25 篇成果入选,字节跳动 Seed 与你共赴 ICML 2025
25 篇成果入选,字节跳动 Seed 与你共赴 ICML 2025
Date
2025-07-14
Category
Academic Collaboration and Events

ICML 2025 将于 7 月 13 日至 19 日在加拿大温哥华举行。
在本届会议中,字节跳动 Seed 团队共有 25 篇论文入选,其中包括 3 篇 Spotlight, 研究内容涵盖 LLM 推理优化、语音生成、图像生成、视频生成与世界模型、AI for Science 等多个前沿领域。本文将对其中六篇精选论文进行详细解读。
活动期间,我们将在会场展台 No.321 展示 verl、BAGEL、DPLM Family (多模态扩散蛋白质语言模型)等多项前沿技术成果。 届时,Seed 研究员们也将在现场分享交流,期待与大家共同探讨技术前沿。
Meetup
主题:verl Happy Hour @ ICML Vancouver
地点:Vancouver, British Columbia(报名成功后可获详细地址)
时间:7 月 16 日 17:00 - 22:00(GMT-7)
活动详情&报名链接:https://lu.ma/0ek2nyao (因场地有限,主办方将在活动前确认报名结果)

verl 是由字节跳动 Seed 发起的开源强化学习框架,旨在帮助从业者高效灵活地训练大模型,GitHub Star 数达到 10.6k。本次 Meetup,我们邀请强化学习、推理系统和开源 Agent 基础设施领域的优秀研究者、工程师相聚温哥华,一同交流,欢迎你的报名。
精选论文

阐释多模态蛋白质语言模型的设计空间
arXiv: https://arxiv.org/pdf/2504.11454Project
Project Page: https://bytedance.github.io/dplmExhibition
Location: West Exhibition Hall B2-B3 #W-115
本文系统地阐明了多模态蛋白语言模型在蛋白质结构建模中的挑战,并提出了解决方案以克服其局限性。
具体来说,本文发现多模态蛋白语言模型在结构建模中,主要面临以下核心瓶颈:三维结构离散化导致细节信息损失;对于多模态蛋白语言模型,离散的结构 token 不是一个最优的学习目标,以及几何关系建模缺失。
为解决以上挑战,本文以基于多模态离散扩散语言模型的 DPLM-2 为研究对象,提出的设计方法涵盖了更优的生成式建模、几何模块与表征学习,以及数据探索,有效提升了多模态蛋白语言模型的表现:
一、对于蛋白结构,本文采用更优的生成式建模方式,提升了结构预测的准确度。
- 扩散生成残差信息:弥补离散化过程的信息损失;
- 比特级结构特征建模:引入更细粒度的监督信号,降低预测难度的同时,更准确地捕捉局部结构特征关联;
- 原始坐标空间采样:直接在连续坐标空间进行原子级生成,提升结构生成精度。
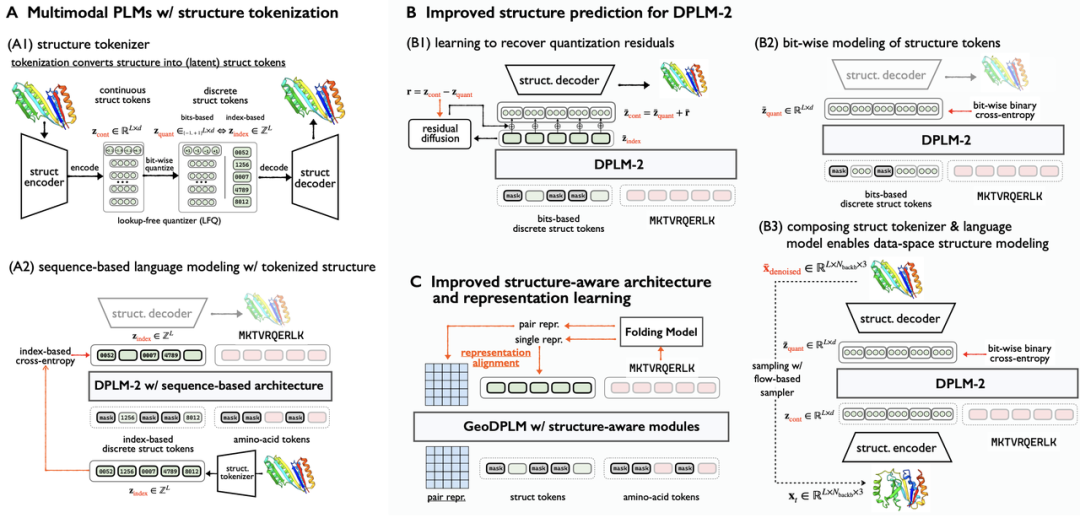
(A)基于离散结构 token 和氨基酸序列联合建模的多模态蛋白质语言模型。(B) 更优的生成式建模方式,包括残差信息的扩散生成、比特级结构特征建模以及原始坐标空间采样。(C) 改进的结构感知模型架构(引入几何模块)和包含显式结构几何信号的表示学习。
二、利用显式蛋白质结构的几何信号监督,捕捉复杂残基交互关系。通过引入几何模块架构创新和表征对齐,提升了蛋白质结构的几何关系建模能力与生成多样性
三、我们发现蛋白复合物和单体蛋白的建模密切相关,利用复合物数据可以有效提升单链和多链蛋白的结构建模效果。
实验结果显示,本文提出的技术方案显著提升了多模态蛋白语言模型的结构生成表现。
在蛋白质折叠任务中, 新方法结构预测误差指标(RMSD) 从 5.52 降低至 2.36,与专注于蛋白质结构预测的模型 ESMFold 相当,并且更加参数高效(0.65B vs 3B);在无条件蛋白质生成中, 采样多样性提升约 30%,有效解决了此前多样性不足的问题,同时维持了较高的生成样本质量。

