Seed-Coder开源代码模型发布,依托LLM构建代码数据
Seed-Coder开源代码模型发布,依托LLM构建代码数据
日期
2025-05-19
分类
技术发布
字节跳动 Seed 近日公开了以模型为中心的代码预训练数据构建流水线(Model-centric Data Pipeline)实现方法。
通过研究,我们验证了——基于 LLM 即可实现对代码数据的评分、过滤。此类方法不仅能释放语言模型潜力,减少人工参与,还能提升模型在代码方面的能力。
经过一系列实验,我们发现,基于该流水线训练的 8B 代码模型系列 Seed-Coder,在代码生成、补全等任务上均有不错表现。
为更好地与业界分享上述探索,推动相关领域发展,我们开源了 Seed-Coder 系列(遵循自由的 MIT 协议),并公开其预训练数据构建的详细配方。
项目主页:https://bytedance-seed-coder.github.io
技术报告:https://github.com/ByteDance-Seed/Seed-Coder/blob/master/Seed-Coder.pdf
GitHub:https://github.com/ByteDance-Seed/Seed-Coder
Models:https://hf.co/collections/ByteDance-Seed/seed-coder-680de32c15ead6555c75b0e4
Hugging Face:https://huggingface.co/ByteDance-Seed/Seed-Coder-8B-Reasoning-bf16
在 Hugging Face 平台上,Seed-Coder 系列已开放下载,我们期待和更多研究者深入交流,共同推动大模型代码能力进一步突破。
在大语言模型(LLM)预训练阶段,代码数据不仅直接影响相关任务表现,更对提升模型通用智能上限起到关键作用。
在此前公开方法中,代码预训练数据构建高度依赖人工,但此类方法容易引入主观偏差,并且扩展到多种不同编程语言时,成本较高、难以维护。
面对上述挑战,字节跳动 Seed 团队于 2024 年初开始,进行了一系列研究,逐步探索出了一套以模型为中心的代码预训练数据构建流水线(Model-centric Data Pipeline) ,实现了预训练代码数据的高效产出。
基于该流水线,我们训练得到 Seed-Coder,以验证数据构建流水线的效果。
Seed-Coder 是包含基座模型(Base Model)、指令微调模型(Instruct Model)和推理模型(Reasoning Model)在内的 8B 系列开源模型。对比同等规模开源模型,Seed-Coder 在代码生成、补全、编辑、推理和软件工程等代码任务上,取得了不错分数:
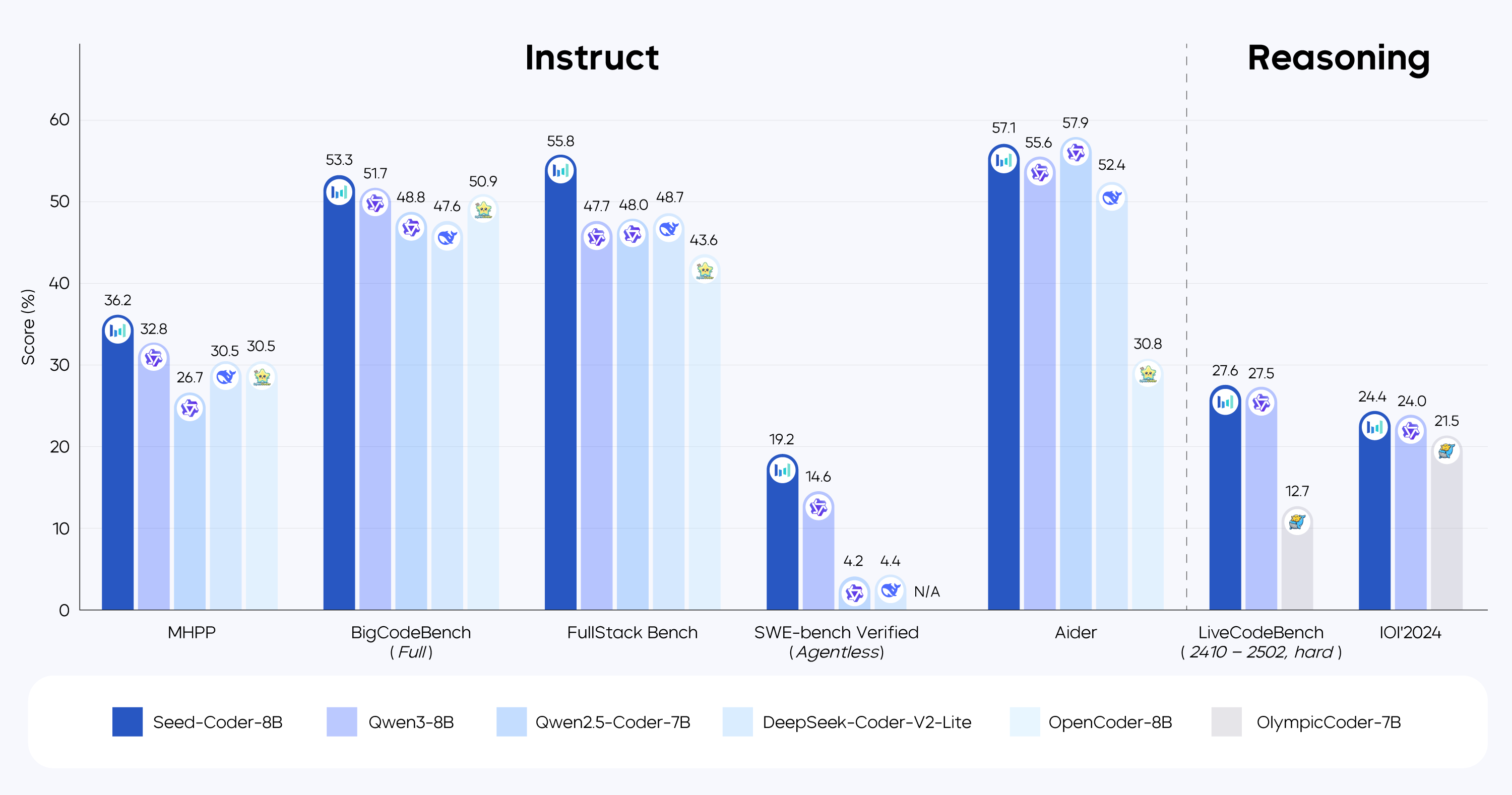
BigCodeBench,FullStack Bench,MHPP:在轻量级开源模型中展现一定优势;
