Seed-Coder Released: A Powerful Family of Open-Source Code Models for Curating Code Data Based on LLMs
Seed-Coder Released: A Powerful Family of Open-Source Code Models for Curating Code Data Based on LLMs
Date
2025-05-19
Category
Technology Launch
Recently, the ByteDance Seed team has unveiled the technical implementation of a model-centric data pipeline designed to produce code pretraining data.
Our research verifies that large language models (LLMs) alone are capable of scoring and filtering code data. This not only unleashes the potential of language models while minimizing human involvement in data curation, but also enhances the coding capabilities of these models.
According to our experiments, Seed-Coder, a family of open-source code models of 8B size trained on the pipeline, excels in code generation and code completion tasks.
To drive progress in related fields with our findings, we have open-sourced Seed-Coder under the permissive MIT License and shared its recipe for curating pretraining data.
Homepage:https://bytedance-seed-coder.github.io
Tech Report:https://github.com/ByteDance-Seed/Seed-Coder/blob/master/Seed-Coder.pdf
GitHub:https://github.com/ByteDance-Seed/Seed-Coder
Models:https://hf.co/collections/ByteDance-Seed/seed-coder-680de32c15ead6555c75b0e4
Hugging Face:https://huggingface.co/ByteDance-Seed/Seed-Coder-8B-Reasoning-bf16
Seed-Coder is now available for download on Hugging Face. We look forward to working with more researchers to boost the performance of large models in code intelligence.
Code data plays a critical role during the pretraining phase of LLMs, not only directly impacting performance on code-related tasks but also contributing significantly to enhancing the general intelligence of LLMs.
Existing publicly available methods for constructing code pretraining datasets rely heavily on manual efforts. However, these approaches are inherently limited in scalability, prone to subjective biases, and costly to extend and maintain across diverse programming languages.
To address these challenges, the ByteDance Seed team has conducted a series of studies since early 2024, gradually developing a model-centric data pipeline to efficiently produce code pretraining data.
Using this pipeline, we trained Seed-Coder to validate its effectiveness.
Seed-Coder is a family of open-source LLMs comprising base, instruct, and reasoning models of 8B size. It achieves state-of-the-art results among open-source models of similar size, demonstrating superior performance in code generation, code completion, code editing, code reasoning, and software engineering tasks.
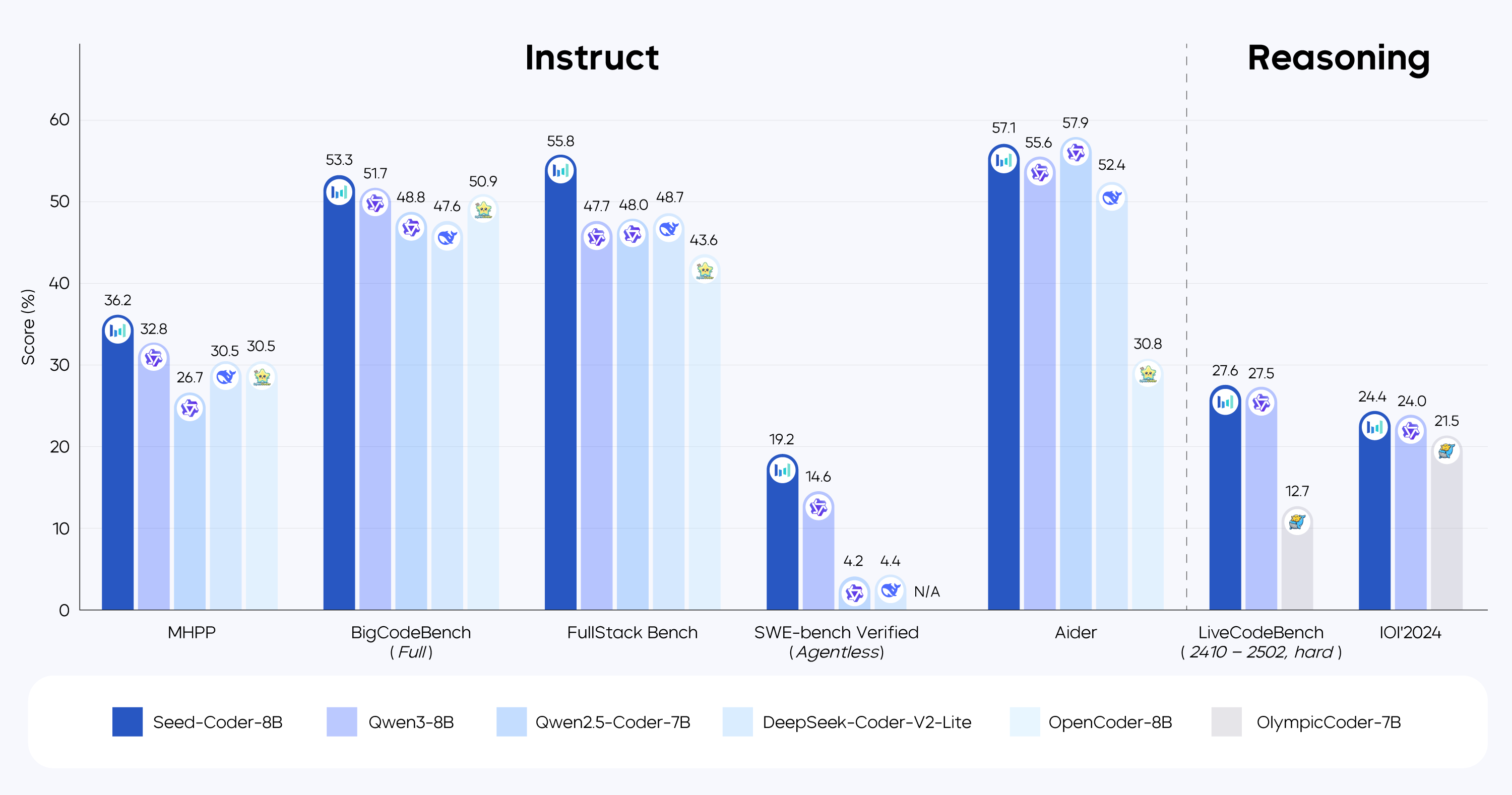
On BigCodeBench, FullStack Bench, and MHPP, Seed-Coder showed a competitive edge among lightweight open-source models.
