Multi-SWE-bench: First Multilingual Code Fix Benchmark Open Source
Multi-SWE-bench: First Multilingual Code Fix Benchmark Open Source
Date
2025-04-14
Category
Research
The ByteDance Doubao (Seed) team has officially open-sourced the first multilingual SWE dataset, Multi-SWE-bench, which can be used to evaluate and improve "self-debugging" capabilities of the large model.
On the basis of SWE-bench, Multi-SWE-bench covers seven major programming languages beyond Python for the first time, making it a truly "full-stack engineering" evaluation standard. The dataset is entirely sourced from GitHub issue, which took nearly a year to build to measure and improve the advanced programming intelligence of large models as accurately as possible.
This article introduces the research background, data set construction and follow-up plans of Multi-SWE-bench, hoping to work with the industry to drive code generation technology to maturity.
From ChatGPT to 4o, o1, o3, Claude-3.5/3.7, and now Doubao-1.5-pro, DeepSeek-R1, large language models are revolutionizing the coding world at an incredible speed.
Nowadays, AI is not limited to writing functions or looking up APIs. Allowing AI to automatically solve real-world problems (bugs) submitted on GitHub has become one of the benchmarks for measuring the intelligence of models.
But a problem has emerged: Existing major evaluation datasets, such as SWE-bench, are all Python projects. This has led to some large models scoring high on the Python list, but struggling to perform well in other programming languages.
In order to solve the problem of insufficient generalization ability, the ByteDance Doubao (Seed) team officially open-sourced Multi-SWE-bench.

The dataset is the industry's first large model evaluation benchmark for multilingual code issue remediation across programming languages such as Java, TypeScript, C, C++, Go, Rust, and JavaScript.
As a standardized, reproducible, and multilingual open-source evaluation benchmark for "automated programming", Multi-SWE-bench aims to advance automated programming from being limited to solving tasks in a single language (such as Python) with low complexity, towards supporting multiple languages and demonstrating genuine problem-solving capabilities in a general-purpose intelligent agent.
Along with the rise of reinforcement learning, the team also open-sourced Multi-SWE-RL, providing a standardized, reusable data infrastructure for RL training in real-world code environments.
Currently, the Multi-SWE-bench paper, code, and datasets are all publicly available.
The team believes that this open-source release is only a small step in a thousand miles. No single team alone can meet the needs of technology development. Therefore, we welcome more researchers to participate in the construction of open-source benchmarks and data infrastructure.
Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving
Link to study: https://arxiv.org/abs/2504.02605
Link to leaderboard: https://multi-swe-bench.github.io
Link to code: https://github.com/multi-swe-bench/multi-swe-bench
Link to data: https://huggingface.co/datasets/ByteDance-Seed/Multi-SWE-bench
1. Mainstream Code Benchmark Limitations: Narrow language coverage and limited task complexity
Code generation tasks place comprehensive demands on the core capabilities of large language models, including logical inference and contextual understanding. Accordingly, benchmarks represented by SWE-bench have become an important indicator for assessing model intelligence in recent years.
SWE-bench is currently the most representative benchmark for code remediation evaluation, emphasizing realistic tasks and high difficulty. It is based on GitHub issue, which requires models to automatically locate and fix bugs, with challenges such as cross-file modifications, complex semantic inference, and contextual understanding. Compared to traditional code generation tasks (e.g., HumanEval, MBPP, LiveCodeBench), SWE-bench is closer to real-world development scenarios, serving as a key benchmark for measuring the advanced "programming intelligence" of large models.
However, with the rapid development of the industry and the continuous improvement of model capabilities, the benchmark struggles to fully cover multi-language environments and complex tasks encountered in real-world development, constraining the further evolution of large model code intelligence.
Specifically, its limitations are reflected in two main aspects:
(1) Single language dimension: The current mainstream evaluations are heavily concentrated on Python, lacking coverage for other languages, making it difficult to assess the model's cross-language generalization capabilities.
