Seed Research|BAGEL: The Open-Source Unified Multimodal Model - An All-in-One Model!
Seed Research|BAGEL: The Open-Source Unified Multimodal Model - An All-in-One Model!
Date
2025-05-28
Category
Models

BAGEL is the latest open-source multimodal foundation model from ByteDance's Seed team, supporting unified understanding and generation of text, images, and videos. Through experimental research, the team discovered that as the cross-modal interleaved pretraining data expanded, the model demonstrated emergent enhanced capabilities in complex reasoning and compositional abilities, laying the foundation for broader and more general-purpose multimodal functionalities.
In multiple public multimodal understanding and generation benchmarks, BAGEL significantly outperforms previous open-source unified models. Additionally, BAGEL not only supports core features provided by advanced closed-source models - such as visual understanding, image editing, and style transfer - but also offers additional capabilities like 3D spatial navigation.
Official website and demo: https://seed.bytedance.com/bagel
GitHub repository: https://github.com/bytedance-seed/BAGEL
Model Weights: https://huggingface.co/ByteDance-Seed/BAGEL-7B-MoT
Research paper: https://arxiv.org/pdf/2505.14683
Unifying multimodal understanding and generation has been a key focus in the field. However, existing academic research models have primarily focused on training with standard image-text paired data, still showing a notable performance gap compared to proprietary industrial models like GPT-4o and Gemini 2.0.
The team believes that the key to bridging this gap lies in training with well-structured interleaved multimodal data to enhance model performance on complex multimodal tasks. Additionally, existing models are often constrained by their architectural limitations, making scalability challenging. Therefore, developing architecture-agnostic, scalable multimodal models remains another crucial research direction.
Based on these insights, the team has open-sourced BAGEL to share their research explorations with the AI community.
BAGEL Ranks #1 on Hugging Face Trending
BAGEL is a Unified Multimodal Model for both understanding and generation with 7B activated parameters (14B total parameters). It adopts the MoT (Mixture-of-Transformer-Experts) architecture and is pre-trained on large-scale interleaved text, image, video, and web data.
Experiments show that as the training data expands, BAGEL not only enhances its core multimodal understanding and generation capabilities but also demonstrates emergent complex compositional abilities, including long-text reasoning combined with multimodal generation, free-form image editing, future frame prediction, 3D space manipulation, and world navigation.
