12篇成果入选,2场Talk,字节跳动Seed邀你相聚CVPR 2025
12篇成果入选,2场Talk,字节跳动Seed邀你相聚CVPR 2025
日期
2025-06-10
分类
学术活动

CVPR 2025 将于 6 月 11 日至 15 日在美国田纳西州纳什维尔举行,全球顶尖学者将汇聚于此,共同探讨计算机视觉领域的前沿技术与研究成果。
在本届会议中,字节跳动 Seed 团队共有 12 篇论文入选,其中包括 4 篇 Highlight ,研究内容涵盖视觉推理、视觉建模、3D 视觉与工业级应用等多个前沿领域。本文将对其中六篇精选论文进行详细解读。
活动期间,我们将在现场 Booth No.1101 区域设置展台,展示 Seedance 1.0、Seedream 3.0、Seed1.5-VL、SeedEdit 3.0、BAGEL 等多项前沿技术成果。届时,Seed 团队多位研究员也将来到现场,期待与你相见!
展台 Talk 分享
会议期间,Seed1.5-VL 和 BAGEL 两项工作的主要作者将在展台与大家见面,欢迎前来交流。

时间地点:June 13, 15:30 (CDT), Booth No.1101
Talk 主题:Seed1.5-VL 是 Seed 推出的前沿视觉 - 语言多模态大模型,基于超过 3T tokens 的多模态数据预训练,具备通用多模态理解与推理能力,在保证多任务处理能力的同时显著降低推理成本。

时间地点:June 14, 16:00 (CDT), Booth No.1101
Talk 主题:BAGEL 是 Seed 最新开源的多模态基础模型,支持文本、图像、视频的统一理解和生成,采用 MoT 架构,具有 7B 激活参数。在多项公开的多模态理解&生成评测基准中,BAGEL 的表现显著超越此前的开源统一模型。
精选论文

并行自回归视觉生成
arXiv: https://arxiv.org/pdf/2412.15119
Code: https://github.com/YuqingWang1029/PAR
Exhibition Location: ExHall D Poster #220, Poster Session 3
在视觉生成领域,自回归(AR)模型因强大的序列建模能力备受关注,但其逐 token 顺序生成的特性导致推理效率低下,成为制约实际应用的瓶颈。传统加速方案或依赖非自回归范式引入复杂架构(如 MaskGIT),或通过多尺度设计破坏 AR 模型的统一建模能力,难以在效率与质量间实现平衡。
据此,本文提出 并行自回归视觉生成(Parallelized Autoregressive Visual Generation, PAR)方法,根据 token 依赖强度动态调整生成模式,首次在标准视觉 AR 框架内实现高效加速,其核心内容包括:
- 两阶段生成策略:先顺序生成各区域初始 token 建立全局结构,再将空间远距、弱依赖的跨区域同位置 token 分组并行生成,避免相邻强依赖 token 冲突。
- 双向注意力与位置编码优化:允许并行组内 token 访问前组完整上下文,强化跨区域依赖建模,免局部细节断裂;此外,采用 2D 旋转位置编码(RoPE),确保 token 空间位置信息独立于生成顺序,维持全局结构连贯性。
- 无缝架构兼容:无需修改 Transformer 架构或 tokenizer,通过可学习过渡 token 和平移不变位置编码实现适配。

PAR 与传统自回归生成(LlamaGen)的可视化对比:PAR 可以在保持相当质量的同时,相比 LlamaGen 实现了 3.6-9.5 倍的加速。在单张 A100 batch size=1 的设定下,可以将每张图像的生成时间从 12.41 秒减少到 3.46 秒(PAR-4×)和 1.31 秒(PAR-16×)
实验显示,PAR 在 ImageNet 图像生成中实现 3.6 - 9.5 倍推理加速,FID 增幅 0~0.7;在 UCF - 101 视频生成中提速达 12.6 倍,FVD 增幅仅 9.3,具时空数据普适性。与基线模型 LlamaGen 相比,PAR 提速同时保持生成质量可比,无需额外模型或复杂设计,优于非自回归方法和多尺度方案。除此之外,该算法可以无缝和 torch compile 等工程优化手段结合,实现进一步 3-4 倍加速。总的来说,PAR 通过 “依赖感知并行” 的设计,在保证准确度的同时,突破自回归模型的效率瓶颈。

