ByteDance Seed Open-Sources VeOmni, Unlocking Any Modality Model Training
ByteDance Seed Open-Sources VeOmni, Unlocking Any Modality Model Training
Date
2025-08-14
Category
Research
In recent years, large language model (LLM) technology has evolved from unimodal specialization (text-only) toward "omni-modal" understanding and generation across multiple modalities such as images, audio, and video. Despite this progress, training omni-modal LLMs capable of "seeing," "hearing," and "talking" remains a significant challenge, requiring sophisticated system design.
To advance research and application of omni-modal LLMs, the ByteDance Seed team has unveiled and open-sourced VeOmni, a PyTorch-native omni-modal training framework.
VeOmni introduces model-centric distributed recipes that decouple complex distributed parallel logic from model computation. This allows researchers to compose efficient parallel training recipes for omni-modal models as if building with blocks. This method significantly reduces engineering overhead, boosts training efficiency and scalability, and slashes engineering development cycles from weeks to days.
Historically, training novel-architecture vision-language models via Megatron-LM-like frameworks depended heavily on the Infra team's expertise. The engineering work used to take more than a week, plus additional time for distributed optimization and precision alignment. Now, with VeOmni, it is possible to build model code and kick off training in just a single day, compressing engineering time by over 90%.
Our experiments show that VeOmni—a 30B-parameter omni-modal mixture-of-experts (MoE) model capable of processing text, audio, images, and video—achieves over 2,800 tokens/sec/GPU on 128 GPUs, and scales seamlessly to support ultra-long contexts of up to 160K tokens.
Currently, VeOmni's related paper and code repository are publicly available, with over 500 stars on GitHub.
arXiv: https://arxiv.org/pdf/2508.02317
GitHub: https://github.com/ByteDance-Seed/VeOmni
Challenge of Training Omni-Modal LLMs
As LLMs are extended to handle diverse modalities, their architectures have become increasingly complicated. In a typical unified omni-modal understanding and generation model, a language model often serves as the central backbone, connecting modality-specific encoders and decoders. They function like "senses", processing continuous signals (such as images and audio) and discrete sequences (such as text), endowing the model with highly integrated understanding and generation capabilities across multiple modalities.
From our research and experience over a long period of time, we have found that it is not easy to directly extend existing training frameworks to omni-modal LLMs.
Represented by Megatron-LM, most common training frameworks primarily target text-only LLMs. These frameworks adopt "system-centric" designs that tightly couple model definition with parallel logic (such as tensor parallelism and pipeline parallelism). While suitable for relatively structured text models, using these frameworks to train omni-modal LLMs with complex architectures and diverse modalities often leads to load imbalance and poor scalability.
More importantly, the "coupling" significantly increases engineering overhead. When teams attempt to introduce new modalities or adjust model architecture, they often need to delve deep into the underlying details and rewrite substantial amounts of distributed training code. In addition, the algorithm research team must work closely with the engineering team, hindering the ability to rapidly and independently validate different ideas and delve into cutting-edge challenges in model research.
Although next-generation PyTorch-native training frameworks such as TorchTitan can greatly reduce engineering complexity, they focus more on the design of distributed systems and lack attention to multimodal models. For the more complex any-to-any scenarios, the industry has long lacked a mature and scalable industrial-grade distributed training solution.
Core Design of VeOmni: Model-Centric Distributed Training Recipes
To address the challenges of training omni-modal models, VeOmni proposes model-centric distributed training recipes.
In system design, a trade-off often exists between generality and high performance: In-depth optimizations for specific scenarios can significantly boost performance, but at the expense of framework flexibility. The architectures of omni-modal models are evolving at a rapid pace, with highly imbalanced computational loads across different modalities. In a field of ongoing technological exploration, a framework's generality and capacity to foster innovation are far more valuable than extracting peak performance in a single scenario.
Therefore, we have adopted a model-centric design philosophy: Strive for high performance on the premise of maintaining generality, letting the system adapt to fast-evolving models rather than the other way around.
VeOmni decouples model definition from the underlying distributed training code. This allows users to flexibly compose and apply distributed strategies such as fully sharded data parallel (FSDP), sequence parallelism (SP), and expert parallelism (EP) to various model components like encoders or MoE layers without changing any model code.