On SWE-bench Verified, Seed-Coder achieved a resolved rate of 19.2%, demonstrating that small models can play a meaningful role in complex software engineering tasks.
On IOI'2024, Seed-Coder scored 146.5, achieving top-tier performance, together with QwQ-32B (144.0) and DeepSeek-R1 (137.0).
Notably, Seed-Coder achieved an ELO score of 1,553 on Codeforces contests, approaching the level of o1-mini. This demonstrates that small code models trained on high-quality data also possess considerable potential for tackling challenging reasoning tasks.
The data pipeline has now been applied in our flagship models to boost their coding capabilities.
1. "The Bitter Lesson" from Filtering Code Data by Human Effort
Code is the fundamental medium of human-machine interaction. The rapid advancement of LLMs makes it possible to develop software through automatic code generation. Since coding tasks demand comprehensive logical reasoning from models, enhancing the coding capabilities of models is, to some extent, a prerequisite for artificial general intelligence (AGI).
LLMs have demonstrated outstanding performance across a wide range of coding tasks. Among closed-source models, Claude 3.7 Sonnet, OpenAI o3, OpenAI o4-mini, and Gemini 2.5 Pro have demonstrated unprecedented capabilities in code generation, explanation, debugging, editing, and real-world software engineering tasks.
Among open-source models, top performers such as DeepSeek-R1, DeepSeek-Coder-V2, and Qwen2.5-Coder have also shown competitive performance on coding tasks.
Relying on human-designed rules for filtering and cleaning code datasets has been a widely accepted approach to improving code pretraining data quality in the industry. For example, DeepSeek-Coder and Qwen2.5-Coder apply a set of filtering rules as the initial data processing step, following the filtering rules used in StarCoder. OpenCoder also incorporates over 130 hand-crafted filtering rules in their pretraining data pipeline.
However, hand-crafted rules are prone to conflicts and subjective biases, and their scalability is limited. They are also costly to extend and maintain across diverse programming languages.
We believe that these limitations resonate with the insights from the widely cited essay "The Bitter Lesson" by Richard Sutton, the Turing Award laureate:
AI researchers often favor human-centric methods due to their short-term advantages... but breakthrough progress eventually arrives by the opposing approach based on scaling computation by search and learning.
The eventual success is tinged with bitterness, and often incompletely digested, because it is success over a favored, human-centric approach.