SWE-bench Verified:修复率 19.2%,证明小模型也能在复杂的软件工程任务中有一席之地;
IOI'24:得分 146.5,与 QwQ-32B (144.0) 和 DeepSeek-R1 (137.0) 同处于第一梯队。
值得一提的是,Seed-Coder 在 Codeforces 上的 ELO 得分为 1553,接近 o1-mini 水平。这证明了,基于高质量数据的小代码模型面向高难度推理任务,同样具备一定潜力。
目前,该代码预训练数据构建流水线已被应用于 Seed 主力模型中,有效提升了模型代码能力。
1. 代码质量由人工过滤的“苦涩教训(The Bitter Lesson)”
代码,是人类与机器交互的核心媒介,伴随 LLM 迅猛发展,代码自动编写构建软件的交互方式成为可能。同时,由于代码类任务综合考察了模型逻辑推理能力,某种程度上,模型代码能力提升是实现 AGI 的先决条件。
我们能看到,LLM 在各类代码任务中已经取得卓越表现,闭源模型中 Claude 3.7 Sonnet、OpenAI o3、OpenAI o4-mini 以及 Gemini 2.5 Pro,已在代码生成、解释、调试、修改以及真实软件工程任务上,展现出前所未有的智能水平。
开源模型中,DeepSeek-R1、DeepSeek-Coder-V2 和 Qwen2.5-Coder 等主流模型,也在代码任务上表现优异。