Meanwhile, VeOmni provides lightweight APIs for seamless integration of new modalities, overcoming poor scalability and high engineering costs in existing frameworks caused by the tight coupling between models and parallel logic.
The following figure demonstrates the difference between existing training frameworks (left) and VeOmni (right). In existing training frameworks, communication operations (Comm. Ops) are often deeply coupled with computation operations (Comp. Ops) and interspersed throughout the model code. In VeOmni, all submodels are purely "computation-only modules," with all distributed communication logic handled by the framework itself.
Plug-and-Play Omni-Modal APIs
To simplify the integration of new modalities, VeOmni offers a suite of lightweight omni-modal model APIs.
As shown in the following figure, VeOmni's architecture allows any combination of multimodal encoders and decoders to be flexibly attached to the input and output sides of a foundation model. Encoders and decoders for any modality can be quickly integrated simply by following the unified, lightweight HuggingFace API specifications (such as the implementation of the lm_encode and lm_generate functions). This design empowers researchers to swiftly and easily incorporate any modalities into LLMs or switch model architectures of independent submodules.
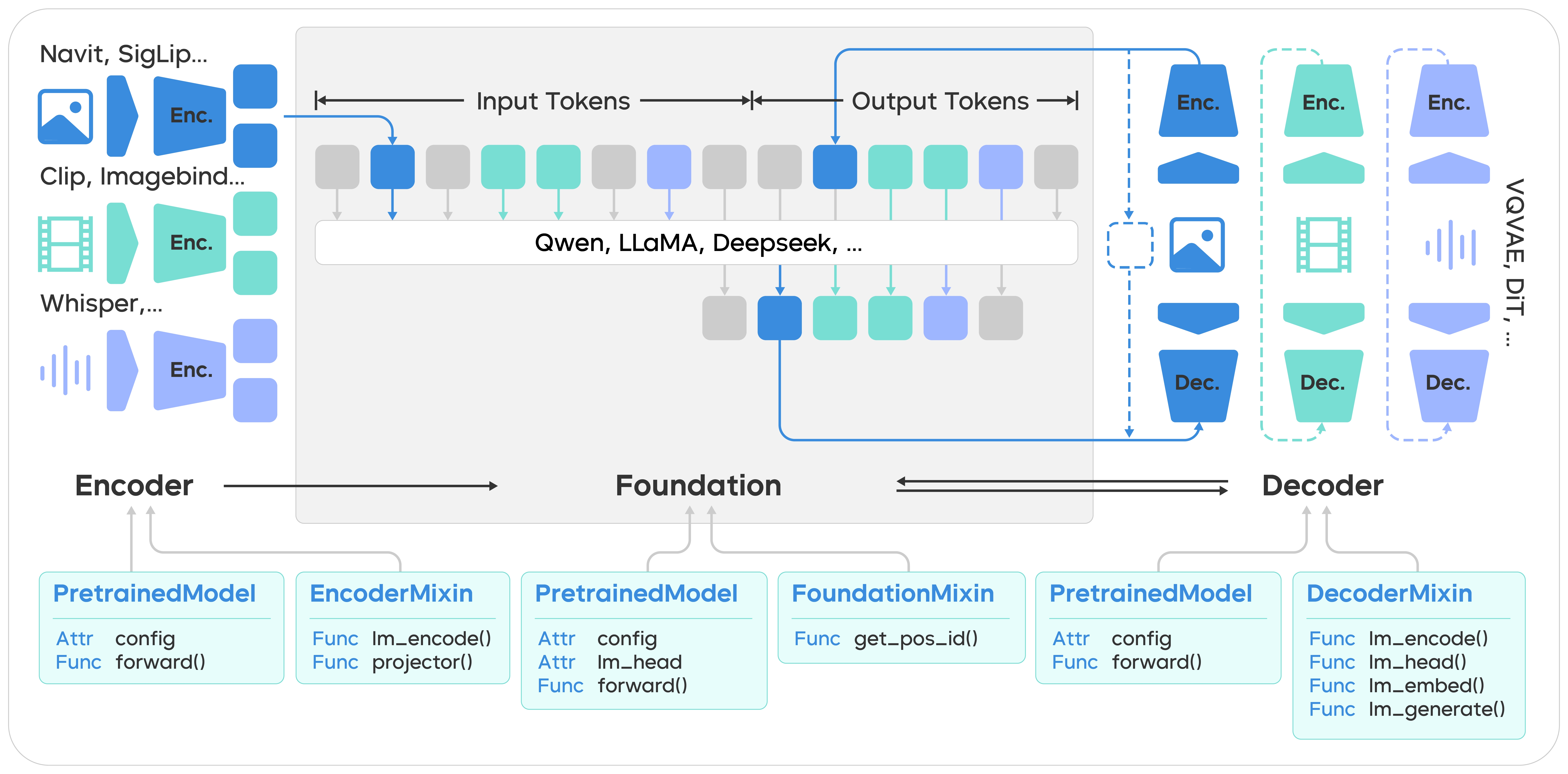
Composable n-D Parallelism and Unified Scheduling
Another key feature of VeOmni is its composability. In VeOmni, distributed code is decoupled from model code, and all parallelism strategies, such as FSDP, SP, and EP, are composable blocks that can be flexibly applied to different components of models.
