Introduction to Techniques Used in Seed1.6
Introduction to Techniques Used in Seed1.6
Date
2025-06-25
Category
Models
Seed1.6 is the latest general-purpose model series unveiled by the ByteDance Seed team. It incorporates multimodal capabilities, supporting adaptive deep thinking, multimodal understanding, GUI-based interaction, and deep reasoning with a 256K context window. Seed1.6 is now available through the open API of Volcano Engine. You can try it out via the links provided at the end of this article.
In Seed1.6, we introduced Adaptive Chain-of-Thought (AdaCoT), a novel technique for initiating thinking processes adaptively based on question difficulty. This adaptive approach enables a better trade-off between model effectiveness and reasoning performance.
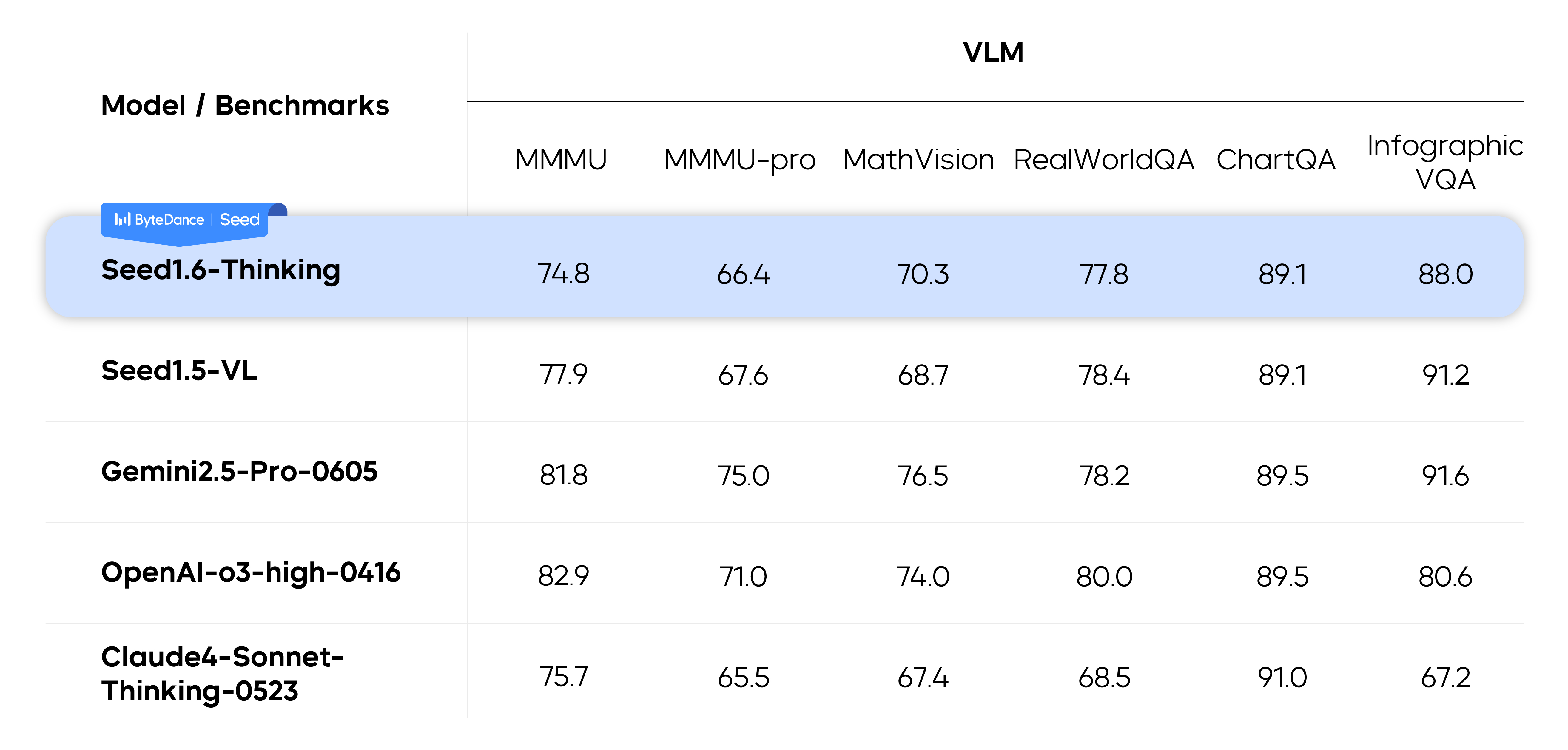
Seed1.6 models demonstrated competitive performance across diverse benchmarks. They matched or even outperformed Seed1.5-VL in multiple visual tasks, while also achieving high scores in generalization tests such as college entrance exams in China and abroad.