作为代码模型训练的基础,业内此前认为基于人工规则筛选、清洗代码,是提高代码数据质量相对有效的方法。例如 DeepSeek-Coder 和 Qwen2.5-Coder 均借鉴 StarCoder,采用一系列过滤规则筛选代码数据。OpenCoder 也在其预训练数据处理中,手工定制超过 130 条过滤规则。
然而,人工过滤规则容易互相冲突,且容易引入人类的主观偏见,面向多种编程语言拓展维护,成本较高,拓展性受限。
我们认为,此类限制背后原因和图灵奖获得者 Richard Sutton 的经典文章《苦涩的教训》(“The Bitter Lesson”)中的洞见不谋而合:
研究员们往往试图依赖他们自己在该领域的知识,以谋求短期内带来显著的(模型)效果改进......而突破性进展,往往源自一些反直觉的方法——通过搜索和学习扩展计算。
最终的成果往往带着一丝“苦涩”,且难以完全被人们消化,因为它战胜了备受青睐的“以人类判断为中心”的方法。
在代码质量过滤的问题上,许多 AI 研究人员本身是高水平程序员,对于人工评估代码质量往往以“我”为主。但从长远来看,偏主观的评判可能存在局限,或将阻碍代码大模型的长期发展。
在初步调研时,我们发现,LLM 自身就很擅长评估代码质量,能够很好地把握一些难以明确量化的代码质量标准,且扩展性强、能稳定一致地对代码质量进行大规模打分和过滤,显著优于基于人工规则的代码质量过滤器。
下面两个真实案例,展示了基于 LLM 过滤相较于传统规则过滤的优势。

