Seed1.6 系列模型技术介绍
Seed1.6 系列模型技术介绍
日期
2025-06-25
分类
模型发布
Seed1.6 是字节跳动 Seed 团队推出的最新通用模型系列,融合了多模态能力,支持自适应的深度思考、多模态理解、图形界面操作,且支持 256K 长上下文的深度推理。目前,Seed1.6 系列已通过火山引擎对外开放 API 调用,体验入口可在文末获取。
在 Seed1.6 模型系列中,我们探索了 Adaptive CoT 技术,让模型能够根据问题难度自动触发思考过程,取得了模型效果和推理性能的平衡。
同时,Seed1.6 系列模型在多项 benchmark 上表现较好,包括在多项视觉任务上表现接近或超过 Seed1.5-VL,在国内外高考试题等泛化测试中也取得了优秀的分数。
预训练融合多模态能力 支持 256K 上下文
Seed1.6 沿用 Seed1.5 在稀疏 MoE 上的探索结果,使用 23B 激活、230B 总参数进行预训练。在持续预训练阶段融合了多模态能力,同时支持文本和视觉能力,其预训练分为三个阶段:
- 第一阶段为纯文本预训练。此阶段的训练数据主要由网页、书籍、论文、代码等数据组成。我们通过基于规则和模型的多种数据清洗、过滤、去重与采样策略,提升了预训练数据的质量和知识密度。
