ByteDance's Seed1.5-Embedding Model Achieves SOTA in Retrieval: Training Details Unveiled
ByteDance's Seed1.5-Embedding Model Achieves SOTA in Retrieval: Training Details Unveiled
Date
2025-05-12
Category
Models
The ByteDance Seed team has unveiled the technical details of its latest embedding model, Seed1.5-Embedding, trained based on Seed1.5 (Doubao-1.5-pro). On the Massive Text Embedding Benchmark (MTEB), an authoritative leaderboard for evaluating embedding models, Seed1.5-Embedding has achieved state-of-the-art (SOTA) performance in both Chinese and English tasks. In addition to general-purpose embedding tasks, the team has optimized the model's capabilities in reasoning-intensive retrieval tasks, achieving SOTA performance on the BRIGHT leaderboard as well.
The team believes that Seed1.5-Embedding can serve as a key component in search tasks, efficiently and accurately converting user input texts and document information into vectors for precise matching. The API for this model now is available on the Volcano Ark platform. Stay tuned for updates.
Project Homepage (With API trial access inside): https://seed1-5-embedding.github.io/
An embedding model encodes the semantic meaning of input texts into high-dimensional representation vectors, ensuring higher vector similarity for semantically relevant texts. This capability can support downstream tasks such as retrieval, classification, and clustering, making it widely applicable in scenarios such as search, recommendation, and content understanding.
With the rapid growth of large model technologies, embedding models are now shifting their foundation from Bidirectional Encoder Representations from Transformers (BERT) to large models, gaining stronger encoding capabilities through a scale-up of parameters. Meanwhile, as a critical component of Retrieval-Augmented Generation (RAG) mechanisms, embedding models enable large models to generate reliable responses informed by external knowledge, further highlighting their significance.
Recently, the ByteDance Seed team released its latest embedding model, Seed1.5-Embedding.
Seed1.5-Embedding has introduced iterative optimizations in the following three key aspects:
- Designed a two-stage contrastive learning training pipeline with meticulously constructed training data to enhance the model's general representation capability.
- Constructed reasoning-intensive retrieval data (requiring deep understanding of query-document matching relationships beyond simple lexical or semantic matching) from pre-training and post-training corpora, and used it to optimize the model.
- Adopted a Mixture-of-Experts (MoE) model with a small number of activated parameters as the foundation, and supported multiple embedding dimensions through Matryoshka Representation Learning (MRL) training, thus achieving high speed and flexible storage overheads.
MTEB is now the most widely recognized general-purpose leaderboard for evaluating embedding models across diverse languages (Chinese, English, etc.) and tasks (retrieval, clustering, classification, etc.). Tech companies like Google and NVIDIA have benchmarked their models on MTEB. BRIGHT is another leaderboard that has gained significant attention from the community for its focus on evaluating the reasoning-intensive retrieval capabilities of embedding models. Its tasks are specifically designed to evaluate how well embedding models understand and reason over the relationships between queries and documents.
Seed1.5-Embedding has achieved SOTA performance in both Chinese and English tasks on the MTEB and BRIGHT leaderboards, outperforming its competing models such as Gemini-Embedding (Google), NV-Embed (NVIDIA), GTE, and Conan.
