ByteDance Released Image Editing Model SeedEdit 3.0: Enhanced Image Consistency and Usability Rate
ByteDance Released Image Editing Model SeedEdit 3.0: Enhanced Image Consistency and Usability Rate
Date
2025-06-06
Category
Models
The demand for AI-powered, instructive image editing is widespread across creative visual workflows. However, previous image editing models show limits in preserving subjects/backgrounds and following edit instructions, resulting in a low rate of usable output images.
To address these challenges, the ByteDance Seed team released its latest image editing model, SeedEdit 3.0. Built upon the text-to-image (T2I) model Seedream 3.0, SeedEdit 3.0 employs diverse data merging methods and a set of specialized reward models. With upgraded capabilities in preserving image subjects, backgrounds, and details, this model performs particularly well in tasks such as portrait retouching, background changes, perspective shifts, and lighting adjustments.
Starting today, the tech report of SeedEdit 3.0 is publicly available. This model is now open for testing on the web page of Jimeng and will be applied in the app soon. Feel free to try it out and share your feedback.
Model Homepage: https://seed.bytedance.com/seededit
Tech Report: https://arxiv.org/pdf/2506.05083
Today, the ByteDance Seed team officially released its image editing model, SeedEdit 3.0.
This model can process and generate 4K images, editing selected areas naturally and precisely while faithfully preserving the visual fidelity of non-edited areas. SeedEdit 3.0 particularly excels in understanding and balancing what to change and what to preserve, yielding a higher usability rate.
When you need to remove crowds from an image, the model accurately detects and removes irrelevant pedestrians—along with their shadows.

Prompt: Center person only
When converting a 2D drawing into an image of a lifelike model, SeedEdit 3.0 effectively preserves details such as the clothing, hat, and handbag, generating an image with a fashionable, street-style look.

Prompt: Make the girl realistic
SeedEdit 3.0 can also smoothly and naturally handle lighting and shadow changes across the entire scene. From close-up houses to far-off sea ripples, details are well preserved and rendered with pixel-level adjustments in response to lighting changes.

Prompt: Change the scene to daytime
To implement the capabilities mentioned above, the team proposed an efficient data merging strategy and introduced a set of specialized reward models during the R&D of SeedEdit 3.0.
By jointly training these reward models with diffusion models, the team has achieved targeted improvements in image editing quality for key tasks, such as face alignment and text rendering. The team has also optimized the inference efficiency during implementation.

Prompt: Change "STOP" to "WARM"
1. High Image Consistency and High Usability Rate in Human Evaluations
To better evaluate the upgraded SeedEdit 3.0, we collected hundreds of real-world and synthetic testing images and created 23 types of subtasks for editing operations. In addition to common operations like stylization, adding, replacing, and deleting elements, we also included complex instructions involving camera movements, object shifts, and scene changes.
- Machine-based Evaluation Results
The team used CLIP image similarity to evaluate image consistency, and leveraged third-party vision-language models (VLMs) to automatically evaluate whether the model accurately responded to edit instructions in output images, known as instruction response.
The chart below shows that SeedEdit 3.0 leads in image consistency and instruction response metrics, compared to its previous versions—SeedEdit 1.0, SeedEdit 1.5 (introduced new data sources), and SeedEdit 1.6 (added a data merging strategy). SeedEdit 3.0 also outperforms Gemini 2.0 and Step1X in these metrics. Notably, GPT-4o is positioned at the right bottom, suggesting it excels in the instruction response metric but falls behind in the image consistency metric, compared to SeedEdit 3.0.