- 第二阶段为多模态混合持续训练(Multimodal Mixed Continual Training, MMCT)。此阶段进一步提升了文本数据的知识和推理密度,增加了学科、代码、推理类数据的占比;同时加入了视觉模态的数据,和高质量文本数据混合训练。
- 第三阶段为长上下文持续训练阶段(Long-context Continual Training, LongCT)。此阶段使用不同长度范围的长文数据,逐步将模型的最大序列长度从 32K 提升至 256K。
通过对模型架构、训练算法和 infra 的持续改进,Seed1.6 Base 模型性能在参数规模接近的情况下较 Seed1.5 Base 取得明显提升,为后续的 Post-training 工作提供了良好的基础。
Seed1.6 Base 的 LLM 评估指标如下:
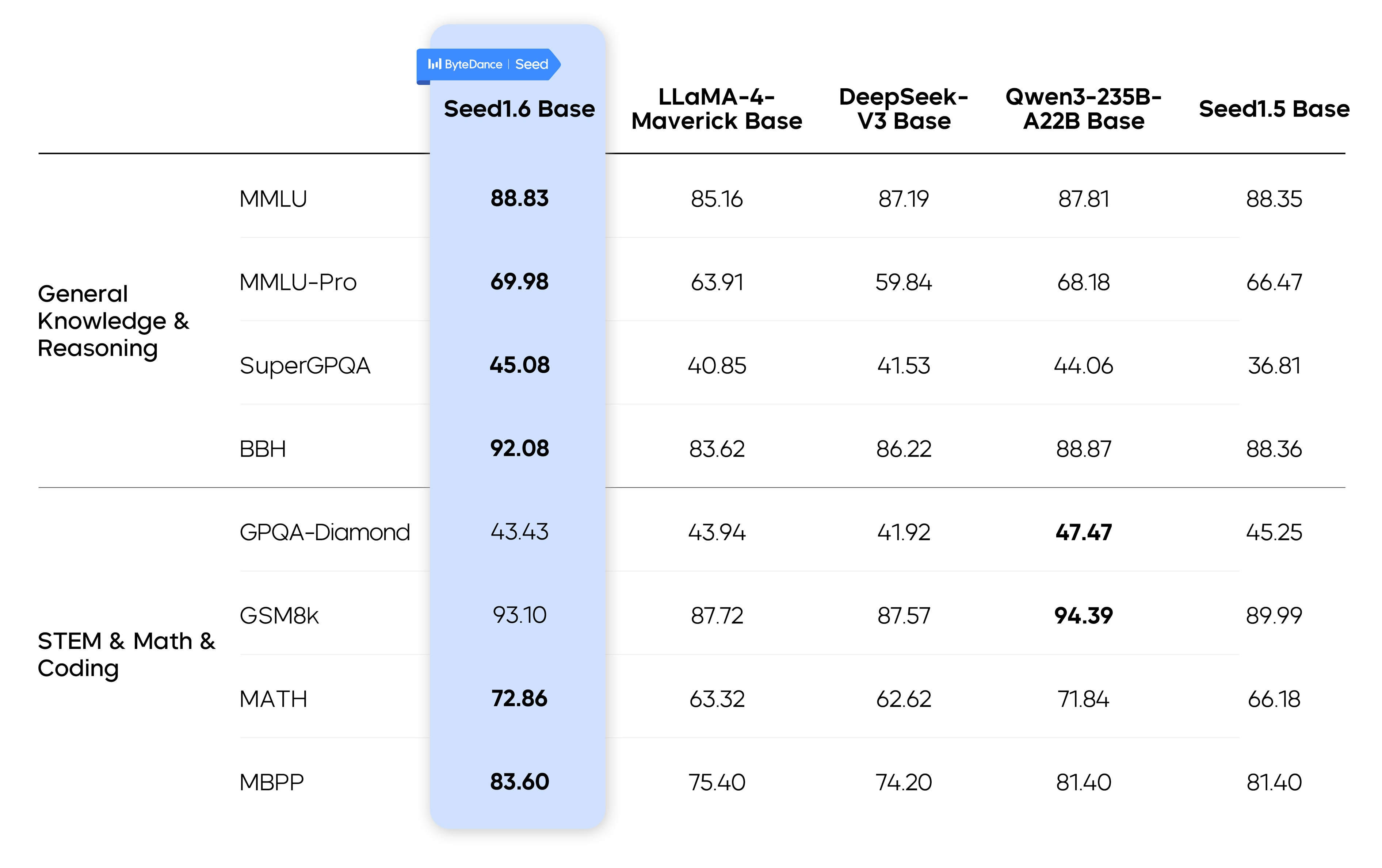
注:外部模型指标均来自 Qwen3 Technical Report
后训练强化推理能力 Adaptive CoT 压缩思维链
基于高效预训练的基础模型,我们在 Post-training 阶段研发了 Seed1.6-Thinking 和 Seed1.6 (Adaptive CoT)。Seed1.6-Thinking 专注于融合了 VLM 各项能力后,通过更长的思考过程实现极致推理效果;Seed1.6 通过动态思考技术,在保证效果的同时压缩 CoT 长度,在性能和效果上实现更好的动态平衡。未来,我们计划将极致推理效果和动态思考技术融合到一个模型,为用户提供更智能的模型。