In the context of code pretraining data, the human-centric approaches appear particularly favorable, since many AI researchers are skilled programmers themselves and feel confident in evaluating code quality. Nevertheless, human-centric methods would ultimately prove restrictive and tend to impede advancements of code LLMs in the long run.
During preliminary research, we found that compared to human-centric approaches, the use of LLMs is particularly advantageous, as they effectively capture nuanced standards of code quality that are difficult to quantify explicitly, and provide scalable, self-contained evaluations capable of processing billions of samples consistently.
Below are two real-world examples illustrating cases where LLM filters outperform traditional rule-based filters.

Left: This Python snippet is incorrectly dropped by rule-based filters due to a high numeric-character ratio. In contrast, LLM filters identify that the code serves a meaningful purpose: showing a Pikachu image on an LED display.
Right: This visually well-structured Python script passes rule-based filters. However, LLM filters identify a logical error (if temp < 0 and temp > 1) and an inconsistent docstring (it claims to return a string but actually returns None), accurately rejecting this low-quality code.
Based on these findings, we designed our model-centric data pipeline, which significantly reduces reliance on human effort. Seed-Coder demonstrates that, with minimal human effort, LLMs can effectively curate code training data by themselves to drastically enhance coding capabilities. "The Bitter Lesson" holds true — this time in code LLMs!
2. Model-centric Data Pipeline
This work aims to research, share, and advance technologies related to code generation. To this end, we only collected publicly available data that does not contain any personal information. Upon completion of the research, we open-sourced Seed-Coder and shared its recipe for curating pretraining data, covering the processing and filtering of GitHub code, GitHub commits, and code-related web data.
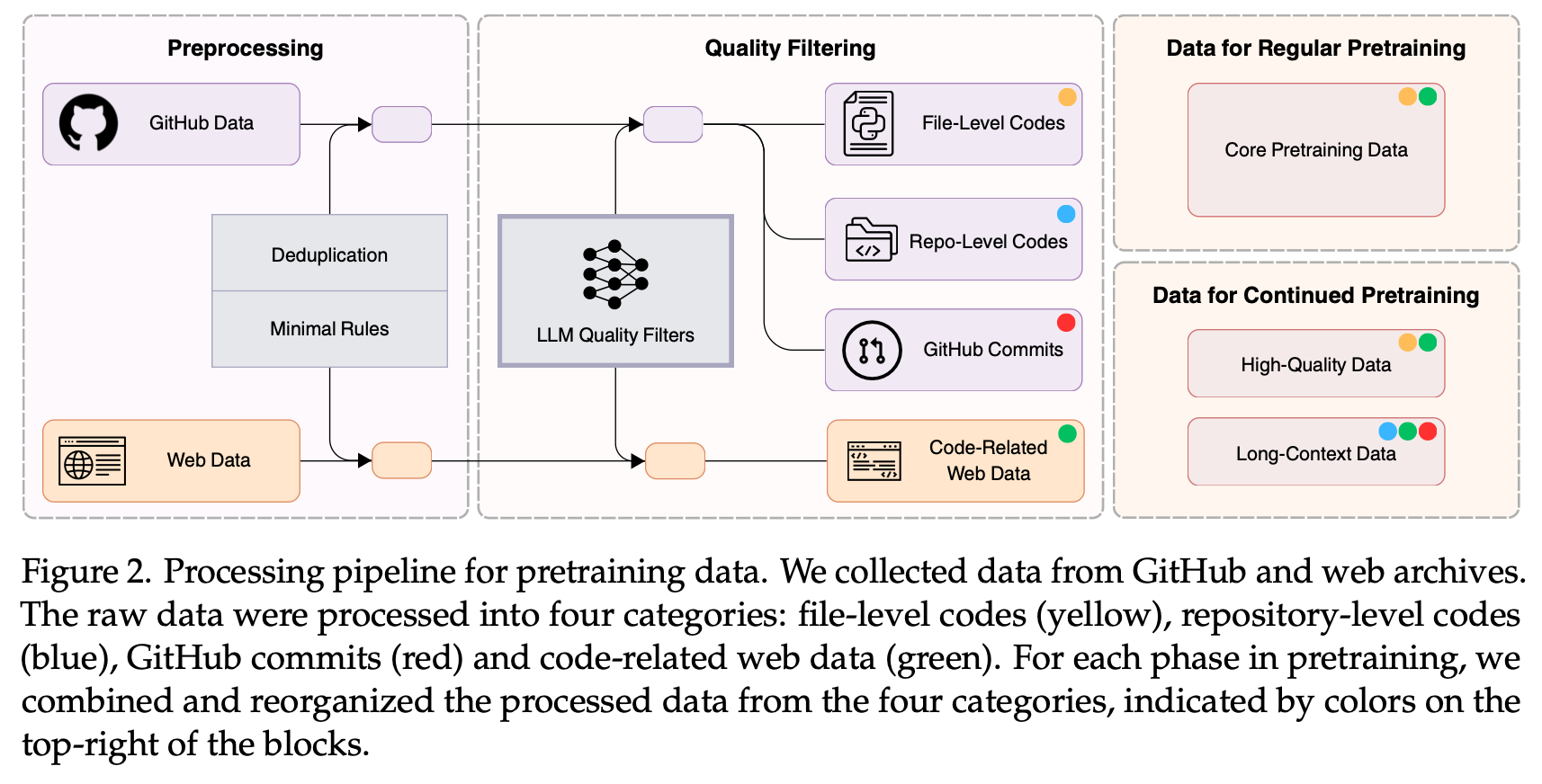
Our LLM filters evaluate code quality from four dimensions: readability, modularity, clarity, and reusability.
To extend the coverage of LLM filters over public GitHub data, we fine-tuned a pretrained small model (1.3B) of Llama 2 structure with a regression head for one epoch as an efficient quality scorer.
The diagram below illustrates the pipeline of our GitHub code quality scorer:
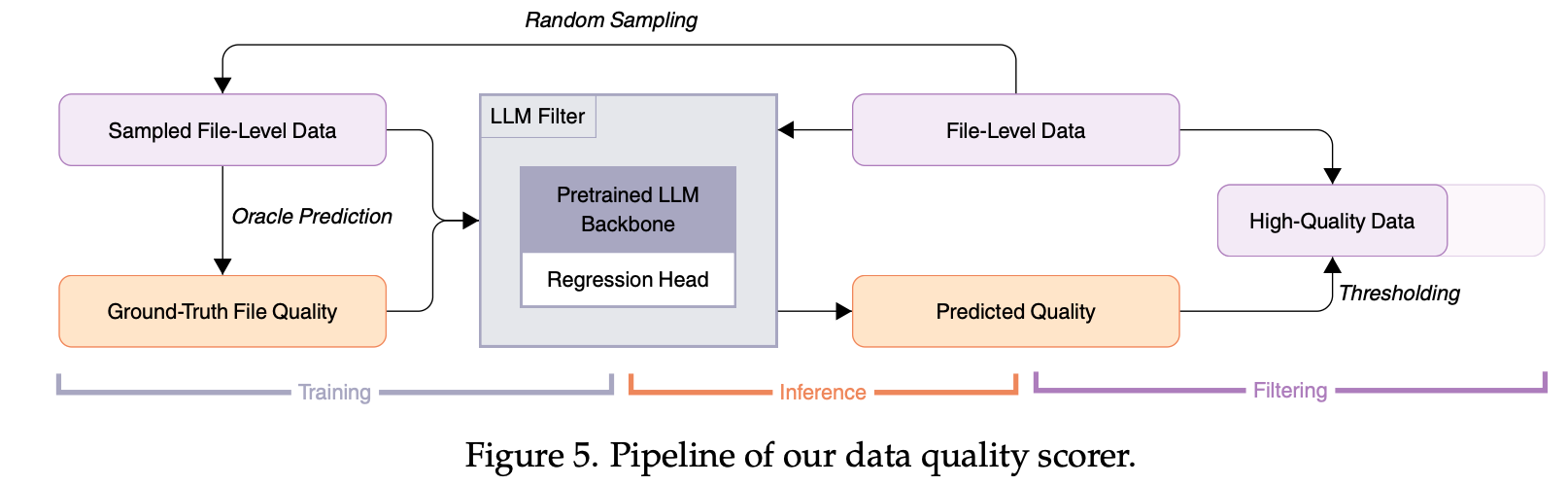
This way, we curated a code pretraining corpus comprising a total of 6 trillion tokens—5 trillion tokens for regular pretraining and 1 trillion tokens for continued pretraining.
Our ablation studies show that code data curated by LLM filters significantly improves the coding performance of the pretrained models.
