Meet Seed at CVPR 2025: 12 Papers Accepted and 2 Talks
Meet Seed at CVPR 2025: 12 Papers Accepted and 2 Talks
Date
2025-06-10
Category
Conferences

The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025 was held from June 11 to 15 in Nashville, Tennessee, USA.
At this year's conference, the ByteDance Seed team had 12 papers accepted, 4 of which are highlight papers, spanning cutting-edge domains such as visual reasoning, visual modeling, 3D vision, and real-world industrial applications. In this article, we explore 6 of these selected papers in detail.
During the conference, at Booth 1101, we showcased cutting-edge technologies such as Seedance 1.0, Seedream 3.0, Seed1.5-VL, SeedEdit 3.0, and BAGEL. Seed team researchers joined the conference to share our work.
Booth Talks
During the conference, the lead authors of the Seed1.5-VL and BAGEL projects shared their insights with attendees at our booth.

When & Where: June 13, 15:30 (CDT), Booth 1101
Topic: Seed1.5-VL is a state-of-the-art vision-language multimodal large model developed by Seed. Pre-trained on over 3T multimodal tokens, it delivers general-purpose multimodal understanding and reasoning capabilities, and significantly reduces inference costs without compromising multi-task performance.

When & Where: June 14, 16:00 (CDT), Booth 1101
Topic: BAGEL, the latest open-source foundation model developed by Seed, achieves unified understanding and generation across text, images, and video. Based on the Mixture-of-Transformers (MoT) architecture with 7B active parameters, it significantly outperforms previous open-source general-purpose models on major multimodal benchmarks.
Selected Papers

Parallelized Autoregressive Visual Generation
arXiv: https://arxiv.org/pdf/2412.15119
Code: https://github.com/YuqingWang1029/PAR
Exhibition Location: ExHall D Poster #220, Poster Session 3
Autoregressive (AR) models have garnered significant interest due to their powerful sequence modeling capabilities in visual generation. However, their sequential token-by-token generation mechanism results in low inference speed, posing a critical bottleneck for real-world applications. Traditional acceleration approaches struggle to balance efficiency and quality, either relying on complex non-autoregressive paradigms to introduce complex architectures (such as MaskGIT) or compromising the AR model's unified modeling power via multi-scale designs.
To address this challenge, this paper presents Parallelized Autoregressive Visual Generation (PAR), a novel approach that achieves efficient acceleration in standard visual AR frameworks for the first time. PAR dynamically switches between generation modes by continuously evaluating token dependency strength. The core innovations include:
- Two-stage generation strategy: PAR first sequentially generates initial tokens for each region to establish the global context. It then performs parallel generation by identifying and grouping spatially distant, weakly dependent tokens at corresponding positions across different regions. This strategy helps to avoid conflicts between strongly dependent adjacent tokens.
-
Bi-directional attention and positional encoding optimization: PAR allows each token in parallel groups to access the complete context from previous groups, enhancing cross-region dependency modeling while avoiding broken local details. Additionally, it employs 2D Rotary Position Embedding (RoPE) to decouple tokens' spatial position information from the generation order, thereby preserving global structural coherence.
-
Seamless architecture compatibility: PAR's seamless adaption is achieved through learnable transition tokens and translation-invariant positional encoding, without modifying the transformer architecture and tokenizer.

Visual comparison of PAR and traditional autoregressive generation (LlamaGen): PAR achieves a 3.6–9.5× speedup over LlamaGen while maintaining comparable quality, reducing the generation time from 12.41 seconds to 3.46 seconds (PAR-4×) and 1.31 seconds (PAR-16×) per image. Time measurements are conducted with a batch size of 1 on a single A100 GPU.
