First Release of Seed VLM Tech Report: Comprehensive Solutions for Image, Video, GUI, and Game
First Release of Seed VLM Tech Report: Comprehensive Solutions for Image, Video, GUI, and Game
Date
2025-05-13
Category
Models
Seed1.5-VL is the latest visual-language multimodal large model released by ByteDance's Seed team. It offers enhanced general multimodal understanding and reasoning capabilities while significantly reducing inference costs, achieving state-of-the-art (SOTA) performance on 38 out of 60 public benchmarks.
Currently, Seed1.5-VL's API is available on Volcano Engine for users to explore.
Tech report: https://arxiv.org/abs/2505.07062
Website link: https://seed.bytedance.com/tech/seed1\_5\_vl
API (log in and select Doubao-1.5-thinking-vision-pro to experience): https://www.volcengine.com/experience/ark?model=doubao-1-5-thinking-vision-pro-250428
GitHub sample code: https://github.com/ByteDance-Seed/Seed1.5-VL
We are thrilled to introduce Seed1.5-VL!
Seed1.5-VL is the latest addition to the Seed series of large models, pre-trained on more than 3T multimodal data tokens.
As illustrated in the diagram, Seed1.5-VL consists of three main components:
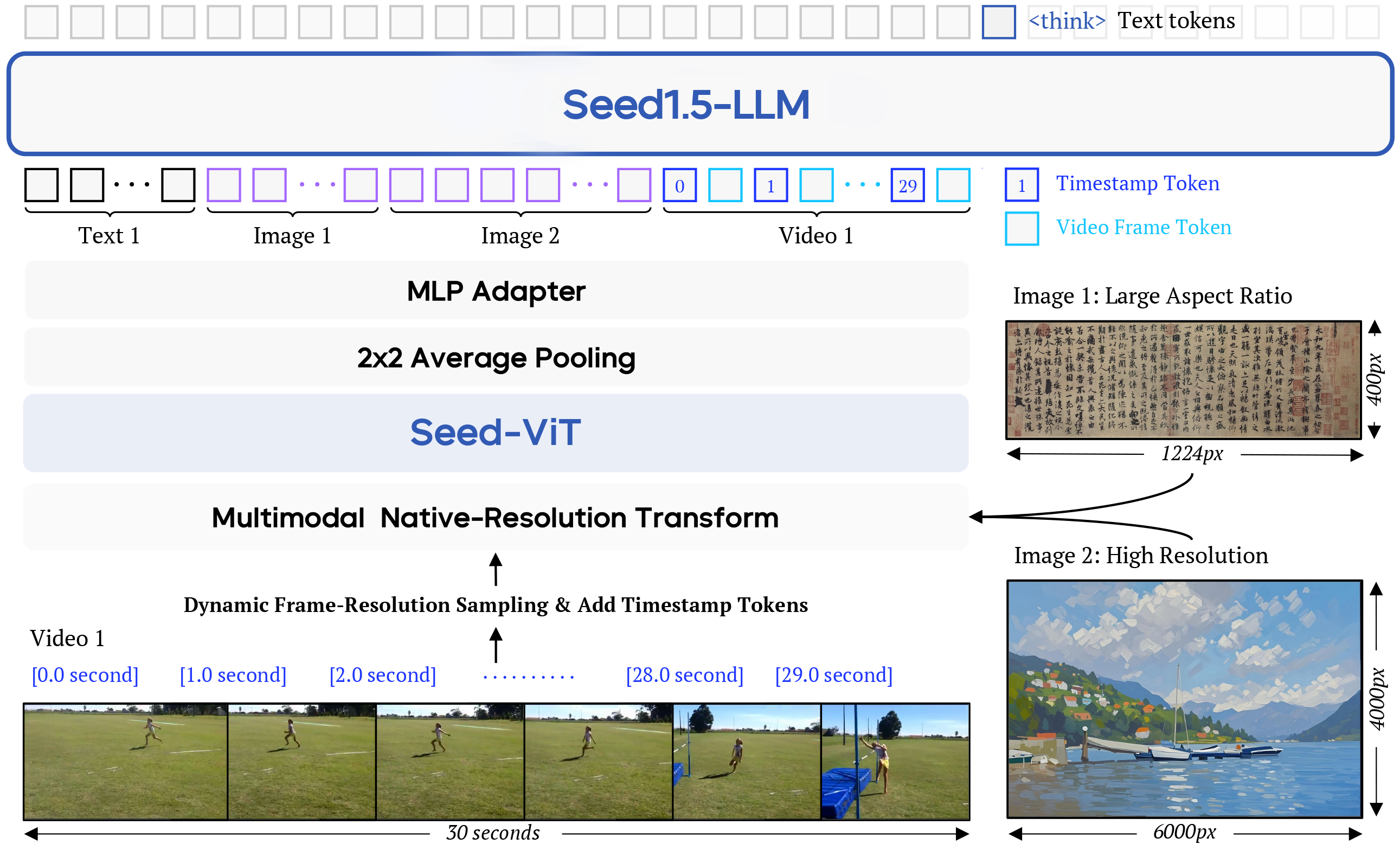
(1) SeedViT, with 532M parameters, designed for encoding images and videos, capable of processing inputs with any aspect ratio;
(2) A Multilayer Perceptron (MLP) adapter, for projecting visual features into the multimodal representation space;
(3) Seed1.5-LLM, utilizing an MoE architecture with 20B active parameters, for handling multimodal inputs.
Despite having only 20B active parameters, Seed1.5-VL excels in tasks such as visual reasoning, image question answering, chart understanding and Q&A, visual localization/counting, video understanding, and GUI intelligent agents. Additionally, its streamlined architecture design significantly reduces inference costs and computational requirements, making it highly suitable for interactive applications.