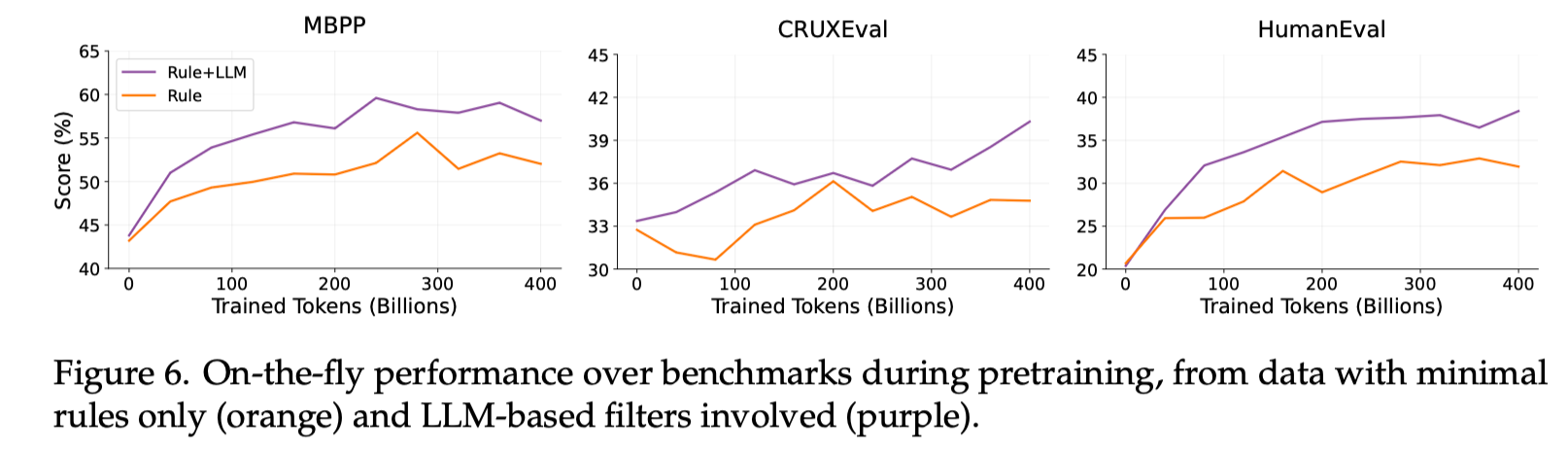
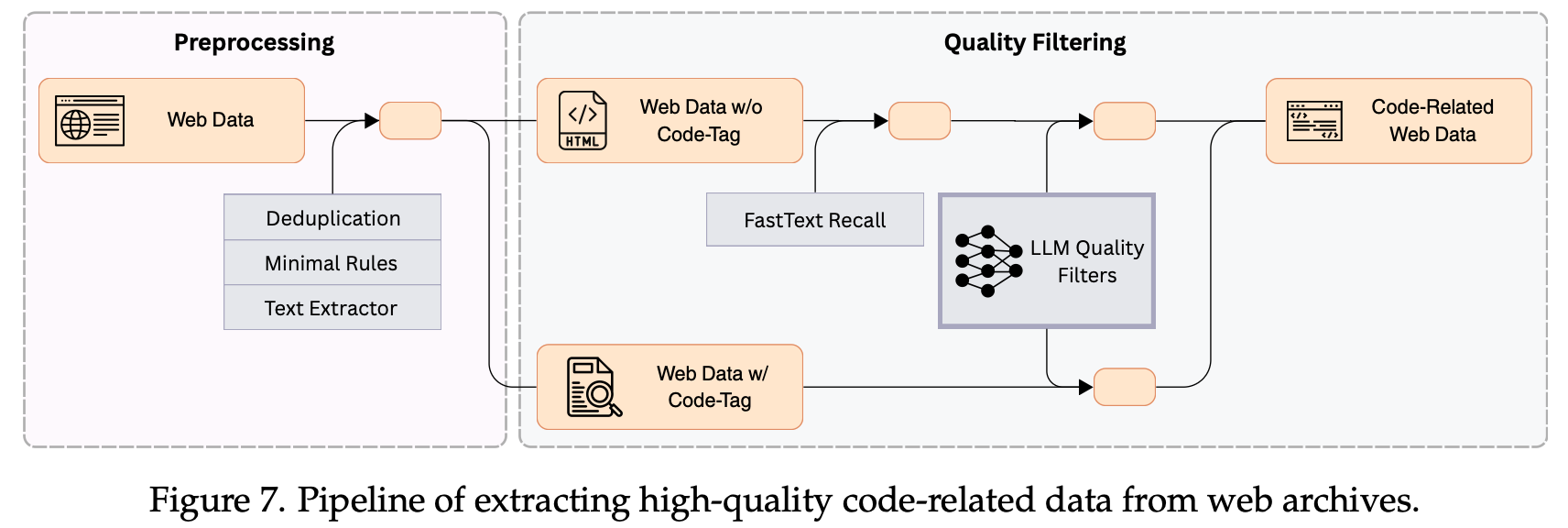
By filtering and cleansing, the model-centric data pipeline also extracted high-quality code-related data (1.2 trillion tokens) from extensive web data. The diagram below shows the data extraction process:
3. Post-Training Data Recipe for Seed-Coder
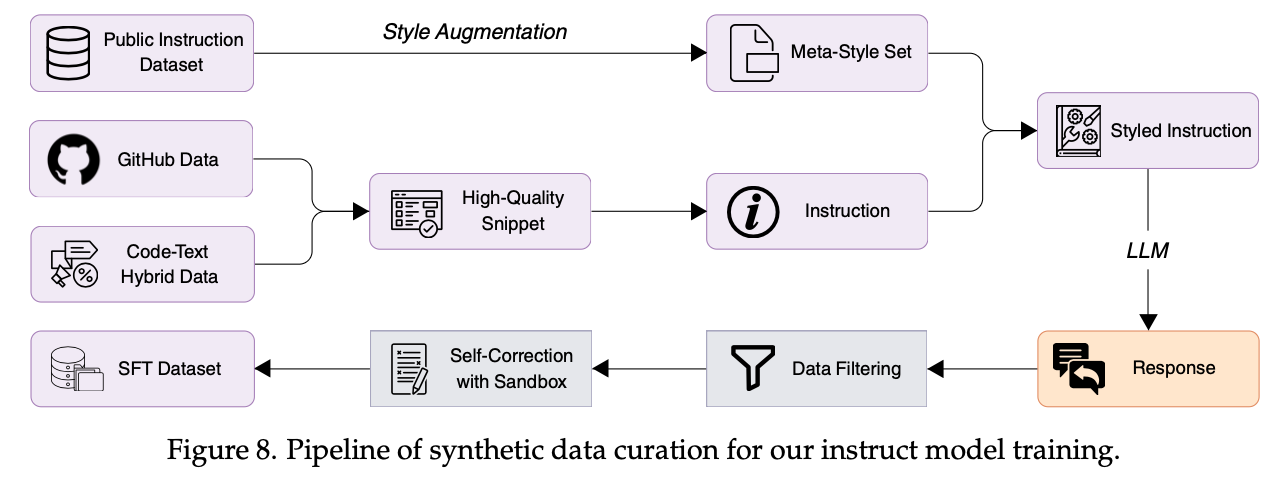
Building upon the pretrained base model Seed-Coder-Base, we conducted post-training, including instruction tuning to build the instruct model Seed-Coder-Instruct, and reinforcement learning (RL) to develop the reasoning model Seed-Coder-Reasoning.