Incorporate Multimodal Capabilities During Pre-training, Support a 256K Context Window
Building on the sparse Mixture of Experts (MoE) research from Seed1.5, Seed1.6 was pre-trained using 23B active parameters and 230B total parameters. It incorporated multimodal capabilities to support both textual and visual data during continual pre-training, which consists of the following stages:
- Stage 1: Text-only pre-training. At this stage, we used web pages, books, papers, code, and other data for training. To enhance data quality and knowledge density, we employed a combination of rule-based and model-driven strategies for data cleansing, filtering, deduplication, and sampling.
- Stage 2: Multimodal mixed continual training (MMCT). At this stage, we increased the proportion of discipline-specific content, code, and reasoning-focused data to further boost textual knowledge density and reasoning complexity. Simultaneously, we introduced high-quality visual data for mixed modal training alongside text.
- Stage 3: Long-context continual training (LongCT). At this stage, we used long-context data of varying lengths to progressively extend the model's maximum sequence length from 32K to 256K.
Seed1.6 Base, benefiting from continuous optimizations to its model architecture, training algorithm, and infrastructure, demonstrated substantial performance improvements over Seed1.5 Base at a comparable parameter scale. These enhancements laid a solid foundation for subsequent post-training.
The table below shows the performance of Seed1.6 Base in LLM evaluations.
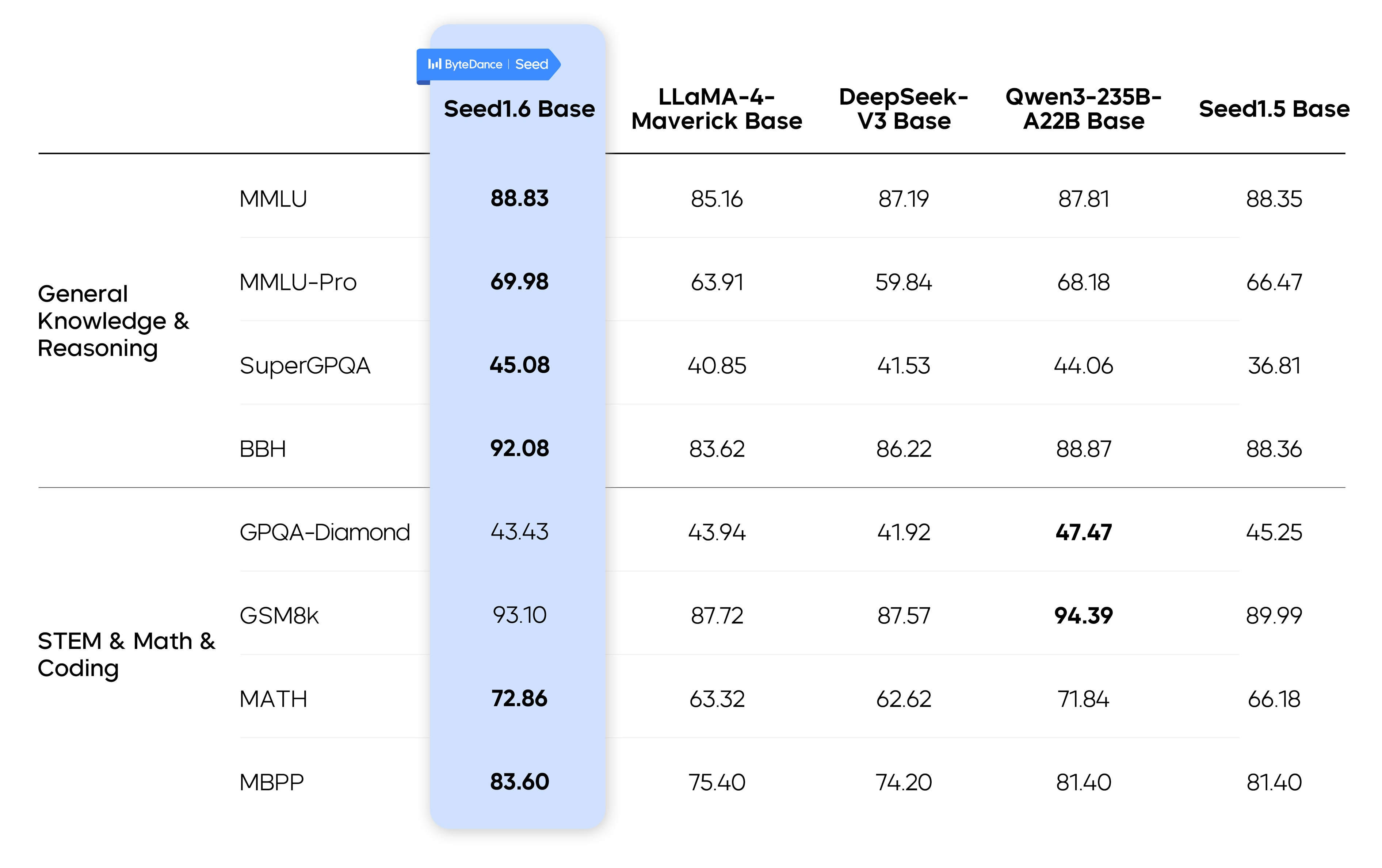
Note: Performance data of external models is sourced from the Qwen Technical Report.
