Seed Research│Seed Diffusion Preview Released: A Diffusion Language Model, Achieving an Inference Speed of 2,146 Tokens/s
Seed Research│Seed Diffusion Preview Released: A Diffusion Language Model, Achieving an Inference Speed of 2,146 Tokens/s
Date
2025-07-31
Category
Seed Research

Autoregressive (AR) models are fundamentally constrained by the inherent latency of serial decoding. To address this issue, discrete diffusion models offer a potentially powerful parallel decoding solution. However, there is a significant gap between the theoretical benefits of parallel decoding and actual inference acceleration.
Today, ByteDance Seed released Seed Diffusion Preview, an experimental diffusion language model. Its objective is to systematically validate the feasibility of the discrete diffusion approach as a foundational framework for next-generation language models, using structured code generation as the experimental domain.
During this exploration, ByteDance Seed introduced two-stage diffusion training, constrained order learning, and on-policy learning for efficient parallel decoding, and validated the effectiveness of this technical approach through experiments.
The experimental results reveal that Seed Diffusion Preview can achieve a code inference speed of 2,146 tokens/s, a 5.4-fold increase in speed compared to autoregressive models of similar scale.
It not only achieves efficient sampling but also demonstrates comparable performance to autoregressive models of similar scale on multiple code generation benchmarks. In addition, in code-editing tasks that require global planning, such as CanItEdit tasks, Seed Diffusion Preview showcases inherent benefits of discrete diffusion models and outperforms autoregressive models. It unlocks new opportunities to address complex structured inference challenges.
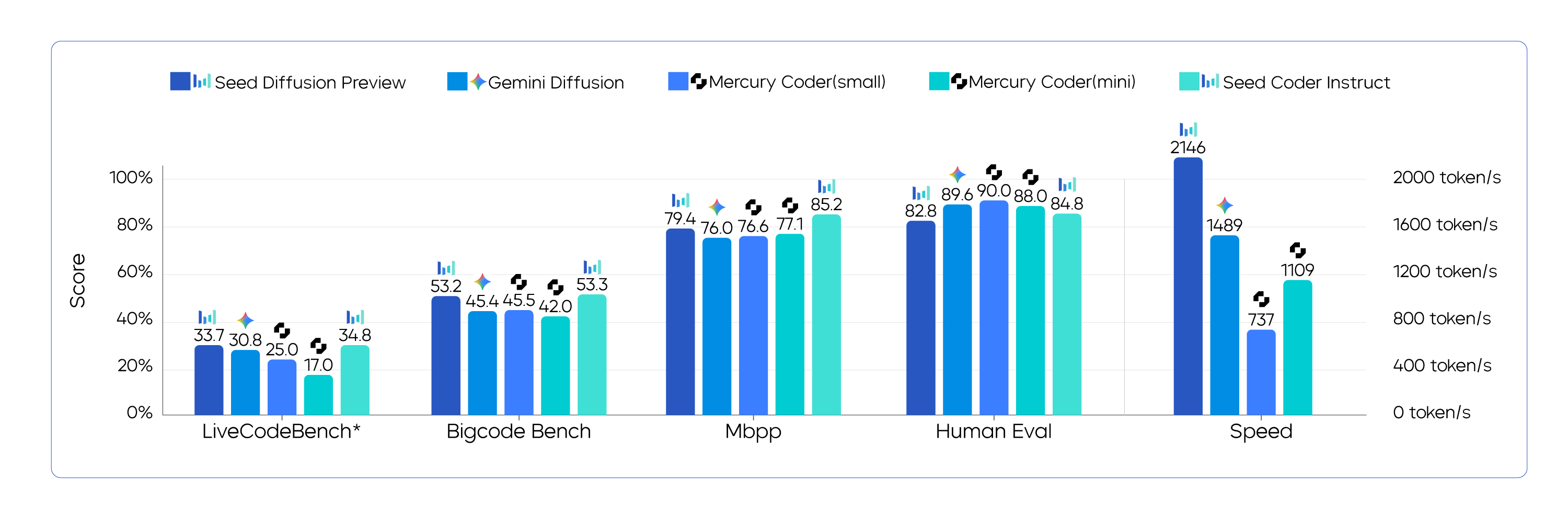
Seed Diffusion Preview Performance Evaluated on Open-Source Code Benchmarks
ArXiv:https://arxiv.org/pdf/2508.02193
Model Homepage: https://seed.bytedance.com/seed_diffusion
A New Language Model Paradigm Beyond Autoregressive Models
Diffusion models offer a coarse-to-fine generative approach, which has proven remarkably successful across a wide range of applications in continuous data domains, including image and video synthesis. The potential and features of diffusion models in parallel generation and global generation make them an ideal alternative for overcoming the limitations of autoregressive models in inference speed and global control.