(2) Insufficient task difficulty: Most of the existing benchmarks consist of short patches and single-file fixes, failing to cover complex development scenarios such as multi-file, multi-step, and extra-long contexts. At the same time, tasks in SWE-bench lack any difficulty classification, making it challenging to systematically evaluate the model's performance across different capability levels.
In this context, the industry urgently needs a "multi-language bug repair evaluation set" with high-quality annotation instances and difficulty ranking that covers the mainstream programming languages.
2.Multi-SWE-bench covering 7 languages and 1,632 real remediation tasks
Multi-SWE-bench aims to make up for the shortcomings in the coverage of existing benchmark for other languages, systematically evaluating the "multilingual generalization capability" of large models in complex development environments, and advancing the evaluation and research of multilingual software development agents. Its main features are as follows:
- First to cover 7 mainstream programming languages (including Java, Go, Rust, C, C++, TypeScript, and JavaScript), constructing code repair tasks in multilingual development environments, and systematically evaluates the cross-language adaptability and generalization capabilities of models;
- Introducing of a task difficulty grading mechanism to classify problems into three levels: Easy, Medium and Hard, covering development challenges from one-line modification to multi-file, multi-step, multi-semantic dependencies;
- 1,632 instances are all sourced from real open-source repositories, and have been reviewed and screened by unified testing standards and professional developers to ensure that each sample includes a clear description of the problem, a correct repair patch, and a reproducible testing environment.
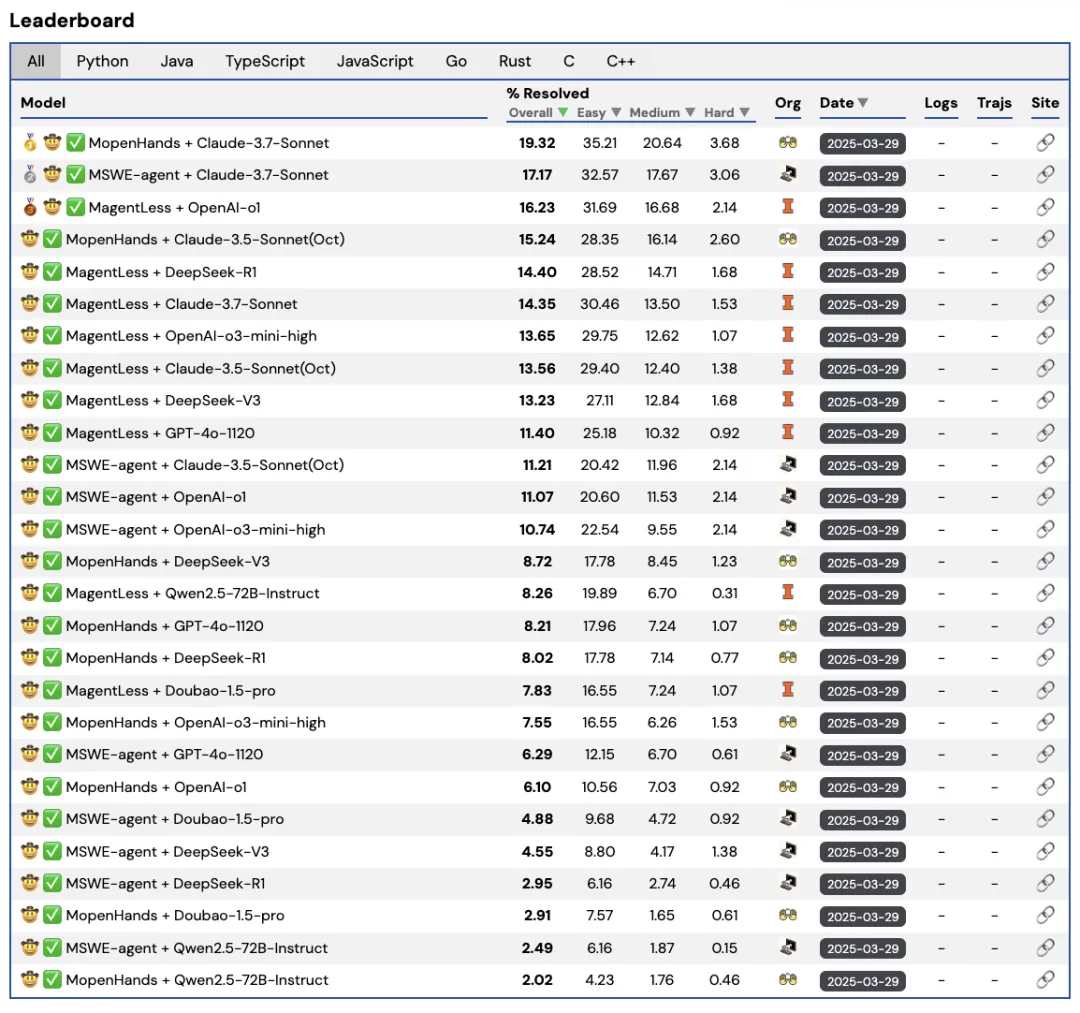
Evaluation Scores for Various Model Coding Abilities
Experiments conducted by the team utilizing Multi-SWE-bench revealed that while current LLMs perform well in Python bug-fixing, their average success rate for other languages generally falls below 10%.
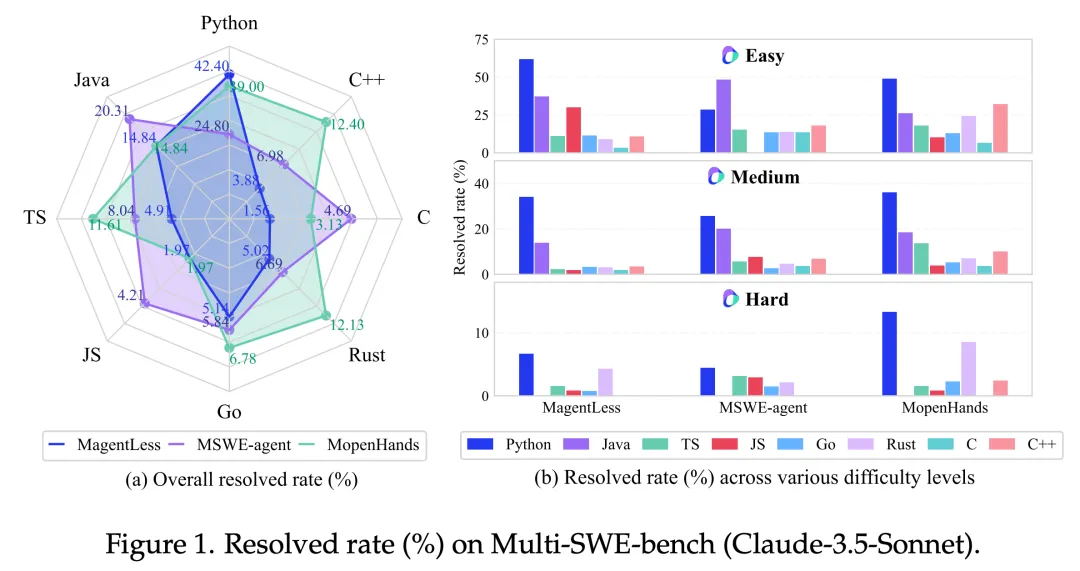
Some mainstream models perform better on Python but score poorly on other languages. Additionally, as task difficulty increases, the model's repair rates exhibit a declining trend.
This highlights that multilingual code repair remains a significant challenge for large models and a core direction for advancing AI toward general-purpose programming agents.
3. A year-long systematic construction with rigorous manual validation
In developing the Multi-SWE-bench, the team designed and executed a systematic data construction process in five stages, covering the entire process from project screening and data acquisition to data verification, to ensure the authenticity, comprehensiveness and usability of the data.