Enhance Reasoning Capabilities During Post-training, Compress CoTs Using Adaptive CoT
Building on the efficiently pre-trained base model, we developed two variants during post-training: Seed1.6-Thinking and Seed1.6 (Adaptive CoT). Seed1.6-Thinking incorporates vision language model (VLM) capabilities, enabling superior reasoning through extended thinking processes. Seed1.6 (Adaptive CoT) leverages the AdaCoT technique to compress CoT length while maintaining effectiveness, striking a better dynamic balance between performance and effectiveness. Looking ahead, we strive to develop more intelligent models that integrate superior reasoning and adaptive thinking.
Multimodal Thinking
Seed1.6-Thinking was trained similarly to Seed1.5-Thinking. During the training, we adopted multi-stage rejection fine-tuning (RFT) and reinforcement learning (RL) for continual optimizations. The model started each round of RL from the point where the last round of RFT ended, using a multi-dimensional reward model to select the best answer from the candidates filtered during RFT.
We developed Seed1.6-Thinking based on Seed1.5-Thinking with greater training compute and larger high-quality training datasets, including math problems, code, puzzles, and non-reasoning data. This enhances the model's CoT capabilities for complex problems. We also integrated VLM capabilities into Seed1.6-Thinking to bring accurate visual understanding to the model. As a result, Seed1.6-Thinking demonstrates considerable performance improvement over Seed1.5-Thinking in both complex textual reasoning and visual reasoning.