As shown in the following figure, VeOmni can apply FSDP to vision encoders, hybrid sharded data parallel (HSDP) and SP to the attention layers of the language model, and FSDP, EP, and SP to MoE layers, thus optimizing distributed training of complex models.
To support this flexible composition of distributed strategies, VeOmni introduces a unified abstraction layer for distributed training—parallel_state—based on a DeviceMesh to control all parallelism dimensions. Compared to manually managing process groups, this design significantly simplifies n-D parallelism management while enhancing scalability.
Data Parallelism Strategies
VeOmni integrates the fully sharded data parallel (FSDP) strategy. A key advantage of FSDP is its non-intrusive design, making it well-suited for training omni-modal LLMs that struggle with stable convergence due to their complex architectures. This non-intrusive nature aligns perfectly with VeOmni's design philosophy.
For further optimization on ultra-large clusters, VeOmni also supports hybrid sharded data parallel (HSDP). HSDP utilizes a 2D device mesh, employing FSDP within shard groups and distributed data parallel (DDP) across replicate groups. This hybrid approach drastically cuts down on inter-node communication, enabling even greater scalability. In VeOmni, the switch from FSDP to the more efficient HSDP is as simple as changing one parameter (data_shard_size) in the configuration.

Sequence Parallelism for Ultra-Long Sequences
For omni-modal models to handle long sequences such as high-resolution images, long videos, and long audio, it is essential to support ultra-long context windows.
To address this, VeOmni adopts DeepSpeed-Ulysses, a highly efficient sequence parallelism technique. Furthermore, it implements Async-Ulysses, an enhanced implementation designed to overlap communication and computation. This version schedules time-consuming all-to-all communication operations to execute concurrently with the linear projection computations in Attention, thus ensuring efficient training and scalability for ultra-long sequences.
In adherence to its model-centric design philosophy, VeOmni provides flash_attention_forward, a simple distributed interface that enables highly efficient sequence parallelism without the need to introduce any distributed training code at the model layer.
For the specific code snippet, visit https://github.com/ByteDance-Seed/VeOmni/blob/main/veomni/ops/attention.py.
Expert Parallelism for Efficient MoE Model Scaling
For expert parallelism in MoE models, VeOmni introduces ParallelPlan, an interface based on PyTorch DTensor.
Users only need to specify the sharding dimension for relevant parameters and set expert_parallel_size during training to implement expert sharding and parallelism.
Flexible Operator-Level Communication Optimization
A major bottleneck in MoE training lies in all-to-all communication required for routing tokens to their assigned experts on different devices, incurring significant communication overhead.
Previous industry solutions often relied on complex pipeline parallel scheduling (e.g., DualPipe) to hide communication latency. However, in multimodal model training scenarios with dynamic workloads, this approach proves "rigid" and "highly inflexible" because it is tightly coupled with model architecture and computation. This rigidity easily leads to bubbles, wasting substantial computational resources.
VeOmni employs COMET, a fine-grained communication-computation overlapping technique unveiled by the ByteDance Seed team. This renders VeOmni independent of model architectures and sizes and reduces resource wastage during the communication process in MoE training, making VeOmni well-suited for training omni-modal MoE models.