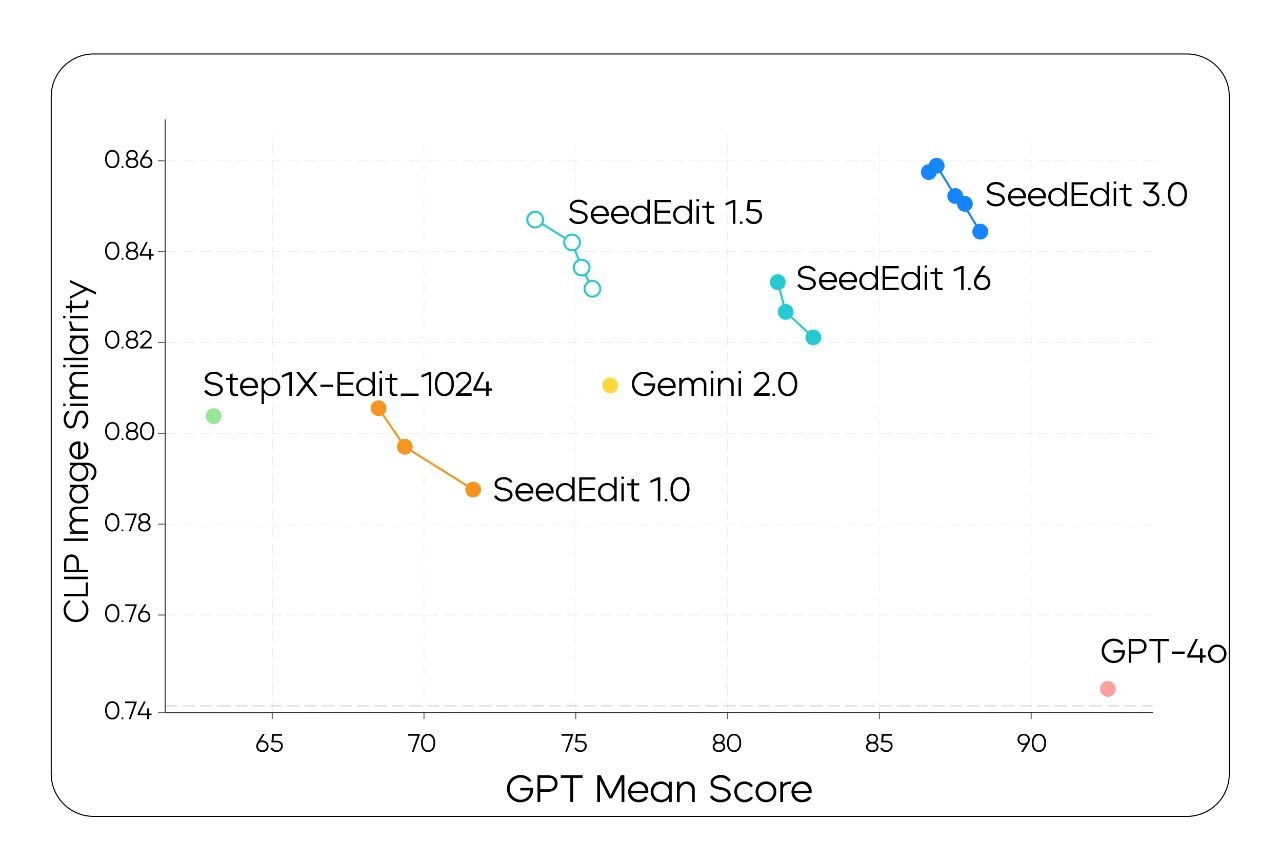
The vertical axis represents the image subject consistency metric, and the horizontal axis represents the instruction response metric for machine-based evaluation.
The chart below reveals that SeedEdit 3.0 also achieves substantial leads in face preservation.
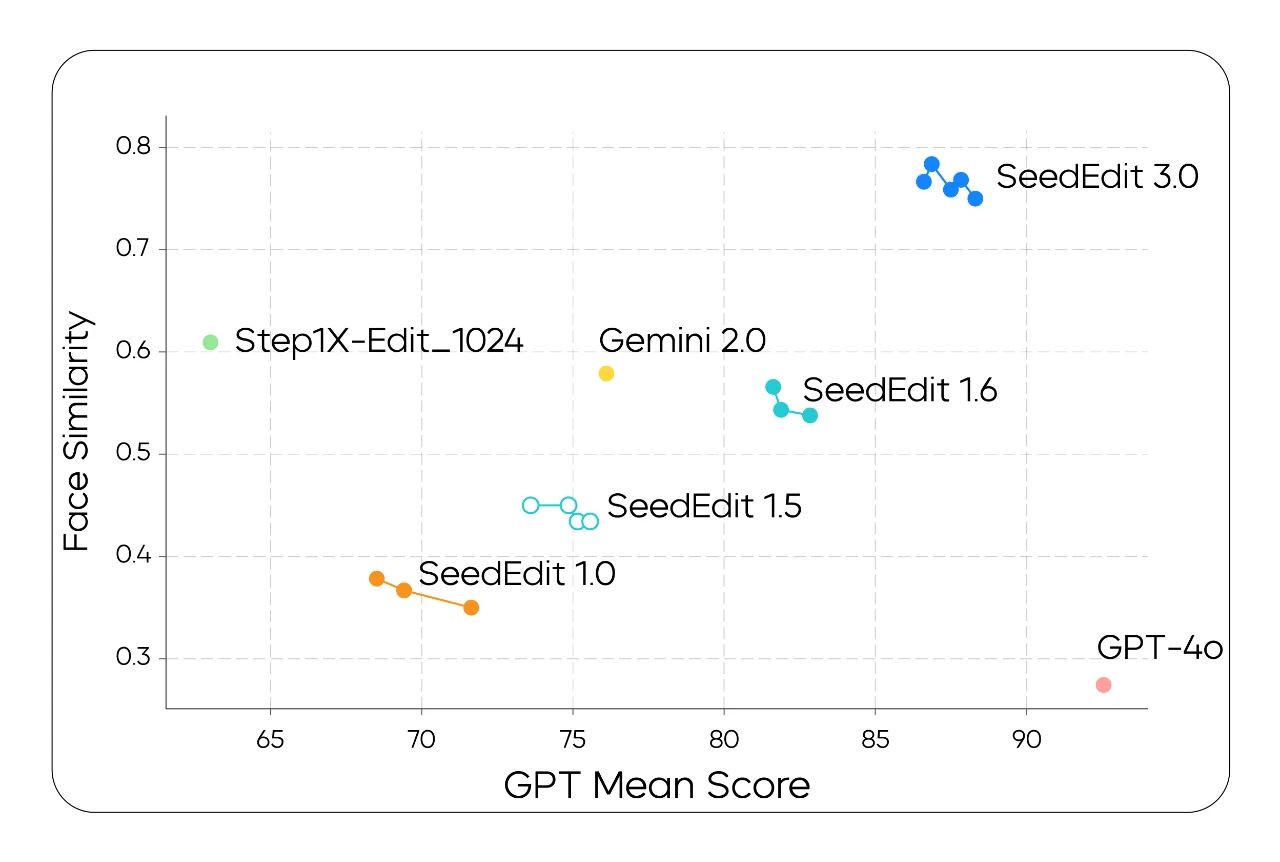
The vertical axis represents face similarity, and the horizontal axis represents the instruction response metric for machine-based evaluation.
- Human Evaluation Results
To make the evaluation more reliable for reference, the team introduced a set of human evaluations, using a 0-5 scoring scale to evaluate the gap between the model's outputs and expected results across 5 dimensions:
- Instruction Response:evaluates whether the model can accurately respond to edit instructions.
- Image Consistency:evaluates whether the model edited areas that should remain unchanged.
- Image Quality:evaluates whether the model generates high-quality, aesthetically appealing images without artifacts.
- Satisfaction Rate:evaluates the percentage of high-quality images produced after editing with different methods.
- Usability Rate:evaluates the percentage of edited images that are deemed usable by users.
In the comprehensive evaluation, SeedEdit 3.0 delivers the best performance in image consistency, scoring 4.07 out of 5, which is 1.19 points higher than SeedEdit 1.6. The usability rate of SeedEdit 3.0 reaches 56.1%, an increase of 17.46% over SeedEdit 1.6. SeedEdit 3.0 also demonstrates industry-leading performance in instruction response and image quality metrics.