视频深度泛化:超长视频的一致性深度估计
arXiv: https://arxiv.org/pdf/2501.12375
Project Page: https://videodepthanything.github.io/
Exhibition Location: ExHall D Poster #169, Poster Session 5
单目深度估计模型,可根据二维 RGB 图像估计每个像素点的深度信息,在增强现实、3D 重建、自动驾驶领域应用广泛。但时间一致性问题限制了单目深度估计模型在视频领域的实际应用。如何构建一个又准又稳又快的长视频深度模型,成为单目深度估计进一步扩大应用范围的关键。
本文提出 Video Depth Anything(VDA),首次实现数分钟级超长视频的高质量一致深度估计,核心方法包括:
- 单图深度模型到视频深度模型的变换方法:通过轻量级的时空头,将 Depth Anything 模型变为 Video Depth Anything 模型,并引入图像和视频联合训练方式,在保持单图模型细节的同时,实现了时空稳定性。
- 简单有效的时空一致性约束:直接使用相邻帧中相同坐标深度来计算损失,假设相邻帧中相同图像位置的深度变化应与真实值变化一致,去除对光流的依赖。
- 超长视频推理策略:使用重叠区域插值和关键帧对齐方法,确保局部窗口之间的平滑推理,并显著减少累积的尺度漂移,尤其利于长视频处理。

左图:VDA 能够为包含丰富动作的长视频生成时空一致的深度预测。该图展示了一段 196 秒(4690帧)长的双人滑冰镜头。右图:在 A100 上与 baseline 方法在精度(δ₁)、时序一致性和延迟(圆圈大小表示延迟)的对比。一致性定义为所有模型中的最大时序对齐误差(TAE)减去各个模型的 TAE。VDA 在所有指标上都取得了最佳表现。
实验结果表明,VDA 在视频数据集的精度和稳定性指标均取得 SOTA,尤其精度提升超过 10 个百分点,且推理速度均远快于此前同类模型,其速度是此前最高精度模型的 10 倍以上。在 V100 下,较小版本 VDA 模型推理速度甚至可达 30FPS(每秒 30 帧),为 AR/VR、机器人导航、电影级视频编辑等动态场景提供可行方案。

