Seed Research│通用机器人模型 GR-3 发布!支持高泛化、长程任务、柔性物体双臂操作
Seed Research│通用机器人模型 GR-3 发布!支持高泛化、长程任务、柔性物体双臂操作
日期
2025-07-22
分类
模型发布

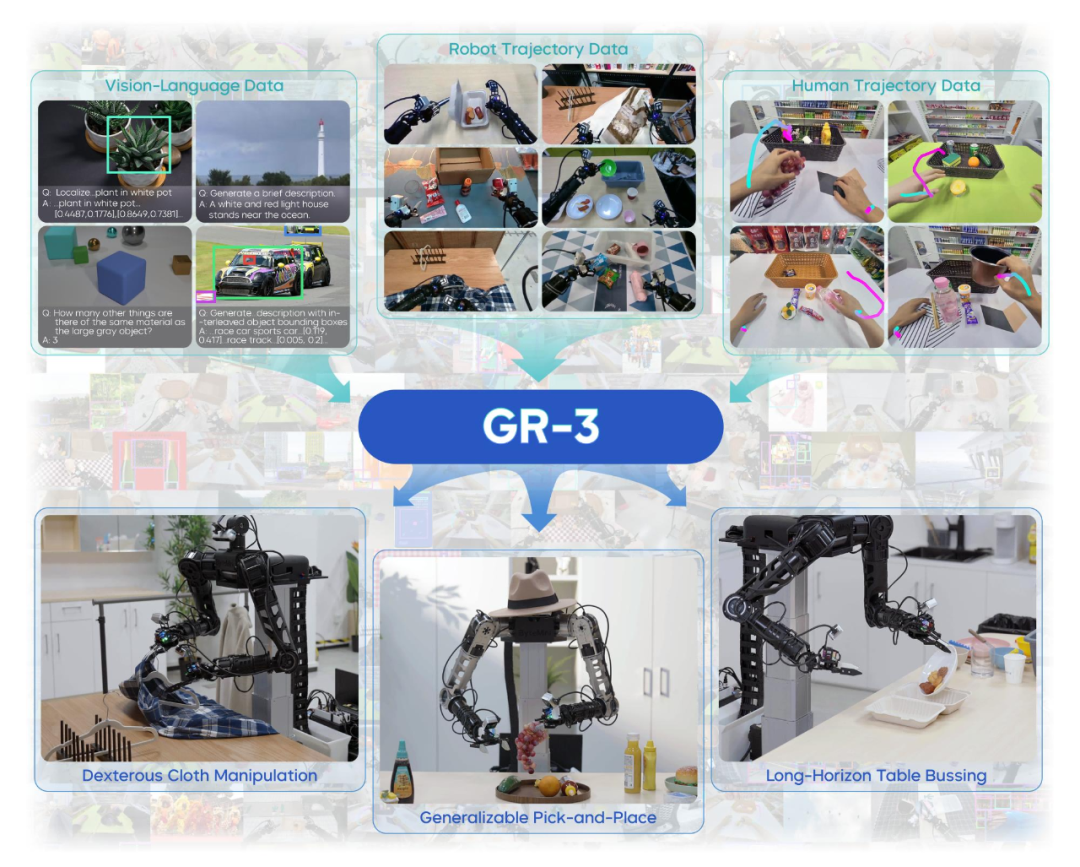
Seed GR-3 是字节跳动 Seed 团队提出的全新 Vision-Language-Action Model(VLA)模型,它具备泛化到新物体和新环境的能力,能理解包含抽象概念的语言指令,还能够精细地操作柔性物体。
与此前需要大量机器人轨迹训练的 VLA 模型不同,GR-3 通过少量的人类数据即可实现高效微调, 从而快速且低成本地迁移至新任务,以及认识新物体。
此外,得益于改进的模型结构,GR-3 能有效处理长程任务并能进行高灵巧度的操作, 包括双手协同操作、柔性物体操作,以及融合底盘移动的全身操作等。
具体而言,这些能力是通过一种多样的模型训练方法实现的:除遥操作机器人收集的高质量真机数据外,负责实验室采集的同学基于 VR 设备构建了人类轨迹数据,以及公开、可用的大规模视觉语言数据进行联合训练——多样性数据的融合是 GR-3 区别于现有 VLA 模型的亮点之一。
同时,字节跳动 Seed 团队还开发了一款具备高灵活性、高可靠性的通用双臂移动机器人 ByteMini: 22 个全身自由度以及独特的手腕球角设计,使它能够像人类一样灵活,在狭小空间中完成各种精细操作。ByteMini 作为机器人本体,携带 GR-3 模型这颗“机器人大脑”,可高效在真实环境中处理复杂任务。
GR-3 在各类任务中展现的特点包括:
“心灵”: GR-3 在超长序列(子任务数≥ 10)的餐桌整理任务中,可高鲁棒性、高成功率地完成任务,并在过程中严格跟随人类发出的分步指令;