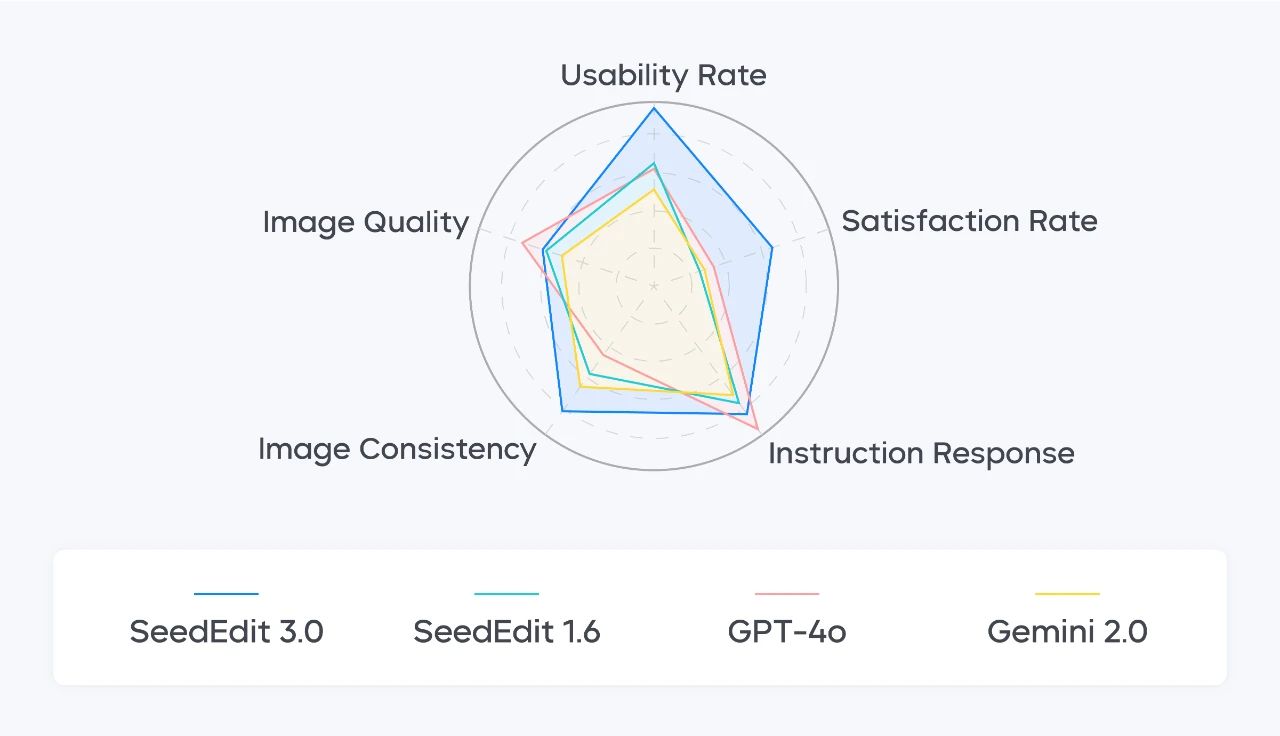
Performance of different image editing models across 5 dimensions: Usability Rate, Satisfaction Rate, Instruction Response, Image Consistency, and Image Quality
The following examples compare the outputs of different models. SeedEdit 3.0 keeps non-edited areas highly consistent, producing natural-looking results with well-preserved details and impressive aesthetic appeal.
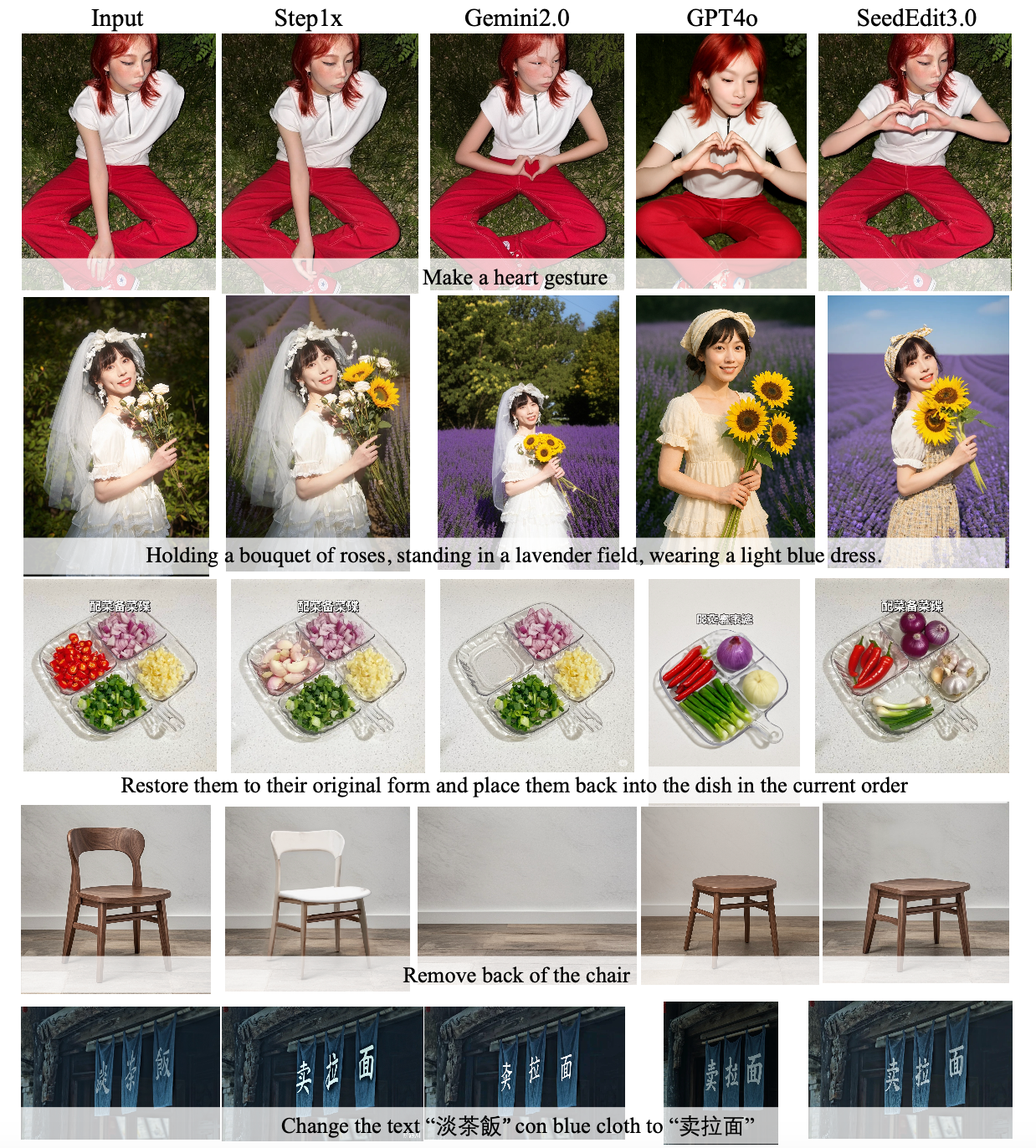
The qualitative comparison shows that SeedEdit 3.0 performs well in the preservation of faces, object/human foregrounds, and image details, as well as the change and alignment of Chinese characters.
2. Enhanced Data Merging Strategy: Let AI Understand What to Change and What to Preserve in Image Editing
The key to training models for image editing tasks lies in enabling models to understand instructions, recognize the differences between tasks, and distinguish what to change from what to preserve in images. Data serves as the cornerstone of model capabilities. Therefore, we proposed an enhanced data merging strategy.
With different tasks and scenarios in mind, we curated the following types of data:
- Synthesized Dataset
We designed a novel pair data sampling strategy, which includes prompt sampling from the large language model (LLM)/vision-language model (VLM) and noise sampling from the T2I model. This type of data enables the model to focus on both important and long-tail tasks as well as image subjects. It also helps the model understand the geometric changes caused by different subject poses.
- Editing Specialists
The team collected real-world data in a compliant manner, including large amounts of professional image editing processes (such as ComfyUI workflows, background and lighting adjustments, and text editing). By integrating such data with image generation APIs, we created multiple data curation pipelines, covering a broad spectrum of specialist scenarios.
- Traditional Edit Operators
We also produced high-quality data about editing operations—such as lens blur, lighting adjustments, cropping, and generating posters based on templates—based on traditional editing tools. This type of data provides accurate loss directions, enabling the model to understand and distinguish between what to change and what to preserve in image editing.
- Video Frames and Multi-Shot
Large-scale and diverse real-world image data are crucial for improving the generalization ability. Videos serve as a natural source of pairs or groups of images, which can be annotated for image editing tasks. Therefore, we sampled image editing pairs from videos in three steps. First, we randomly sampled several key frames from each video clip, with text instructions added to describe their differences. Then, we coarsely filtered these key frames based on CLIP image similarity and optical flow metrics. Lastly, we applied a VLM for refined filtering.
This approach helps us collect data from a wider range of domains, minimizing domain gaps arising from cross-domain data processing. It also enhances the model's ability to understand image editing tasks like a human designer—knowing what to change and what to preserve, and making edits accordingly.