SeedVR:扩散Transformer为通用视频修复注入无限可能
arXiv: https://arxiv.org/pdf/2501.01320
Exhibition Location: ExHall D Poster #187, Poster Session 1
在视频修复领域,从含未知退化的低质视频中恢复出保真且时间一致的细节颇具挑战。现有基于扩散的方法存在生成能力与采样效率不足的问题,处理高分辨率长视频时,因依赖分块采样和全注意力机制,计算成本高、推理速度慢,效果上也难以满足实际需求。针对以上问题,本文提出 SeedVR,这是一种专为通用视频修复设计的扩散 Transformer 模型,其主要方法包括:
- 移位窗口注意力机制(Swin-MMDiT):采用 64×64 大窗口替代全注意力,有效捕捉长距离依赖,通过 3D 旋转位置嵌入处理边界可变窗口问题,使模型可处理任意分辨率和长度的视频,摆脱分块采样的限制。
- 因果视频自动编码器(CVVAE):对时空分别进行 4 倍和 8 倍压缩,将 latent 通道数增至 16,在保证高重建质量的同时,显著降低计算成本,提升训练和推理效率。
- 混合训练与渐进策略:联合训练 1000 万图像和 500 万视频的混合数据,采用多阶段渐进训练,从低分辨率短视频逐步过渡到高分辨率长视频,增强模型对复杂场景的泛化能力。
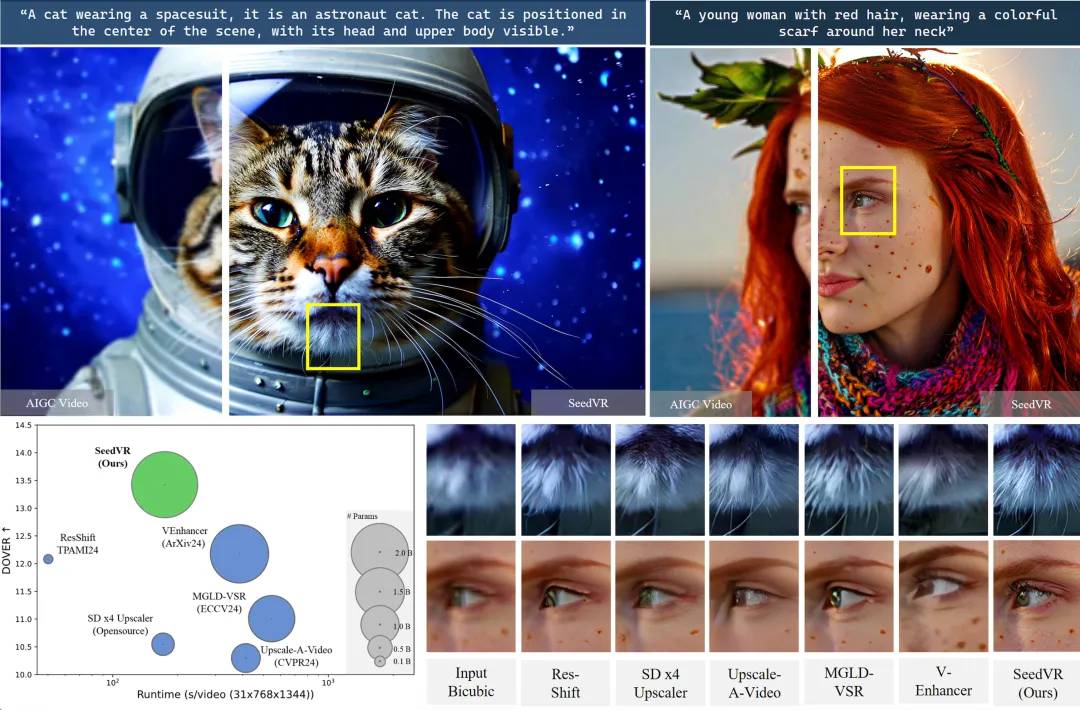
SeedVR 与现有基于扩散模型的复原方法的可视化对比:即便拥有更大的模型尺寸(2.48B), SeedVR 借助高效的窗口注意力设计和更高效的视频 VAE,在显著提升视频质量的同时实现了更快的推理效率(2x)。
SeedVR 在多种数据集上表现都很出色,在 SPMCS、UDM10 等 6 个基准测试中,4 个表现最优,其生成结果在 LPIPS、DISTS 等感知质量指标上显著领先,修复后的视觉效果和质量评分都超过了现有方法。尤其是在真实世界和 AI 生成视频修复中,SeedVR 能有效去除退化,恢复如建筑结构、动物毛发等精细细节,展现出更强的细节保真度和时间一致性。此外,其推理速度比 VEnhancer、Upscale-A-Video 快 2 倍以上,即便拥有 24.8 亿参数,仍能保持高效。总的来说,SeedVR 首次将扩散 Transformer 大模型用于通用视频修复,为通用视频修复提供了新的基准,推动了视频修复技术向高质量、高效率方向发展。