左图:该 Python 代码片段由于数字字符占比过高,被规则过滤器误判为垃圾代码,但 LLM 过滤器能识别这段代码是有意义的:它是为了在 LED 显示屏上显示一个皮卡丘的形象;
右图:该段 Python 代码乍看格式整齐、风格良好,能通过传统的规则过滤器。但是,LLM 过滤器却发现其中存在逻辑错误(条件写成 temp < 0 and temp > 1,这明显不对),且文档注释也有问题(文档里说会返回一个字符串,实际上却返回了 None),因此 LLM 准确地舍弃了这种质量不高的代码。
基于上述发现,我们设计了一套以模型为中心的代码数据构建方法,大幅减少对人工的依赖,并通过 Seed-Coder 证明,只需极少量的人工参与,LLM 就能自主高效地筛选代码训练数据,从而大幅提升编程能力。“苦涩的教训”在代码大模型领域再次得到了验证。
2. 以模型为中心的预训练数据流水线
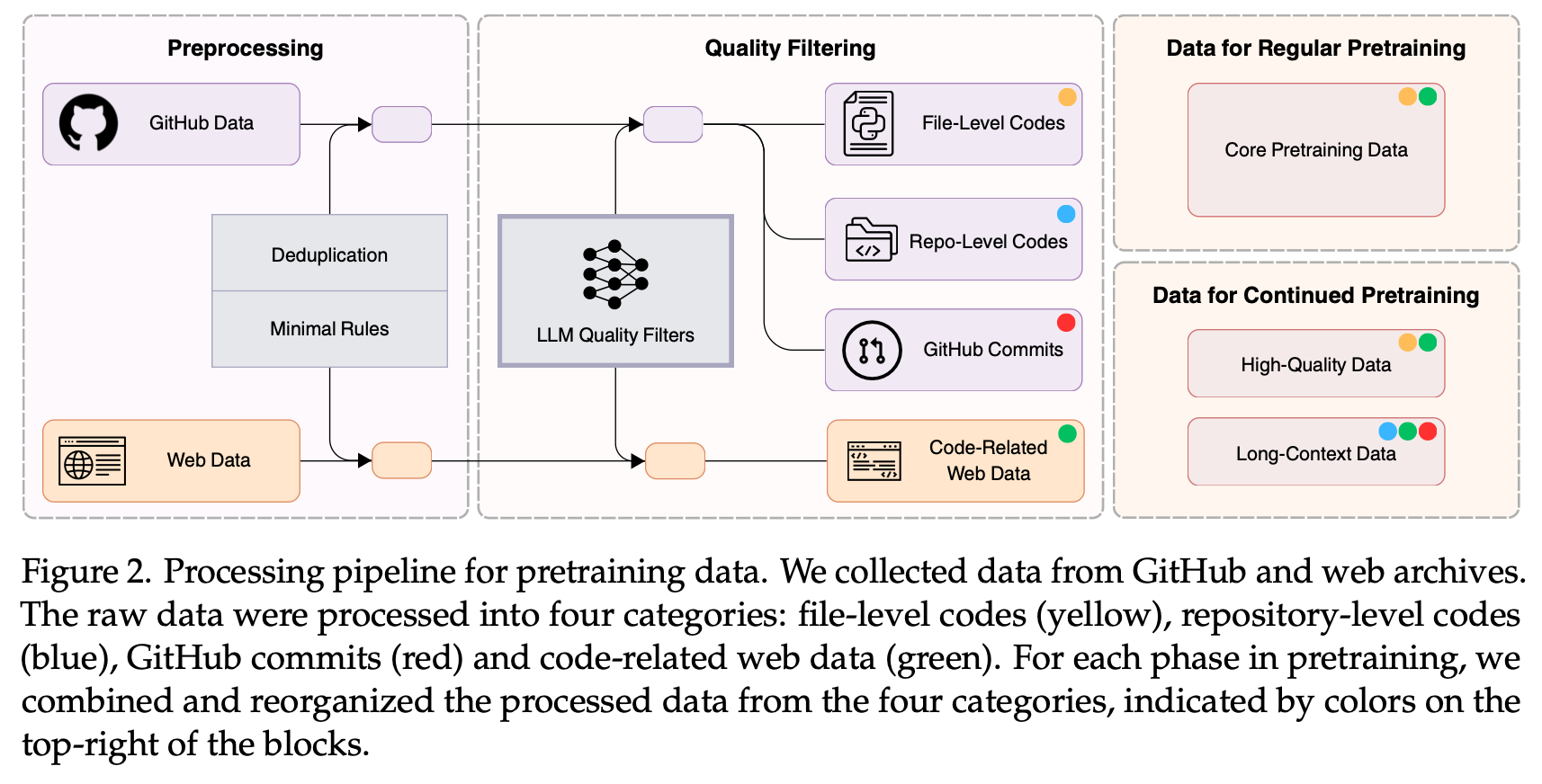
本工作旨在研究、分享、推动代码生成相关技术发展,为此,我们仅获取了公开、不涉及个人信息的相关数据,在研究完成后,我们开源 Seed-Coder 模型,并公开了其预训练数据构建的详细配方,包括 GitHub 代码、commits 和代码相关网页数据的处理和筛选流程。
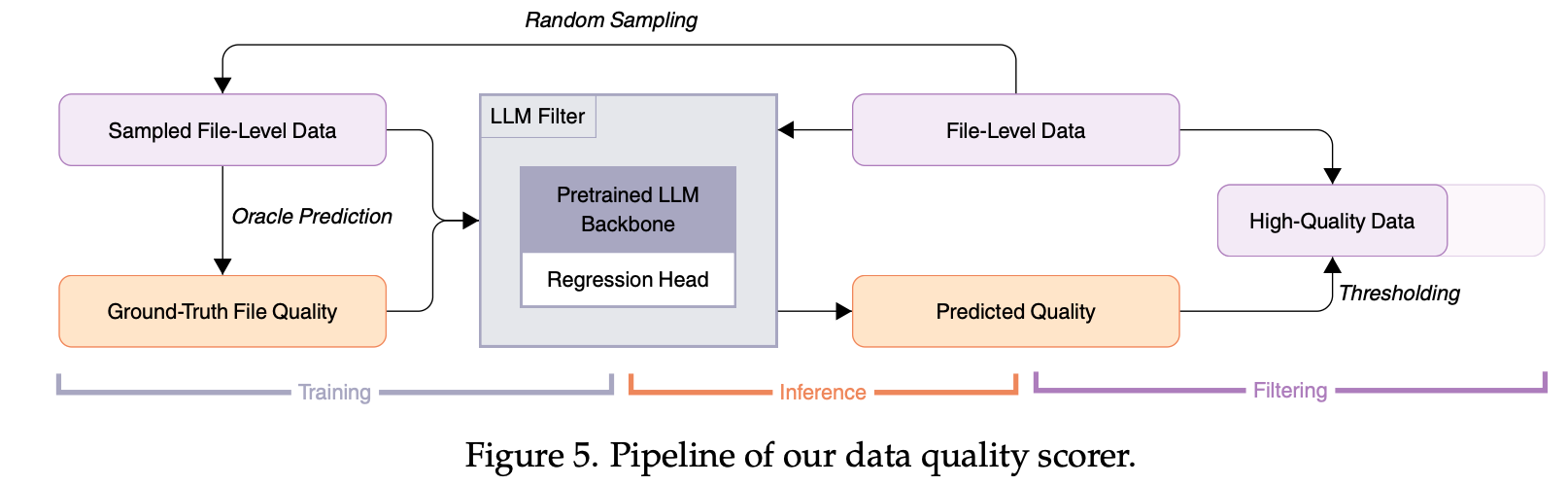
我们的 LLM 过滤器主要从四个维度评估代码的质量:易读性、模块化、清晰度和可复用性。