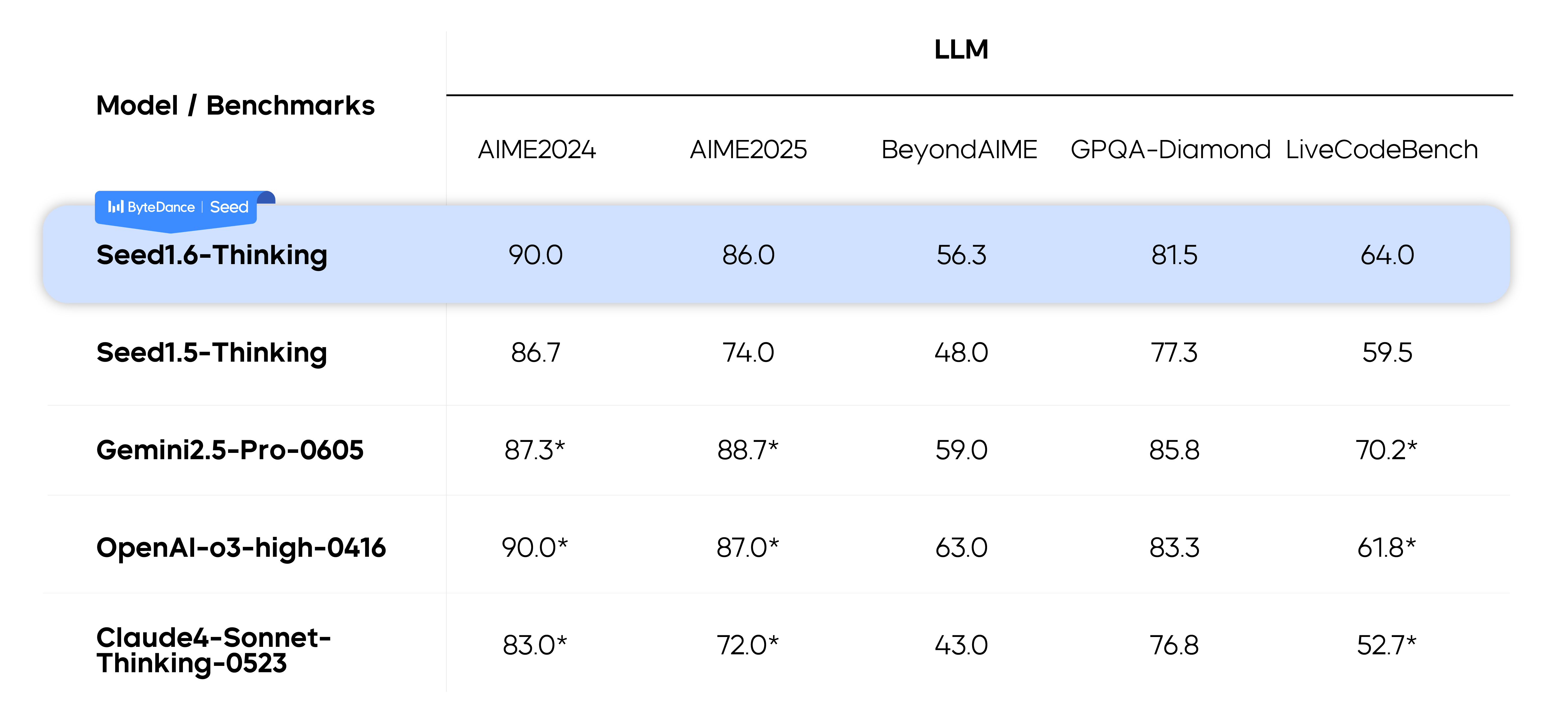
Note: Test results marked with an asterisk (*) are provided by the ByteDance Seed team.
To further enhance thinking, Seed1.6-Thinking leverages parallel decoding. This training-free approach expands the model's capability, allowing it to use more thinking tokens before responding. Our findings demonstrate that parallel decoding significantly improves the model's performance on challenging tasks. For example, on the challenging math dataset BeyondAIME, Seed1.6-Thinking scored 8 points higher and showed notable performance gains in coding tasks.
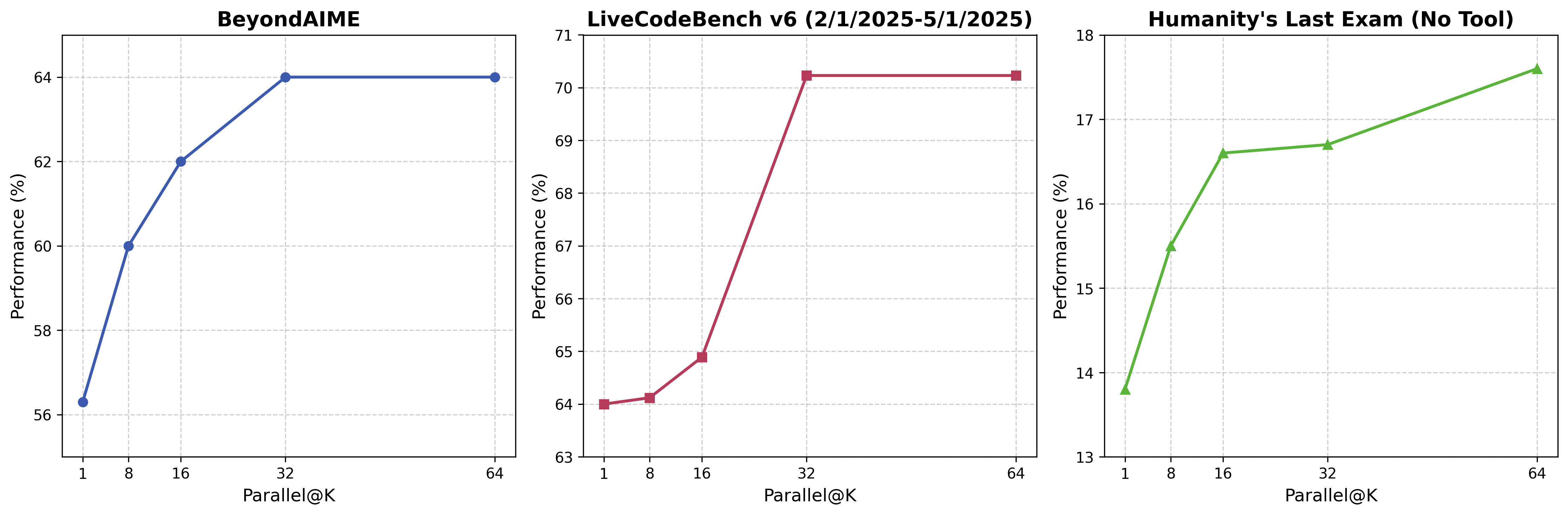
Note: Impact of parallel decoding on Seed1.6-Thinking test results
Adaptive Thinking
Deep thinking models demonstrate impressive capabilities in challenging domains such as mathematics and programming, primarily because long CoTs significantly enhances the model's reasoning ability. However, this poses the risk of overthinking, where deep thinking models indiscriminately use long CoTs to generate outputs. During CoT scaling, these models generate excessive unnecessary tokens, which increase reasoning costs without contributing to answer accuracy.