However, translating the success of diffusion models to discrete domains such as natural language presents critical challenges. The primary difficulty stems from the fact that the standard diffusion process is naturally defined over continuous state spaces, thus not directly applicable to discrete domains.
To bridge the gap, two approaches are used in mainstream efforts: constructing the diffusion process in continuous latent spaces or directly defining a state transition paradigm in discrete state spaces. Recent studies reveal that the discrete state approach has great potential in scalability and effectiveness.
Despite impressive progress, large-scale deployment of discrete diffusion models for language is still hampered by two key challenges:
- Inductive bias conflict: Using discrete diffusion to generate tokens in arbitrary orders is theoretically powerful; however, natural language is overwhelmingly processed in a sequential order (such as from left to right). Consequently, a purely random-order learning signal can be inefficient, or even dampen model performance with finite compute and data budgets.
- Inference efficiency bottleneck: Although diffusion models are non-autoregressive, their iterative step-sensitive denoising procedure introduces severe latency, which undermines their major advantage over traditional autoregressive models.
To systematically address the preceding challenges, ByteDance Seed released Seed Diffusion Preview, using code generation—focused on structure and logic—as the experimental domain.
This framework achieves an inference speed of 2,146 tokens per second through model training and inference optimization. It achieves performance comparable to autoregressive models of similar scale across multiple key code benchmarks. It establishes a new technical baseline at the speed-quality Pareto frontier, demonstrating the effectiveness and feasibility of this technical approach.
Key Acceleration Methods for Diffusion Language Models
Seed Diffusion Preview adopts four key innovative technologies to improve the performance of diffusion models in data modeling, parallel decoding, and convergence.
Two-Stage Curriculum Learning: From Pattern Filling to Logical Editing
To overcome the limitations of traditional mask-based diffusion models, which only focus on masked positions and lack global correction capabilities, ByteDance Seed designed a two-stage learning strategy:
- Stage 1: Mask-based diffusion training. This stage employs a standard mask-filling task, where partial code tokens are replaced with [MASK] tokens according to a dynamic noise schedule. In this stage, the model learns to complete local context and code patterns (such as regularities, structures, and feature distributions).
This initial training stage leads to "spurious correlations", where the model learns to blindly trust that unmasked tokens are always correct. To mitigate this issue, ByteDance Seed introduced the second training stage.
- Stage 2: Edit-based diffusion training. To enable the model to evaluate the overall validity of the code, this stage introduces the diffusion process through insertion and deletion operations guided by edit distance constraints. This perturbation forces the model to re-examine and correct all tokens (including those not originally masked), thereby breaking the "spurious correlations".
Empirically, introducing this edit-based stage has boosted the model's pass@1 score on the CanItEdit benchmark by 4.8 percentage points over AR models (54.3 vs. 50.5), demonstrating a significant enhancement in its code logic comprehension and repair capabilities.
Constrained-Order Diffusion: Incorporating Structural Priors of Code
While language data (both natural language and code) is not strictly left-to-right, it contains strong causal dependencies (for example, variables must be declared before use). Unconstrained-order generation, common in mask-based diffusion models, ignores this structural prior. This often leads to limited performance under finite compute and data budgets.