The following are some examples of curated data:

Based on the data mentioned above, we employ an interleaved training strategy that enables the diffusion model to learn jointly from editing spaces for real-world and synthetic input-output data. This enhances the editing performance on real-world images, without compromising the information of diverse editing tasks. The training framework is as follows:
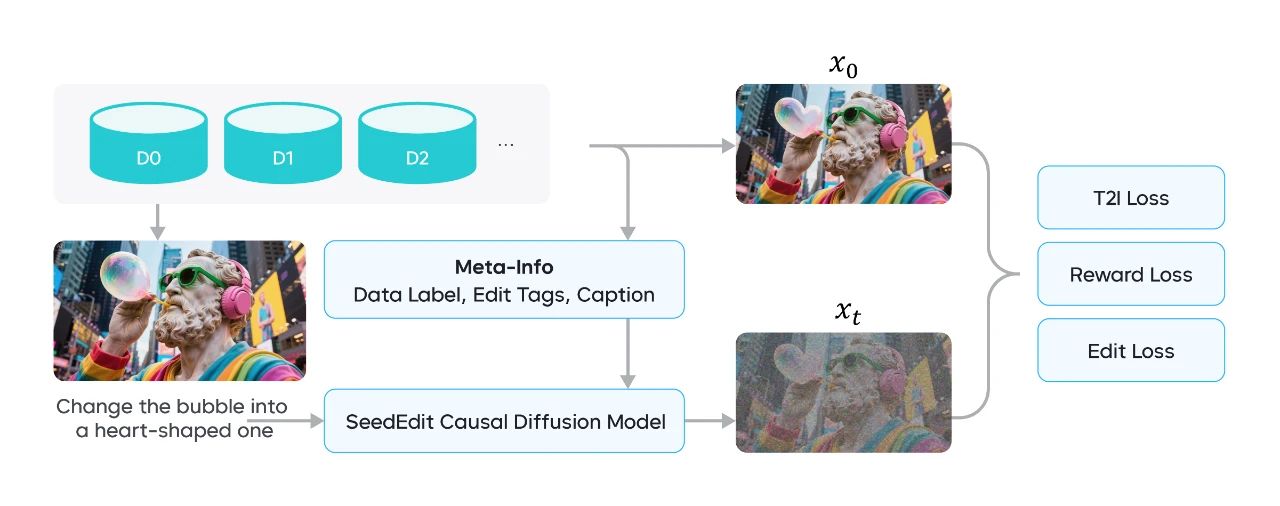
Meta-information is collected from diverse data sources, and multiple loss functions are integrated into the training pipeline
Since image editing data varies widely across sources, directly adding such data to the original synthesized image pairs can lead to degraded performance. For example, the prompt "change to Paris" may imply a simple background replacement in a traditional image editing task, but may imply changing every pixel in the image in an IP/ID preservation task based on the diffusion model.
Therefore, we have proposed a multi-granularity label strategy to effectively merge image editing data from different sources. To reduce randomness in model inference, we used unified task labels to distinguish data with sharp differences and added special captions to distinguish data with subtle differences. As the model needs to handle both Chinese and English tasks, we sampled prompts and used a VLM to generate new bilingual descriptions.
After rephrasing, filtering, and alignment, all data can be used in training for forward and backward editing operations, thus achieving an overall balance across performance metrics.
3. Cross-Modal Information Alignment and Multi-Stage Training
We have been leveraging the proven framework, where a VLM at the bottom infers high-level semantic information from the image, and a causal diffusion network at the top reuses the diffusion process as an image encoder to capture fine-grained details.
Between these components, a connector module is introduced. Its purpose is to align the editing intent from the VLM—such as task type and editing tag information—with the diffusion model.
In addition, we have upgraded the diffusion network to Seedream 3.0, which can natively generate 1K to 2K images. This greatly enhances the performance in preserving input image details, such as face and object features. This also enables SeedEdit 3.0 to effectively understand and render bilingual texts, making it easily adaptable to multimodal image generation.