In this article, we will delve into the core aspects of Seed1.5-VL's data construction, training methods, and infrastructure. More details can be found in the full tech report.
Performance Evaluation
To ensure comprehensive evaluation, we employed a wide array of public benchmarks and meticulously constructed an internal evaluation system that covers a variety of tasks including visual reasoning, localization, counting, video understanding, and computer usage.
Specifically, even though Seed1.5-VL possesses only 20B active parameters, its performance is comparable to that of Gemini2.5 Pro, achieving state-of-the-art (SOTA) results in 38 out of 60 public benchmarks.
In terms of image understanding, both the standard "non-thinking" mode and the enhanced "thinking" mode of Seed1.5-VL were assessed through a series of tests encompassing multimodal reasoning, general visual Q&A, document understanding, semantic anchoring, and spatial reasoning capabilities. As illustrated in the table, the highest score in each test is highlighted in bold, and the second-highest score is underlined.
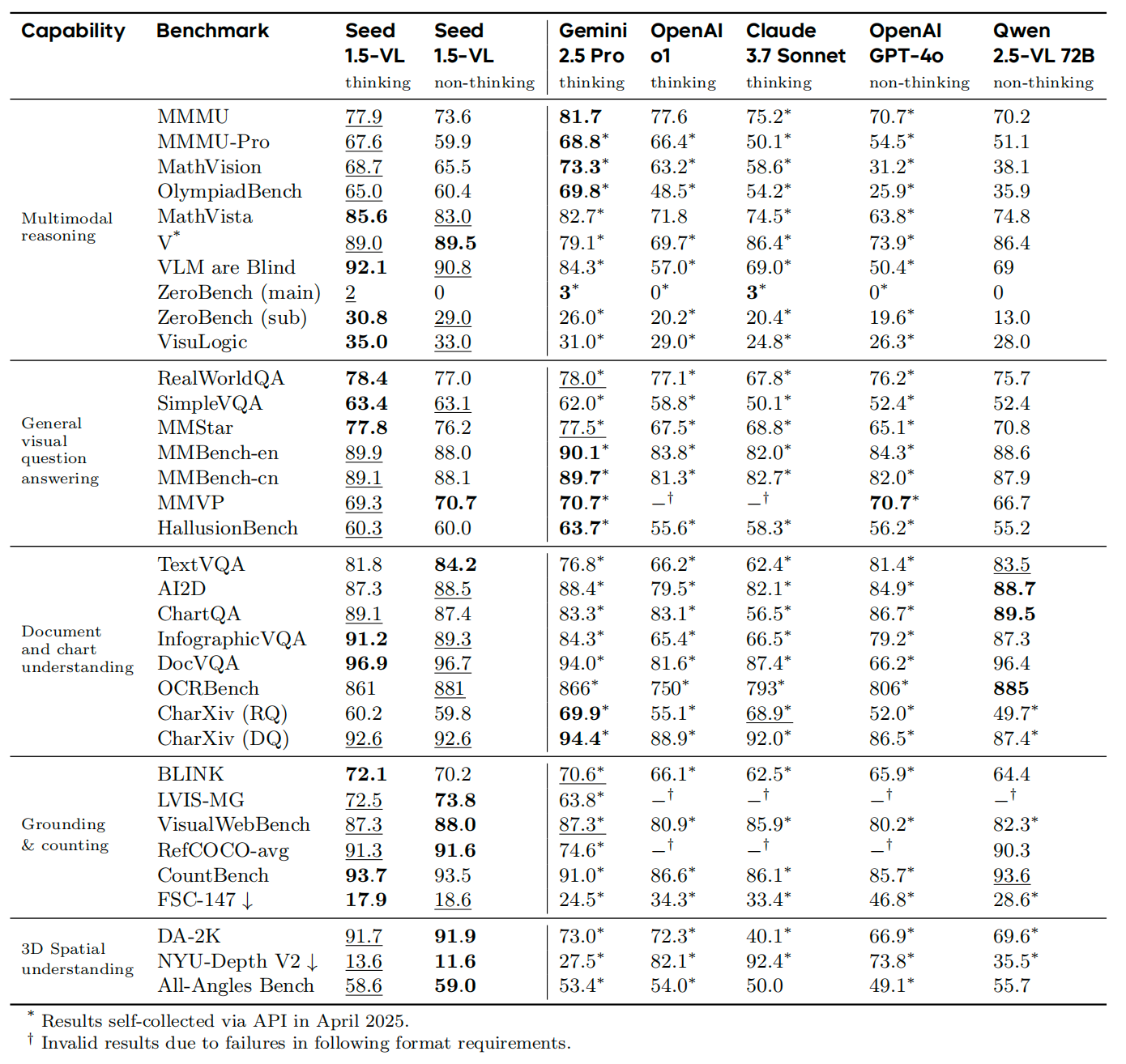
Performance Evaluation of Seed1.5-VL in Image Understanding
For video understanding, the evaluation covers five dimensions: short videos, long videos, streaming videos, video reasoning, and video temporal localization. Out of the 19 relevant benchmarks, Seed1.5-VL achieved SOTA results in 14.
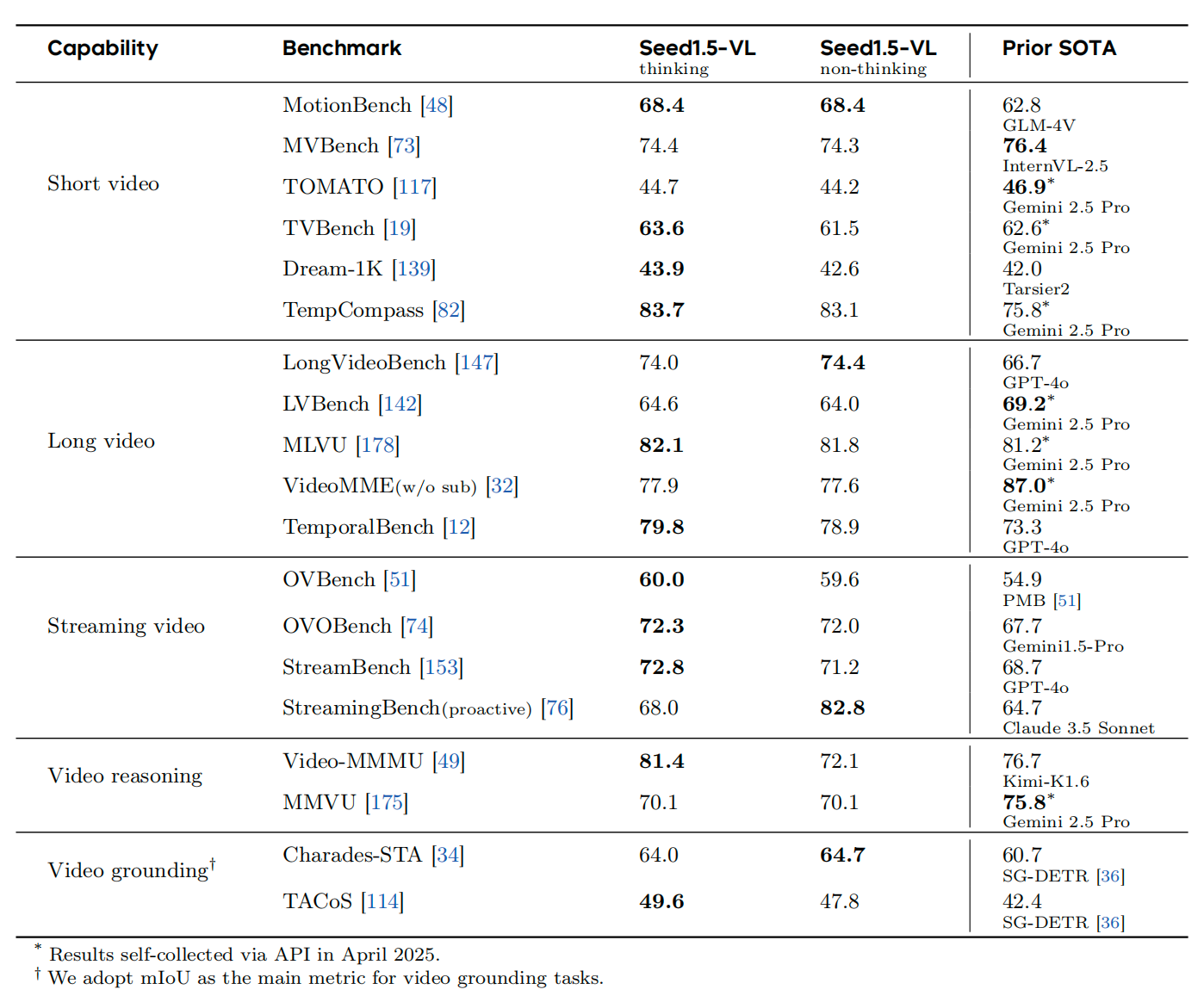
Performance Evaluation of Seed1.5-VL in Video Understanding
In agent-centric tasks (such as GUI control and games), Seed1.5-VL achieved SOTA results in 3 out of 7 GUI intelligent agent tasks.
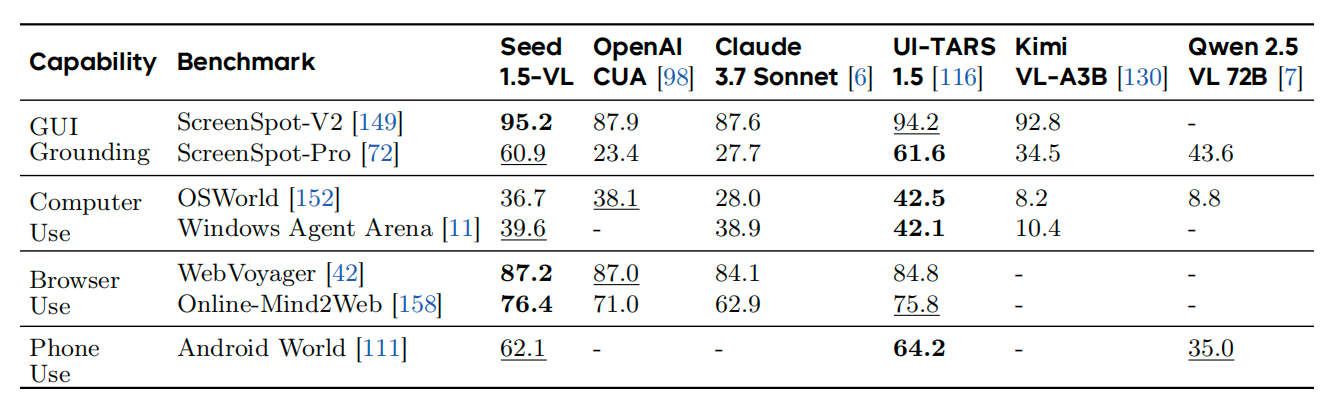
Performance Evaluation of Seed1.5-VL in GUI Tasks
Meanwhile, we also conducted multiple evaluations of the model's visual encoder, Seed-ViT. In zero-shot visual recognition tasks, it attained an average score of 82.5, comparable to InternVL-C-6B, but using only 1/10 of its total number of parameters.