X-Dyna:富有表现力的动态人体图像动画
arXiv: https://arxiv.org/pdf/2501.10021
Exhibition Location: ExHall D Poster #5, Poster Session 2
在虚拟人创作与数字内容领域,单张人像的动态化生成长期受制于动态僵硬、背景割裂、表情失真等难题。本文提出创新扩散模型框架 X-Dyna,通过多模块协同突破,实现人物动作、面部表情与环境动态的自然融合,为静态图像赋予鲜活的动态生命力。
X-Dyna 主要有如下三个方面的创新:其一,动态适配器(Dynamics-Adapter)作为外观与动态的桥梁,以轻量级设计将参考图像的服饰纹理、光影特征以可训练残差形式融入扩散网络的注意力机制,在保持动作流畅性的同时锁定人物身份,避免传统方法中背景僵化与动态模糊;其二,S-Face ControlNet 面部控制器通过合成跨身份人脸补丁隐式学习表情规律,剥离面部动作中的身份干扰,即使跨身份迁移也能精准复刻挑眉、微笑等细微表情变化;最后,混合数据训练策略融合人体运动与自然场景(如水波、烟火、云层)动态数据,使模型同步掌握头发飘动、衣摆摇曳等物理运动规律,以及下雨、火焰等环境交互效果。
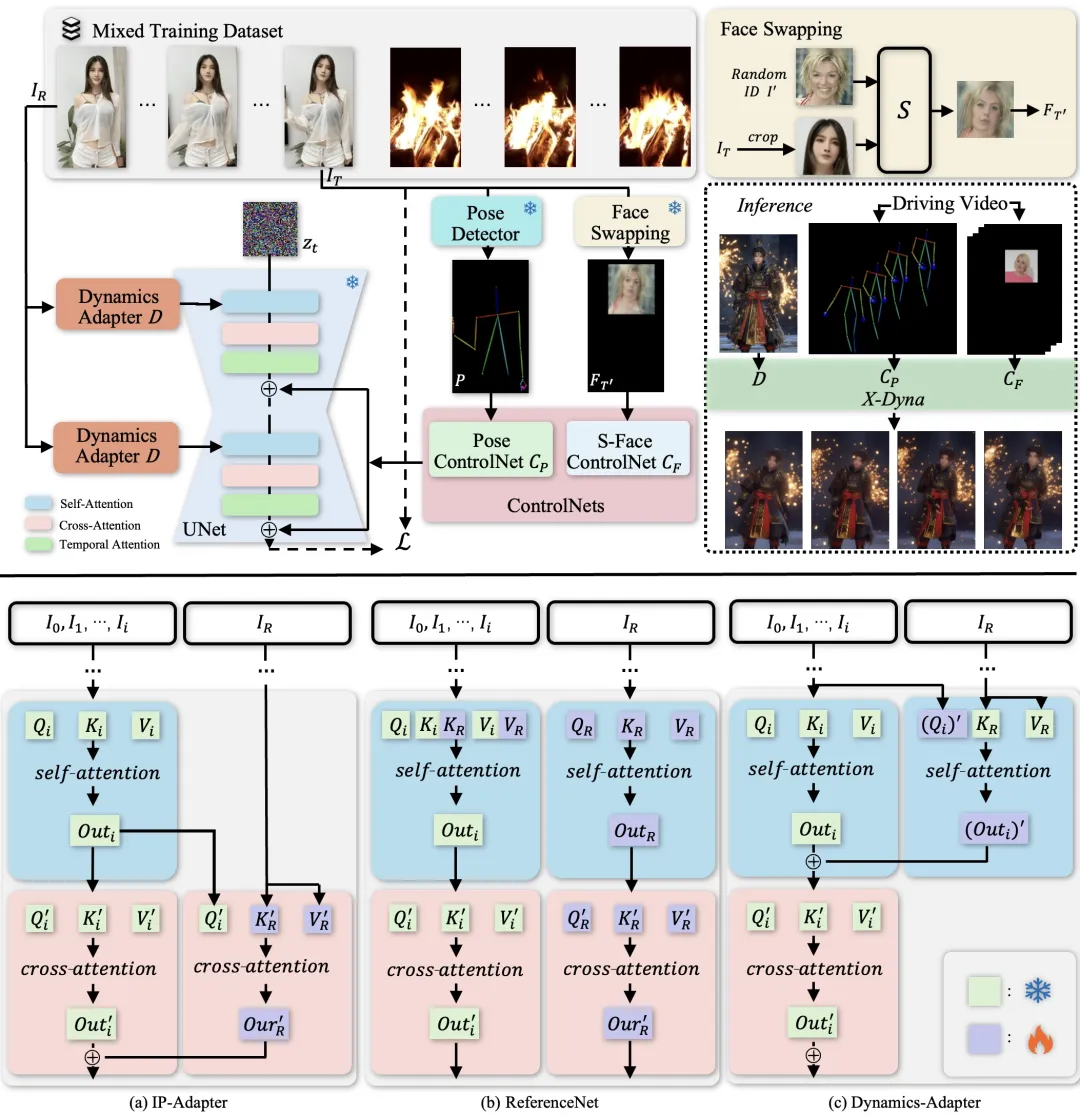
a) IP-Adapter 将参考图像编码为图像 CLIP 嵌入,并将信息作为残差注入 SD 中的交叉注意层。 b) ReferenceNet 是一个可训练的并行 UNet,通过连接自注意特征将语义信息输入 SD。 c) 我们提出的 Dynamics-Adapter 使用部分共享权重的 UNet 对参考图像进行编码。外观控制是通过在自注意层中学习残差来实现的,所有其他组件与 SD 共享相同的冻结权重。
实验显示,X-Dyna 在动态纹理生成指标 DTFVD 上达 1.518,较 MagicAnimate 等方法提升超 50%,头发飘动、水波涟漪等细节清晰度提升 3 倍。用户盲测中,其前景动态(4.85/5)、背景交互(4.92/5)和身份保留(4.78/5)评分均领先对比方法 0.8-1.2 分。总的来说,X-Dyna 通过即插即用的 Stable Diffusion 扩展模块,实现 “单张图像驱动逼真动态人像”,可广泛应用于虚拟主播实时动画、影视角色动态生成、社交特效等场景。