To address this issue, ByteDance Seed proposed constrained-order training. In a post-training stage, ByteDance Seed uses the internal pre-trained model in a model-aware fashion to synthesize and filter a large dataset of preferred generation trajectories. The model is then fine-tuned on these trajectories through distillation, guiding the diffusion language model to learn and respect these correct dependencies.
Efficient Parallel Decoding with On-policy Learning
While discrete diffusion models theoretically offer the advantage of high-speed parallel decoding, realizing this potential in practice is challenging. A single parallel inference step is computationally expensive, and reducing the total number of steps to offset this overhead often leads to severe degradation in generation quality.
To overcome this challenge, ByteDance Seed proposed an on-policy learning paradigm. In this paradigm, the model is trained to directly accelerate its own generation process. The objective is to minimize the number of generation steps (|τ|) while ensuring high-quality final output through a verifier model (V).
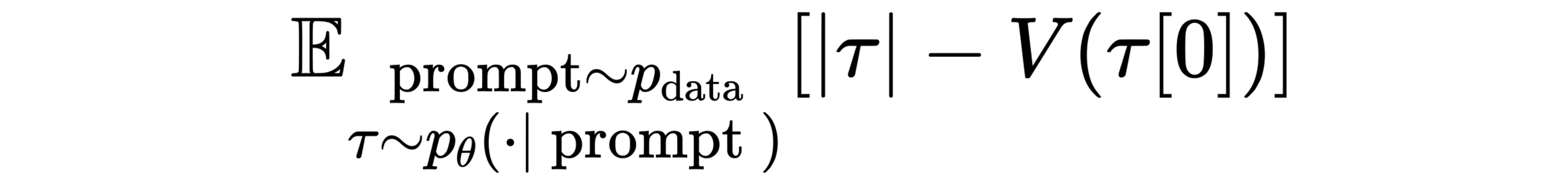
In practice, directly minimizing the number of steps was found to cause training instability. To fix this issue, ByteDance Seed adopted a more stable surrogate loss function. This loss function, based on the edit distance between different steps in a generation trajectory, encourages the model to converge more efficiently. As shown in the following figure, the training process successfully improves the model's inference speed.