Experiments on ImageNet and UCF-101 demonstrate that PAR achieves 3.6–9.5× faster inference in image generation with only 0–0.7 FID degradation, and accelerates video generation by 12.6× with merely 9.3 FVD increase, demonstrating its spatiotemporal universality. Compared to the baseline model LlamaGen, PAR not only accelerates generation with comparable quality but also operates without extra models or complex designs, outperforming both non-autoregressive and multi-scale approaches. Furthermore, this algorithm can be seamlessly integrated with engineering-level optimizations such as torch.compile, achieving an additional 3–4× speedup. In summary, PAR's dependency-aware parallel design overcomes the efficiency bottleneck of autoregressive models while maintaining competitive accuracy.

Video Depth Anything: Consistent Depth Estimation for Super-Long Videos
arXiv: https://arxiv.org/pdf/2501.12375
Project Page: https://videodepthanything.github.io/
Exhibition Location: ExHall D Poster #169, Poster Session 5
Monocular depth estimation models predict depth information for each pixel from single 2D RGB images, making them widely applicable in augmented reality (AR), 3D reconstruction, and autonomous driving. However, it suffers from temporal inconsistency in videos, hindering its real-world applications. Therefore, building an accurate, temporally stable, and efficient long-video depth model has become the key challenge for wider adoption of monocular depth estimation.
In this paper, we propose Video Depth Anything (VDA), the first method that achieves high-quality, consistent depth estimation in super-long videos (over several minutes). The core approaches include:
-
Shift from a single-image depth model to a video depth model: We transform Depth Anything into Video Depth Anything by incorporating a lightweight spatiotemporal head. We also adopt a joint training strategy using both image and video data. This approach achieves spatiotemporal stability without sacrificing the single-image model's richness in details.
-
Simple yet effective spatiotemporal consistency constraint: We directly use the depth at the same coordinate in adjacent frames to calculate the loss. We posit that the change in depth of corresponding points between adjacent frames should be consistent with the change observed in ground truth, thereby eliminating the dependence on the optical flow.
-
Inference strategy for ultra-long videos: We employ overlap interpolation and key-frame referencing to ensure smooth inference across local windows. This strategy significantly reduces accumulated scale drift, making it particularly suitable for long video processing.

Left: VDA can generate spatiotemporally consistent depth predictions for long videos with rich actions. The demo video shows a 196-second (4,690 frames) long take of pair skating. Right: Comparison to baselines in terms of accuracy (δ₁), temporal consistency, and latency on the NVIDIA A100 GPU (denoted with circle size). Consistency is defined as the maximum Temporal Alignment Error (TAE) among all models minus the TAE of each model. VDA achieves the best performance across all metrics.
Experiment results show that VDA achieves state-of-the-art (SOTA) performance in both accuracy and stability metrics on video datasets, with a particularly notable accuracy improvement of more than 10%. Moreover, its inference speed significantly surpasses that of previous competing models, which is over 10× faster than the previous highest-accuracy model. On V100 GPUs, the compact version of VDA even achieves 30 FPS (30 frames per second), providing a feasible solution for dynamic scenarios such as AR/VR, robotic navigation, and cinematic video editing.

SeedVR: Seeding Infinity in Diffusion Transformer Towards Generic Video Restoration
arXiv: https://arxiv.org/pdf/2501.01320
Exhibition Location: ExHall D Poster #187, Poster Session 1
Video restoration poses non-trivial challenges in maintaining fidelity while recovering temporally consistent details from low-quality videos with unknown degradations. Despite recent advances in diffusion-based restoration, these methods often face limitations in generation capabilities and sampling efficiency. When processing high-resolution long videos, they rely on patch-based sampling and full attention mechanisms, leading to high computational costs, slow inference speeds, and unsatisfactory output results that struggle to meet real-world needs. To address these challenges, this paper presents SeedVR, a diffusion transformer model designed for generic video restoration. Its core approaches include:
- Shifted window attention mechanism (Swin-MMDiT): SeedVR employs a large 64 × 64 window instead of full attention to effectively capture long-range dependencies. It also uses 3D RoPE to handle variable-sized windows. This mechanism empowers the model to process videos of arbitrary resolutions and lengths, overcoming the limitations of patch-based sampling.