The specific performance metrics are as follows:
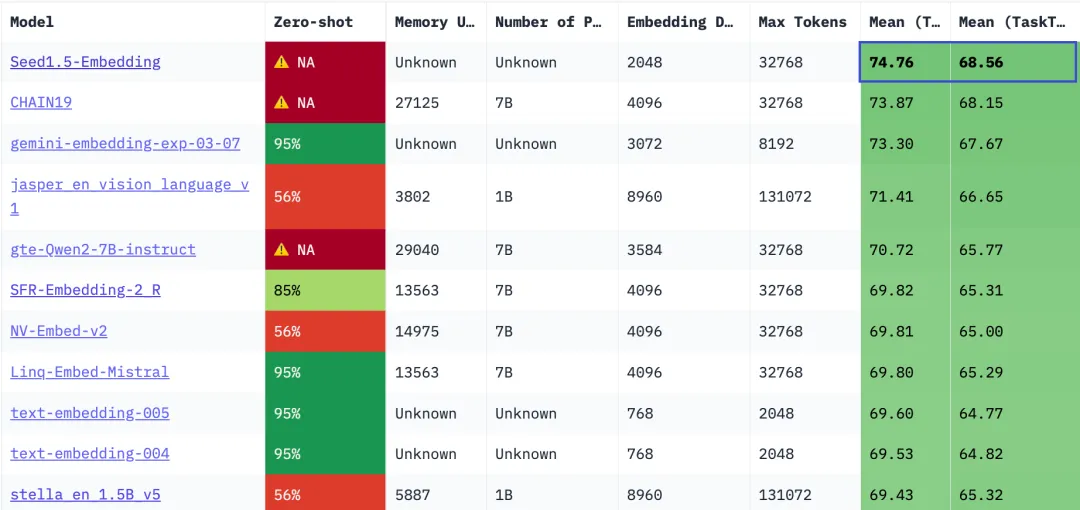
MTEB_v2 (English; general-purpose tasks) leaderboard
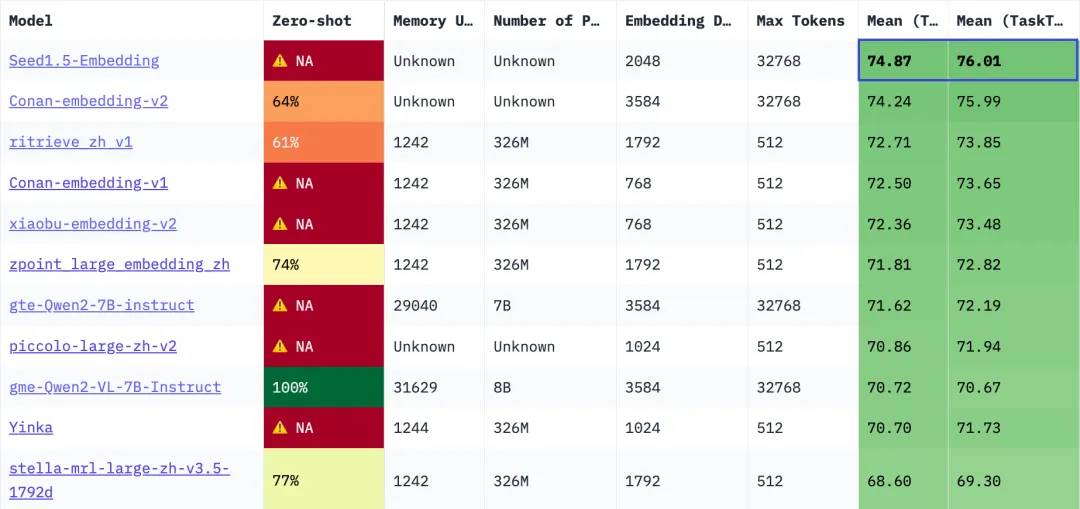
CMTEB (Chinese; general-purpose tasks) leaderboard
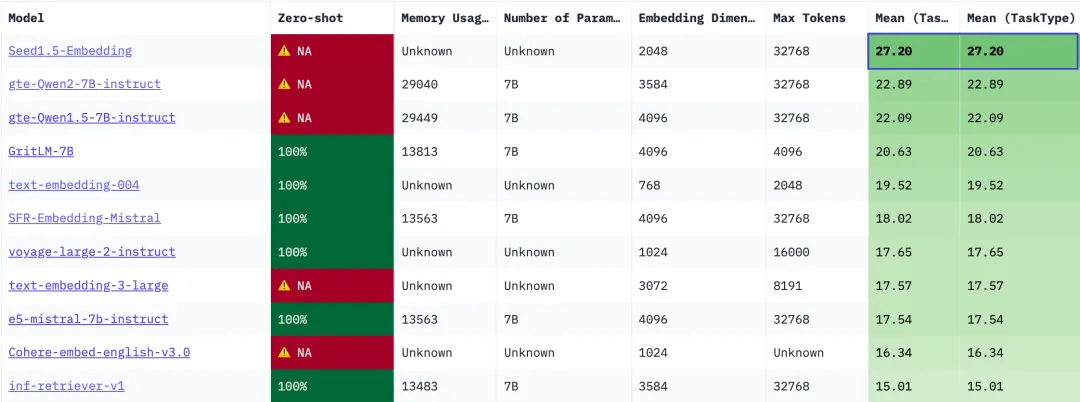
BRIGHT (English; reasoning-intensive retrieval) leaderboard
1. MoE-based Embedding Model: Empower AI to "Understand" Search Intent and Reuse Text Features
As large models are reshaping traditional search, advertising, and recommendation technologies, embedding models are also pushed to tackle more demanding challenges:
(1) Embedding models must provide powerful general-purpose capabilities to accurately model the deep semantic meanings of texts, thereby pulling in the most suitable external knowledge for large models.