To address this challenge, Seed1.6 introduced AdaCoT to offer three reasoning modes: FullCoT, NoCoT, and AdaCoT. This greatly compresses CoT length without compromising effectiveness. To achieve adaptive thinking, we introduced a novel reward function during RL training to penalize overthinking and reward appropriate thinking. Models featuring adaptive thinking capabilities allow users to select reasoning modes through prompt configuration:
- FullCoT: The model engages in thinking before responding to each prompt, achieving results comparable to Seed1.6-Thinking while reducing the length of CoTs.
- NoCoT: The model responds directly to all prompts without engaging in thinking, achieving higher efficiency.
- AdaCoT: The model automatically decides whether to engage in thinking based on each prompt. This mode is a fusion of the two modes mentioned above.
The table below shows the performance of adaptive thinking models on public benchmarks.
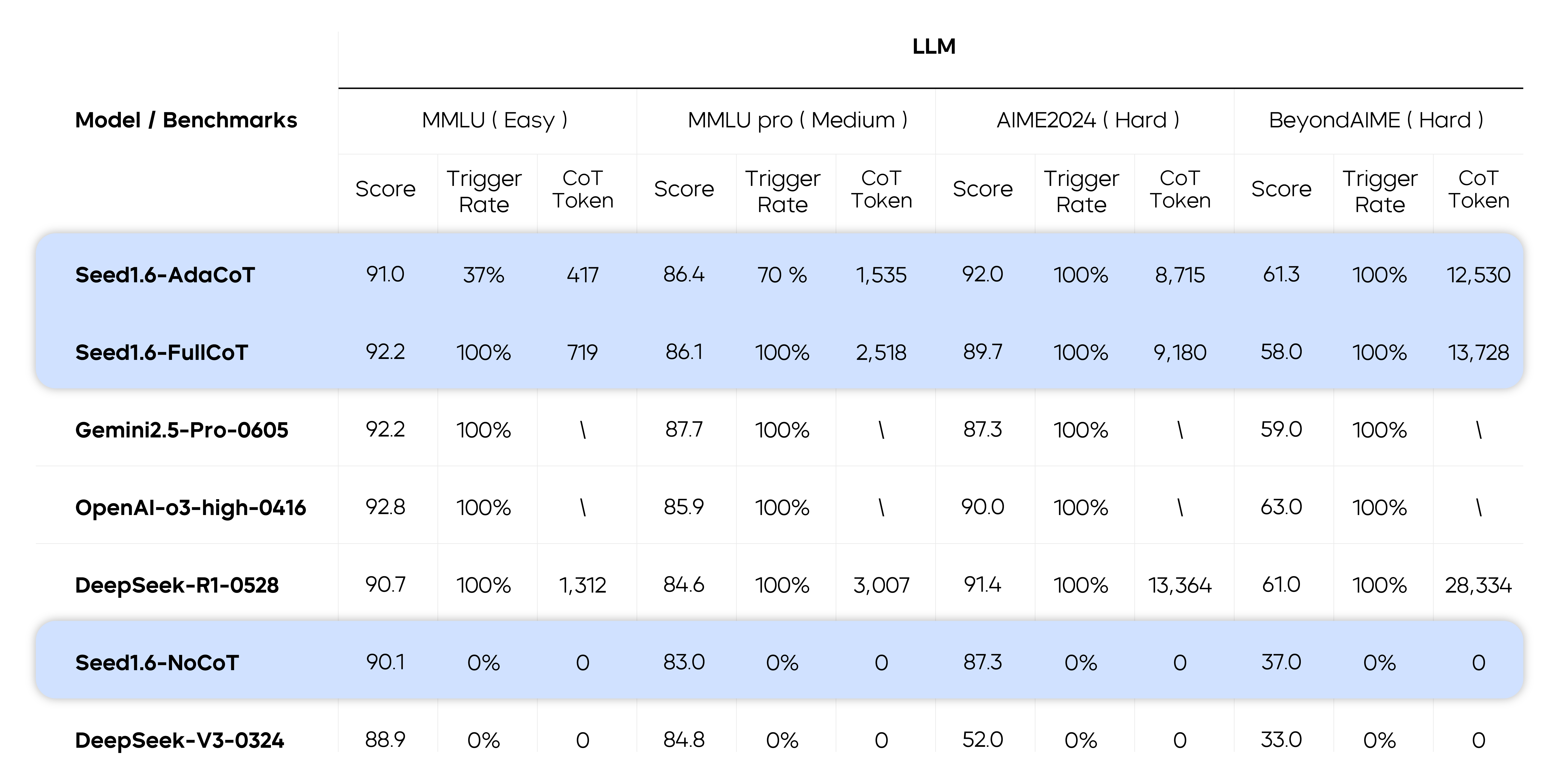
For external models, test results from the ByteDance Seed team are used in cases where no official result is provided.