“手巧”: GR-3 在复杂灵巧的挂衣服任务中,能够控制双臂协同操作可形变的柔性物体,甚至可以鲁棒地识别并整理不同摆放方式的衣物;
泛化好: GR-3 在各类物体的抓取放置任务中,可以泛化到抓取未见过的物体,同时可理解包含复杂抽象概念的指令。
经过团队上千次系统性实验测试,GR-3 表现超过业界此前可测试具体性能的 VLA 头部模型 π0。未来,团队希望 GR-3 可以成为迈向通用机器人“大脑”的重要一步。

以 GR-3 为大脑的 ByteMini 机器人高效完成各类通用家庭任务。
为什么机器人只能清扫地面 无法收拾衣服、整理餐桌?
在技术层面,让机器人像人类一样灵活地应对纷繁复杂的日常家务,做到“听得懂、学得快、做得好”,其实比想象中难得多,这也是机器人拥有“通用大脑”的关键瓶颈之一。具体难点包括:
听不懂: 人类说话太“模糊”。我们会说“把左边的书放到最高层”,“最大的物体放进箱子里”,这些表达里藏着“左边”“最大”等抽象概念,机器人得先理解这些复杂指令,才能动手做事。在过去,机器人往往“一根筋”,换个说法就听不懂了。
不灵活: 现实世界太“善变”了。今天杯子放在餐桌中央,明天可能被随手搁到餐桌边缘;今天去了趟商场,明天餐桌上可能会多出新的杯子、衣柜多出新的衣服——这些都是机器人从未见过的。通用场景的多样性与易变性,要求机器人必须具备超强的泛化与学习能力,才能轻松应对每天都在变化的场景和新物品。
做不好: 家务大多是麻烦的“长程任务”。比如收拾餐桌,包含:打包剩菜、收纳餐具、清理垃圾,中间哪一步出错都导致完不成任务。传统机器人经常做到一半就“乱了套”,甚至会面对“不可能完成的指令”(如把不存在的勺子放进碗里)傻乎乎地瞎忙活。