- Causal video variational autoencoder (CVVAE): SeedVR uses CVVAE to compress time and space by factors of 4 and 8, respectively, and increases the number of latent channels to 16. This autoencoder significantly reduces computational costs while maintaining high reconstruction quality, thereby enhancing training and inference efficiency.
- Mixed image and video training and progressive training: SeedVR jointly trains on a mixed dataset comprising 10 million images and 5 million videos. Additionally, it employs a multi-stage progressive training approach, advancing from low-resolution, short videos to high-resolution, long videos. These training strategies help to enhance the model's generalization capabilities in handling complex scenarios.
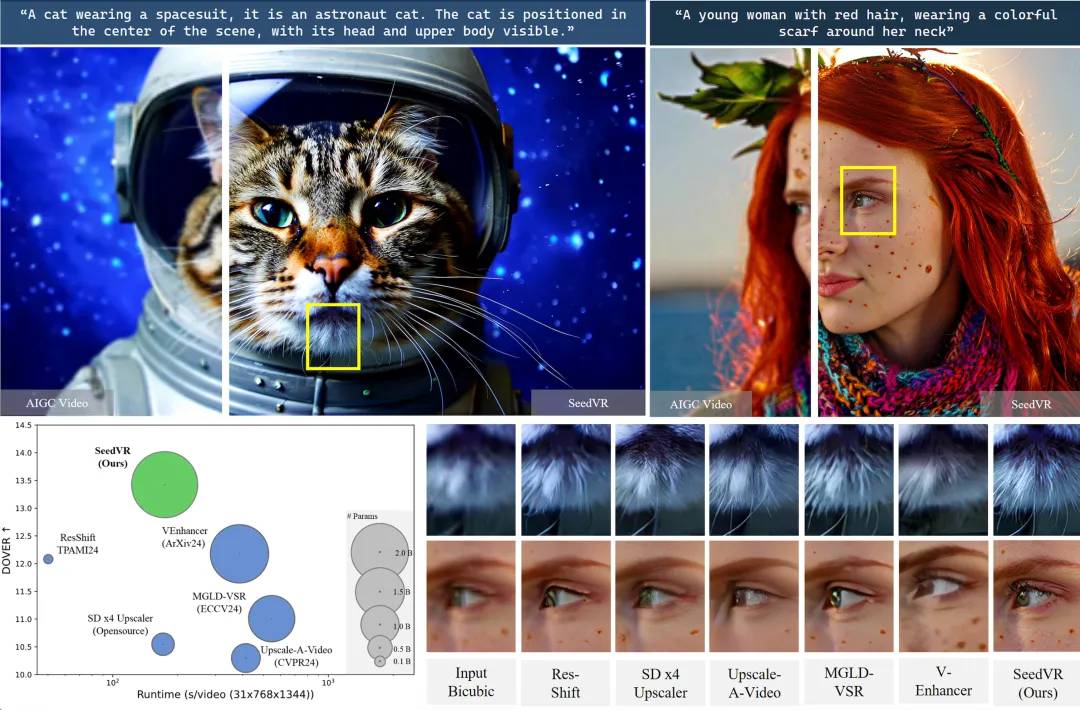
Visual comparison between SeedVR and existing diffusion model-based restoration approaches: Despite its substantial 2.48 billion parameters, SeedVR is over 2× faster in inference while delivering significantly enhanced video quality. This is attributed to its optimized window attention design and an improved video VAE.