BAGEL Demo Video
1. BAGEL Capability Showcase: All-in-One Multimodal Model
Chat
BAGEL is pre-trained on large language models, providing it with foundational capabilities for reasoning and conversation. BAGEL can handle both image and text inputs and outputs in a mixed format.
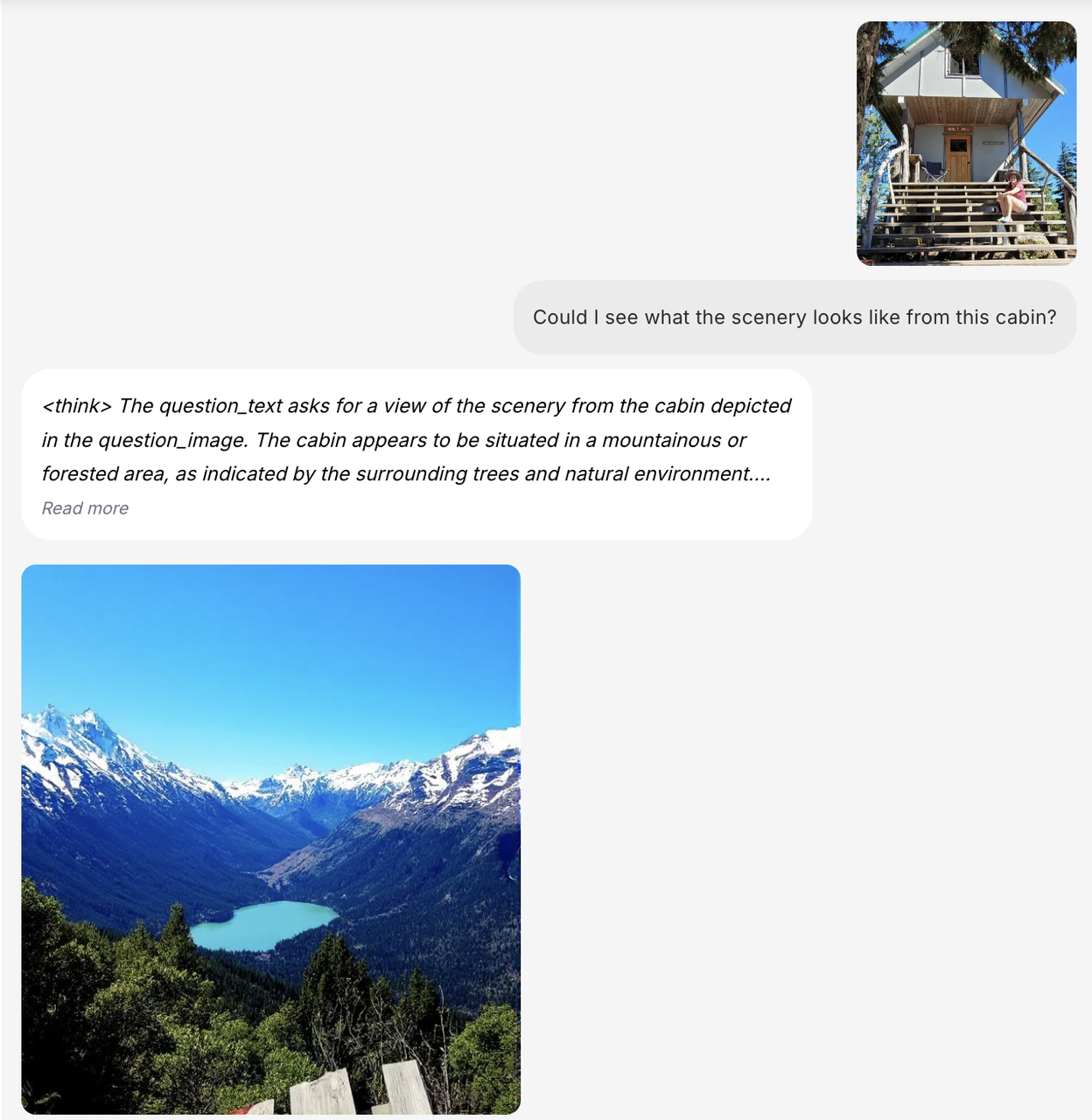
Mixed input - mixed output
Generation
BAGEL can generate high-fidelity, photorealistic images, or interleaved image-text content. It adopts the CoT(Chain-of-Thought) method, allowing the model to "think" before generating visual outputs.

BAGEL is able to "think" before generating a crocodile plushie wearing a sweater
Editing
By pre-training on interleaved video clips, BAGEL naturally learns to preserve visual identities and fine details, while also capturing complex visual motion from videos - making it highly effective for image editing.


Image editing based on the same character
Style Transfer
With its deep understanding of visual content and styles, BAGEL can easily transform an image from one style to another - or even shift it across entirely different worlds - using only minimal alignment data.

BAGEL performs multiple style transfers
Navigation
Furthermore, BAGEL demonstrates fundamental world modeling capabilities, enabling it to perform more challenging tasks such as world navigation, future frame prediction, and 3D world generation, along with rotation and viewpoint switching from different angles. Additionally, BAGEL exhibits strong generalization abilities, successfully navigating not only through various real-world scenarios but also in games, artworks, and animated cartoons.
Example 1:Real-world
Example 2:Game
Example 3:3D rotation
Composition
Building upon these capabilities, BAGEL can leverage a unified multimodal interface to achieve complex combinations of its various abilities, enabling multi-turn conversations.

Image cropping - Smart editing - Scene transformation - Style transfer Compositional abilities
2. The "Three-Stage Law" of BAGEL's Emergent Capabilities
BAGEL employs a Mixture-of-Transformer-Experts (MoT) architecture to maximize its learning capacity from rich multimodal information. Specifically, the model consists of two Transformer experts: one focused on multimodal understanding and another on multimodal generation. Correspondingly, it utilizes two independent visual encoders - the Und Encoder and Gen Encoder - to capture pixel-level and semantic-level image features respectively.
BAGEL's overall design framework follows the "Next-Token-Prediction" paradigm, enabling continuous self-optimization.