The instruct model is further trained via supervised fine-tuning and preference optimization, and the reasoning model leverages Long-Chain-of-Thought (LongCoT) RL to improve multi-step code reasoning.
During instruction tuning, we focused on the following three aspects:
- Diversity: We leveraged LLMs to generate code instructions in varying styles, thereby enhancing the diversity of the training data.
- Quality: We employed a combination of syntax rule-based and LLM-based techniques to filter out low-quality responses.
- Difficulty: We used an LLM to tag prompts/problems, removing simple ones and retaining challenging ones.
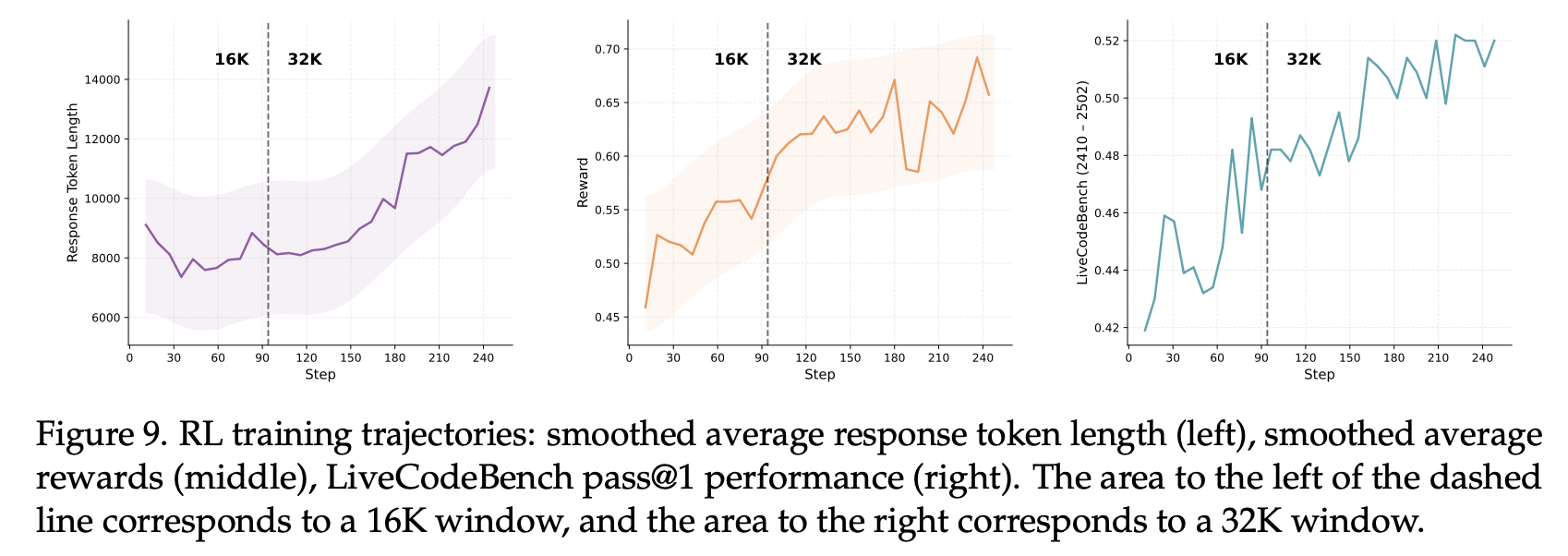
During the RL training process of the reasoning model, we used the open-source veRL framework and adopted the following practical training techniques:
-