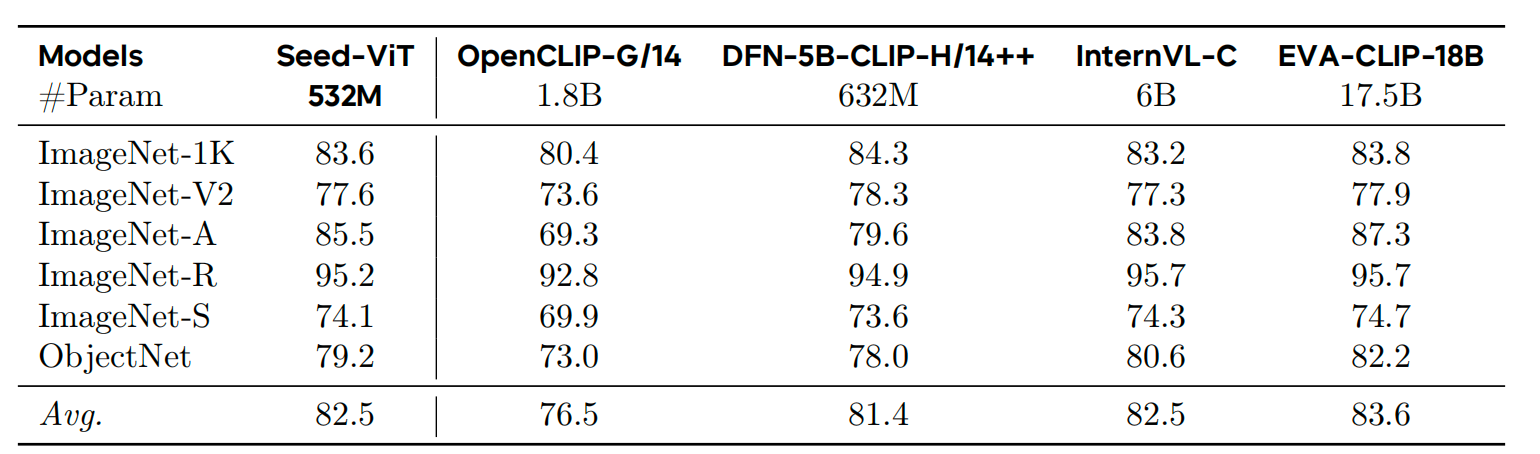
Performance Evaluation of Seed-ViT
Notably, Seed1.5-VL also showcases strong comprehensive capabilities and effective generalization to tasks beyond the training data, aside from the aforementioned benchmarks. For instance, solving complex visual reasoning puzzles, interpreting and correcting handwritten code in images, interacting with computers and games as an agent, among other advanced capabilities. These emerging capabilities are worth of further exploration. Next, we will demonstrate several specific cases.
Key Highlights & Cases
1. Visual localization capability
Support localization for multiple targets, small targets, and general targets through both bounding box and point localization. Also handle complex scenarios such as localization and counting, localization content description, and 3D localization.
Count the number of wild geese in the image
2. Video understanding capability
Support dynamic frame rate sampling, significantly enhancing video temporal localization. Can also accurately locate video segments that correspond to textual descriptions through vector search.
Locate the time when the key is found in the video
3. Visual reasoning capability
By incorporating reinforcement learning, the model's reasoning abilities have greatly improved, allowing it to solve complex visual puzzles.
Identify the differences between two images
Solve a visual reasoning problem
4. Multimodal intelligent agent capability
Enhance GUI localization performance, enabling the completion of complex interactive tasks across various environments such as PC and mobile platforms. This includes gathering and processing information, reasoning, and acting within open games. Currently, the Douyin testing team has begun using VLM for automation in regression testing.