(2) Real-world searches often require deep understanding of queries and documents. To address this challenge, embedding models must go beyond semantic modeling and enhance reasoning capabilities to capture and model complex matching relationships.
(3) Embedding models must ensure high speed and storage efficiency to support real-world applications across various downstream tasks.
To tackle these challenges, the team introduced a series of optimizations to the embedding model across design, training, and data engineering:
As for the model architecture, the team employed a Siamese two-tower model architecture, taking the average of all token representations as the final text vector. The matching scores between queries and documents are calculated via cosine similarity. Built upon the Seed1.5 pre-trained large language model (LLM), the model shifts from unidirectional attention to bidirectional attention and implements a small-scale MoE model. Additionally, model parameters are shared between the query tower and the document tower, ensuring high speed.
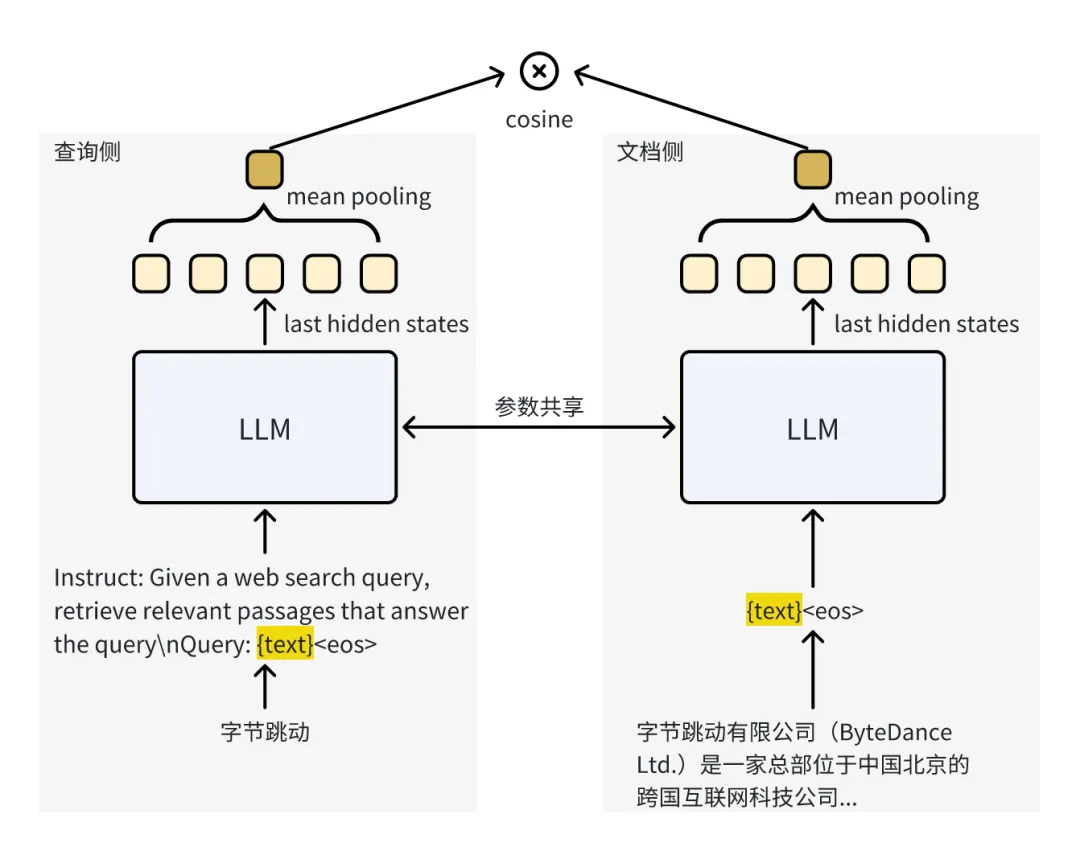
In real-world applications, the query tower in the embedding model converts user inputs into vectors to help AI understand the query intent. The team tailored prompts for different tasks to guide the model in learning appropriate matching patterns. For the document tower, no prompts were used, allowing document vectors to be reusable across multiple tasks.
2. Two-stage Training: Progressively Refine the Model's General Representation Capability and Support Different Embedding Dimensions
Pre-trained large models are designed for generative tasks, aiming to predict the next token based on hidden states. In contrast, embedding models focus on representation tasks, aiming to calculate similarity based on hidden states. To adapt a large model into an embedding model, the team employed a two-stage training approach to progressively develop the model's general representation capability.
