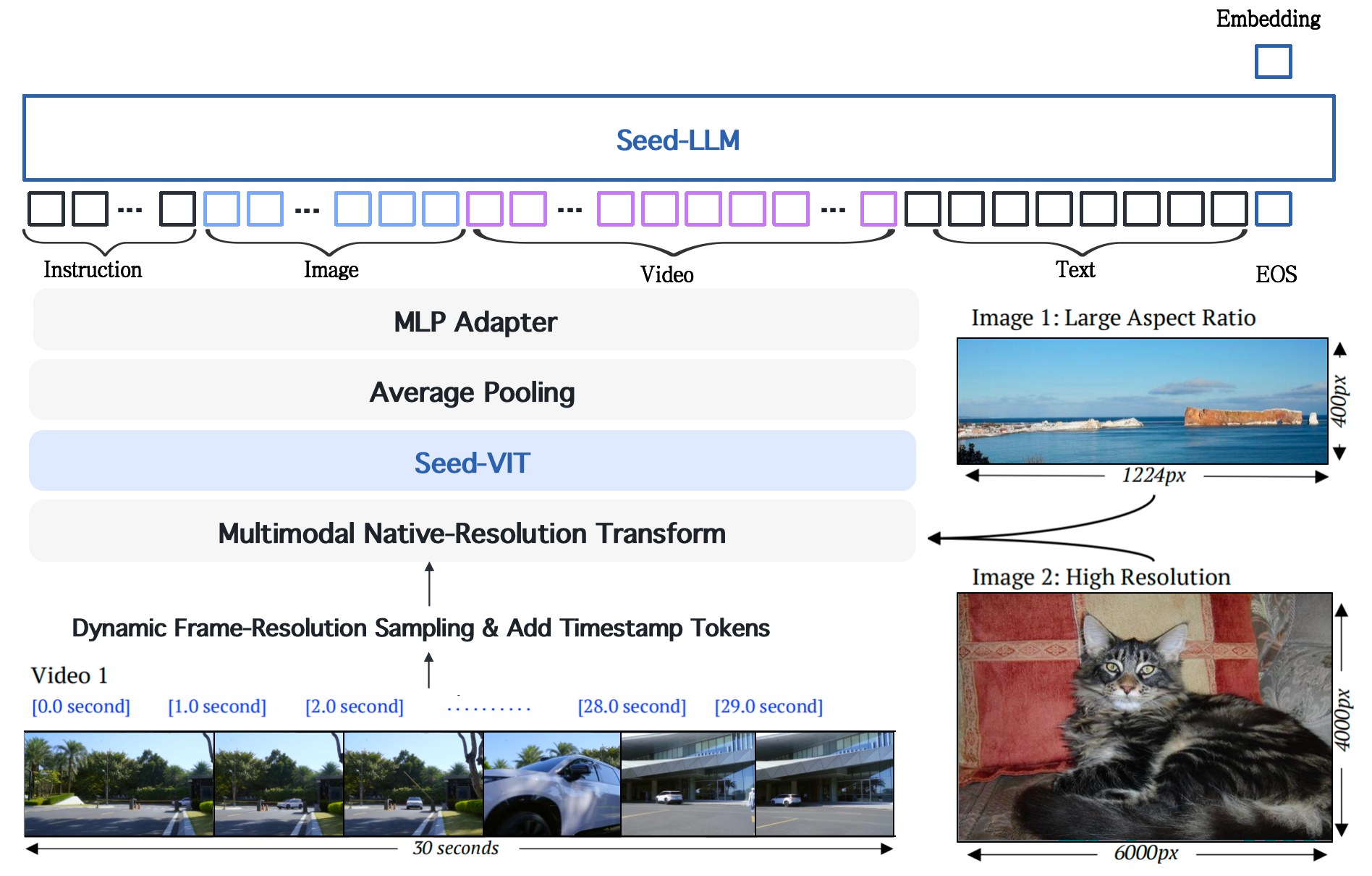
Training Method
During the construction of the embedding model, we employed a phased training strategy to progressively improve model performance and successfully developed Seed1.6-Embedding model. The entire training process consists of three core stages.
Stage1: Text Continue Training
Training Objectives: The objective of this stage is to endow the model with basic embedding capabilities, transforming the VLM model into one that possesses embedding capabilities.
Training Strategy: We utilized large-scale pure text data as training data, which includes multi-domain public data collected from the internet and some synthetic data. For public data, we designed sophisticated data cleaning algorithms and filtering rules to remove noise, duplicate content, and irrelevant information, ensuring high-quality data. Synthetic data, on the other hand, is expanded based on specific seed data using large language models, enabling the synthetic data to cover various domain knowledge and topics. During training, each sample is a text pair, and the InfoNCE loss function is used for contrastive learning.
Stage 2: Multimodal Continue Training
Training Objectives: Building on the previous stage, the objective is to add multimodal alignment capabilities for text, images, and videos.
Training Strategy: We collected a large-scale dataset of tens of millions of image-text pairs and video-text pairs for training. A portion of this raw data was sourced from the internet. To ensure data quality, we first conducted rigorous cleaning and filtering of the images, removing those that were blurry, damaged, or low-resolution. Additionally, to construct high-quality image-text pairs, we designed a data production process to obtain accurate and detailed captions from the raw images, ensuring precise semantic alignment between images and text. During training, we again employed the InfoNCE loss function, optimizing the distance between image-text pairs in the vector space to continuously enhance the model's understanding of multimodal data.
Stage 3: Fine-Tuning
Training Objectives: The objective of this stage is to comprehensively improve the model's ability to handle various niche scenarios and complex tasks by introducing data of different forms, modalities, and task types. This will enable the model to better meet the practical application requirements of information retrieval and content classification.
Training Strategy: We systematically constructed a high-quality fine-tuning dataset by focusing on three key dimensions: task type, input data modality, and task scenario. On one hand, we referenced the task types and data structures of publicly available benchmark datasets. On the other hand, we closely integrated the actual business needs and extensive experience of Volcengine to create dozens of datasets for different tasks. For each dataset, we designed specific instructions tailored to its characteristics and scenario requirements, guiding the model to learn the logic of handling specific tasks and to develop a certain level of generalization ability. For scenarios and tasks with limited training data, we applied data augmentation and synthesis techniques to expand the data scale. For more challenging tasks with poor training outcomes, we targeted the mining of negative samples at different difficulty levels to improve the model's performance in complex tasks. Finally, we conducted mixed training on all datasets, iterating through multiple rounds of optimization. This process enabled the Seed1.6-Embedding model to demonstrate strong generalization capabilities and performance across various niche scenarios.
Performance
In the authoritative leaderboards that best reflect the model's generalization ability, Seed1.6-Embedding has demonstrated significant advantages:
C-MTEB (Chinese)
*Results until June 28th
Pure Text Tasks: On the CMTEB Chinese Text Vector Evaluation leaderboard, our model has set a new SOTA with a high score of 75.62, continuing to lead in general tasks such as retrieval, classification, and semantic matching.
MMEB-V2
*Results until June 28th
Multimodal Tasks: On the MMEB_v2 multimodal evaluation leaderboard, the model has topped the SOTA in both image and video tasks, achieving a significant lead. Specifically, on the MMEB_v2 Image leaderboard, the model scored an impressive 77.78, leading the second place by 5.6 points. In the newly added video modality, the model has also achieved a substantial lead on the MMEB_v2 Video leaderboard, outperforming the second place by 20.1 points.
Usage