ShadowKV:在高吞吐量长上下文 LLM 推理中隐藏的 KV 缓存
arXiv: https://arxiv.org/pdf/2410.21465
Project Page: https://github.com/ByteDance-Seed/ShadowKV
Exhibition Location: East Exhibition Hall A-B #E-2805
长上下文大型语言模型(LLM)的部署落地正变得越来越广泛,对高吞吐量推理的需求也随之增长。然而,由于 KV cache 会随着序列长度的增加而扩大,服务长上下文 LLM 时,不断增加的内存占用量和每次生成 token 均需要访问 KV cache,导致吞吐量降低。虽然一些工作已经提出了各种动态 sparse attention 方法加快推理速度,同时保持生成质量,但这些方法要么无法充分降低 GPU 内存消耗,要么通过将 KV cache offload 到 CPU ,进而带来显著的推理延迟。
本文提出一个高吞吐量的长上下文 LLM 推理系统—— ShadowKV。 ShadowKV 可以存储低秩 Key cache 并 offload Value Cache,以减少较大 batch size 和较长序列的内存占用。为了最大限度减少推理延迟,ShadowKV 采用了精确的 KV 选择策略,可即时重建最小的稀疏 KV pairs。
ShadowKV 将 KV cache offload 到 CPU,同时,在 GPU 上保留低秩 Key cache、Landmarks 和 Outliers,从而提高了长上下文 LLM 推理的吞吐量。在推理过程中,它利用 Landmarks 进行高效的 sparse attention,从而减少了计算和数据访问。
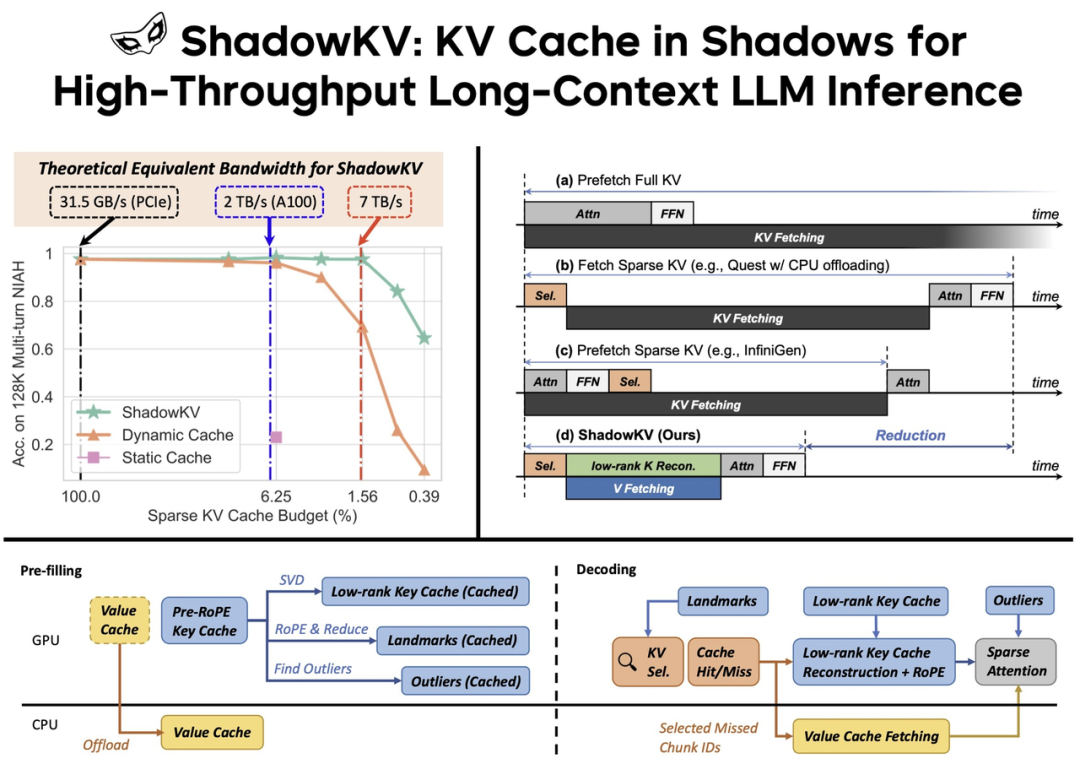
ShadowKV 有效利用有限的 KV cache 预算达到近乎无损的精度,理论上在 A100 上可获得超过 7 TB/s 的等效带宽,实测提高吞吐量 3x 以上。
本文在 RULER、LongBench、Needle In A Haystack 等大量基准测试以及 Llama-3.1-8B、Llama-3-8B-1M、GLM-4-9B-1M、Yi-9B-200K、Phi-3-Mini-128K 和 Qwen2-7B-128K 等模型上对 ShadowKV 进行评估,证明它可以支持高达 6× 的更大批处理规模,并在 A100 上将吞吐量提高 3.04×,甚至超过了在 GPU 内存无限的假设条件下,使用无限批处理量所能达到的性能。