- Stage 1: Let the Model Effectively Represent Different Text Matching Patterns
We performed pre-finetuning using unsupervised data. By applying contrastive learning through vast amounts of data, we adapted a unidirectional attention-based generative model into a bidirectional attention-based encoder model, enabling the model to effectively represent various text matching patterns.
The data consists of (query text, relevant text) pairs, including webpage title-paragraph pairs, QA platform question-answer pairs, and paper title-abstract pairs. We used the standard InfoNCE loss function:
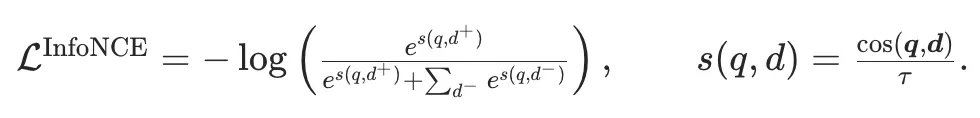
Where, d+∈P(q)d^+\in\mathcal{P}(q)d+∈P(q) is a positive document, d−∈N(q)d^-\in\mathcal{N}(q)d−∈N(q) is a negative document; q,d\boldsymbol{q},\boldsymbol{d}q,d represent the query vector and document vector, respectively, and τ\tauτ is the temperature coefficient. During the first stage of training, we only used in-batch negatives (texts corresponding to other queries in the same batch).
- Stage 2: Let the Model Learn Optimal Representation Patterns for Different Tasks
We performed fine-tuning using supervised data and synthetic data, mixing data from retrieval and other tasks for multi-task optimization. This helps the model autonomously learn how to best represent information for each task.
Given that Sentence Text Similarity (STS) tasks aim to measure how semantically similar two sentences are by learning and fitting Ground-Truth scores, while InfoNCE can only work with binary (1-0) labels, the team used CoSENT loss for STS tasks and InfoNCE loss for other tasks.
Notably, the team also introduced hard negatives (texts that are semantically similar to the query but not exact matches) during this stage. To enhance the model's discrimination capability, both in-batch negatives and hard negatives were used for retrieval tasks and only hard negatives were used for other tasks.
To accommodate different embedding dimensions (M = {256, 512, 1024, 2048}) in downstream tasks, the team balanced performance and storage overheads by adopting MRL to optimize both InfoNCE loss and CoSENT loss. This approach nests multiple low-dimensional vectors within a single high-dimensional vector, reducing the vector size while ensuring performance. The specific implementation is as follows:
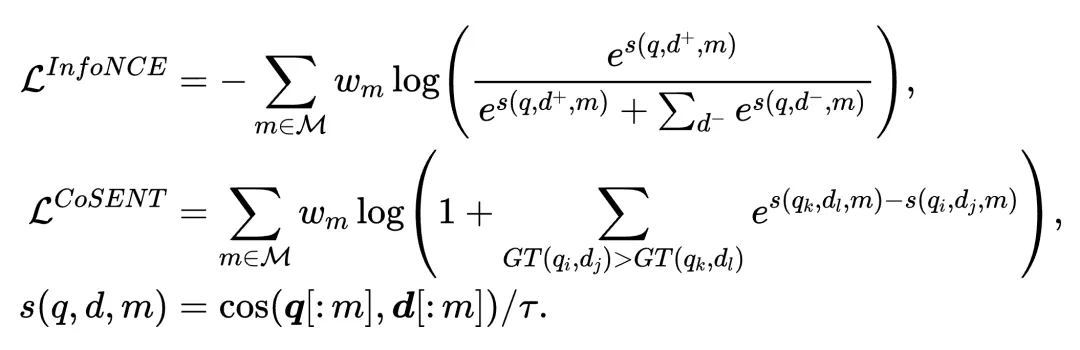
3. Optimize Data Composition and Quality to Boost Retrieval Task Performance
Retrieval is the most critical and challenging application scenario for embedding models. In such tasks, the embedding model must accurately represent the semantic meaning of text to identify relevant information from massive documents. To improve the model's learning performance in retrieval scenarios, the team designed three data engineering strategies to optimize data composition and quality.
- Negative Mining
Hard negatives—texts that are semantically similar to the query but not exact matches—are crucial for enhancing the performance of the embedding model. They can help the model learn to discriminate fine-grained relevance. However, hard negatives mined using open-source models in most practices often fail to align well with the preferences of the target model to be trained.