DiG:基于门控线性注意力的可扩展高效扩散模型
arXiv: https://arxiv.org/pdf/2405.18428
Exhibition Location: ExHall D Poster #219, Poster Session 2
在视觉内容生成领域,基于 Transformer 的扩散模型(如 DiT)虽表现优异,但自注意力机制的二次复杂度在处理高分辨率图像等长序列任务时,面临计算效率与内存消耗的瓶颈。现有线性注意力方法(如 Mamba、GLA)应用于视觉生成时,存在单向建模、局部感知不足等问题。
本文提出 DiG(Diffusion Gated Linear Attention Transformers),将门控线性注意力(GLA)的次二次建模能力引入二维扩散主干,通过轻量化设计实现高效的长序列视觉生成,主要包括:
- 空间重定向与增强模块(SREM):通过块级扫描方向控制(含四种基础模式)和深度卷积(DWConv),解决单向建模缺陷并增强局部空间感知,仅引入极少矩阵操作和参数开销。
- 双架构设计:提供普通型(DiG)和 U 型(U-DiG)两种架构,后者借鉴 UNet 的层次化结构,通过下采样 / 上采样模块和跨层连接提升高分辨率生成性能。
- 线性注意力优化:基于 GLA 的线性注意力机制将计算复杂度从二次降至次二次,显著降低训练耗时和 GPU 内存占用。
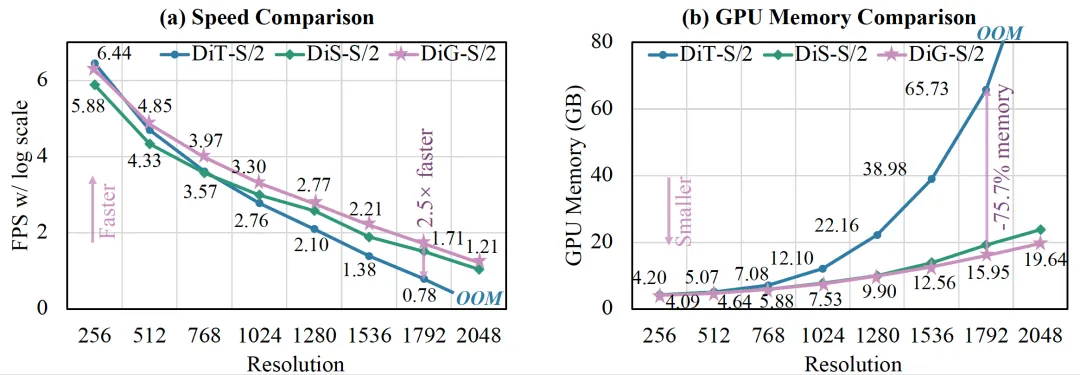
基于 Attention 的 DiT、基于 Mamba 的 DiS 以及我们提出的 DiG 模型之间的效率比较。在处理高分辨率图像时,DiG 的训练速度更快,而 GPU 内存消耗更低。例如,在分辨率为 1792 × 1792(即每幅图像 12544 个 token)的情况下,DiG 比 DiT 快 2.5 倍,节省 75.7% 的 GPU 内存。
实验显示,DiG 在 ImageNet 256×256 和 512×512 分辨率下生成性能与 DiT 相当(如 DiG-XL/2 在 512×512 的 FID 为 17.36,优于 DiT 的 20.94),同时效率显著提升:DiG-S/2 在 1792×1792 分辨率下训练速度快 2.5 倍、GPU 内存节省 75.7%。总的来说,DiG 通过线性注意力与轻量模块设计,在保持生成质量的同时突破二次复杂度限制,为高分辨率图像、视频等长序列生成任务提供了高效可扩展的新主干,有望推动扩散模型在资源受限场景下的应用。