多模态融合的思考能力
Seed1.6-Thinking 总体延续 Seed1.5-Thinking 的训练方法,训练过程中采用了多阶段的 RFT 和 RL 迭代优化,每一轮 RL 以上一轮 RFT 为起点,在 RFT 候选的筛选上使用多维度的 reward model 选择最优回答。
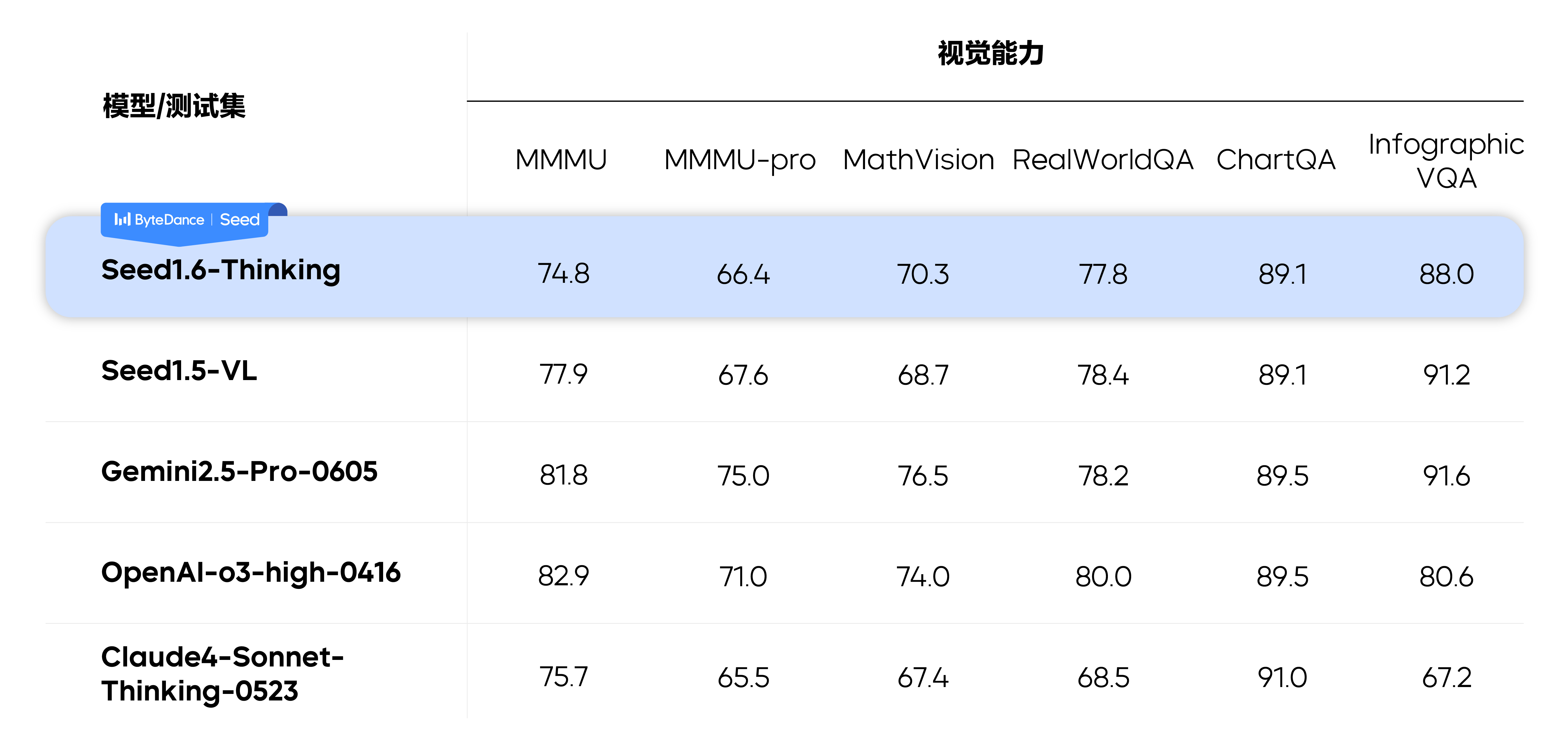
同时,Seed1.6-Thinking 在 Seed1.5-Thinking 的基础上拓展了训练算力,加大了高质量训练数据规模(包括 Math、Code、Puzzle 和 Non-reasoning 等数据),提升了模型在复杂问题上的思考长度,并且在模型能力维度上深度融合了 VLM,给模型带来清晰的视觉理解能力。因此,对比 Seed1.5-Thinking,Seed1.6-Thinking 在复杂文本场景中的推理能力明显提升,同时也具备了较好的视觉推理能力。
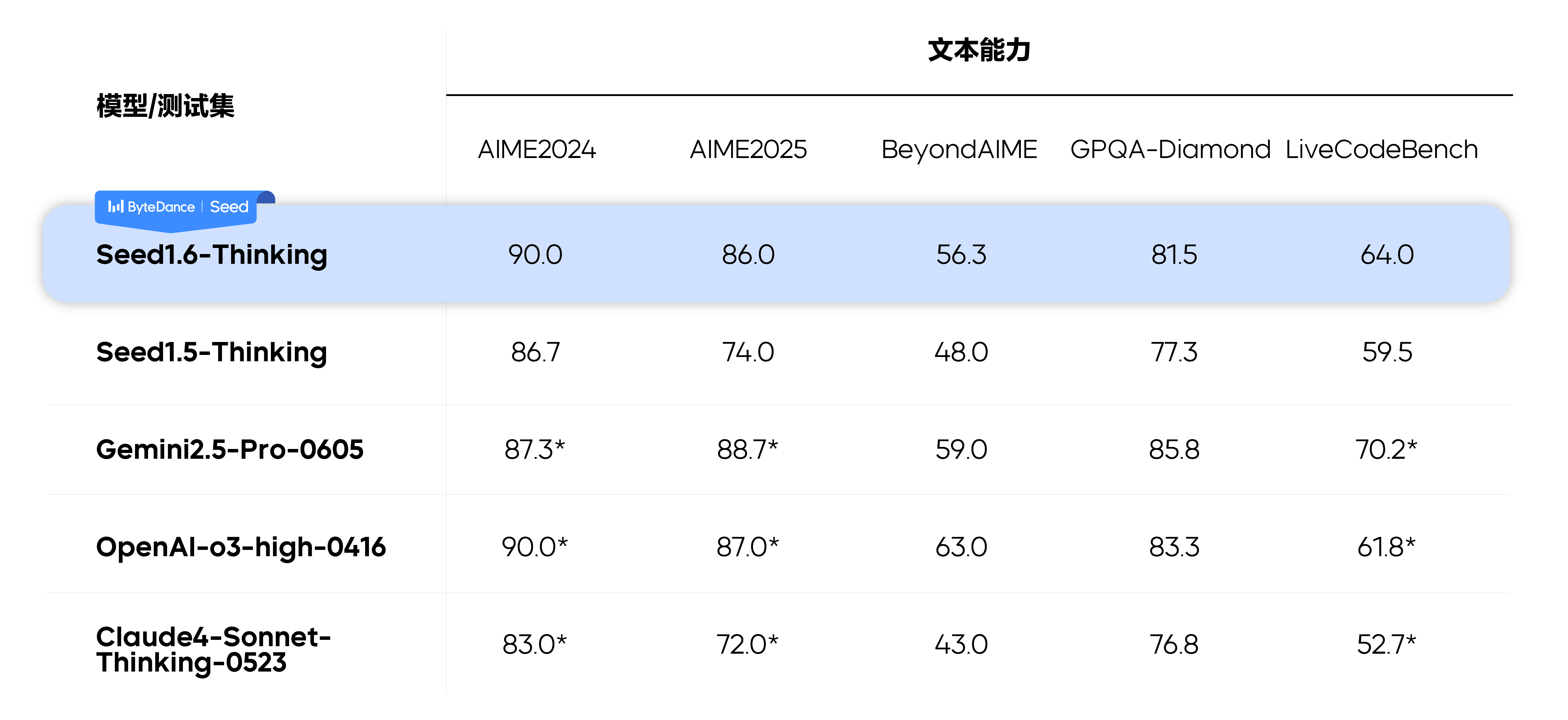
注:标*为 Seed 团队测试结果
为了进一步强化模型思考能力,Seed1.6-Thinking 也引入了 parallel decoding,可以在给出答案之前,使用更多的思考 token,这也是一种无需训练即可扩展模型能力的方法。