为了能让 LLM 过滤器覆盖更多 GitHub 公开数据,我们微调了一个小型的 1.3B Llama 结构模型(输出端替换成 regression head),让它高效地对代码质量进行打分。
下方流程图给出了具体的 GitHub 代码质量过滤流水线。
基于上述过程,我们得到了 6T tokens 的预训练代码数据,包含:常规预训练(5 trillion tokens)数据和持续预训练(1 trillioin tokens)数据。
我们的消融实验表明,使用 LLM 过滤器得到的代码数据,能够显著提高预训练模型的代码性能。
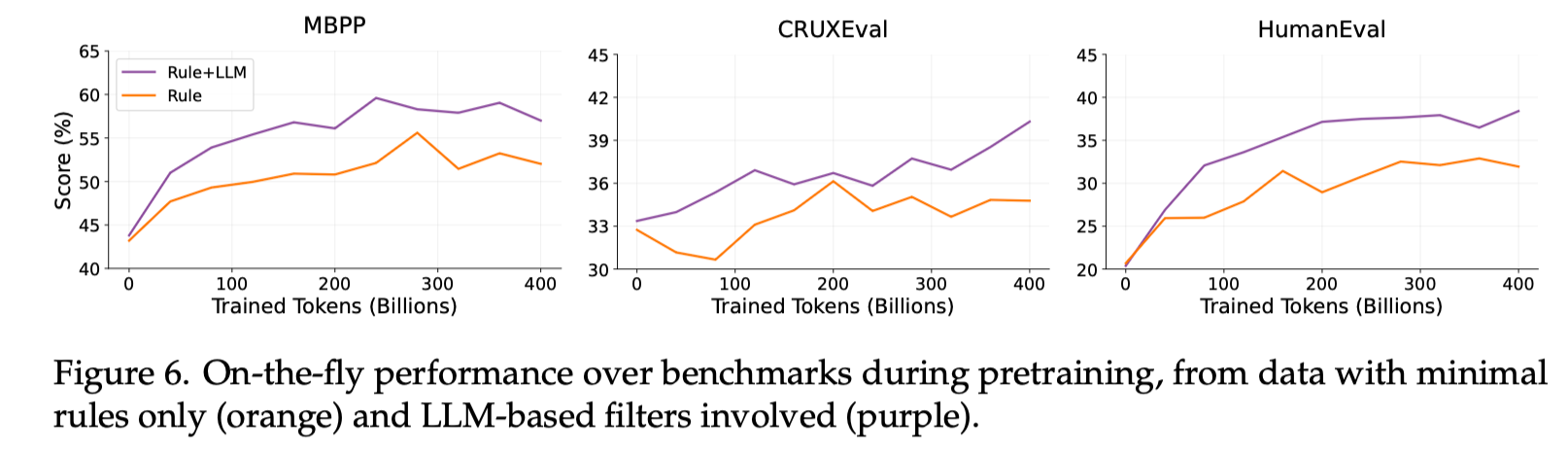
对于网页数据的筛选和清洗,我们也以 LLM 过滤器为中心构建流水线,从海量的网页数据中挑出高质量的代码相关数据(1.2 trillion tokens)。具体数据处理流程参见下图:
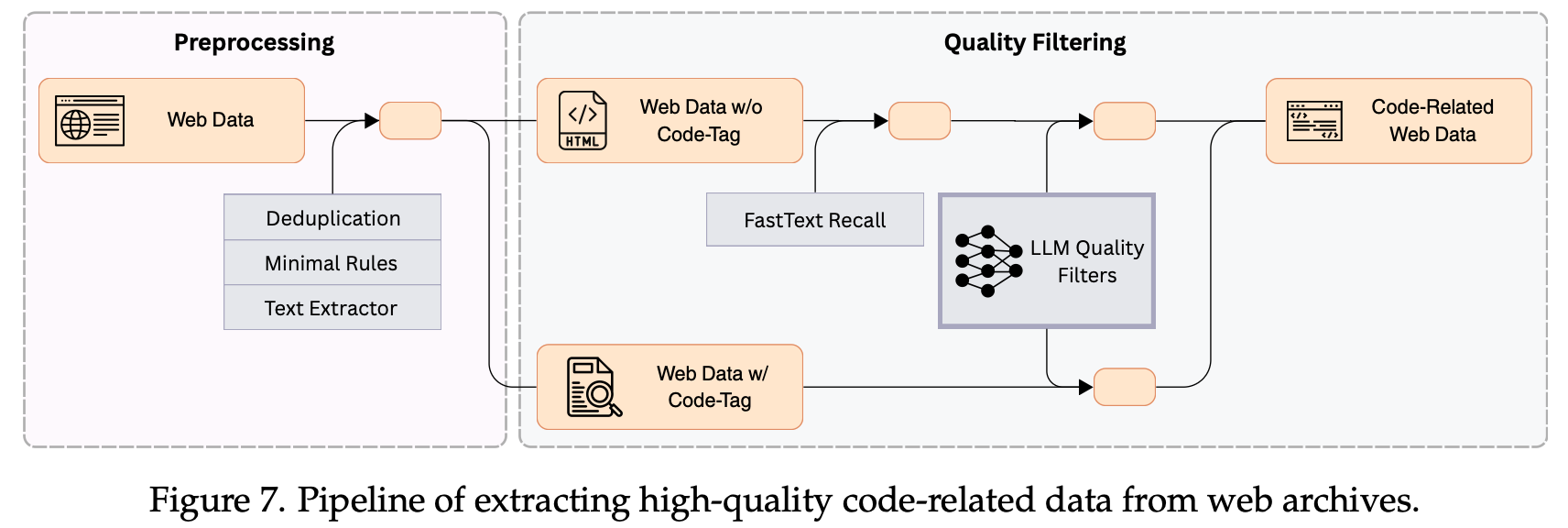
3. Seed-Coder 的后训练数据配方
基于上面预训练的基座模型 Seed-Coder-Base ,我们继续进行了后训练,包括:通过指令微调得到了对话模型 Seed-Coder-Instruct,通过强化学习得到了推理模型 Seed-Coder-Reasoning。
其中,Instruct 模型在 Seed-Coder-Base 基础上,进一步通过监督式微调和偏好优化进行训练,而 Reasoning 模型则利用长链式思考(LongCoT)强化学习,以提升多步代码推理能力。