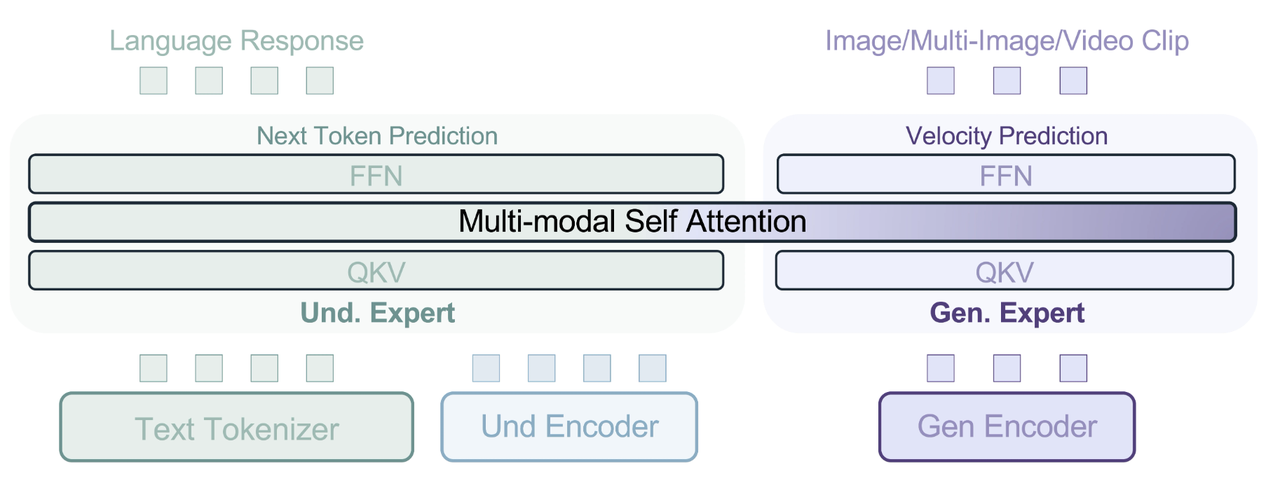
BAGEL Model Architecture
Leveraging the unified MoT architecture and massive interleaved cross-modal data, BAGEL demonstrates an intelligence evolution trajectory that surpasses similar models in both understanding and generation, across images and videos. Through multiple authoritative benchmark tests (VLM Benchmark, GenEval, GEdit, and IntelligentBench), the team has identified BAGEL's capability emergence in "three stages."
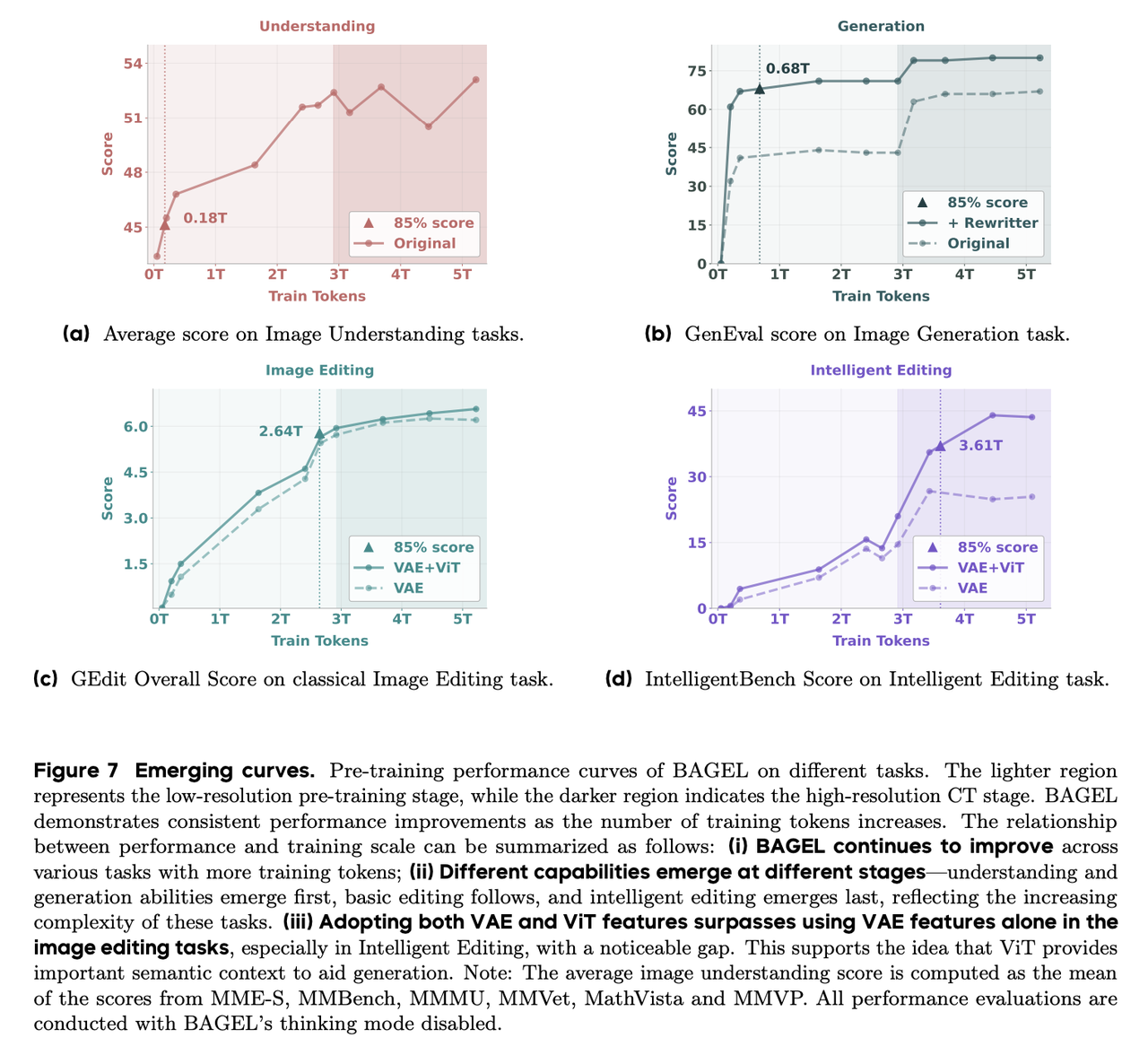
Stage one: Emergence of fundamental capabilities
The model first masters the "basics" of multimodality - understanding image-text relationships and text-to-image generation. As shown, BAGEL achieves decent image generation quality at approximately 1.5T tokens. However, capabilities like precise text rendering and fine image detail adjustment had not fully emerged, becoming key breakthrough points for subsequent development.

Stage two: Emergence of traditional editing capabilities
As training progresses to 2.5T-3.5T tokens, BAGEL begins to master various basic editing techniques, enabling flexible local image modifications based on natural language instructions. Image editing quality continuously improves during this stage, particularly achieving harmony between detail preservation and local redrawing, demonstrating strong cross-modal understanding and manipulation capabilities.

Stage three: Emergence of complex control and reasoning capabilites
With further expansion in data and parameters, the model suddenly exhibits unprecedented complex abilities, including:
- Free-form Image Manipulation: Understanding complex, open-ended editing instructions for precise and creative image modifications.
- Future Frame Prediction: Accurately predicting future scenes given initial video frames, demonstrating understanding of dynamic worlds.
- 3D Space Operations: Achieving precise 3D object rotation and viewpoint adjustments.
- World Navigation: Easily comprehending and executing spatial movement instructions in virtual environments, showing strong spatial awareness.
As shown, intelligent editing capabilities only began to emerge intensively "after 3.5T tokens," distinct from earlier image generation and basic editing capabilities, marking BAGEL's crucial step toward becoming a "world modeling agent".

3. Performance Evaluation: Superior Multimodal Understanding and Generation Compared to Existing Open-Source Models
To comprehensively evaluate model performance, the team referenced existing benchmarks for multimodal understanding, T2I generation, and image editing. However, effective evaluation strategies for complex editing capabilities requiring stronger reasoning are still lacking. Therefore, in addition to utilizing existing benchmarks, the team designed a new editing benchmark incorporating more complex and intelligence-demanding tasks to test model performance.