我们发现对于比较困难的任务,parallel decoding 可以明显提升模型效果。比如在高难度测试集 Beyond AIME 上,Seed1.6-Thinking 的测试结果实现了 8 分的提升,在代码任务上的测试结果也有明显的提升。
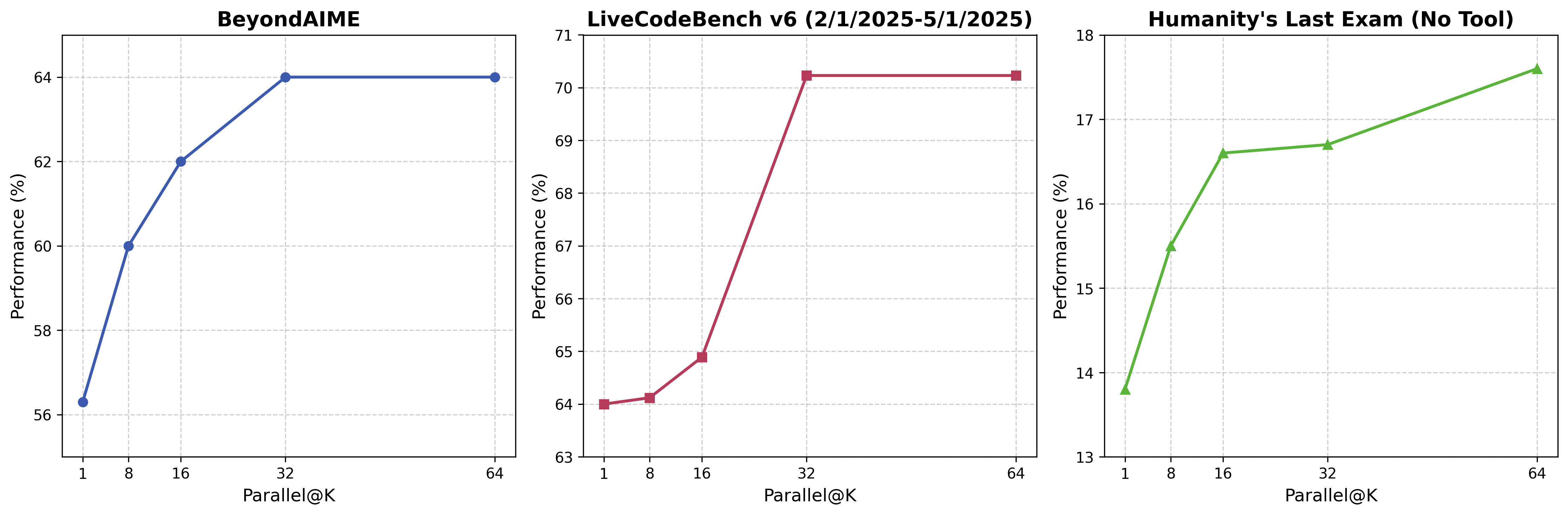
注: 采用 parallel decoding 后,Seed1.6-Thinking 测试结果变化
动态思考能力
深度思考模型在数学、编程等高难度领域展现了令人印象深刻的能力,其核心因素是 long CoT 大幅增强了模型的推理能力。但同时也容易带来过度思考的问题——深度思考模型会无差别地用 long CoT 进行输出。在 CoT scaling 的过程中,模型会生成过多无用“token”,这些“token”本质上不能提升回答的准确率,但却增加了推理负担。
为此,Seed1.6 提出了“动态思考能力”(Adaptive CoT, AdaCoT),提供全思考、不思考、自适应思考三种推理模式,在保证效果的同时大幅压缩了 CoT 长度。为了实现动态思考能力,团队在 RL 训练中引入新的奖励函数——惩罚过度思考、奖励恰当思考。具备“动态思考能力”的模型可以通过 prompt 设置让模型在推理过程中处于以下思考模式:
- 全思考(FullCoT):对所有 prompt 都会进行思考再给出回答,效果与 Seed1.6-Thinking 持平,同时对 CoT 长度进行了压缩