To address this issue, the team developed an iterative hard negative mining strategy: mining hard negatives based on the preferences of the target model to select more "tricky" challenging samples for training, thereby optimizing its capabilities.
- False Negative Filtering
InfoNCE is a loss function used in contrastive learning, designed to minimize the distance between query vectors and positives while maximizing the distance to negatives. Therefore, the quality of negatives is crucial for learning performance. However, during training, unannotated positives in corpora may be mistakenly treated as negatives (false negatives). Such data can confuse the learning signals of the model, leading to degraded performance.
Specifically, during the second stage of training, negatives for retrieval tasks include both hard negatives sourced from mining and in-batch negatives. Among them, the hard negatives may include excessively challenging false negatives. Additionally, for in-batch negatives, since queries are randomly sampled to form a batch, texts corresponding to different queries in the same batch may also become false negatives when the corpus is small or the query distribution is highly skewed.
To address these two issues, the team implemented a mechanism to automatically filter out texts that are excessively similar to positives when mining hard negatives and calculating the in-batch negative loss, thereby mitigating the impact of false negatives on learning.
- Synthetic Data
In real-world applications, matching patterns vary across retrieval scenarios. This requires embedding models to go beyond semantic matching and use reasoning to understand complex queries and texts, thereby modeling deep matching relationships. To meet this requirement, the team separately constructed data for general-purpose scenarios and reasoning-intensive scenarios.
For general-purpose scenarios: The team first prompted the Seed1.5 model to generate diverse queries based on documents in corpora and retained only highly relevant query-document pairs. For the retained query-document pairs, the team applied the previously mentioned hard negative mining method to extract hard negatives.
For reasoning-intensive scenarios: Given the limited availability of documents and queries, the team started by collecting a large set of challenging queries without standard reference answers. The team mined candidate documents from the corpora, and then used LLMs to select positives and hard negatives, ultimately obtaining training data tailored for reasoning-intensive retrieval scenarios.
4. Achieving SOTA Performance in General-Purpose and Reasoning-Retrieval Capabilities across Chinese and English Tasks
The test results show that Seed1.5-Embedding outperforms industry-leading embedding models such as Gemini-Embedding and Conan-Embedding-v2 on the MTEB leaderboard in both Chinese and English tasks, demonstrating its general-purpose capabilities.
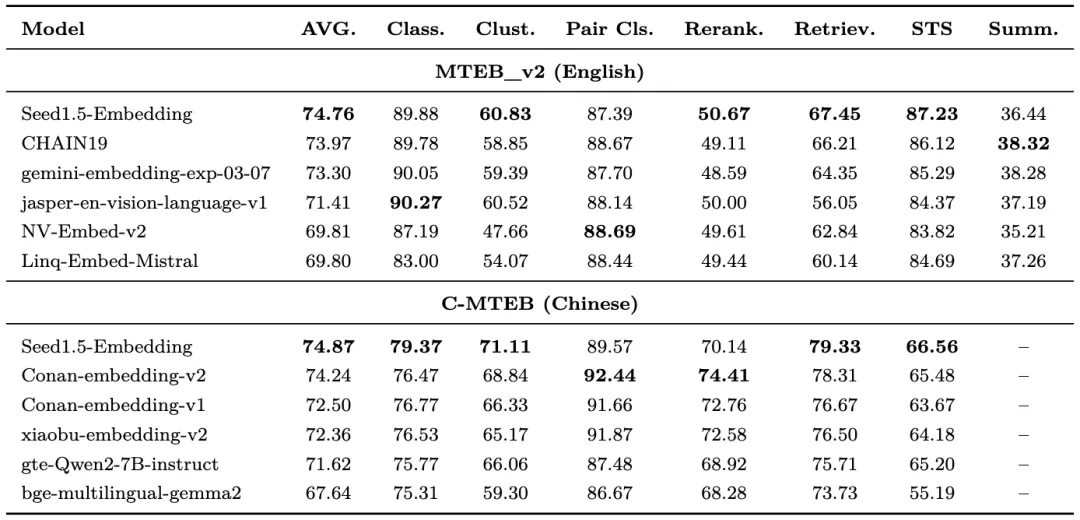
AVG represents the average performance score across all tasks, with results sourced from the MTEB leaderboard
In addition to general-purpose tasks, Seed1.5-Embedding also surpasses its competing models in reasoning-intensive retrieval tasks on the BRIGHT leaderboard. Notably, it achieves substantial leads over existing models in complex searches based on StackExchange in fields such as Biology, Earth Science, and Coding. This demonstrates its capability to deeply understand query and document inputs and effectively model complex matching relationships between them.