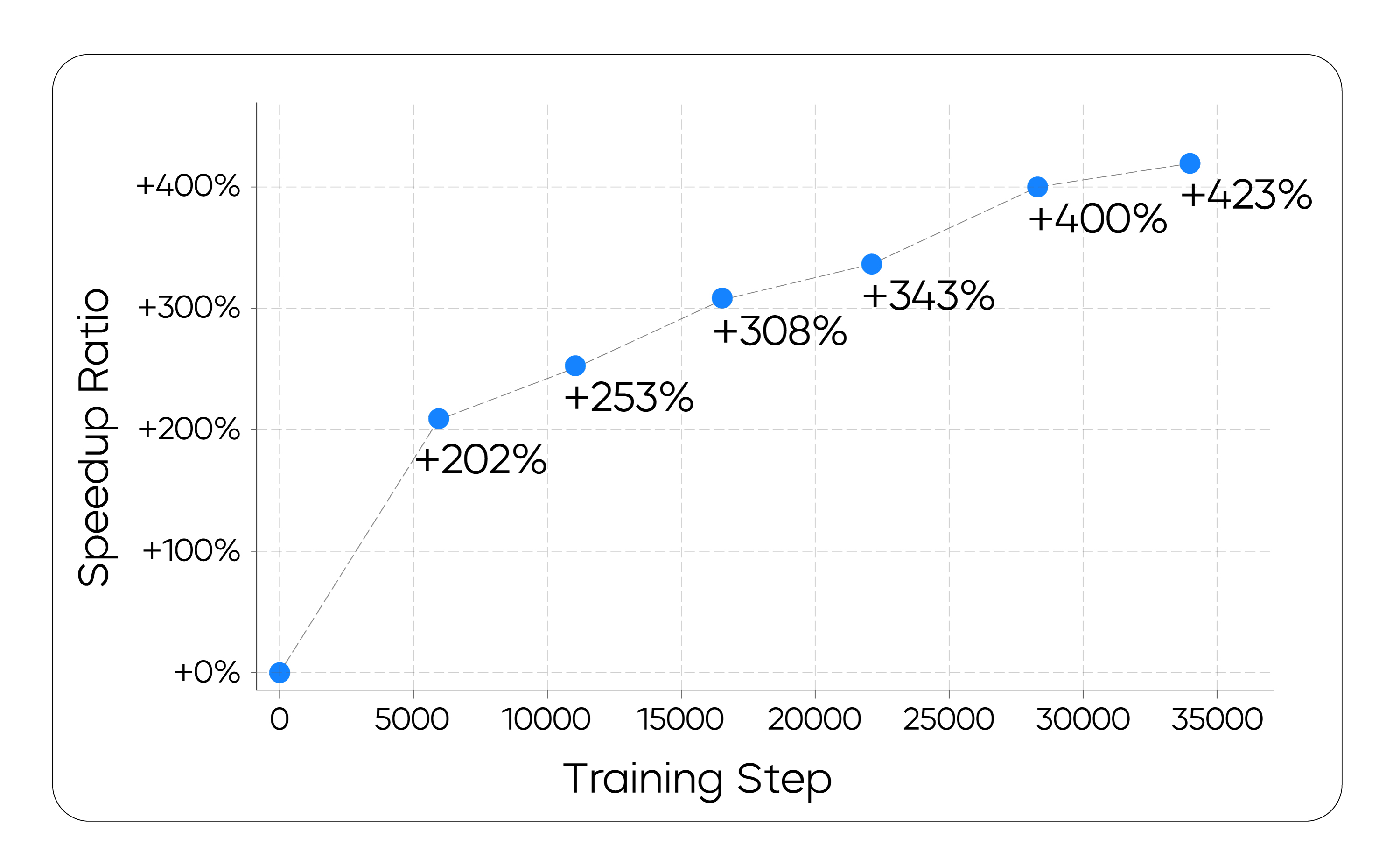
Changes in the Speedup Ratio with On-policy Training
An interesting finding is that the effect produced by this process is similar to the mode filtering technique already established in the non-autoregressive generation literature. Through training, it implicitly "prunes" low-quality or inefficient generation paths, forcing the model to learn to converge to high-quality solutions more directly and rapidly.
From Theoretical Acceleration to Engineering Implementation
To balance computation and latency, ByteDance Seed adopted a block-wise parallel diffusion sampling scheme, which maintains causal order between blocks. We avoided block-specific training to maintain the flexibility of arbitrarily partitioning blocks during inference. In addition, we employed KV-caching to reuse information from previously generated blocks and condition the generation of subsequent blocks on it.
In addition to algorithmic design, our work also includes holistic system optimizations to efficiently support block-wise inference. Specifically, we leveraged an in-house infrastructure framework that is specially optimized for diffusion sampling to accelerate generation. The impact of different block sizes on performance is displayed in the following figure. This analysis provides a basis for selecting the optimal block size.