SeedVR delivers outstanding performance across multiple datasets. On 6 benchmarks including SPMCS and UDM10, it achieves state-of-the-art performance in 4 of them. Its outputs achieve significantly superior performance in perceptual quality metrics such as LPIPS and DISTS, outperforming existing methods in both restored visual quality and quantitative scores. Particularly, in real-world and AI-generated video restoration, SeedVR can effectively remove degradation while restoring intricate details such as building structures and animal fur, demonstrating enhanced detail fidelity and temporal consistency. Additionally, despite its 2.48 billion parameters, it is over 2× faster in inference than VEnhancer and Upscale-A-Video while maintaining high efficiency. In summary, SeedVR pioneers the use of large diffusion transformer models in generic video restoration. It sets a new benchmark for this field and propels the evolution towards high-quality, high-efficiency solutions.

X-Dyna: Expressive Dynamic Human Image Animation
arXiv: https://arxiv.org/pdf/2501.10021
Exhibition Location: ExHall D Poster #5, Poster Session 2
In the field of virtual human and digital content generation, dynamic animation from a single human image has long been constrained by challenges such as rigid motion, disjointed backgrounds, and distorted facial expressions. In this paper, we propose X-Dyna, a novel diffusion model framework. Through multi-module coordination, X-Dyna naturally integrates character movements, facial expressions, and environmental dynamics, breathing vivid dynamic life into static images.
X-Dyna features three key innovations: (1) Dynamics-Adapter serves as a bridge between appearance and dynamics. With a lightweight design, it integrates the clothing textures and lighting features of the reference image as a trainable residual into the diffusion network's attention mechanism. This approach preserves character identity while maintaining smooth motion, avoiding rigid backgrounds and motion blurs common in traditional approaches. (2) S-Face ControlNet, a facial control module, implicitly learns facial expression control from a synthesized cross-identity face patch, enabling identity-disentangled control over facial expressions. This allows for precise reproduction of subtle facial expression changes, such as eyebrow raises or smiles, even during cross-identity transfer. (3) A mixed data training strategy combines data of human motion and natural scene dynamics (such as water ripples, fire, and clouds). This allows the model to learn the physical motion principles governing phenomena such as swaying hair and flowing garments, as well as interactive environmental effects such as rain and fire.