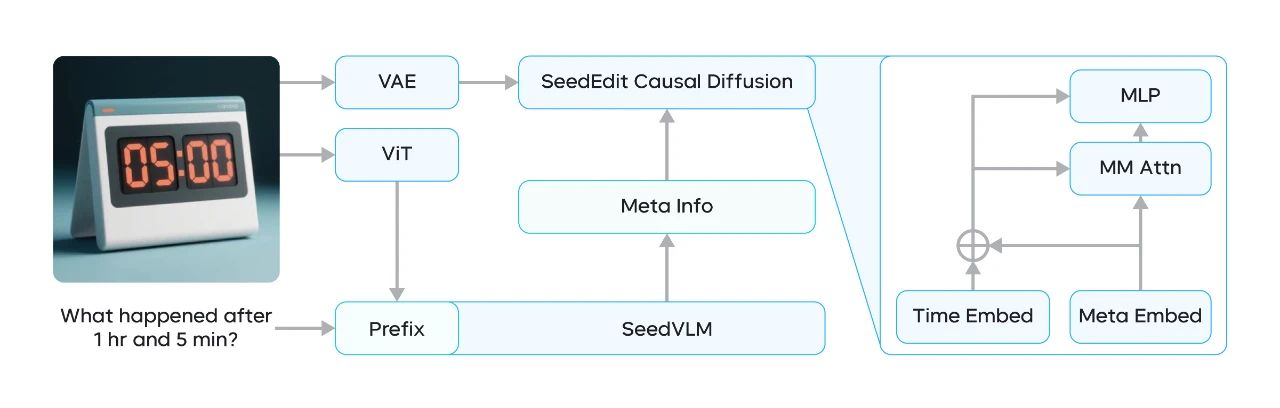
SeedEdit 3.0 architecture after upgrade
To train the framework, we have employed a multi-stage training strategy. Among the training stages, pre-training aims to merge all collected image pairs, and fine-tuning focuses on refining the outputs to stabilize editing performance.
Specifically, we first trained the model with images of varying aspect ratios, and grouped images in batches by resolution, enabling progressive training from low to high resolutions.
In the fine-tuning stage, we selected high-resolution, high-quality samples from massive curated data through model-based filters and human review, to ensure high data quality and wide coverage of editing classes. Then, we adopted diffusion loss functions to fine-tune the model.
For attributes of high value to users, such as face identity, structural details, and aesthetics, we introduced a set of specialized reward models as additional loss functions and assigned them weights to enhance the performance of SeedEdit 3.0 on high-value attributes.
Lastly, we jointly trained the model on both editing tasks and text-to-image (T2I) tasks, which brings the following benefits:
(1) Injecting high-quality, high-resolution T2I images greatly boosts the model's editing capability on high-resolution images.
(2) Using T2I data helps preserve the model's original T2I capability, which also contributes to higher performance in generalization.
4. Integrate Multiple Speedup Methods, Achieving Inference Within 10 Seconds
SeedEdit 3.0 employs more effective methods to speed up training and inference.
- Model Distillation
Our acceleration framework builds upon Hyper-SD and RayFlow. By assigning a unique target distribution to each sample, we have greatly reduced path overlaps. This improves generation stability and output diversity while avoiding issues—such as weakened fine-grained control and destabilized reverse denoising—in traditional methods.
- CFG Distillation
Considering that Classifier-Free Guidance (CFG) nearly doubles the inference cost, we have encoded the CFG scale as a learnable embedding fused with the timestep encoding. This distillation method achieves approximately two times faster inference while preserving the ability to adjust guidance strength on demand.
- Unified Noise Reference
To ensure smooth transitions throughout sampling, we have employed a single noise reference vector predicted by a network. This vector acts as a constant guide at each timestep, helping to align the denoising process over time. This ensures stronger sampling performance and more faithful reconstructions.
- Adaptive Timestep Sampling
To address high variance in the loss and wasted computation on less informative intervals during conventional diffusion training, we have introduced an adaptive sampling strategy. During training, the neural network module identifies the timesteps that yield the greatest loss reduction, allowing more targeted updates, more efficient utilization of computational resources, and lower training costs.
- Few-Step, High-Fidelity Sampling
SeedEdit 3.0 adopts a tightly compressed denoising schedule in its framework. Compared to standard baselines, the new framework enables the model to use far fewer sampling steps while demonstrating strong performance across key metrics such as aesthetic quality, text-image alignment, and structural accuracy.
- Quantization
Considering the architecture and scale of the DiT model, we have optimized the performance of specific operators through techniques such as kernel fusion and memory access coalescing.
As a result, certain operators run more than twice as fast as in their original implementations. Furthermore, we have enhanced performance and reduced memory usage through low-bit quantization of GEMM and Attention modules.
5. Conclusion
While SeedEdit 3.0 excels in image consistency and usability rate metrics, continued efforts are required to refine its ability to follow instructions.
Moving forward, in addition to further optimizing the editing performance of the model, we will explore more diverse editing operations to support capabilities such as sequential multi-image generation, multi-image synthesis, and story-based content creation, helping users unlock greater creativity.