上述问题中包含许多复杂、抽象、难以建模的现实场景,传统 Rule-Based 的方法难以用穷举法覆盖。
为此,字节跳动 Seed 团队探索融合大模型与机器人技术,研发了 GR-3 机器人操作大模型,希望让机器人“听得懂、学得快、做得好”,离理想中的“机器人全能助手”更近一步。
GR-3 三项关键设计:融合大脑+丰富数据+灵活身体
在技术上,GR-3 采用多项突破性设计,具体如下:
融合视觉-语言-动作信息的“大脑”
GR-3 采用 Mixture-of-Transformers (MoT)的网络结构,把“视觉-语言模块”和“动作生成模块”结合成了一个 40 亿参数的端到端模型。
其中,动作生成模块是一个 Diffusion Transformer (DiT),它利用 Flow-Matching 的方式生成动作,同时,GR-3 会在 DiT block 的 Attention 和 FFN 中加入归一化的 RMSNorm,这个设计让 GR-3 进一步增强了动态指令跟随的能力。
就像人类先通过眼睛和耳朵接收信息,再用大脑指挥手脚一样,GR-3 能直接根据摄像头“看到”的画面与收到的语言指令,计算出下一步该怎么动——比如看到“餐桌”、听到“收拾”后,直接做出“打包剩菜 →收拾餐具 → 倒垃圾”的连续动作。
三合一数据训练法
GR-3 突破了传统机器人只学“机器人数据”的局限,在训练中能够同时从三种数据源中学习知识:
遥操作获取的机器人数据: GR-3 的训练利用了遥操作收集机器人完成“捡杯子”、“挂衣服”的动作轨迹,这类数据保证了机器人基础的操作能力;
人类 VR 轨迹数据: GR-3 还能使用 VR 设备采集人类的轨迹数据进行学习,这个方法突破了 VLA 模型数据瓶颈,让机器人以极低的成本快速学习新任务。团队发现,利用 VR 设备采集人类的轨迹数据,效率上会比遥操作收集机器人数据快近一倍(450 条/小时 vs 250 条/小时);