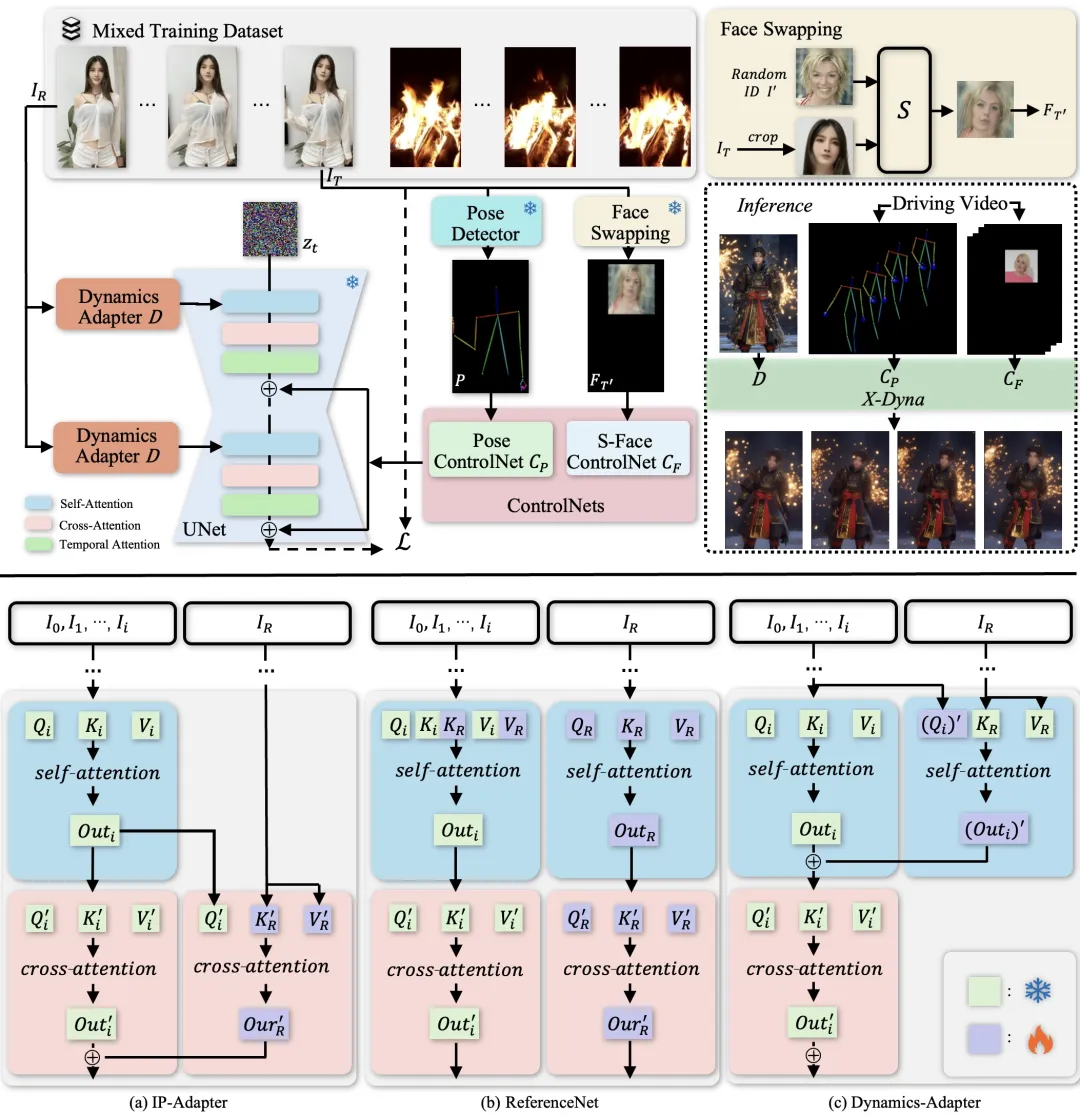
(a) IP-Adapter encodes the reference image as an image CLIP embedding and injects the information into the cross-attention layers in Stable Diffusion (SD) as the residual. (b) ReferenceNet is a trainable parallel UNet and feeds the semantic information into SD via concatenation of self-attention features. (c) Dynamics-Adapter encodes the reference image with a partially shared-weight UNet. The appearance control is realized by learning a residual in the self-attention layer. All other components share the same frozen weight with SD.
Experiment results show that X-Dyna achieves a score of 1.518 on the dynamic texture generation metric DTFVD, outperforming approaches such as MagicAnimate by over 50%. Details such as hair sway and water ripples demonstrate a 3-fold improvement in clarity. In user blind testing, its ratings for Foreground Dynamics (4.85/5), Background Dynamics (4.92/5), and Identity Preserving (4.78/5) consistently outperformed its competing approaches by 0.8–1.2 points. In summary, X-Dyna, powered by its out-of-the-box Stable Diffusion extension module, can create highly lifelike and expressive animations from a single human image. It can be widely used in real-time animation for virtual anchors/hosts, motion generation for film/television characters, and dynamic effects on social media.

DiG: Scalable and Efficient Diffusion Models with Gated Linear Attention
arXiv: https://arxiv.org/pdf/2405.18428
Exhibition Location: ExHall D Poster #219, Poster Session 2
Transformer-based diffusion models demonstrate strong performance in the field of visual content generation, particularly exemplified by Diffusion Transformers (DiT). However, when DiT models handle long-sequence tasks such as processing high-resolution images, the quadratic complexity of the self-attention mechanism creates computational efficiency and memory consumption bottlenecks. Existing linear attention approaches, such as Mamba and Gated Linear Attention (GLA), face challenges like unidirectional modeling and lack of local awareness.