- 不思考(NoCoT):对所有 prompt 都不会进行思考,直接回答,效率更高
- 自适应思考(AdaCoT):以上两种模式的融合,模型会根据不同的 prompt,自动选择是否进行思考
下表给出了动态思考模型在公开测试集上的指标:
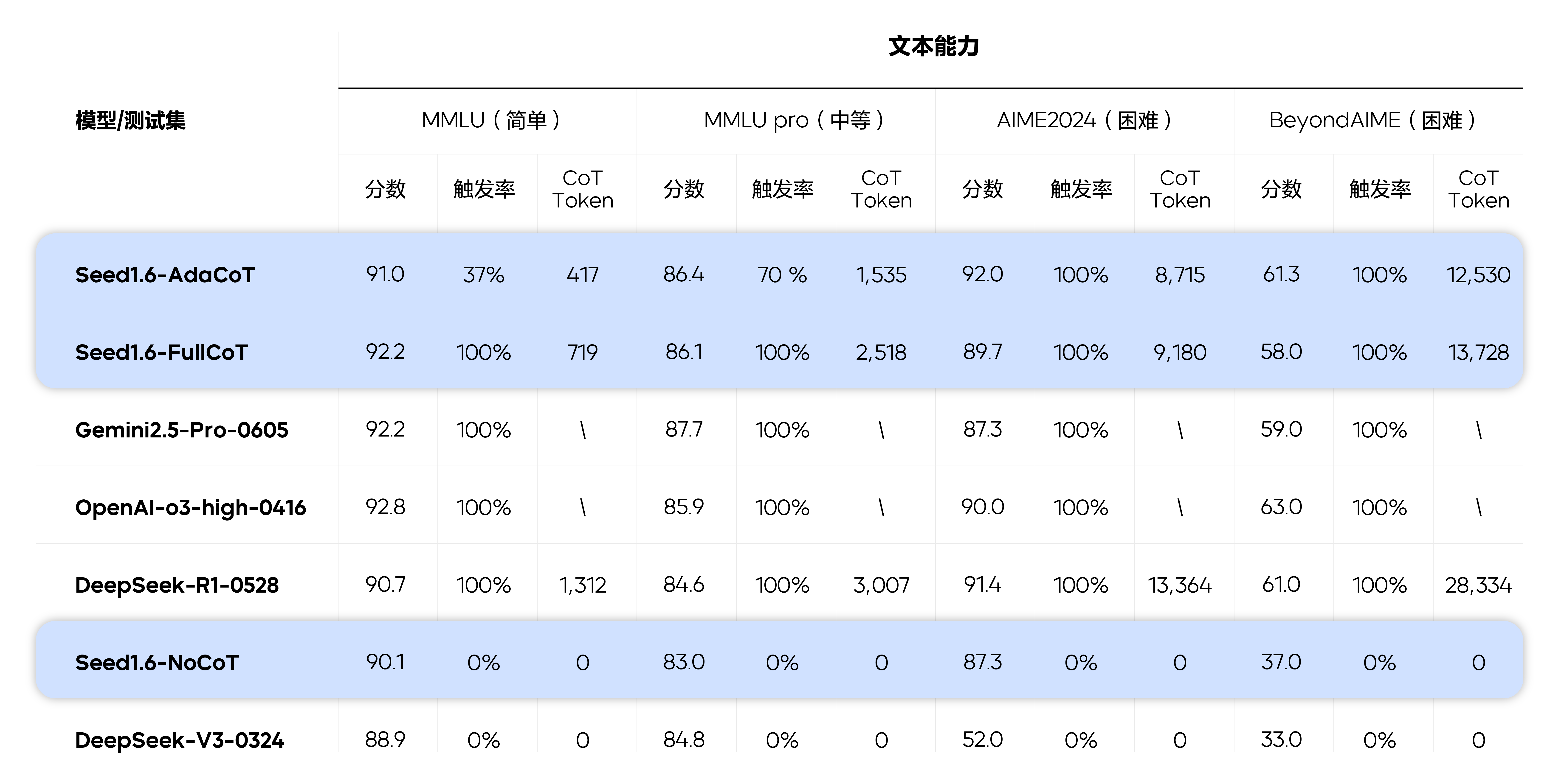
其他模型官方公布的结果采用官方数据,官方未公布结果采用 Seed 团队测试结果;
Gemini 和 OpenAI 系列模型无完整 CoT,平均 Token 用\表示;
DeepSeek 的平均 CoT Token 来自 Seed 团队测试结果。
在 MMLU、MMLU pro 等简单或中等难度的任务上,Seed1.6-AdaCoT 表现出不同的 CoT 触发率,在 MMLU 上 CoT 触发率达 37%,在 MMLU pro 上 CoT 触发率达 70%,和难度呈相关关系。在这类任务中,模型在性能未下降的情况下有效节省了 token 数。在 AIME、BeyondAIME 等困难任务上,Seed1.6-AdaCoT 的 CoT 触发率达到 90~100%,且效果与 Seed1.6-FullCoT 相当,说明自适应思考保留了 Long CoT 给模型带来的推理能力优势。同时,我们也发现 AdaCoT 的方法在多模态场景同样有效。
泛化测试结果突出 文理学科表现均衡