For Gemini and OpenAI models that do not support FullCoT, the average CoT token usage is represented with a backslash (\).
For DeepSeek, the average CoT token usage comes from tests by the ByteDance Seed team.
Seed1.6-AdaCoT demonstrated varying CoT triggering rates—37% on MMLU for easy tasks and 70% on MMLU-Pro for moderate tasks—showing a positive correlation with task complexity. In such tasks, the model saved tokens without compromising performance. In challenging tasks such as AIME and BeyondAIME, Seed1.6-AdaCoT exhibited CoT triggering rates ranging from 90% to 100% and was comparable to Seed1.6-FullCoT in effectiveness. This indicates that adaptive thinking preserves the reasoning advantages brought by long CoTs to the model. Additionally, our findings confirm the effectiveness of the AdaCoT approach in multimodal scenarios.
Excel in Generalization Tests, Score Evenly in Humanities and Science
Beyond conventional benchmark tests, we evaluated Seed1.6-Thinking on the college entrance exams of two countries to validate its generalization performance.
Tests on China's 2025 College Entrance Exam
China's national college entrance exam (Gaokao), which assesses both humanities and science subjects, provides an ideal testbed for evaluating a model's textual and visual understanding. The novelty of the exam questions further reveals a model's generalization capabilities. We used the 2025 Shandong-Province Gaokao papers sourced online for evaluation. For the Chinese, Math, and English subjects, we utilized papers based on Version I issued by China's Ministry of Education under the New Curriculum Standards. Papers for other subjects were the self-developed versions authored independently by Shandong Province. The full score of all subjects is 750 points. To ensure reliable evaluation results, we strictly adhered to the official Gaokao grading standards.
- Multiple-choice and fill-in-the-blank questions::Machines automatically graded the answers to closed-ended questions, which were then reviewed by humans.
- Open-ended questions:Two experienced joint exam graders from top-tier high schools evaluated the anonymous answers, which were then reviewed in multiple rounds.
Throughout the evaluation, no prompt engineering was applied to enhance model effectiveness, and all inputs were original questions from Gaokao sourced online.
For grading details, visit:https://bytedance.sg.larkoffice.com/sheets/QgoFs7RBjhnrUXtCBsYl0Jg2gmg
We ranked five industry-leading reasoning models based on their total scores across six subjects: Chinese, Math, English, and three others spanning science and humanities. The models evaluated were Gemini2.5-Pro-0605, Seed1.6-Thinking, DeepSeek-R1-0528, Claude-Sonnet-4, and OpenAI-o3-high-0416.