Foundation model: Seed1.5-VL. Automated GUI testing scenario: giving a like to a friend's video
Data Construction
The Seed1.5-VL pre-training corpus includes 3T tokens of diverse, high-quality multimodal data, which we categorized based on target capabilities:
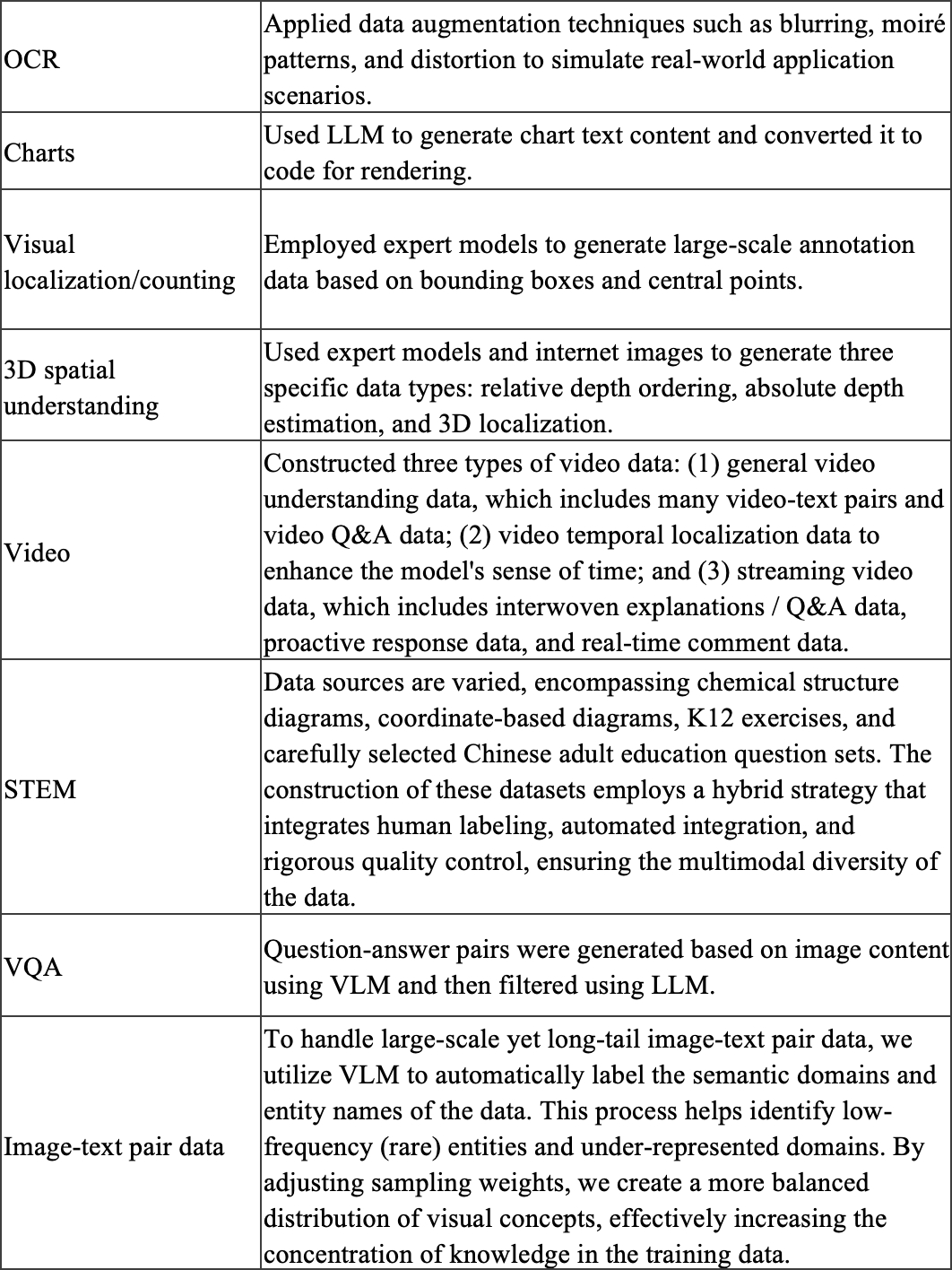
In the post-training phase, we employ a hybrid training method that integrates deep-thinking and non-deep-thinking data, isolating them with system prompts. This allows us to flexibly enable or disable the model's deep-thinking mode during inference based on specific needs. Additionally, we have designed a variety of visual tasks to enhance the model's visual reasoning capabilities, including STEM-related questions with images, visual instruction following, and visual puzzles. These tasks can be used for model training simply through answer matching or constraint validation methods.