在传统 benchmark 评测之外,我们评测了模型在两个国家大学入学考试中的结果,验证模型在泛化测试上的表现。
2025 高考试题测试
国内高考题目全面,包括文科和理科,覆盖对模型文本和图像理解能力的考察。同时题目比较新,能够反映模型的泛化能力。我们采用了 2025 年山东卷高考真题(题目源自网络)进行测试,语数外采用新课标全国 Ⅰ 卷,其余科目为山东省自主命题,满分 750 分。评测方式参考高考判卷方法,确保评估真实可信:
- 选择题、填空题:封闭题机判,自动评估,人工质检
- 开放题:由两位来自重点高中、有联考判卷经验的高中老师进行匿名评估,后续引入了多轮质检
整个测试中,团队未引入 prompting engineering 来提升模型效果,所有输入均为来自网络的高考原题。
评分明细详见:https://bytedance.sg.larkoffice.com/sheets/QgoFs7RBjhnrUXtCBsYl0Jg2gmg
在总分计算上,采用 3(语数外)+3(理综/文综)的形式对 5 个模型进行排名,包括了业界主流的推理模型:Gemini2.5-Pro-0605、Seed1.6-Thinking、DeepSeek-R1-0528、Claude-Sonnet-4、OpenAI-o3-high-0416。
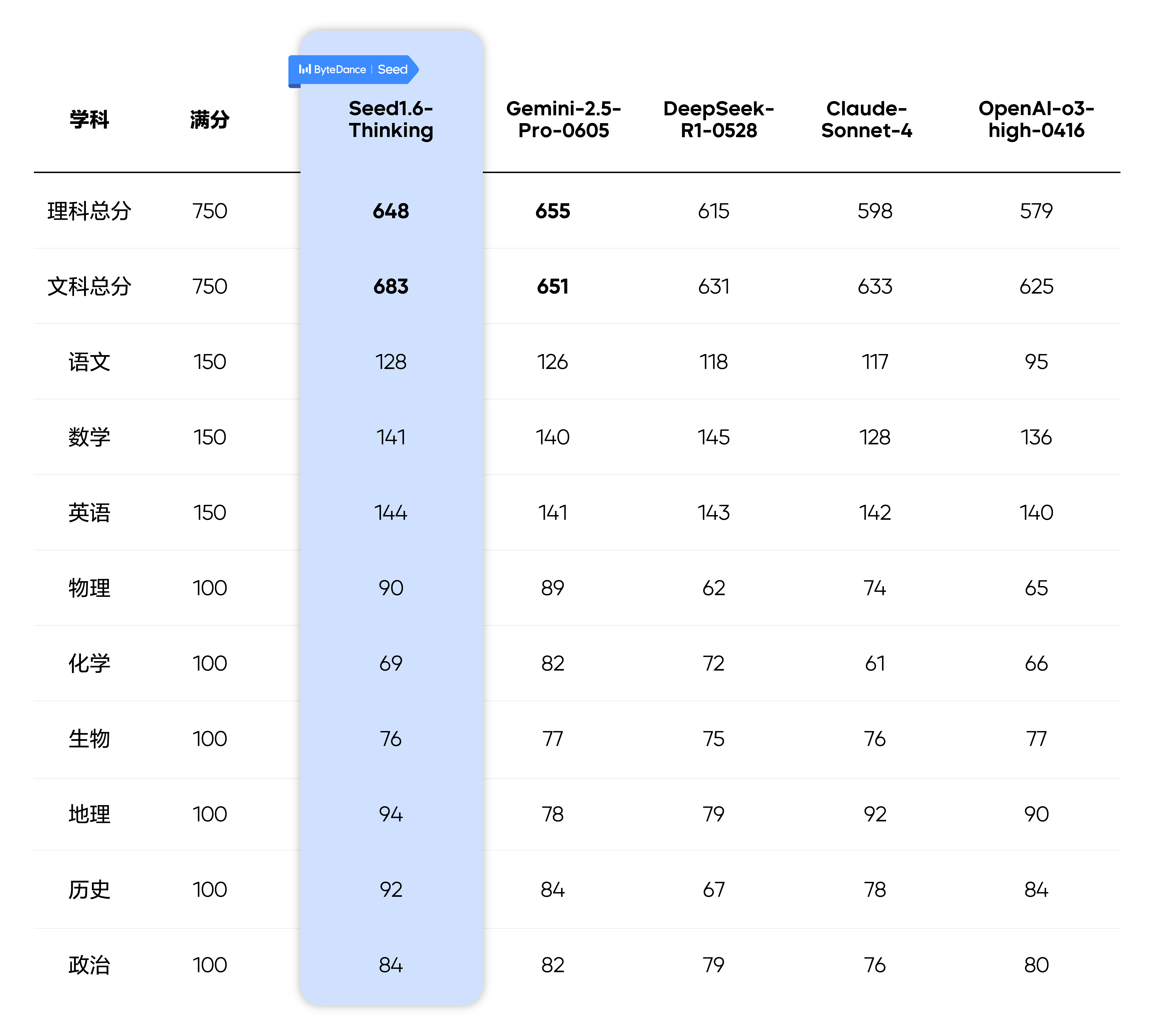