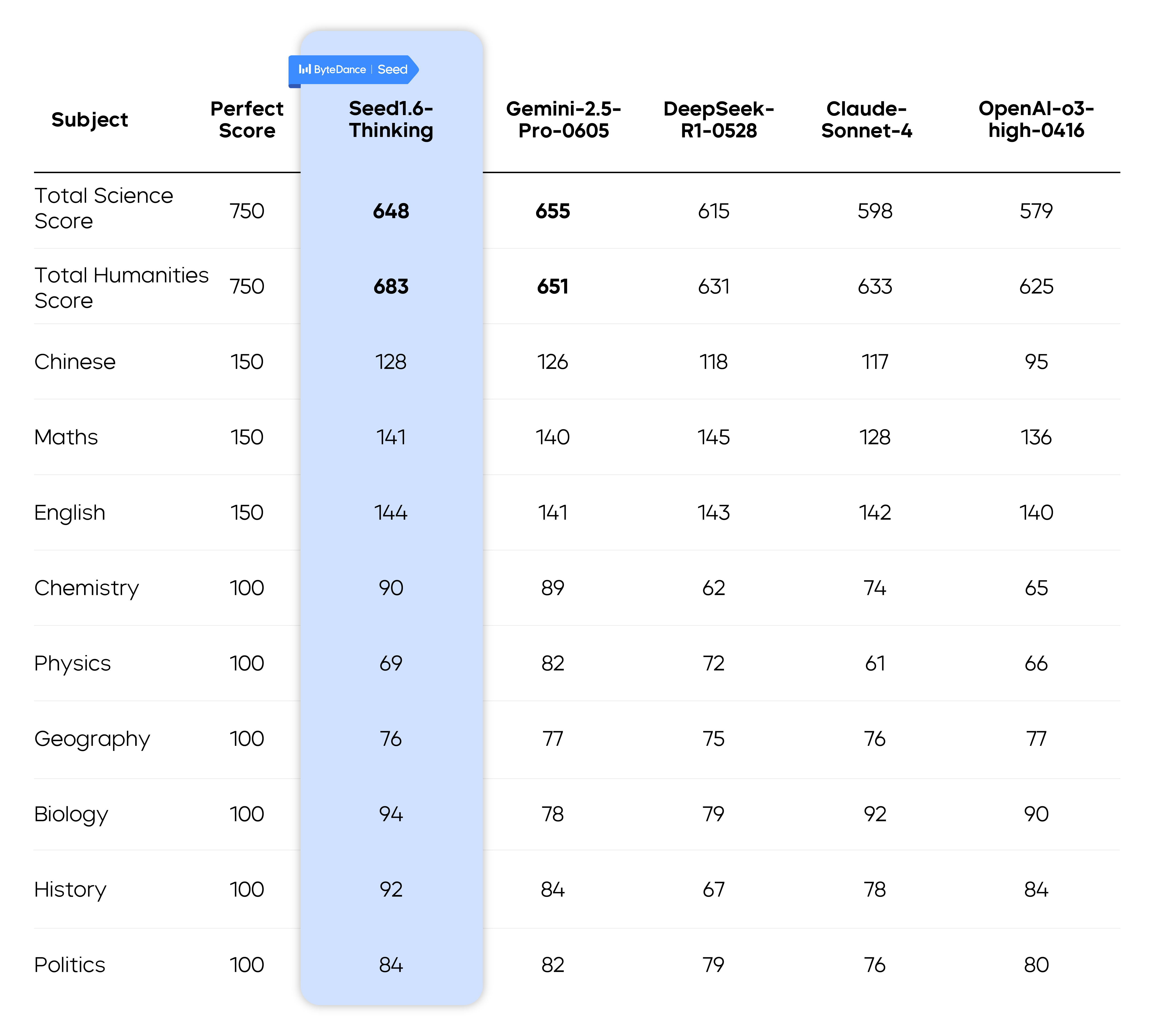
DeepSeek R1 received the text of the questions, while other models received both the text and images.
All models were assumed to achieve full scores in the English listening section.
In science subjects, Seed1.6-Thinking ranked second with a score of 648, demonstrating particular strength in Physics. In humanities subjects, it achieved first place (score: 683), excelling notably in Geography and History. Both scores surpassed the historical admission thresholds for most Project 985 universities in China.
The results show that most models performed comparably well in fundamental subjects (Chinese, Math, and English), achieving top-performing student levels with minimal score variations. However, Chemistry and Biology presented challenges due to numerous diagram-based questions. As these unofficial materials contained blurry diagrams, model performance declined significantly in both subjects. Gemini2.5-Pro-0605 demonstrated superior multimodal capabilities with a notable edge in Chemistry.
Recently, after obtaining higher-resolution images of the Gaokao papers, we used text and images as inputs to repeat the reasoning tests for Biology and Chemistry, the two subjects requiring accurate image understanding. This time, Seed1.6-Thinking scored an additional 30 points in these subjects, raising its total science score to 676. This demonstrates that multimodal reasoning integrating text and images can better unlock a model's potential, highlighting it as a promising direction for future research.

Note: Sample input integrating text and images
Tests on JEE Advanced
JEE Advanced is the second-stage exam for admission to the Indian Institutes of Technology (IITs). Each year, millions of candidates take the first-stage screening test, with the top 250,000 qualifying for JEE Advanced. This three-subject exam (Math, Physics, and Chemistry) spans two rigorous 3-hour sessions.
To further evaluate the models' generalization capabilities in multimodal understanding and reasoning, we used images of JEE Advanced questions as input. All questions were objective-type, with each sampled five times. Answers were graded strictly according to JEE rules: full credit for correct answers and deductions for incorrect ones, regardless of format.