Multimodal understanding capabilities
BAGEL demonstrates outstanding performance across multiple visual understanding benchmarks, achieving higher average scores than existing open-source models on tasks such as MME-S, MMBench, MMMU, MM-Vet, MathVista, and MMVP, surpassing recently released models including MetaMorph, MetaQuery, and Janus-Pro.
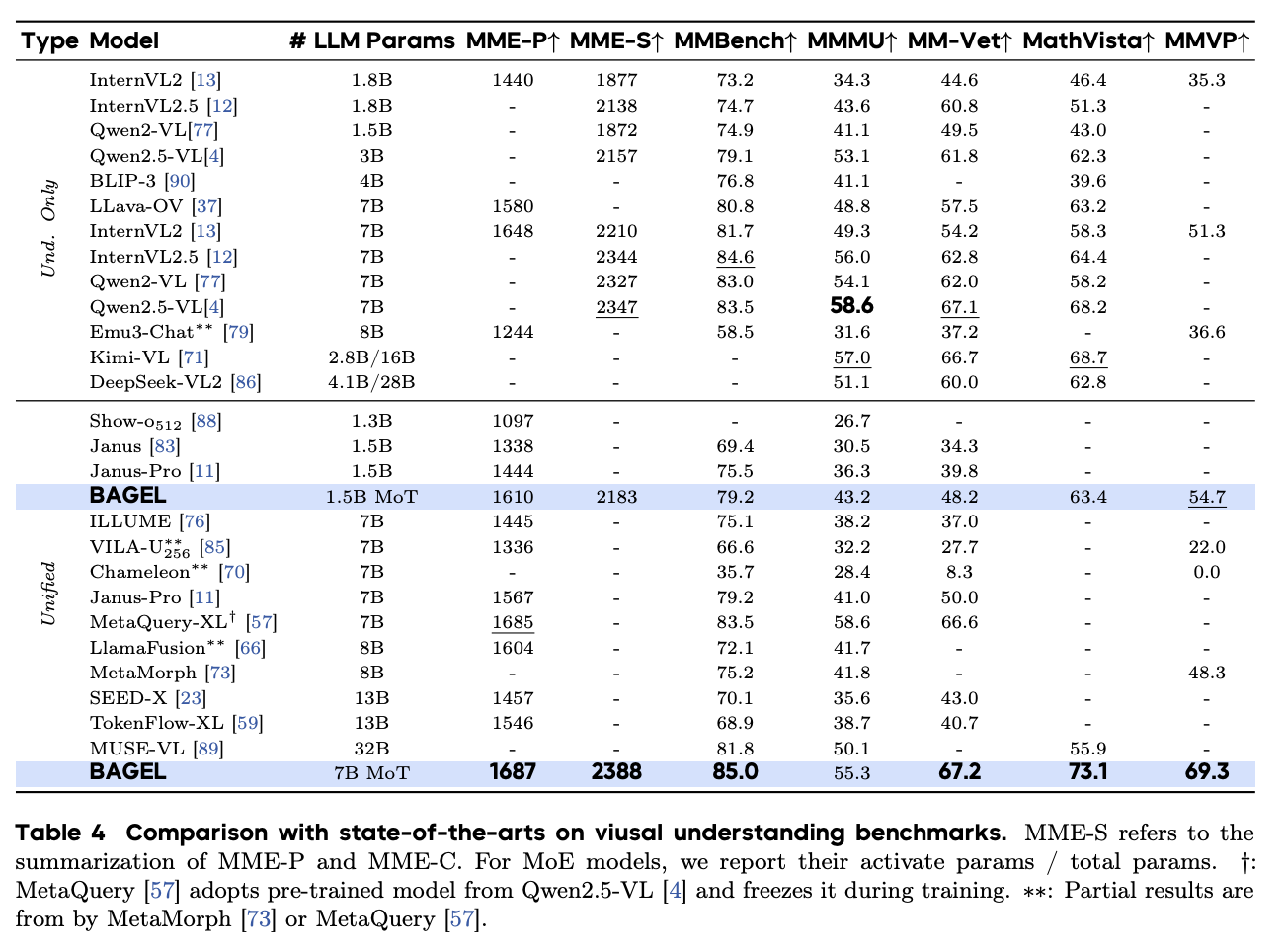
Image generation capabilities