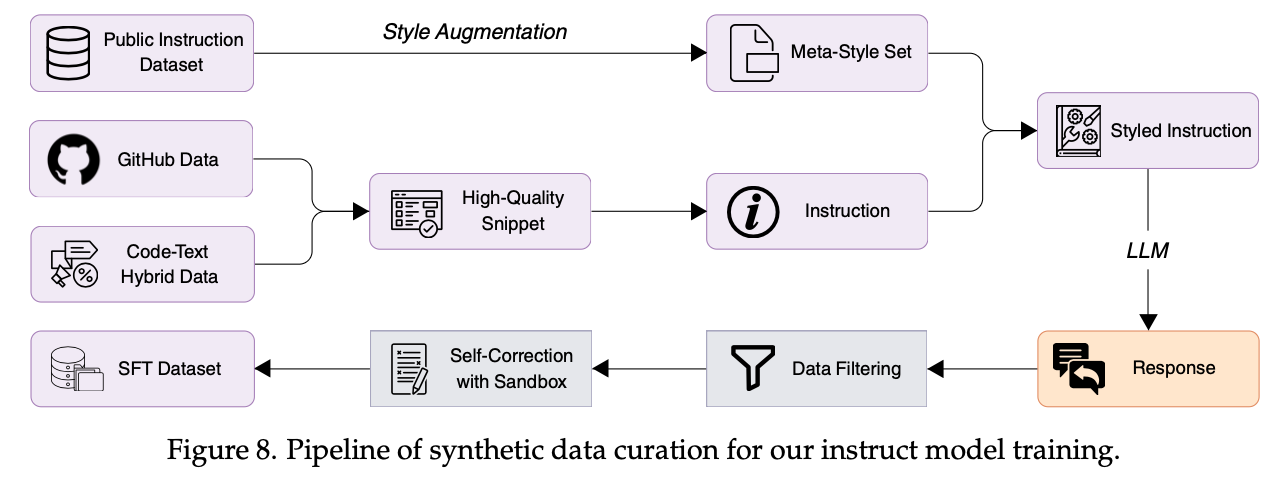
在指令微调阶段,我们重点关注三个方面:
- 多样性:用 LLM 生成各种不同风格的代码指令,让训练数据更丰富;
- 质量:通过语法和 LLM 筛掉质量不佳的回答;
- 难度:用 LLM 给问题打上难度标签,把简单的去掉,只留有挑战性的 prompt。
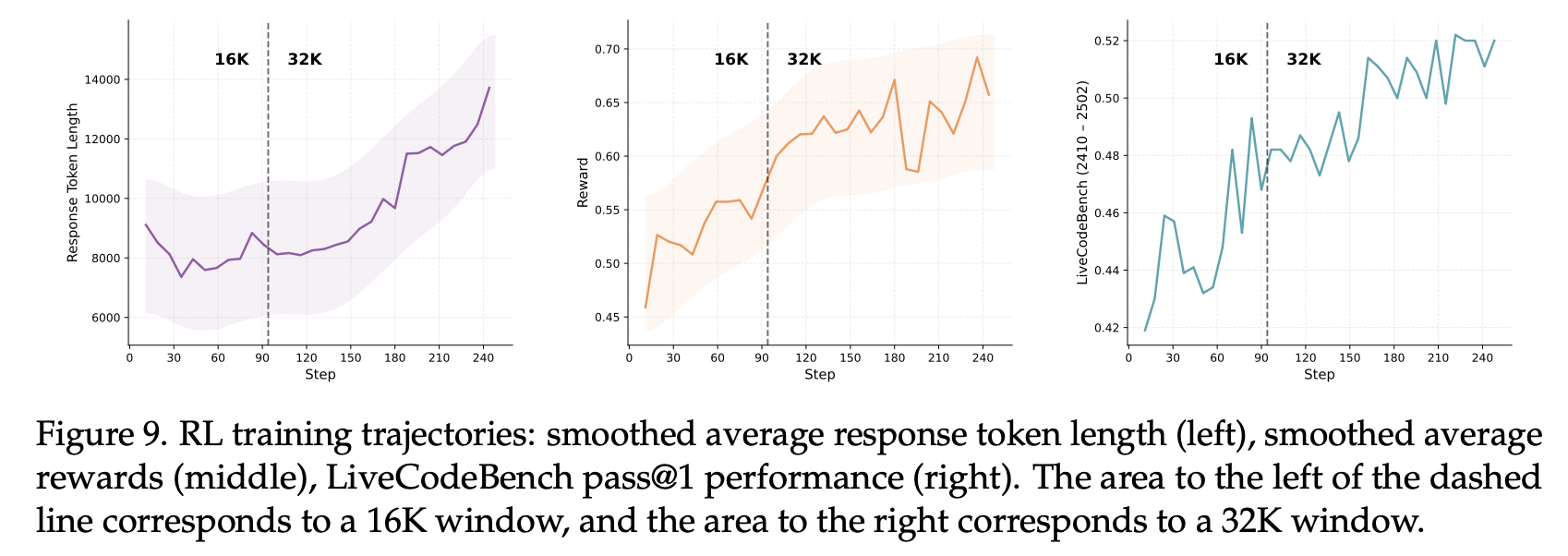
在强化学习阶段,我们采用开源框架 veRL 来训练推理模型,并结合一些实用的训练技巧:
-
课程学习:把正确率已经很高的简单问题筛掉,在训练过程中不断提升问题的难度;
-
渐进探索:在训练过程中逐步增加序列长度和 rollout 次数,让模型逐步学得更好。
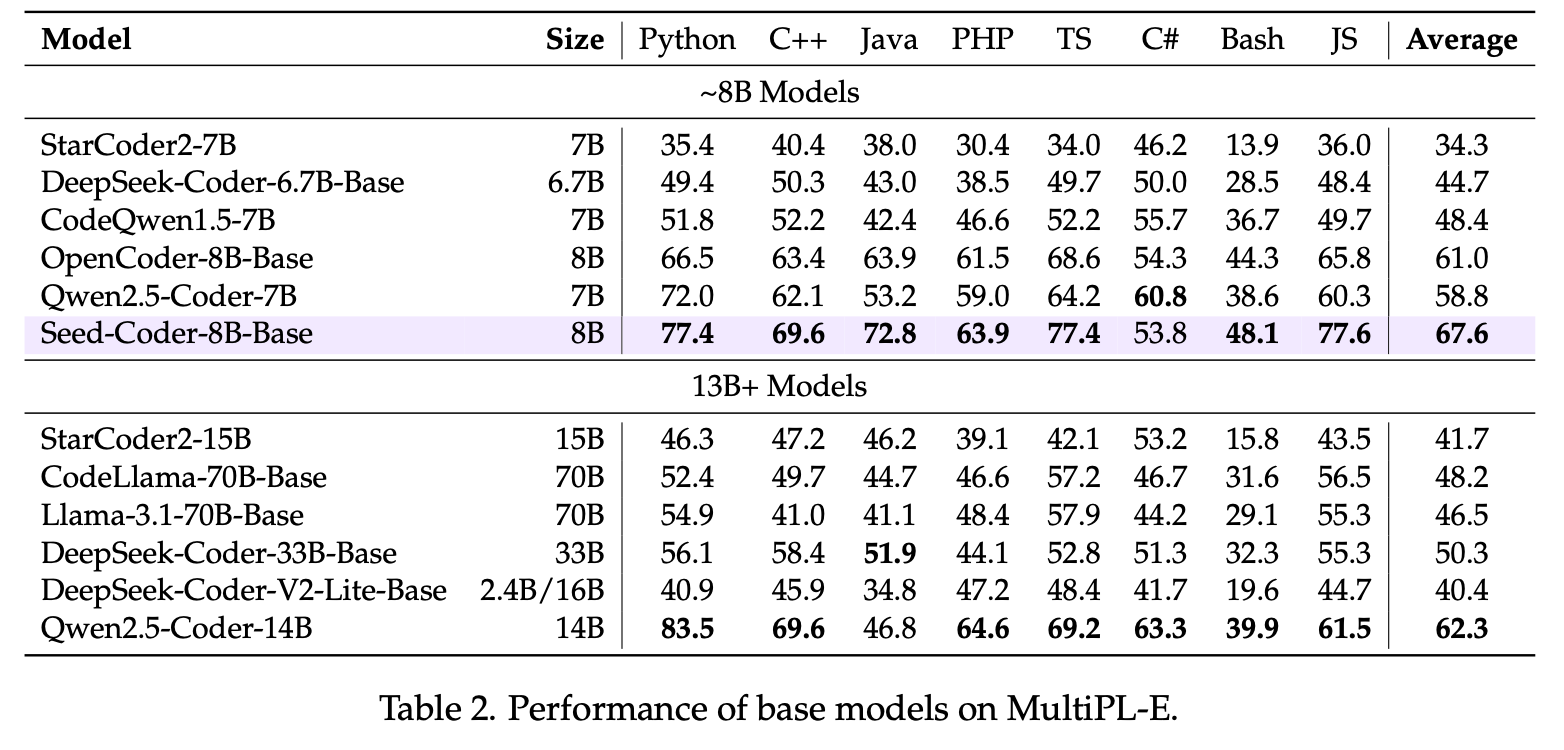
4. Seed-Coder 模型评测
我们基于被广泛采用的各类代码评测基准,对 Seed-Coder 系列的三个模型进行全面评测。这里仅列出部分结果,完整模型评测请参见技术报告。
结果显示,Seed-Coder-8B-Base 在各种代码生成和补全测试中均有不错表现:
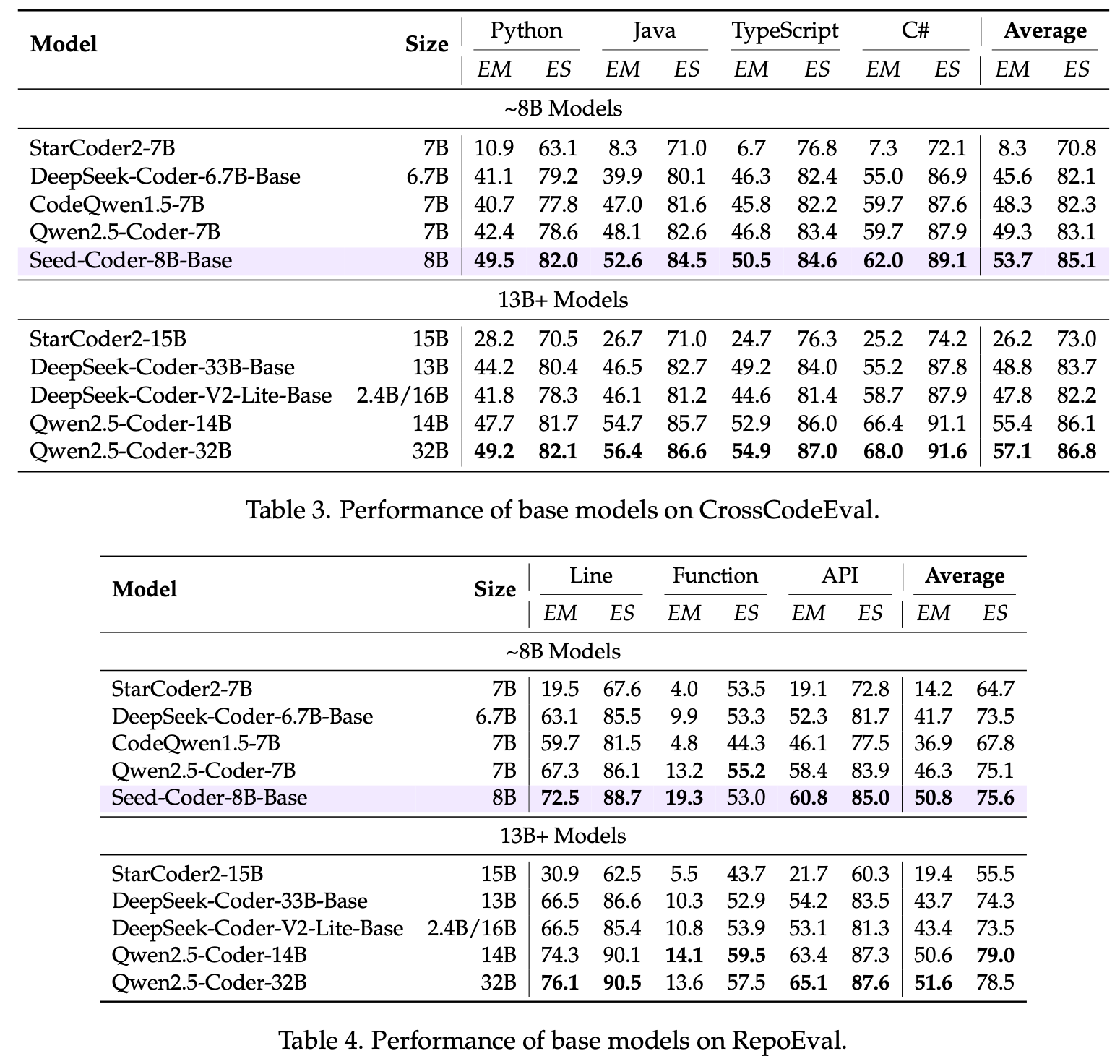
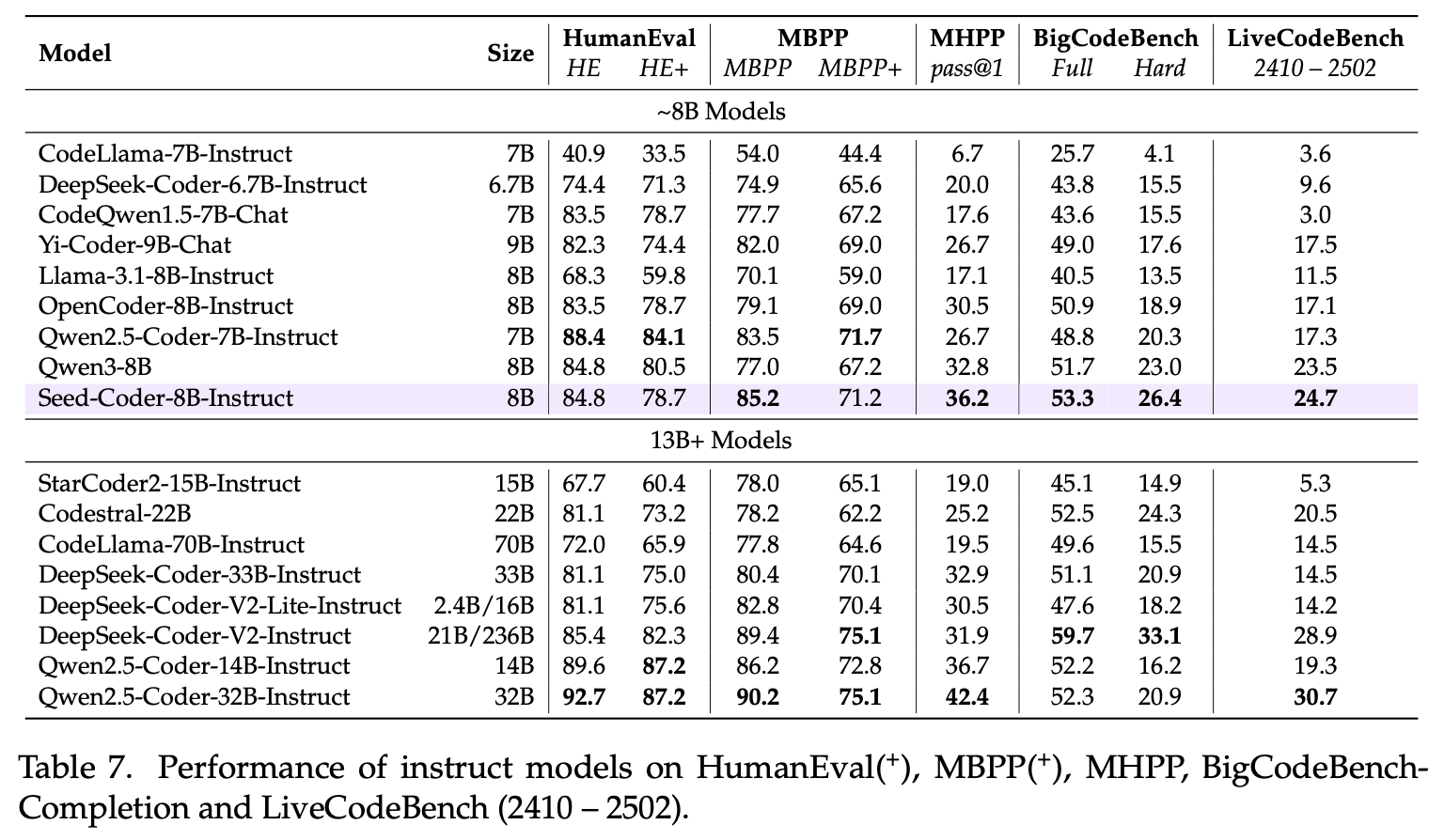