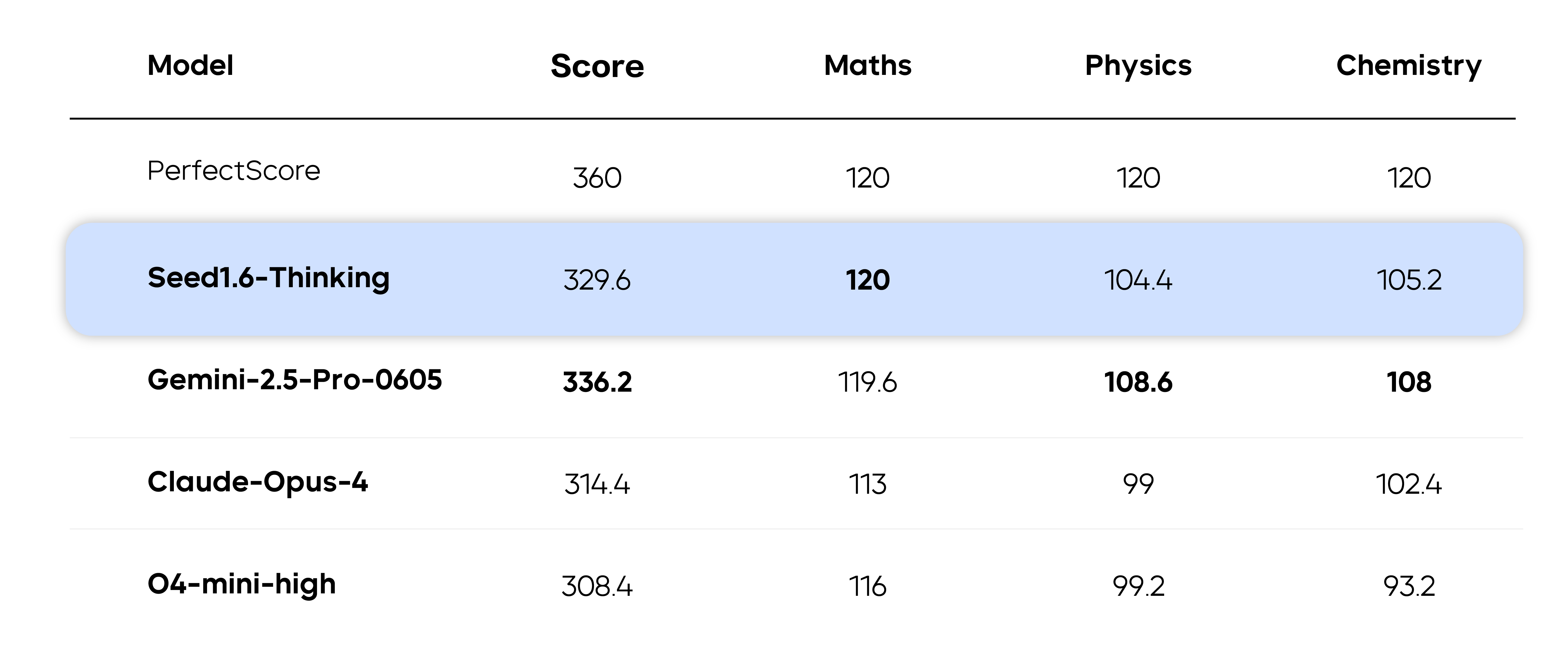
Among human participants across India, the first place scored 332, while the tenth place scored 317. If Gemini-2.5-Pro and Seed1.6-Thinking were human participants, their performance would place both within India's top 10. Notably, Gemini-2.5-Pro excelled in Physics and Chemistry, while Seed1.6-Thinking achieved 100% accuracy in Math across all five sampling rounds.
Summary and Outlook
The Seed1.6 series models mark a significant advance by the ByteDance Seed team, effectively balancing reasoning effectiveness and performance. These models incorporate the multimodal capabilities of VLMs across the entire development lifecycle, spanning from pre-training to post-training.
Looking ahead, our focus shifts to exploring more efficient model architectures to further enhance reasoning effectiveness and expand multimodal capabilities. Furthermore, we are committed to deepening our research in empowering models to act as autonomous agents for end-to-end task execution.
To try out Seed1.6, visit the following link: https://www.volcengine.com/experience/ark?model=doubao-seed-1-6-250615
To try out Seed1.6-Thinking, visit the following link: https://www.volcengine.com/experience/ark?model=doubao-seed-1-6-thinking-250615