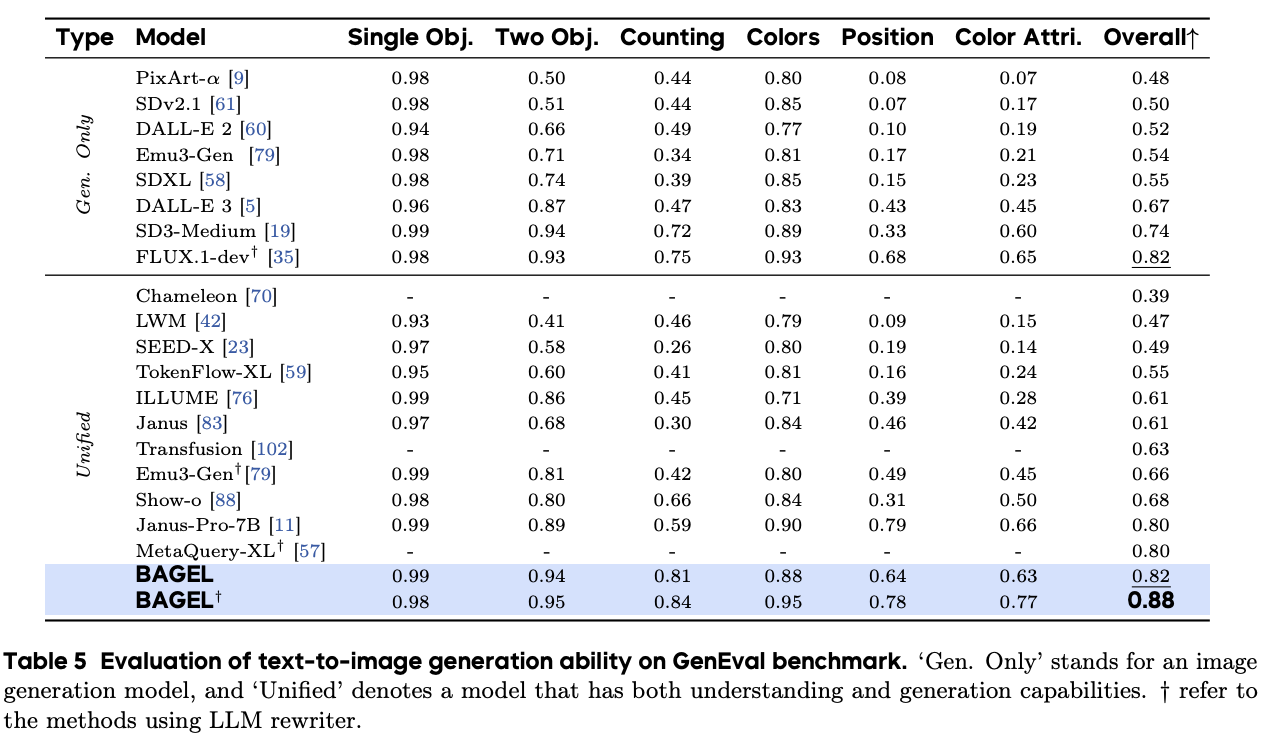
In the GenEval benchmark, BAGEL achieved an overall score of 88%, exceeding both specialized open-source generation models (such as FLUX-1-dev: 82% and SD3-Medium: 74%) and other unified open-source models (such as Janus-Pro: 80% and MetaQuery-XL: 80%).
Additionally, in the WISE benchmark, BAGEL's performance ranks second only to the leading closed-source model GPT-4o.