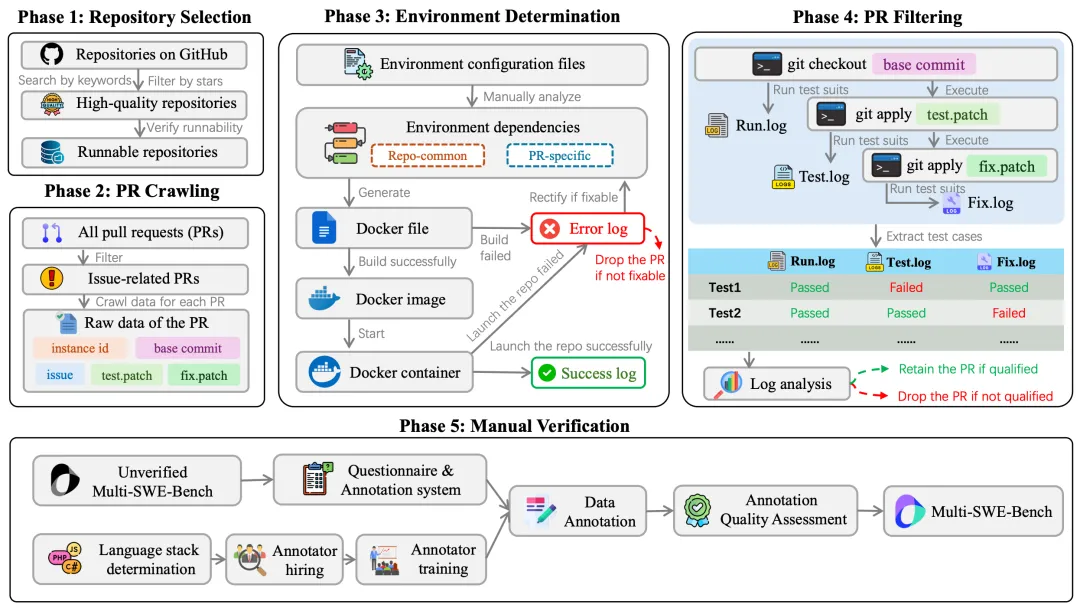
Multi-SWE-bench construction process
Step 1: Open-source repository screening
Based on the GitHub public repository, the team screened high-quality project repositories using multiple criteria to ensure coverage of the 7 major programming languages (Java, TypeScript, JavaScript, Go, Rust, C and C++). Selection criteria include:
(1) More than 500 GitHub Stars with a certain degree of community engagement;
(2) Continuous maintenance for at least six months;
(3) With CI/CD support, allowing for automated building and testing using tools like GitHub Actions;
(4) Reproducible construction processes to ensure seamless environment setup.
Step 2: Pull Request (PR) collection
After the initial screening of repositories, the team collected all PRs from the projects through automated crawlers, applying the following filtering rules:
(1) The PR must be associated with at least one GitHub issue;
(2) Include the modification of test files to ensure that the repair behavior is verifiable;
(3) Has been merged into the main branch, and the code quality and maintainers are fully recognized.
Within each PR record, key information is extracted, including: Original issue description, fix patch, test patch, commit info, etc.
Step 3: Build an executable Docker environment
To ensure that every task in the dataset is fully operational, the team built a Docker container based on each PR, to recreate its runtime environment.
Leveraging CI/CD configurations, README files, and other metadata, dependencies were extracted to auto-generate Dockerfiles. In cases of build failures, the team manually troubleshot errors and made necessary fixes to guarantee the integrity and reproducibility of the environment.
Step 4: PR filtering and dataset production
Each PR runs a three-state test pipeline in sequence in a built environment:
(1) Original state (no patches applied);
(2) Only apply test patches (test.patch);
(3) Apply both the test and fix patches (test.patch + fix.patch) at the same time ;
By analyzing the three-phase test log, the team identifies whether there is an effective repair behavior (such as FAILED→PASSED), and excluded samples that exhibited regression risks or abnormal testing behavior. After this phase, the team eventually retained 2,456 candidate entries.