In this paper, we propose Diffusion Gated Linear Attention Transformers (DiG), aiming to incorporate the sub-quadratic modeling capability of GLA into the 2D diffusion backbone. With a lightweight design, DiG enables efficient long-sequence visual generation:
- Spatial reorient & enhancement module (SREM): This module employs block-wise scanning direction control (with four basic patterns) and depth-wise convolution (DWConv). By doing so, it overcomes the limitations of unidirectional modeling and enhances local spatial awareness while introducing minimal matrix operations and parameter overhead.
- Dual architecture design: DiG offers two variants: plain architecture (denoted as DiG) and U-shape architecture (denoted as U-DiG). Inspired by UNet, U-DiG adopts a hierarchical structure. It uses downsampling and upsampling modules along with cross-layer connections to enhance its performance in generating high-resolution content.
- Linear attention optimization: The GLA-based linear attention mechanism reduces computational complexity from quadratic to sub-quadratic, significantly decreasing training time and GPU memory usage.
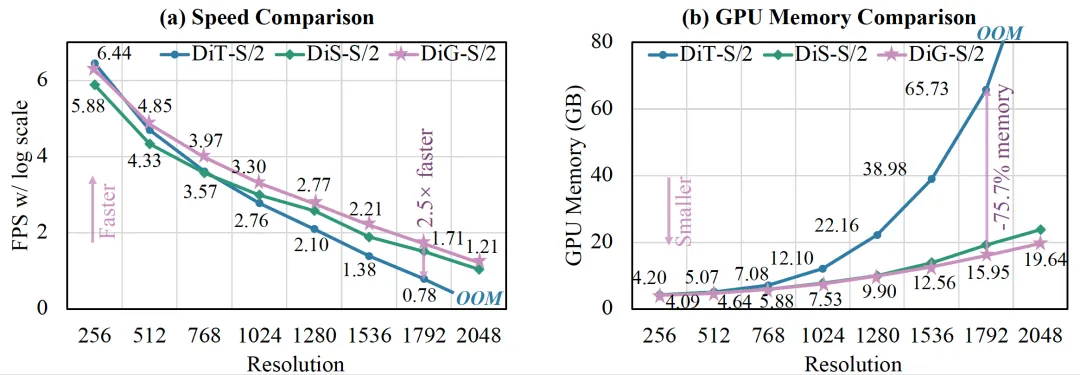
Efficiency comparison among DiT with Attention, DiS with Mamba, and DiG model. DiG achieves higher training speed while costs lower GPU memory in dealing with high-resolution images. For example, DiG is 2.5× faster than DiT and saves 75.7% GPU memory at a resolution of 1792 × 1792 (12,544 tokens per image).
Experiment results show that DiG achieves generation performance comparable to DiT on ImageNet at resolutions of 256 × 256 and 512 × 512, while demonstrating significant efficiency improvements. For example, at 512 × 512 resolution, DiG-XL/2 achieves an FID of 17.36, surpassing DiT's 20.94. At 1792 × 1792 resolution, DiG-S/2 trains 2.5× faster and uses 75.7% less GPU memory. In summary, by leveraging linear attention and lightweight module design, DiG generates high-quality outputs while overcoming quadratic complexity limitations. It provides an efficient and scalable new backbone for long-sequence generation tasks, such as high-resolution image and video generation. This advancement paves the way for applying diffusion models in resource-constrained scenarios.