Optimized curriculum learning: We filtered out simple problems that already had high accuracy and progressively increased the problem difficulty during training.
-
Progressive exploration strategy: During training, we gradually increased the sequence length and the number of rollouts, enabling the model to learn more effectively over time.
4. Performance Evaluation of Seed-Coder Models
We comprehensively evaluated the three Seed-Coder models across widely adopted coding benchmarks. Here, we present only part of the results. For complete evaluation results, please refer to the tech report.
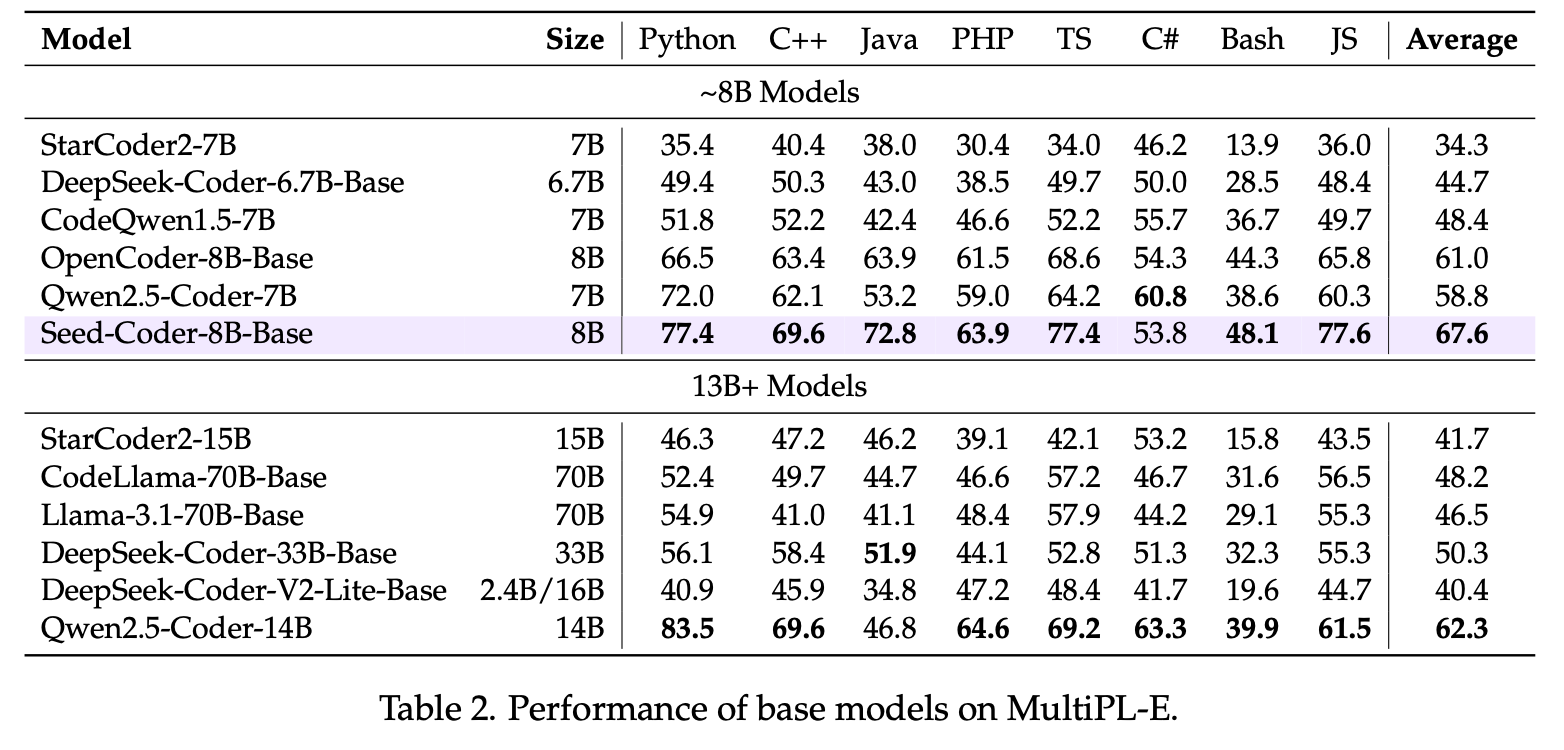
Seed-Coder-8B-Base demonstrated strong performance across various code generation and code completion tasks.
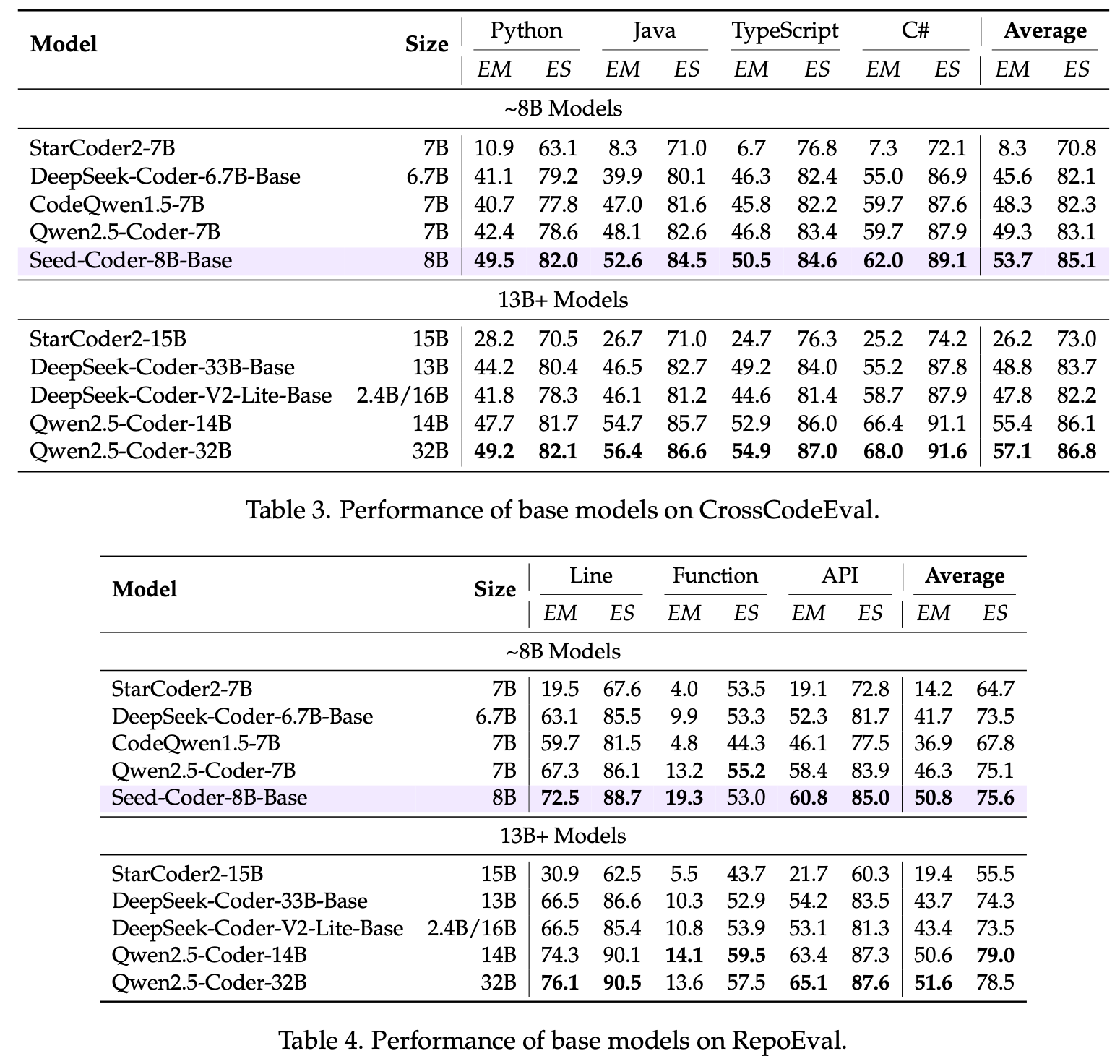
Seed-Coder-8B-Instruct delivered competitive performance in a wide range of coding tasks, outperforming models of similar size in real-world, complex software engineering tasks on SWE-bench.