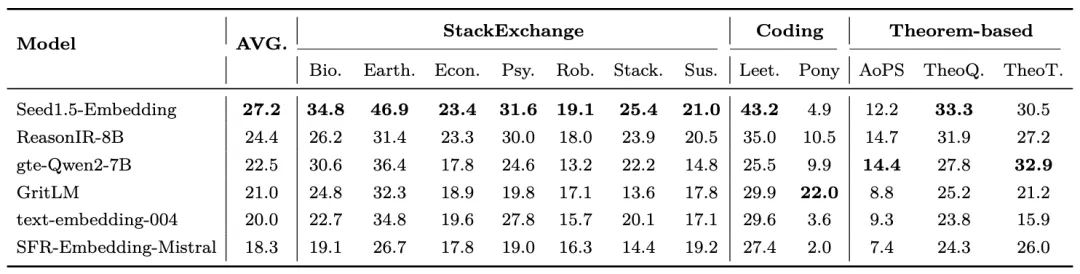
The performance of benchmark models is sourced from papers BRIGHT: A Realistic and Challenging Benchmark for Reasoning-Intensive Retrieval and ReasonIR: Training Retrievers for Reasoning Task .
Finally, we conducted an ablation study on the most critical task—retrieval—to analyze the impact of different techniques, with the results as follows:
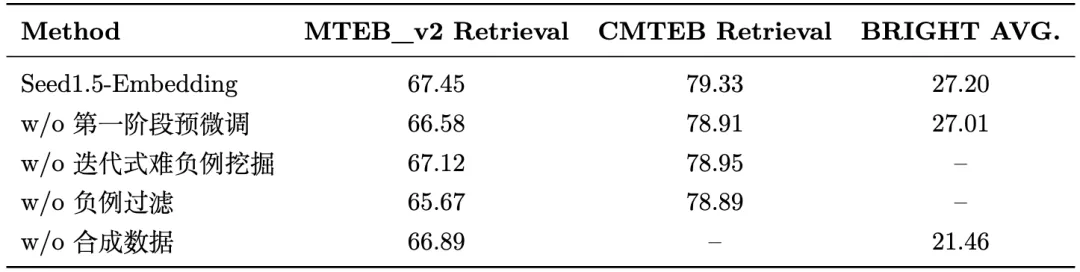
Based on the ablation study, we made the following observations:
(1) First-stage pre-finetuning, iterative hard negative mining, and negative filtering all contribute to improving the performance of general-purpose retrieval tasks. Particularly, negative filtering is especially impactful for English tasks. This is attributed to a limited number of documents in multiple English datasets, coupled with challenges from both false hard negatives and false in-batch negatives.
(2) Synthetic data boosts the performance of English retrieval and reasoning-intensive retrieval. For Chinese retrieval tasks, however, the team did not use synthetic data due to sufficient training data.
These observations led the team to place greater emphasis on both the quantity and quality of training data when training embedding models. Sufficient quantity allows LLMs to smoothly shift from a generative paradigm to a representational one, while high quality ensures robust retrieval performance for embedding models.
Additionally, the team believes that synthetic data can be used for targeted optimization in specific retrieval scenarios, enabling the model to learn scenario-specific matching patterns.
5. In Conclusion
The API for Seed1.5-Embedding now is available on the Volcano Ark platform, Click here to learn how to use it. Additionally, this model and its related technologies will soon be applied in real-world search recall tasks to enhance retrieval accuracy and better serve users.
Moving forward, the team will continue to delve into the impact of scaling up model parameters and explore more inclusive, generalizable data construction methods to expand the capability boundaries of embedding models. The team will also explore the next-generation training recipes for embedding models, aiming to transfer the capabilities of generative large models to vector representation tasks in a more natural and efficient way.
[1] MTEB: Massive Text Embedding Benchmark.
[2] BRIGHT: A Realistic and Challenging Benchmark for Reasoning-Intensive Retrieval.
[3] Improving Text Embeddings with Large Language Models.
[4] Towards General Text Embeddings with Multi-stage Contrastive Learning.
[5] NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models.
[6] Gemini Embedding: Generalizable Embeddings from Gemini.
[7] Conan-embedding: General Text Embedding with More and Better Negative Samples.
[8] CoSENT (I): A More Effective Sentence Embedding Approach than Sentence-BERT.
[9] ReasonIR: Training Retrievers for Reasoning Tasks.