Dora: Sampling and Benchmarking for 3D Shape Variational Auto-Encoders
arXiv:https://arxiv.org/pdf/2412.17808
Project Page: https://aruichen.github.io/Dora/
Exhibition Location:ExHall D Poster #38, Poster Session 4
Recent 3D content generation approaches commonly adopt a two-stage pipeline based on variational auto-encoders (VAEs): encoding shapes into a latent space, followed by training a latent diffusion model. However, the widely adopted uniform point sampling strategy often leads to a significant loss of geometric details, limiting the quality of shape reconstruction and downstream generation tasks. Additionally, existing evaluation protocols struggle to effectively measure reconstruction accuracy for complex geometric features. To systematically address these challenges, we propose Dora-VAE, accompanied by Dora-Bench in this paper:
(1) Sharp edge sampling (SES): This algorithm identifies edges with high geometric complexity by analyzing dihedral angles between adjacent faces on a mesh. It then prioritizes sampling points along these salient regions while maintaining a balance with uniformly sampled points to capture the overall structure. This approach ensures comprehensive coverage of both fine details and global geometry. (2) Dual cross-attention mechanism: During the encoding process, we separately compute the attention for uniformly sampled points and salient points through a dual cross-attention mechanism. This approach integrates feature representations from both uniform and salient regions, enhancing the model's ability to process detail-rich point clouds. (3) Dora-Bench Benchmark: This benchmark categorizes test shapes into four levels based on geometric complexity, quantified by the number of salient edges. To evaluate reconstruction accuracy specifically in geometrically salient regions, it introduces the Sharp Normal Error (SNE) metric. This enables a more fine-grained assessment of VAE performance.
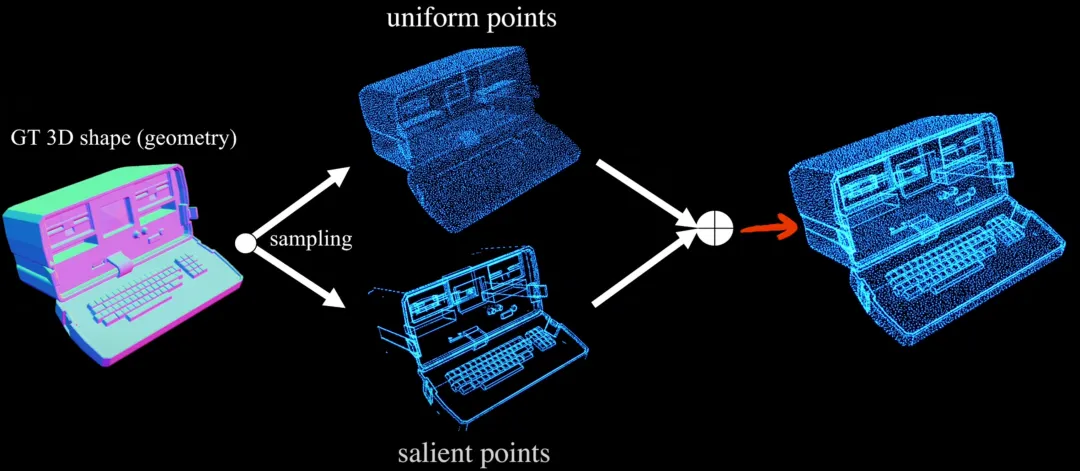
Sharp edge sampling (SES)
Experiments on Dora-Bench demonstrate that Dora-VAE achieves reconstruction quality comparable to the state-of-the-art dense XCube-VAE, while requiring a latent space at least 8× smaller (1,280 vs. > 10,000 dimensions). On complex shapes (Level 4), it achieves an F-score (0.005) of 87.473, a Chamfer Distance (CD) as low as 5.265 × 10⁻⁴, and an SNE of only 1.579 × 10⁻². These results show that Dora-VAE significantly outperforms vector-set methods such as Craftsman-VAE. In single-image-to-3D generation tasks, the diffusion model built with Dora-VAE produces outputs richer in geometric details, demonstrating its benefits for downstream tasks.
In summary, Dora-VAE provides a novel approach to enhancing the feature capture capabilities of 3D VAEs through SES and a dual cross-attention mechanism, and Dora-Bench establishes a rigorous evaluation framework. Collectively, they offer a new paradigm for efficient and compact 3D shape representation learning, and drive downstream tasks such as text-to-3D generation to produce higher-fidelity outputs.
Click to explore more Seed's selected papers at CVPR 2025 and other available papers.