视频生成离世界模型有多远?基于物理定律的视角
arXiv: https://arxiv.org/pdf/2411.02385
Project Page: https://phyworld.github.io/
Exhibition Location: East Exhibition Hall A-B #E-3207
在构建遵循物理规律的世界模型(World Models)的探索中,扩大视频生成模型的规模,被认为是一条有前景的技术路径。然而,这些模型是否能仅从视觉数据中自主发现并学习物理定律,其有效性存疑。一个理想的世界模型应能对细微变化保持预测鲁棒性,并在未见过的场景中,进行正确推断。
为系统性地评估这一问题,本文对模型在三种关键泛化场景下的表现,进行了研究:分布内(in-distribution)、分布外(out-of-distribution)和组合泛化(combinatorial generalization)。
团队为此开发了一个 2D 物理仿真测试平台,该平台能生成由一个或多个经典力学定律控制的物体运动与碰撞视频,旨在评估基于扩散方法的视频生成模型在预测物体运动任务中,性能的规模化效应(scaling effect)。
Phyworld 实验动画演示
实验结果揭示了模型泛化能力的显著差异:在分布内场景中,模型展现出近乎完美的泛化能力;在组合泛化场景中,其性能表现出可衡量的规模缩放效应;但在分布外的全新场景中,模型则完全失败。
团队进一步揭示了模型泛化机制的两个核心洞察:
- 模型未能抽象出通用的物理规则,而是表现出一种“基于案例”(case-based)的泛化行为,即:简单地模仿训练集中最相似的案例。
- 在为新案例匹配参考数据时,模型对不同因素的关注度存在明显的优先级:颜色 > 大小 > 速度 > 形状。
综上所述,本研究表明,仅仅依靠扩大模型规模这一策略,不足以使视频生成模型真正揭示并掌握底层的物理定律,这为构建高保真度的世界模型指出了当前方法的局限性与未来的挑战。