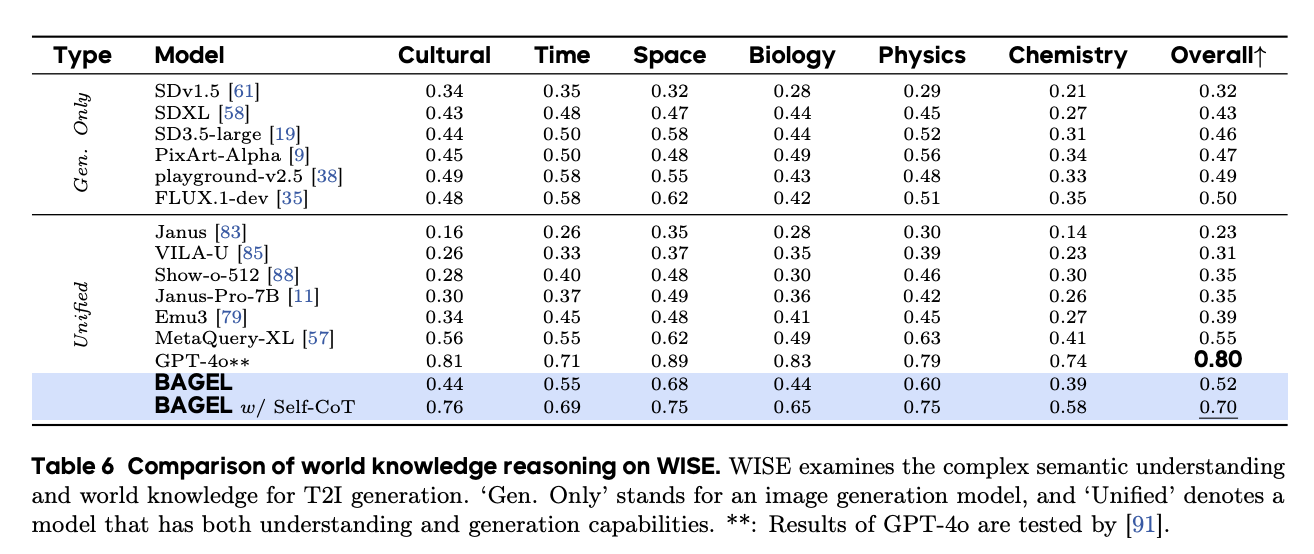
Image editing capabilities
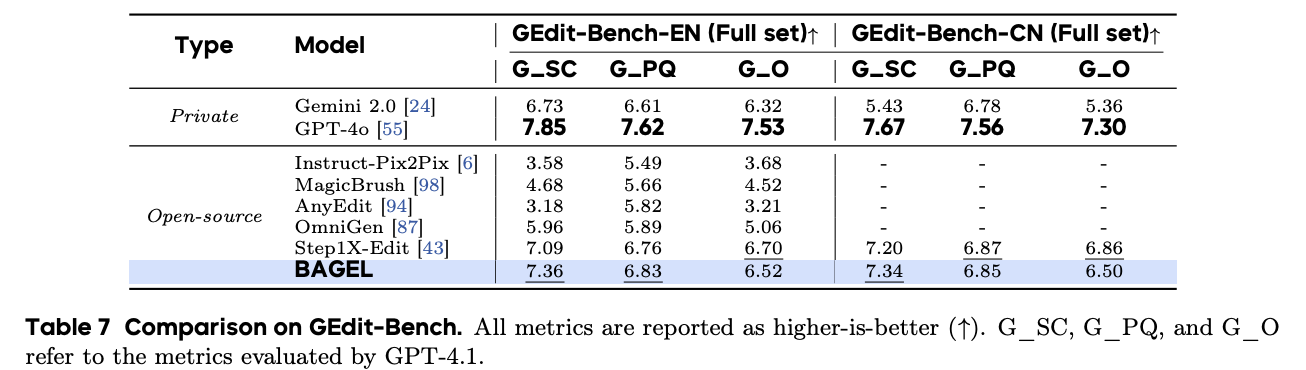
On GEdit-Bench, BAGEL performs comparably to the current leading image editing model Step1X-Edit and surpasses Gemini 2.0.
On IntelligentBench, BAGEL scored 44.9, outperforming the Step1X-Edit model (14.9).

Reasoning-enhanced editing and generation capabilities
With the addition of Chain of Thought (CoT) reasoning, BAGEL's score on WISE increased to 0.70, a 0.18 improvement over the non-CoT BAGEL model. In the IntelligentBench image editing task, the score improved from 44.9 to 55.3. This demonstrates that incorporating the chain of thought significantly enhances the model's capabilities in tasks requiring world knowledge and multi-step complex reasoning.
Visual comparisons
Visual comparisons between BAGEL and mainstream models:

Currently, the Seed team has fully released BAGEL's model weights, code, and demonstration platform, welcoming user experience and feedback.