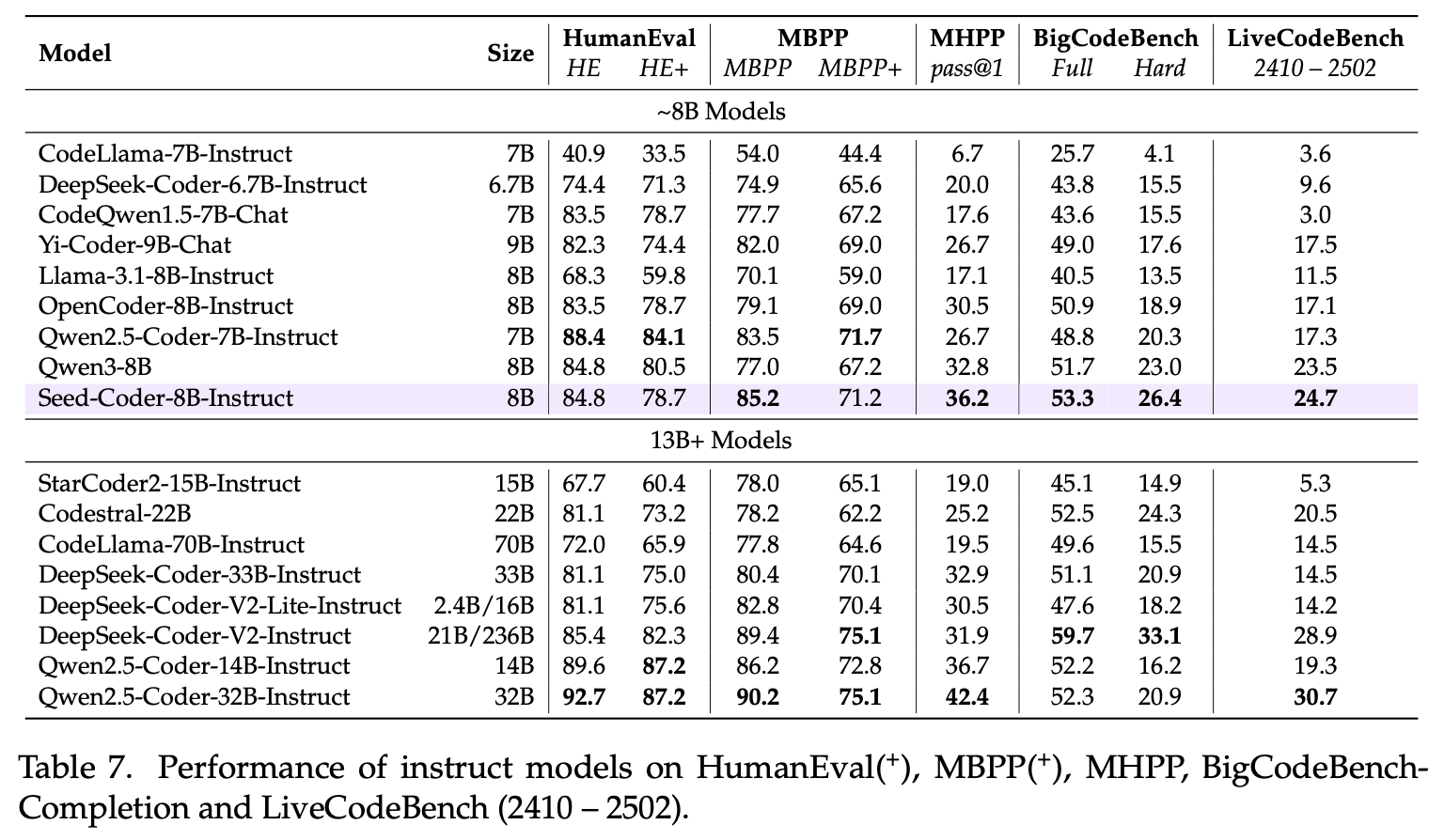
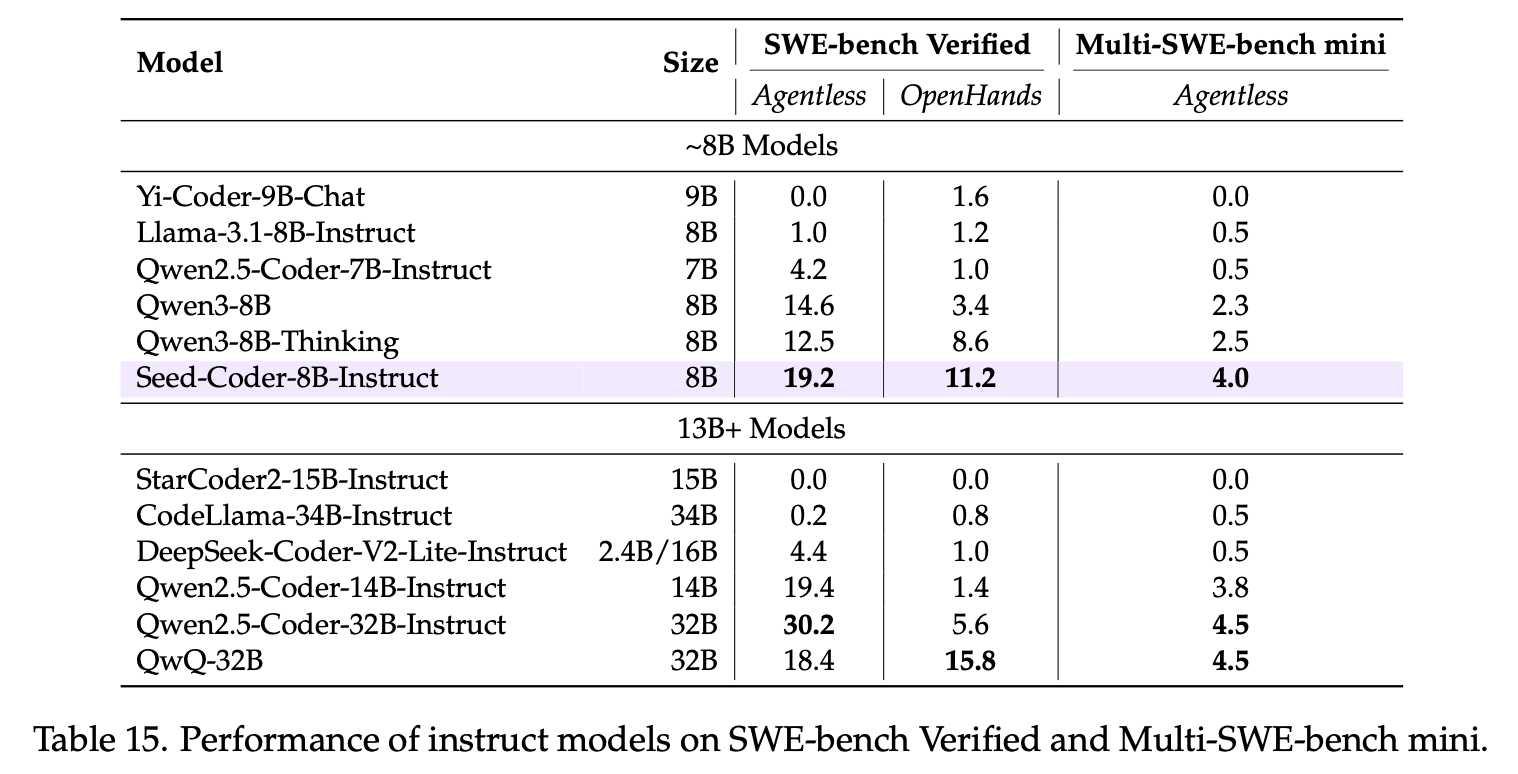
Seed-Coder-8B-Reasoning achieved impressive performance in competitive programming. It achieved an ELO score of 1,553 on Codeforces contests, closely matching that of o1-mini. This highlights the potential of small models to effectively handle complex reasoning tasks.