公开可用的图文数据: GR-3 能从公开可用的图片和文字中认识物体(比如认识“葡萄”、“筷子”)、学习抽象概念(比如理解“大”、“小”、“左边”、“右边”的意思),这类数据极大地提升了 GR-3 的泛化能力;
量身定制的“身体”
配套设计的 ByteMini 机器人,是专为 GR-3 这颗“大脑”打造的“灵活躯体”:
整体运动层面,ByteMini 机器人搭载了全身运动控制(WBC)系统,动作“又快又稳又软”,在遥操作数据采集时,系统能够产生平滑的轨迹数据,同时不会像传统机器人那样“硬邦邦”地撞东西,比如抓纸杯时会自动调整力度,避免捏碎;
精细执行层面,ByteMini 机器人全身具备 22 个自由度,搭载了无偏置 7 个自由度机械臂,同时机械臂的手腕采用了独特的球形设计,能够像人类手腕一样灵活转动,适合在收纳盒、抽屉等狭小空间里进行灵活操作;
感知层面,ByteMini 机器人搭载了多颗摄像头,其中 2 个手腕的摄像头看细节(比如捏杯子的角度),头部摄像头看全局(比如桌子上有哪些东西),保证“眼观六路”。
GR-3 机器人操作 VLA 大模型
以上关键技术设计,让 GR-3 既能懂抽象概念,又能快速学习新技能,还能精准动手,突破了传统机器人“认死理、学太慢、做不细”的瓶颈。
通用任务展现较高泛化性支持长程与精细操作任务
Seed 团队在三个高难度的操作任务中测试了 GR-3 模型。
通用拾取放置任务:泛化性突出
在此类任务中,团队使用了 99 个现实物品,对 GR-3 及两个对比模型进行测试,针对不同的物品和模型,交叉进行了 861 次模型测试,在不同场景中有如下发现:
基础场景测试: 团队在训练中见过的环境里,测试 GR-3 操作训练中见过的物品的能力,结果发现,GR-3 的指令遵循率和成功率分别为 98.1% 和 96.3%,能精准执行 “把 A 放进 B”这类基础指令;

通用拾取放置测试中用到的物体:左为训练中见过的物体,右为训练中未见过的物体。
新环境考验: 团队提高难度,将测试环境换到训练中从未见过的卧室书桌、超市柜台、会议室与茶水间 4 种场景,发现GR-3 在这些新环境中性能几乎无衰减,说明它对环境变化不 “敏感”,具备新环境的适应和泛化能力;

通用拾取放置任务的测试环境:Basic 为训练中见过的场景,其他四个为训练中未见过的场景。
复杂指令理解: 团队测试了 GR-3 对带有抽象概念的复杂指令的理解能力,结果显示,GR-3 能精准处理 “把雪碧旁边的可乐放进盘子里”、“把面包放进更大的盘子里”、“把陆地上的动物放进盘子里” 这类涉及空间关系、物体尺寸等抽象概念的指令(参考如下视频),而测试中基准模型在此类任务可能会混淆物体;
把雪碧旁边的可乐放进盘子里
把面包放进更大的盘子里
把陆地上的动物放进盘子里
新物品挑战: 团队测试了 GR-3 面对训练中未见过物品的操作能力,使用 GR-3 让机器人抓取新物品的实验结果显示,依靠从公开图文数据中积累的 “见识”,GR-3 的成功率较基准模型 π0 高出 17.8%。
通过上面四个维度的测试,并对比未采用公开图文数据训练的 GR-3 模型(图中被标注为:GR-3 w/o Co-Training),结果表明:
在基础场景和新环境中,加入公开可用的图文数据进行训练不会带来能力损失;在未见过的复杂指令和新物品任务中,这部分数据分别能带来 42.8% 和 33.4% 的成功率提升。
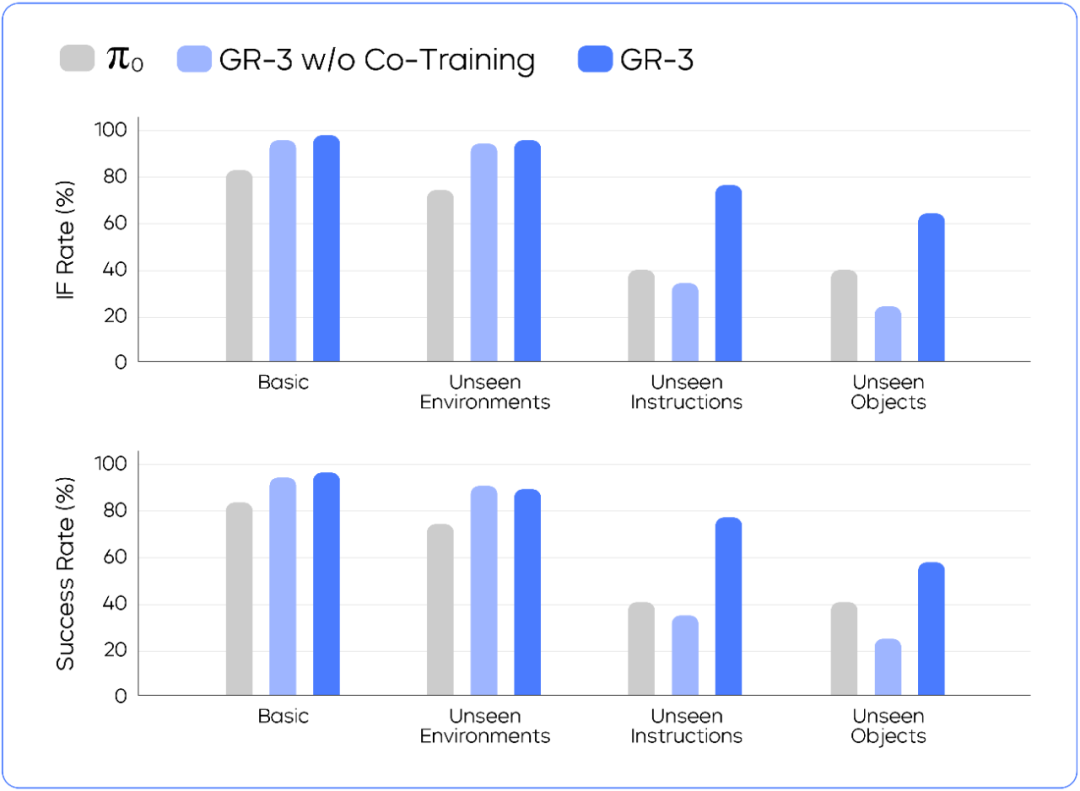