FlowAR:规模自回归图像生成与流匹配
arXiv: https://arxiv.org/pdf/2412.15205
Project Page: https://github.com/OliverRensu/FlowAR
Exhibition Location: East Exhibition Hall A-B #E-3109
自回归(AR)建模在自然语言处理领域取得了显著成就,通过对下一个标记的预测,模型可以生成连贯且具备上下文理解力的文本。在图像生成方面,VAR 提出了尺度自回归建模,它将对下一个标记的预测扩展到下一个尺度预测,保留了图像的二维结构。然而,本文认为 VAR 具有两大局限性:一是其复杂僵化的尺度设计限制了下一尺度预测的通用性;二是生成器依赖于具有相同复杂尺度结构的离散标记器,限制了更新标记器的模块性和灵活性。
为了解决这些局限,本文提出了对下一个尺度的通用预测方法—— FlowAR。 该方法采用精简的尺度设计,每个后续尺度都是前一尺度的两倍,无需 VAR 复杂的多尺度残差标记器,即可使用任何现成的变分自动编码器(VAE)。
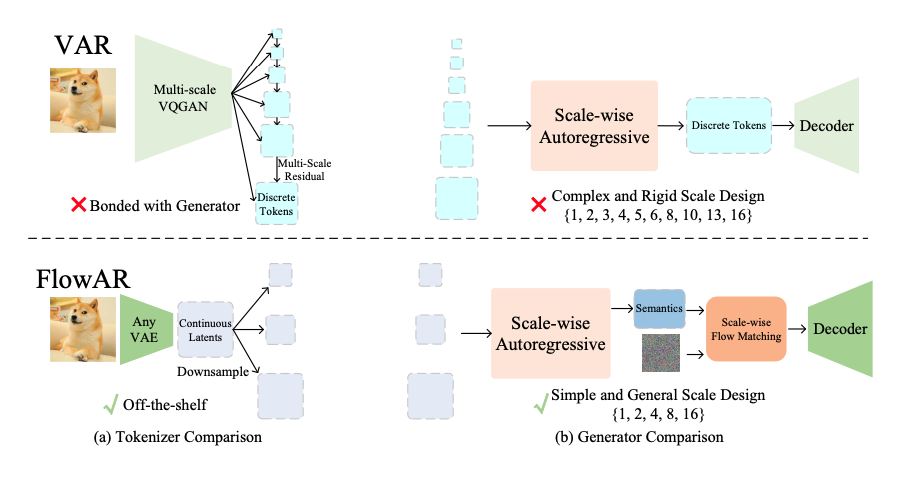
VAR 和 FlowAR 在 (a) 标记器和 (b) 发生器设计方面的比较。(a) VAR 采用复杂的多尺度残差 VQGAN 离散 Token生成器,而 FlowAR 可以利用任何现成的 VAE 连续 Token 生成器,通过直接下采样最细尺度 Token 映射,构建粗尺度的 Token 映射,提升灵活性。(b) VAR 的生成器受限于与其标记器相同的复杂而僵化的尺度设计,而 FlowAR 则受益于简单而灵活的尺度设计,并通过流匹配模型得到增强。
本文提出了一种简化设计,增强了下一尺度预测的通用性,并促进了流匹配的整合,从而更好实现高质量的图像合成。在 ImageNet-256 基准测试中,团队验证了 FlowAR 的有效性,证明其生成性能优于以前方法。

一步式视频生成的扩散对抗后训练
arXiv: https://arxiv.org/pdf/2501.08316
Project Page: https://seaweed-apt.com/
Exhibition Location: East Exhibition Hall A-B #E-3206
扩散模型被广泛应用于图像和视频生成,但其生成过程需要多步神经网络计算,非常耗时。APT1 模型研究首次实现了仅需一步的文生视频,支持 2 秒 1280x720 24fps 高分辨率高帧率视频生成,并且在 8xH100 上达到实时生成效果。此外,该模型还能在单一步骤中生成 1024px 图像,其质量可媲美业内先进方法。