Step 5: Strict manual verification process
To further improve data integrity, the team introduced a manual dual annotation process. A total of 68 professional annotators participated in the review, all with development experience in the relevant programming languages and highly relevant backgrounds.
Each sample was labeled by two independent annotators and cross-checked. Finally, all the annotated results are subject to random inspection by the internal QA team to ensure consistency and accuracy.
After this stage, we finally retained 1,632 high-quality examples and made all the marked questionnaires and scores publicly available to ensure data transparency.
Through the systematic data construction process, the team hopes to lay a solid foundation for the evaluation and training of future automatic programming agents, and drive related research towards scalability and engineering.
4.Multi-SWE-RL Open Source & Community Recruitment
With the rise of next-generation models such as GPT-4o, o1, o3, the potential of reinforcement learning in automated programming is gaining traction. Based on the judgment that RL will play an important role in the code agent, the Doubao (Seed) team further built the Multi-SWE-RL to provide a unified and standardized data foundation for RL training in the code environment. This not only provides models with "textbooks" for learning but also a "learning environment."
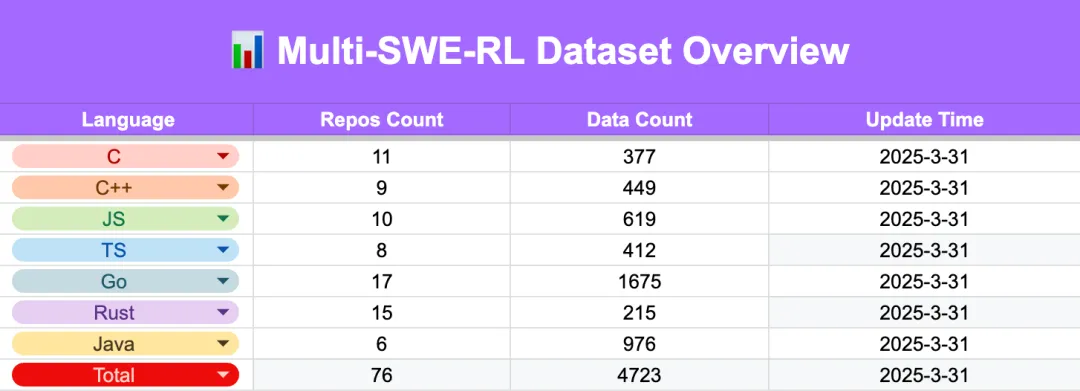
As the first contributor, the team has provided 4,723 instances, each with a reproducible Docker environment that supports one-click startup, automatic evaluation, and fast access to the RL training frameworks. Additionally, the entire data construction process and toolchain have been made fully open-source.
At present, the team is also launching the open-source community project, encouraging developers to participate in the dataset expansion, RL data contribution and new method evaluation. The Multi-SWE-RL project provides detailed contribution tutorials, incentives, and task boards that are updated in real time to ensure effective and transparent community collaboration. All new data and evaluation results will be regularly included in subsequent public releases and will be attributed to all active contributors or authors.
The Doubao (Seed) team is looking forward to working with more developers and researchers to promote the RL for Code ecosystem construction and lay the foundation for building a universal software agent.
Dataset Link:https://huggingface.co/datasets/ByteDance-Seed/Multi-SWE-RL
5. Final Thoughts
The Doubao (Seed) team hopes that Multi-SWE-bench will serve as a benchmark for systematic evaluation of large models in multiple mainstream programming languages and real code environments, promoting the development of automatic programming capabilities in a more practical and engineering direction.
Compared with the previous single language task focusing on Python, Multi-SWE-bench is closer to the real-world multilingual development scenarios and more reflective of the actual capability boundary of the current model in the direction of "automated software engineering".
Looking ahead, the team will continue to expand the coverage of the Multi-SWE series – including adding new languages, expanding more soft tasks, and encouraging more researchers and developers to participate in benchmarking and RL training data contributions through a community co-construction mechanism.
The ByteDance Seed team has always been aiming to explore the endless boundaries of intelligence and unlock the infinite possibilities of universal intelligence.