DeepSeek R1 输入为题目文本,其余模型为题目文本+题目截图;
默认所有模型在英语听力上均取得满分。
在理科上,Seed1.6-Thinking 位于第二名,达到 648 分,其中物理表现比较突出;在文科上,Seed1.6-Thinking 排名第一,为 683 分,地理和历史优势较大。其文科和理科分数均超出大部分 985 高校往年录取分数线。
可以看出,在语、数、外等基础学科中,上述模型大多表现较好,基本达到了优秀考生的水平,分数区分度已经不大。化学和生物涉及比较多的读图题,由于题目不是官方发布,图比较模糊,因此各模型失分较多。Gemini2.5-Pro-0605 多模态能力比较优秀,在化学上体现明显。
近日,在获得更高清版本的高考试题图后,我们重新采用图文交织的方式,对图片理解依赖比较强的科目(生物和化学)重新进行推理测试,发现 Seed1.6-Thinking 在生化两科上的总分可再提升近 30 分(理科总分达到 676)。这说明结合文本和图片进行全模态推理可以更大程度激发模型的潜力,相信这也是未来值得投入的研究方向。

注:图文交织输入示例
JEE Advanced 试题测试
JEE Advanced 是印度理工学院的第二阶段入学考试,每年数百万人参加第一阶段考试,其中前 25 万人进入第二阶段考试。考试分两场,每场 3 小时,同时考察数学、物理、化学三科。