通用拾取放置任务测试结果,GR-3 在四个测试设置中都超越了基准模型。
为持续提升 GR-3 应对未见过物体的能力,团队利用 VR 设备采集了人类操作物体的数据,结果发现:
只需要通过 VR 设备对相应物品采集 10 条轨迹数据,就可以让 GR-3 操作这些物体的成功率从不到 60% 提升到超过 80%。
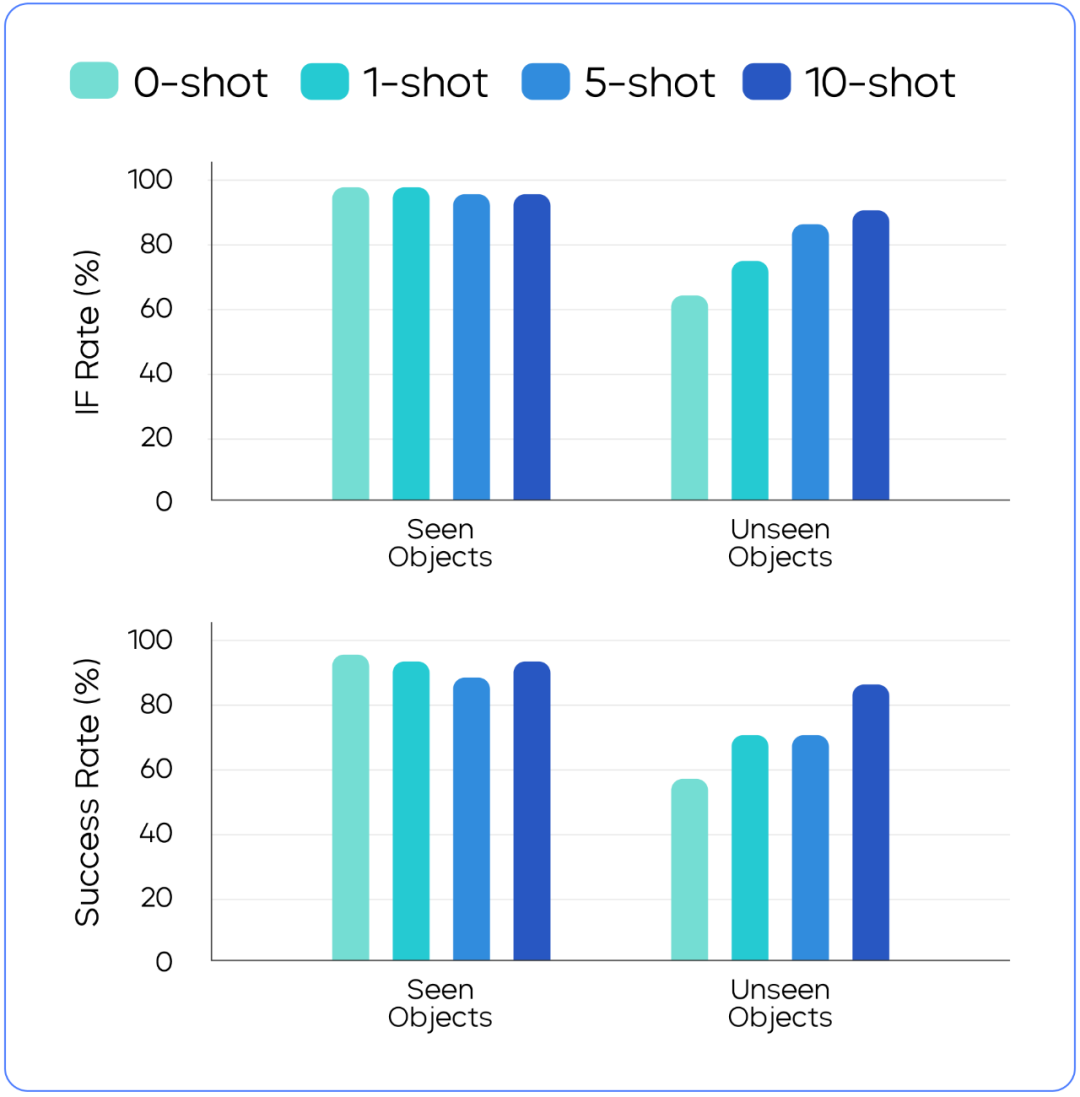
加入人类轨迹数据持续训练能让 GR-3 快速学习新的任务。对于机器人数据中未见过的物体来说,轨迹量加得越多,性能提升越高。对于机器人数据中见过的物体,增加人类轨迹数据对性能影响不大。
长程餐桌清理任务:多步骤“稳得住”
在餐桌清理这个长程任务中,团队发现,GR-3 仅靠 “收拾餐桌” 这样一个总指令,就能自主完成 “打包剩菜→收餐具→倒垃圾→端起收纳盒” 的全流程,平均完成度超过 95%。
GR-3 能完成不同餐具随意摆放的餐桌清理任务(机器人第一视角)

长程餐桌清理测试中用到的物体
团队还同时测试了 GR-3 跟随分步指令的能力,结果发现:
GR-3 在跟随语言指令上,领先基准模型,面对多件同类物品(如多个杯子),GR-3 能按指令将他们“全放进垃圾桶”,若指令无效(如餐桌上没有蓝色的碗,指令为“把蓝色碗放进篮子”),GR-3 能准确判断并保持不动,而基准模型则会随机拿取物品。

GR-3 能严格跟随人类发出的分步指令
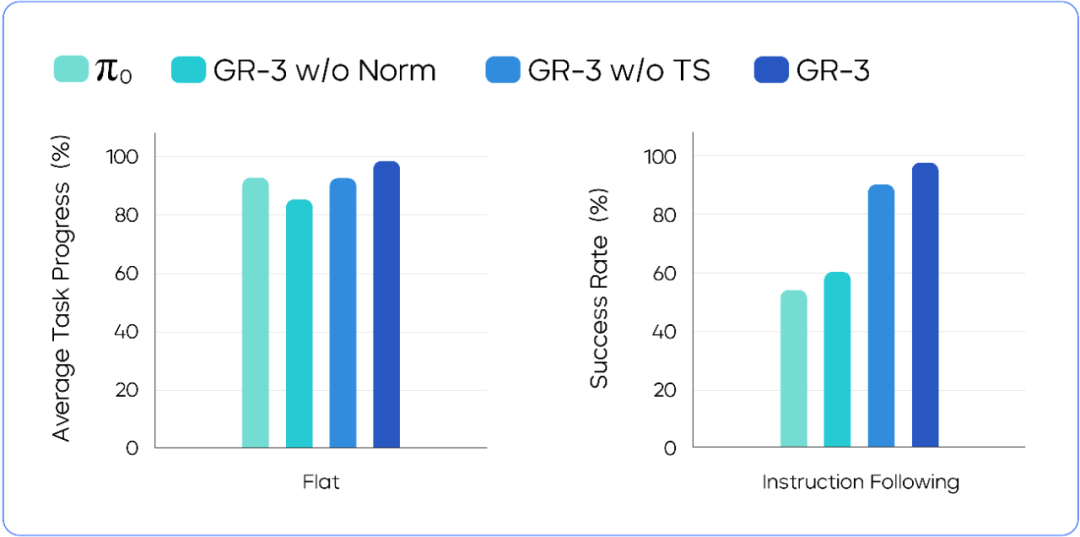
长程餐桌清理任务&跟随语言指令的模型性能对比
柔性衣物精细操作任务:展现灵活度
在机器人操作中,柔性物体操作一直是一大难题,团队在颇有挑战的挂衣服任务上测试了 GR-3。在这个任务中,机器人需要把衣架穿进衣服中,并将其挂在晾衣杆上。