Comprehensive System-Level Optimizations
In addition to its core parallelism optimizations, VeOmni incorporates various system optimizations, such as dynamic batching, efficient kernels, recomputation for memory optimization, and ByteCheckpoint for efficient distributed checkpointing. Together, they comprehensively improve the efficiency and stability of omni-modal model training.
Experimental Results of VeOmni: Support for Ultra-Long Sequences and Efficient Omni-Modal Training
We systematically evaluated VeOmni's performance, testing it with mainstream open-source models across diverse configurations on GPU clusters from 8 to 128 GPUs.
Strong Support for Ultra-Long Sequence Training
Handling modalities such as high-resolution images and videos requires models to support extremely long context windows, posing a significant challenge to memory and computational efficiency. VeOmni effectively overcomes this challenge by employing sequence parallelism (SP).
As shown in the following figure, VeOmni supports sequence lengths up to 192K for the open-source 7B multimodal understanding model. Further increasing the SP size can extend the maximum sequence length. For the 72B model, VeOmni also supports sequence lengths up to 96K.
The top figure shows experiments with Qwen2-VL-7B, and the bottom with Qwen2-VL-72B, illustrating VeOmni 2D parallelism (FSDP+SP) in terms of memory usage, MFU, and throughput across different training setups.
3D Parallelism for Higher Training Efficiency
VeOmni leverages 3D parallelism (FSDP+SP+EP) to ensure higher training efficiency for mainstream MoE models.
On a 30B omni-modal MoE model capable of speech understanding and visual understanding and generation, VeOmni can support extended sequence lengths of up to 160K while maintaining competitive training throughput.
The top figure shows experiments with the Qwen3-30B-A3B full-modal model, illustrating memory usage and throughput under different training configurations using VeOmni 3D parallelism (HSDP+SP+EP). The model uses NaViT from Qwen2.5-Omni as the image and video encoder, Whisper from Qwen2.5-Omni as the audio encoder, and MoVQGAN as the image decoder.
Better Text Model Training Compared to TorchTtan
To provide a fair benchmark, we conducted controlled experiments on large-scale text-only models to compare VeOmni with TorchTitan, a state-of-the-art distributed training framework.
Results demonstrate that VeOmni consistently surpasses TorchTitan in both throughput and memory efficiency across model sizes ranging from 7B to 72B. This advantage is particularly pronounced in long-sequence scenarios, thanks to VeOmni's superior memory management and parallelism strategies.
The table above shows a performance comparison between VeOmni and TorchTitan during Qwen2-72B training on 128 GPUs.
Stable Convergence During Training
In addition to efficiency and scalability, stability is also crucially important for training. We built three structurally distinct omni-modal LLMs using VeOmni's plug-and-play omni-modal APIs and trained them on complex tasks spanning four modalities: text, image, audio, and video.
Results show that all models exhibited stable convergence, demonstrating that VeOmni enables efficient and robust training for large omni-modal LLMs.
As shown in the graph, increasing the step count leads to convergence in both LM loss (text cross-entropy) and decoder loss (image cross-entropy) across models. LLaMA#Omni and Qwen3-MoE#Omni share a similar setup, using Qwen2.5-Omni NaViT as the vision encoder, Qwen2.5-Omni Whisper as the audio encoder, and MoVQGAN as the image decoder, with LLaMA and Qwen3-MoE as their respective text backbones. Janus, based on DeepSeek’s open-source model, employs SigLip for image encoding, LLaMA as its backbone, and LlamaGen as the image decoder.
Real-World Training Practices
In addition to demonstrating strong performance in experiments, VeOmni is also powering multiple cutting-edge projects of the ByteDance Seed team.
For example, the multimodal agent UI-TARS-1.5 was trained on massive amounts of long-sequence (> 128K), multimodal agent data. Leveraging VeOmni's powerful sequence parallelism capabilities, the team overcame the memory bottleneck caused by ultra-long sequences, enabling highly efficient model training.
Summary and Outlook
We have open-sourced VeOmni to provide the AI community with an efficient, flexible, and user-friendly solution for training multimodal models.
With a model-centric design, VeOmni decouples models from systems. This approach lowers the engineering barriers associated with omni-modal AI training, allowing researchers to focus on model and algorithmic innovation.
Looking ahead, we will further refine VeOmni to support training for a wider variety of multimodal model architectures and scales, alongside our ongoing commitment to sharing cutting-edge training techniques with the community.