Dora:三维形状变分自动编码器的采样与基准测试
arXiv:https://arxiv.org/pdf/2412.17808
Project Page: https://aruichen.github.io/Dora/
Exhibition Location:ExHall D Poster #38, Poster Session 4
在 3D 内容生成领域,基于变分自编码器(VAE)的两阶段流水线(“编码形状至潜在空间”及“潜在扩散生成”)已成为主流,但传统均匀点采样策略导致几何细节严重丢失,限制了形状重建和下游生成质量,且现有评估协议难以有效衡量复杂几何特征的重建精度。本文提出 Dora-VAE 及其配套评估基准 Dora-Bench,以系统性解决上述挑战:
一、锐边采样策略(SES):通过分析网格相邻面的二面角识别高几何复杂度边缘,优先采样尖锐特征区域,同时保留均匀采样点以维持整体结构,实现细节与全局几何的均衡覆盖。二、双交叉注意力机制:在编码阶段对均匀采样点和显著特征点分别进行交叉注意力计算,融合两类区域的特征表示,增强模型对细节丰富点云的处理能力。三、Dora-Bench 基准:基于几何复杂度(显著边数量)将测试形状分为 4 个等级,引入尖锐法向误差(SNE)指标,聚焦评估几何显著区域的重建精度,提供更精细化的 VAE 性能评估框架。
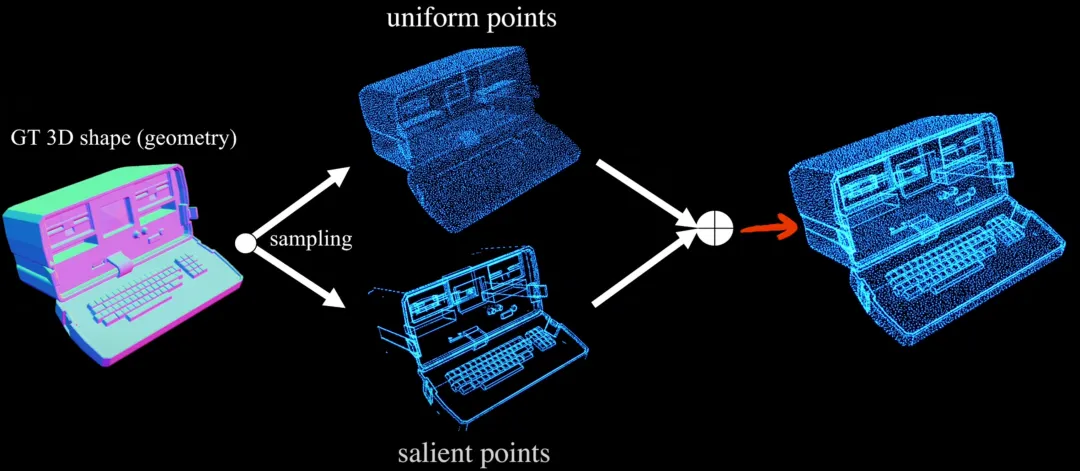
锐边采样(SES)
实验表明,在 Dora-Bench 上,Dora-VAE 使用仅 1280 维潜在空间即可实现与需超 10000 维的 XCube-VAE 相当的重建质量,F-score(0.005)在复杂形状(Level 4)达 87.473,Chamfer 距离低至 5.265×10⁻⁴,SNE 仅 1.579×10⁻²,显著优于 Craftsman-VAE 等向量集方法。在单图生成 3D 任务中,其构建的扩散模型生成结果几何细节更丰富,验证了对下游任务的提升作用。
总的来说,Dora-VAE 通过锐边采样和双注意力机制革新 3D VAE 的特征捕获能力,借助 Dora-Bench 建立更科学的评估体系,为高效紧凑的 3D 形状表示学习提供了新范式,推动文本到 3D 生成等下游任务向更高保真度发展。