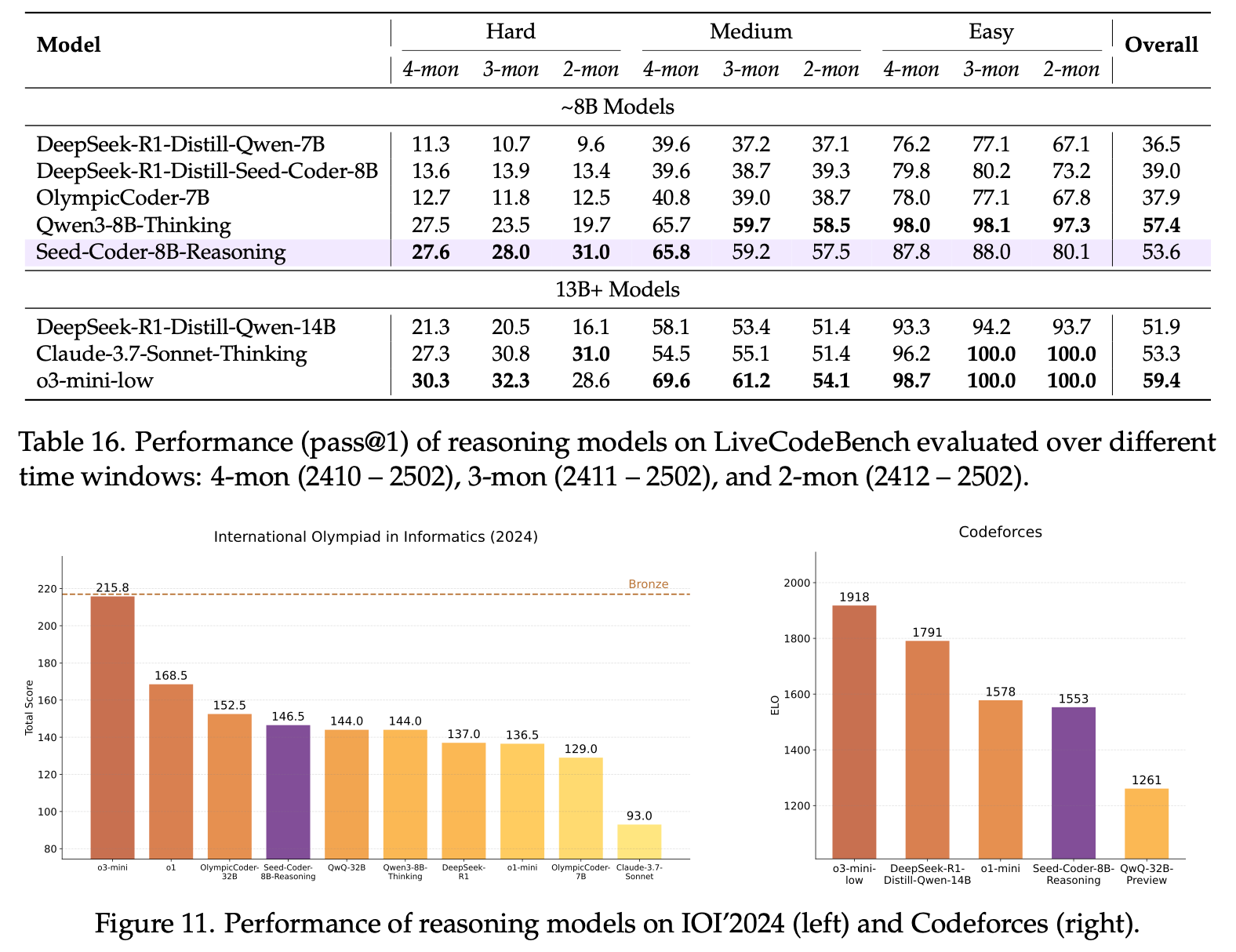
The model was released with a default FP32 precision. In response to external user feedback, we have recently made a BF16 version available on Hugging Face. Both versions support a 64K context window. Click here to try it out.
5. Conclusion
As a family of research-oriented open-source models, Seed-Coder is designed to verify strategies for curating code data. Therefore, we pretrained it solely on our curated code dataset comprising 6 trillion tokens. Compared to leading open-source general-purpose models (such as Qwen3, pretrained on 36 trillion tokens), its general natural language understanding and ability to handle broader tasks remain limited.
As language models continue to evolve, we believe that cutting-edge LLM filters will further improve the quality of code data, thereby enhancing the coding capabilities of general-purpose models.
Building on these insights, we will explore how code data can bring greater benefits to general-purpose models, and the impact of data and model scaling on AI coding performance.