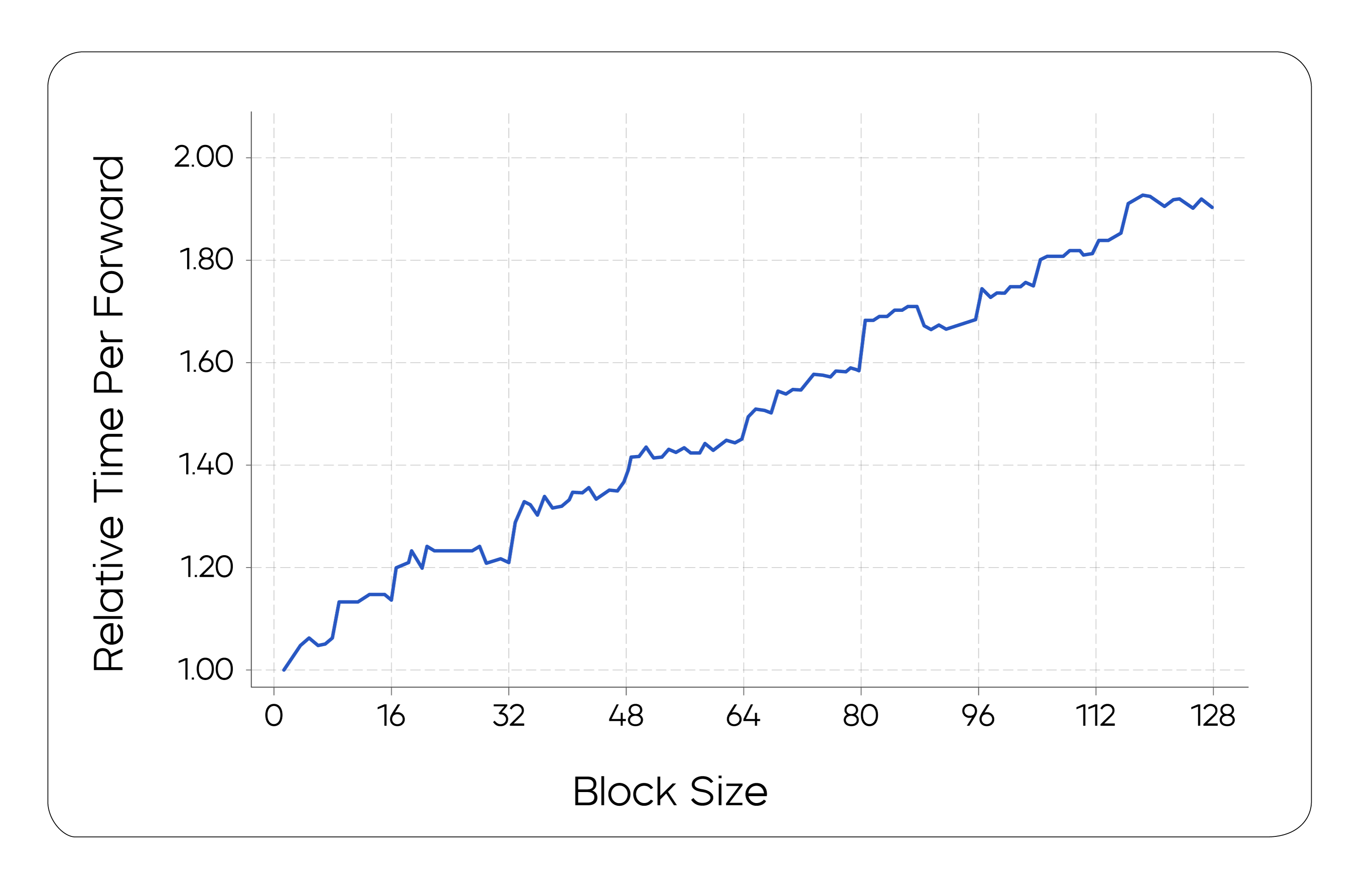
Inference time for different block sizes after optimization
Experimental Results
In generation task tests, Seed Diffusion Preview fully unleashes the parallelism potential of diffusion models, which is 5.4 times faster than autoregressive models of similar scale.
Crucially, the speed does not come at the cost of quality. On several industry benchmarks, Seed Diffusion Preview's performance is comparable to that of leading autoregressive models and even surpasses them on tasks such as code editing.