团队采用 JEE Advanced 题目进一步测试模型,输入为图片形式,同时考察模型在多模态和推理上的泛化能力。题目均为客观题目,每道题目均做了 5 次采样,按照 JEE 考试规则打分,根据题型答对得分、答错扣分,不考虑格式问题。
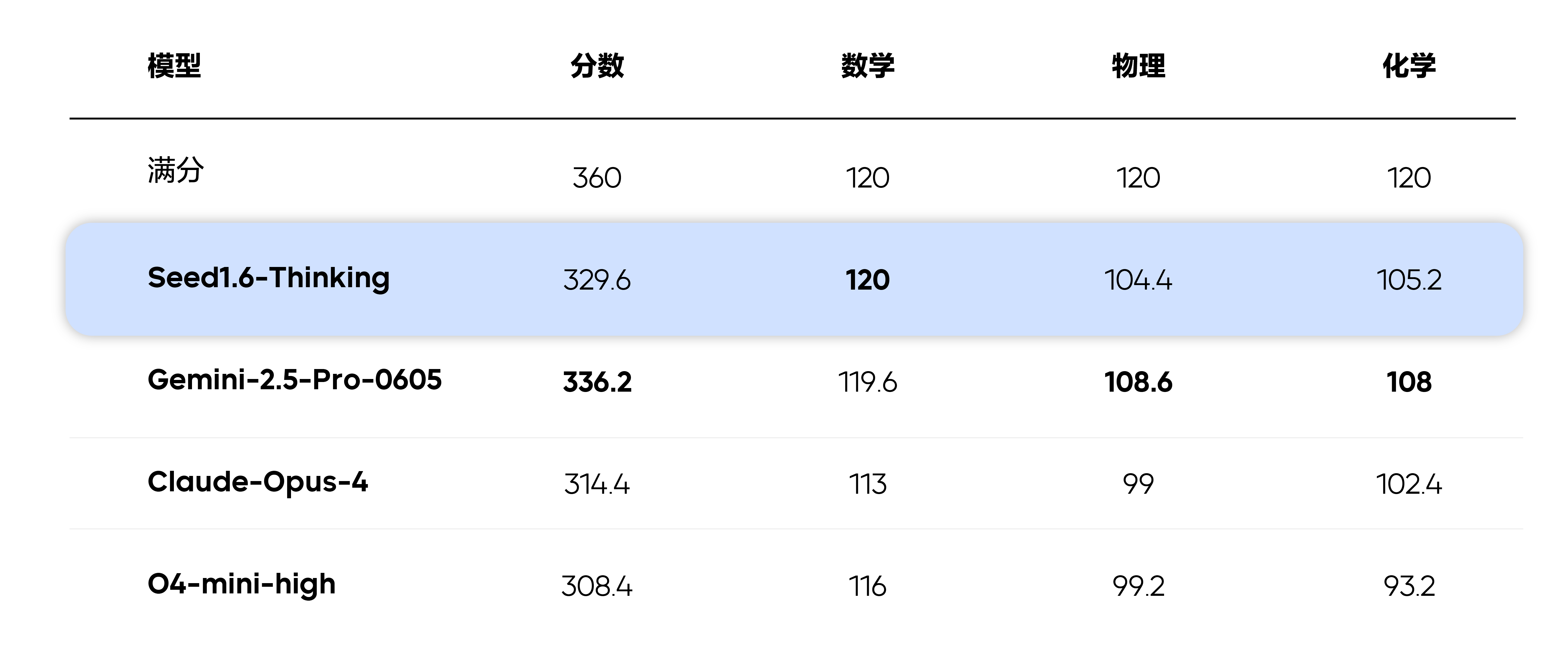
对比全印度人类考生,第一名为 332 分,第 10 名为 317 分,Gemini-2.5-Pro 和 Seed1.6-Thinking 可取得全印度 top 10 的成绩。Gemini-2.5-Pro 物理/化学表现出色,Seed1.6-Thinking 在 5 次采样的数学测试中回答全部正确。
总结与展望
Seed1.6 系列模型是 Seed 团队在推理效果和性能平衡上的一次较好尝试,同时模型从预训练到后训练融合了 VLM 多模态能力,在最新的高考题目测试中也表现突出。
未来 Seed 团队将进一步探索更高效的模型架构,提升模型的推理效果,丰富多模态能力,深入探索模型端到端完成任务的 agent 能力。
Seed1.6 体验入口: https://www.volcengine.com/experience/ark?model=doubao-seed-1-6-250615
Seed1.6-Thinking 体验入口: https://www.volcengine.com/experience/ark?model=doubao-seed-1-6-thinking-250615