测试发现,GR-3 在该类任务中平均完成度达到 86.7%。即使在衣服摆放状态比较混乱的情况,GR-3 也能稳定鲁棒地应对。
对随意摆放的不同衣物,GR-3 都能完成挂衣服任务
此外,GR-3 还能泛化到机器人数据中未包含的衣服。例如,当机器人数据中的衣服均为长袖款式时,GR-3 对短袖衣物同样能有效处理。

柔性衣物精细操作中机器人训练数据中见过(均为长袖款式)和未见过的衣服(有短袖款式),以及衣物不同的摆放状态。
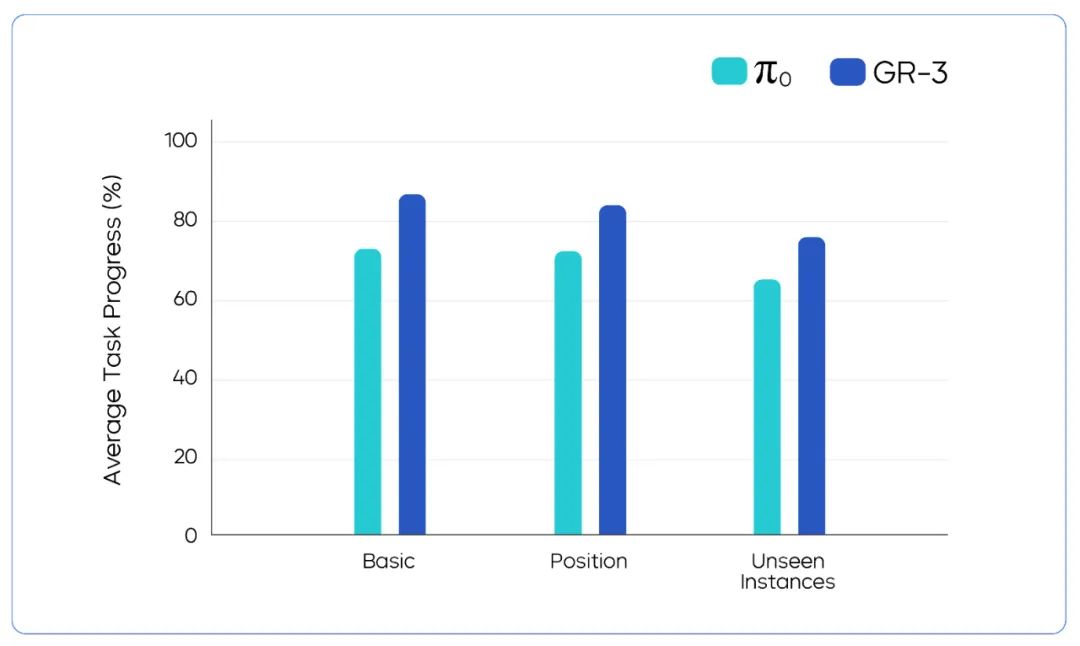
柔性衣物精细操作任务的模型性能对比
总结与展望
字节跳动 Seed 团队会持续在机器人领域研究探索,让机器人操作大模型在复杂真实场景中更加可靠、灵活与智能,后续研究计划包括:
扩大模型规模和训练数据量,进一步提升泛化性。 尽管目前 GR-3 泛化能力良好,但面对完全陌生的复杂概念或特殊形状的物体时,还是会出现指令理解偏差或抓取失误。团队计划增加更多样的训练数据——包括更多物体的视觉语言数据、包含更复杂任务的机器人数据,以及扩大模型参数规模,提升 GR-3 对“未知”的泛化能力。
引入 RL 方法,突破现有模仿学习的局限。 GR-3 和多数机器人模型一样,本质是“模仿”人类专家的动作,当遇到训练中没见过的突发情况(比如抓取时物体意外滑落、环境突然变化)时,容易“卡壳”。为此,团队计划引入强化学习训练,让机器人在实际操作中不断“试错”,从成功和失败中自主学习调整动作与策略(比如物体滑落时如何快速重新抓取等),进而逐步增强其在复杂、精细任务中的抗干扰能力和鲁棒性,让 GR-3 不仅能“模仿”,还能像人类一样“灵活应变”。
团队期望,有朝一日机器人操作大模型能真正进入人们的日常生活,成为帮助人类处理各种事务的通用机器人“大脑”。