Training Methods
There are typically two pre-training methods for multimodal models: 1. conducting joint multimodal learning from the beginning; 2. continuing multimodal pre-training based on a foundational language model. Seed1.5-VL adopts the latter approach to facilitate flexible ablation experiments and rapid iterative development.
The pre-training of Seed1.5-VL is divided into three phases:
- Phase 0: train only the MLP adapter to initially align visual and language representations.
- Phase 1: unfreeze all parameters and train on 3T tokens of multimodal data, focusing on knowledge accumulation, visual grounding, and OCR capabilities;
- Phase 2: introduce new domain data, such as video, programming, and three-dimensional understanding, into a more balanced data mix, and significantly increase the sequence length to handle complex scenarios and long sequence dependencies.
In the post-training phase, we adopted a method that combines rejection sampling with reinforcement learning.
- Supervised fine tuning (SFT): To balance instruction-following and reasoning capabilities, the SFT dataset consists of two parts: general instruction data (for concise and accurate responses) and Long Chain-of-Thought (LongCoT) data (for detailed step-by-step reasoning). The LongCoT data is obtained through models fine-tuned with reinforcement learning and rejection sampling.
- Reinforcement learning (RL): Incorporates reinforcement learning from human feedback (RLHF) and reinforcement learning with verifiable reward (RLVR) along with various advanced technologies. A mixed reward system is employed to differentiate between general prompts and verifiable prompts; general prompts are rewarded only for the final answer to encourage exploratory thinking. Different types of tasks use varying KL divergence coefficients to balance reward exploitation and exploration.
Infrastructure
Training Vision-Language Models (VLMs) presents unique challenges due to the heterogeneity of data, which includes both visual and natural language data, and the model architecture, consisting of a small visual encoder (532M) and a significantly larger language model (20B active parameters).
To address the imbalance between the visual encoder and the language model, we employ the following key solutions:
- Multimodal parallel framework: Different parallel strategies are applied to the visual encoding/MLP adapter and the language model. The visual encoder uses ZeRO data parallelism, while the language model utilizes standard 4D parallelism;
- Visual token redistribution strategy: GPUs are divided into several groups (e.g., groups of 192), with load balancing performed only within each group using a greedy load balancing algorithm (assigning images to the GPU with the lowest current load);
- Custom data loader: The data reading and distribution process is optimized. For non-data parallel groups (such as pipeline parallel groups), only one GPU within the group handles data loading, and the metadata is then sent to other GPUs to avoid redundant reads. For the visual encoder's pure data parallelism, unnecessary image parts are filtered out before transferring data to the GPUs, reducing PCIe traffic.
Limitation
Seed1.5-VL has significantly enhanced its visual understanding and reasoning capabilities, bringing it closer to achieving the generalization abilities of VLM.
However, there are still some limitations in the current research. First, in fine-grained visual perception, the model faces challenges in handling tasks such as object counting, image difference recognition, and explaining complex spatial relations, especially under extreme conditions such as irregular object alignment, similar colors, or partial occlusion. Second, in high-level reasoning tasks such as solving the Huarong Road puzzle (a classic sliding block puzzle), navigating mazes, or following complex instructions, the model can introduce unfounded assumptions or generate incomplete responses, indicating room for improvement. Additionally, in video reasoning, the model still struggles to accurately identify the sequence of actions or infer the order of events from the before-and-after states of objects.
To address these limitations, we plan to make further improvements.
Last But Not Least
ByteDance's Seed team remains dedicated to relentlessly pursuing the upper limits of intelligence. Going forward, we will continue to share our insights and practical experiences in areas such as model architecture, data construction, training methods, and evaluation design. Our aim is to better support future research and innovation for the AI community.