本图对比了不同模型 1 步和 25 步生成图像的结果。在图像细节方面,APT1 更胜一筹,结构完整性也位居前列。
本文提出在预训练扩散模型上进行对抗后训练(Adversarial Post-Training) 实现了一步生成。为了提高训练的稳定性和质量,本文对模型架构和训练程序进行多项改进,并引入了近似 R1 正则化目标。这些改进让超大 Transformer 对抗训练成为可能,首次实现了 16B 规模的对抗训练。团队同时观察到,目前一步生成过程仍有折损并解析了根本原因,并将在之后工作中,继续提高模型性能。实时视频生成将开启更多应用场景,是未来技术发展的重点方向。APT 系列工作专注于实时图片视频生成的基础研究,欢迎前往主页了解。
实时视频生成将开启更多应用场景,是未来技术发展的重点方向。APT 系列工作专注于实时图片视频生成的基础研究,欢迎前往主页了解。

DiTAR:用于语音生成的扩散 Transformer 自回归建模
arXiv: https://arxiv.org/pdf/2502.03930
Project Page: https://spicyresearch.github.io/ditar/
Exhibition Location: East Exhibition Hall A-B #E-3211
过往研究试图结合扩散和自回归模型,在没有离散语音标记的情况下,实现自回归生成连续的语音表示,但这些研究结果往往不理想或计算量过大。本文提出了扩散 Transformer 自回归建模方法 DiTAR。这是一个基于分片的自回归框架,并结合了语言模型和扩散 Transformer。
本文提出了扩散 Transformer 自回归建模方法 DiTAR。 这是一个基于分片的自回归框架,并结合了语言模型和扩散 Transformer。
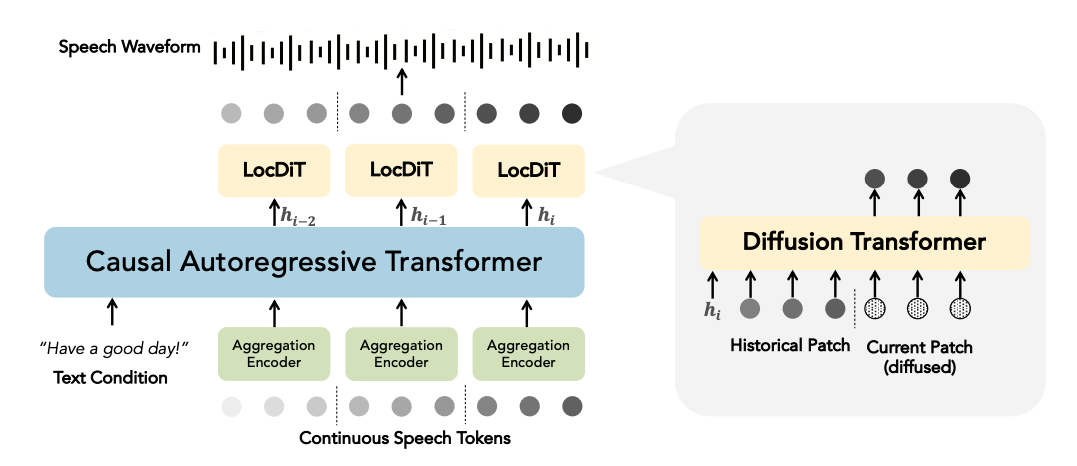
DiTAR 由一个用于输入的聚合编码器、一个因果语言模型骨干和一个用于预测局部词块的扩散解码器 LocDiT 组成。
这种方法大大提高了基于连续表征的自回归模型表现,并降低了计算需求。DiTAR 采用分而治之的分片生成策略,将连续表征以分片的形式输入聚合编码器,得到聚合后的特征,再由语言模型进行特征处理,扩散 Transformer 会根据语言模型输出,生成下一个分片。在推理方面,本文提出将温度定义为在反向扩散常微分方程(ODE)中引入噪声的时间点,从而平衡多样性和确定性。
团队将 DiTAR 应用在音色克隆任务中,模型在鲁棒性、说话人相似性和自然度方面均达到了 SOTA 水平。另外,本文通过大量的实验表明,DiTAR 具有很好的可扩展性。