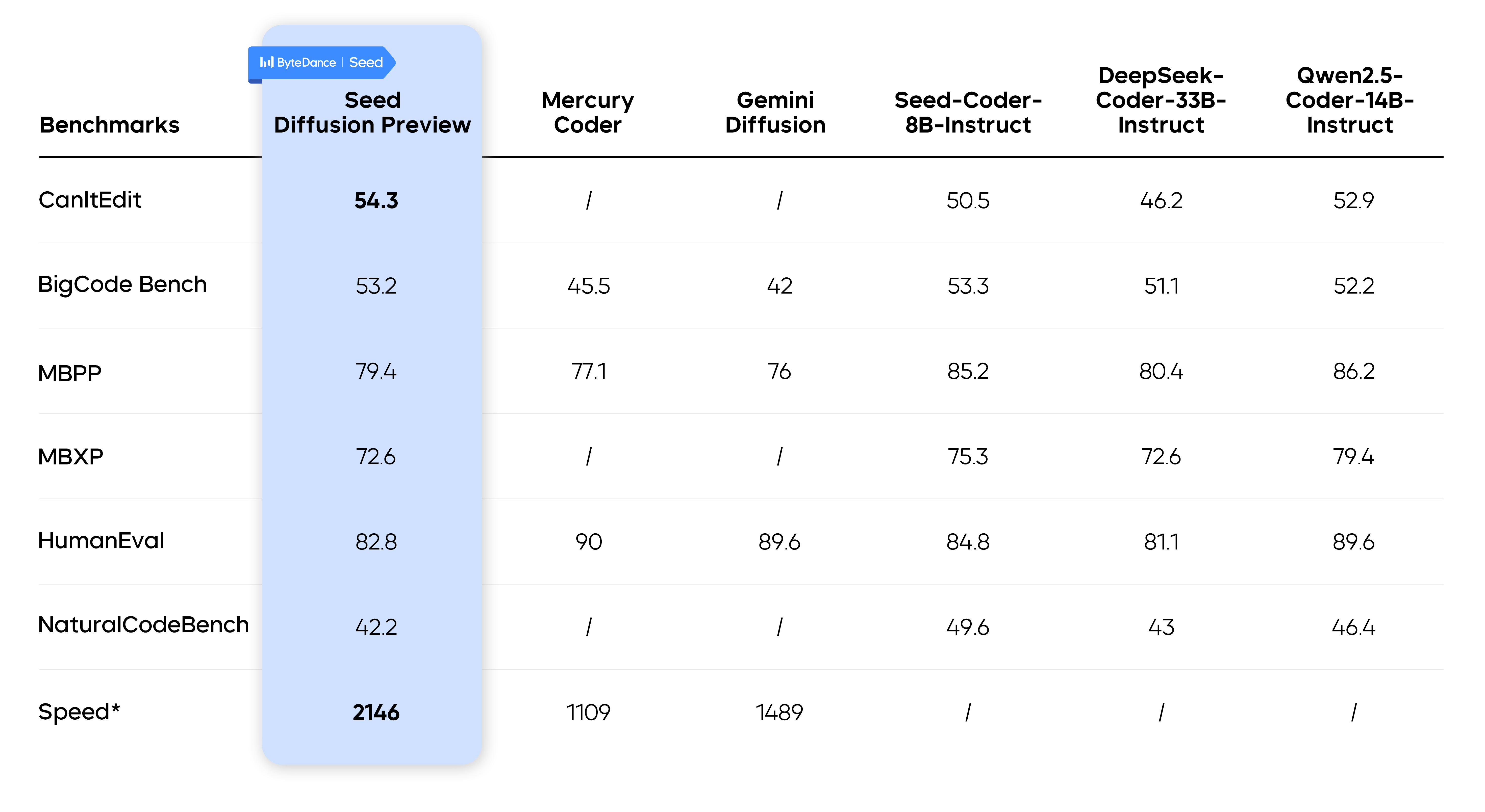
This result demonstrates that the discrete diffusion approach represented by Seed Diffusion not only has immense potential to become the foundational framework for next-generation generative models but also unlocks vast opportunities for real-world applications.
Conclusion
Seed Diffusion Preview demonstrates the huge potential of discrete diffusion models in inference acceleration for large-scale language models. However, ByteDance Seed believes that faster inference is merely the most immediate benefit of discrete diffusion. The Seed Diffusion project will continue to unlock its deeper potential, exploring its scaling patterns and applications in complex inference scenarios.
The Seed Diffusion team is currently seeking research interns and exceptional talent. If you are passionate about shaping the next paradigm of large-scale language models, we invite you to join us. Together, we'll push the boundaries of AI research.