Seed-Coder-8B-Instruct 在各类代码任务上表现也不错,面向 SWE-bench 这种真实而复杂的软件工程任务,较同量级模型有一定优势。
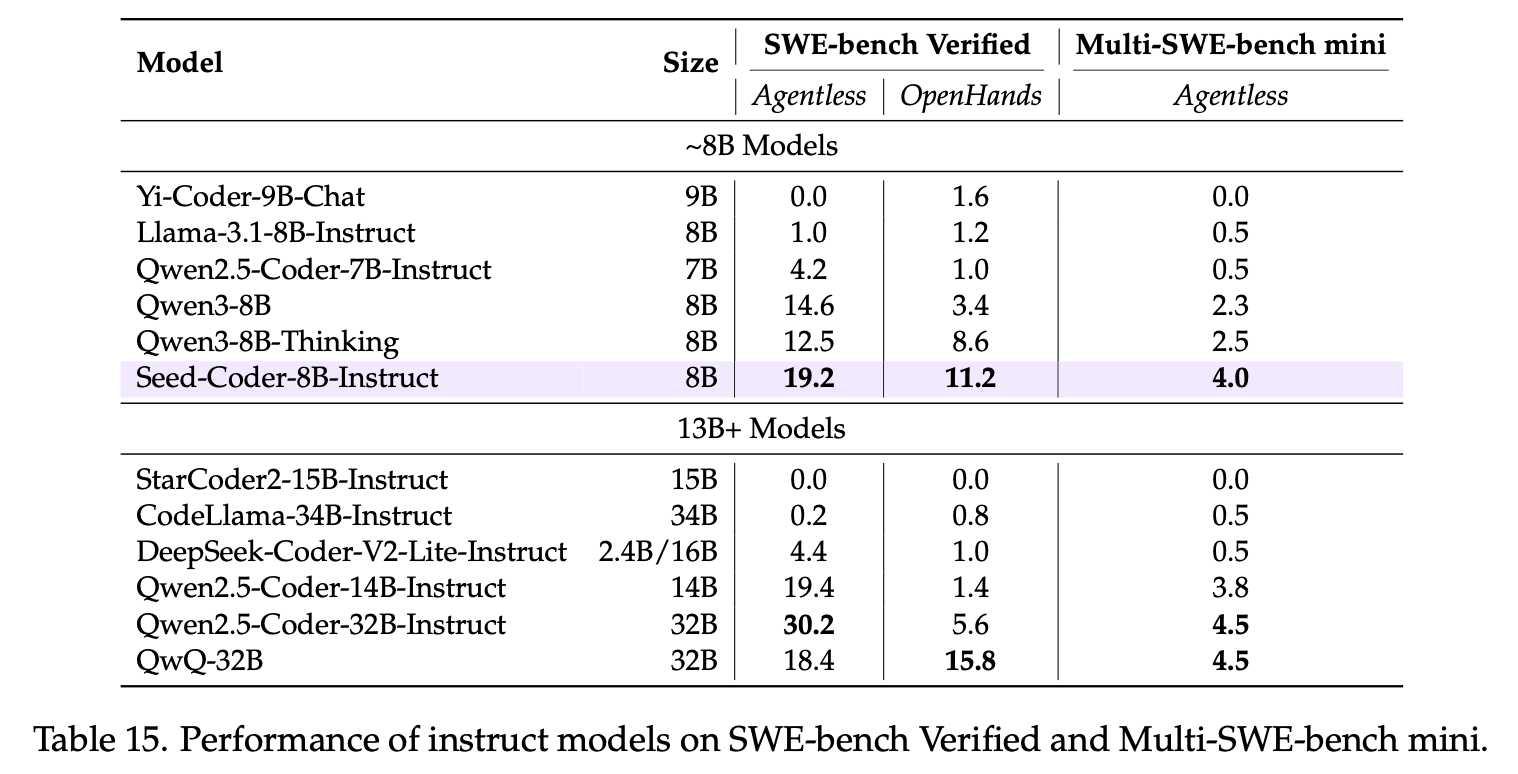
Seed-Coder-8B-Reasoning 则在算法竞赛评测中表现较好,Codeforces ELO 1553 接近 o1-mini 表现,展现了小尺寸模型处理复杂推理任务的潜力。
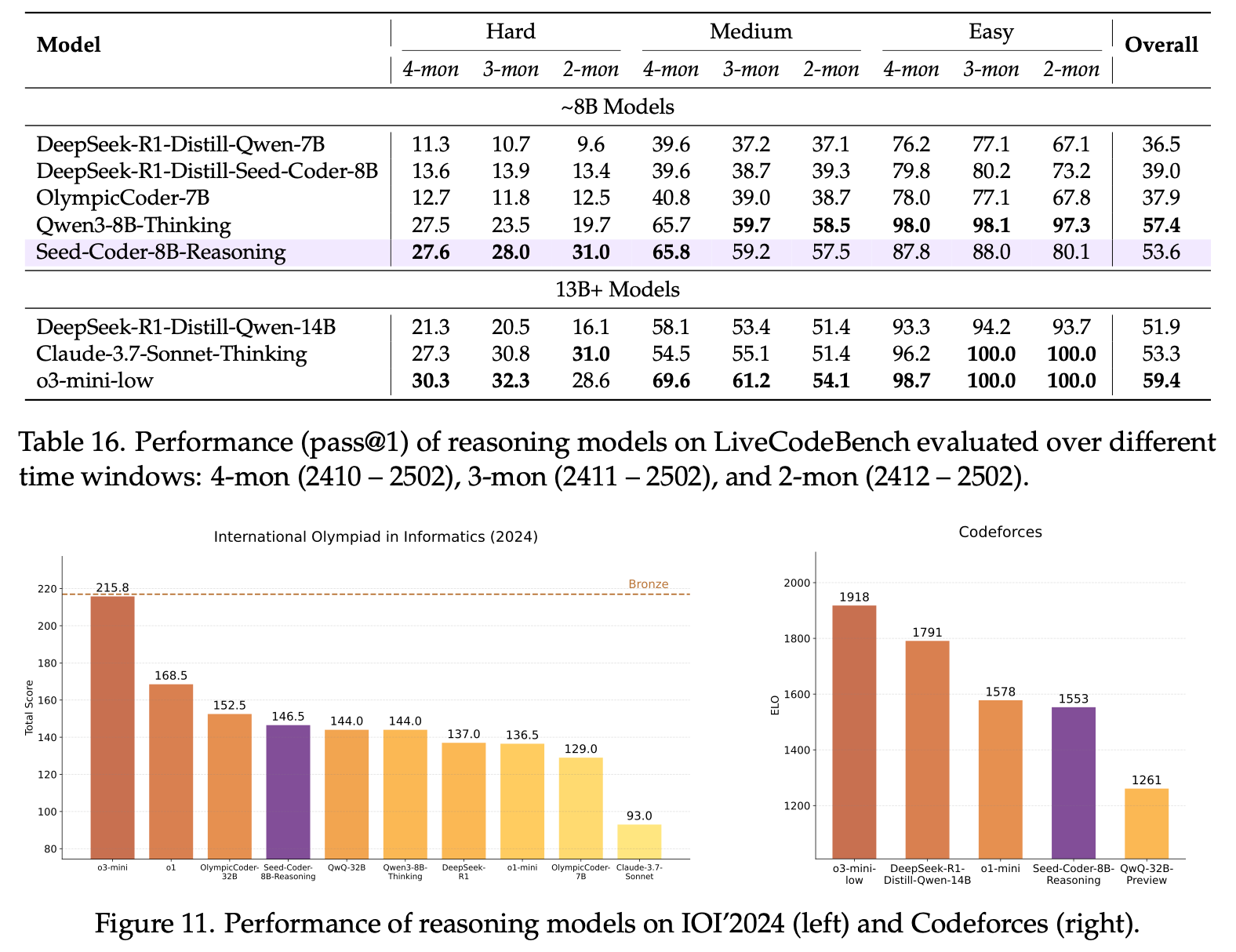
值得一提的是,该模型默认精度为 FP32,应外部反馈,我们近日还在 Hugging Face 提供了 BF16 精度的版本,供大家选用,上下文窗口均为 64K,点击直达开源模型入口。
5. 写在最后
作为面向研究的开源模型系列,Seed-Coder 的主要目标是验证代码数据的构建策略,因此,该模型仅在团队构建的 6 trillion tokens 代码数据上预训练。相比领先的通用开源模型(如 Qwen3 在 36 trillion tokens 上进行预训练),其对通用自然语言的理解和对非代码任务的处理表现仍十分有限。
随着语言模型能力不断进步,团队认为,未来依托更前沿 LLM 的过滤器或将进一步提升代码数据质量,进而推动通用模型代码能力提升。
未来,团队将基于本次观察,探索代码数据对通用模型能力的更大提升,并持续探索数据与模型 Scaling 对 AI 代码能力提升的影响。