Meet Seed at ICML 2025: 25 Papers Accepted
Meet Seed at ICML 2025: 25 Papers Accepted
Date
2025-07-14
Category
Conferences

The International Conference on Machine Learning (ICML) 2025 is scheduled from July 13 to July 19 in Vancouver, Canada.
At ICML 2025, the ByteDance Seed team had 25 papers accepted, 3 of which were selected as Spotlight papers, spanning cutting-edge domains such as LLM inference optimization, speech generation, image generation, video generation and world models, and AI for Science. In this article, we explore 6 of these selected papers in detail.
During the ICML, our technology advancements, including verl, BAGEL, and the DPLM family (multimodal diffusion protein language model), are presented at Booth No.321. Seed team researchers will be on hand to share insights and explore the next tech frontiers.
Meetup
Topic: verl Happy Hour @ ICML Vancouver
Where: Vancouver, British Columbia (the exact address will be provided upon successful registration)
When: 17:00 - 22:00 (GMT-7), July 16
Meetup details & registration link: https://lu.ma/0ek2nyao. Due to limited space, the organizer will confirm the registration result before the meetup.

verl is an open-source reinforcement learning framework initiated by ByteDance Seed. It is designed to help developers efficiently and flexibly train large language models (LLMs). verl has reached 10,600 stars on GitHub. We have invited talented researchers and engineers in the reinforcement learning, inference systems, and open-source agent infrastructure domains to spark innovative ideas and share experiences. Feel free to join us.
Selected Papers

Elucidating the Design Space of Multimodal Protein Language Models
arXiv: https://arxiv.org/pdf/2504.11454
Project Page: https://bytedance.github.io/dplm
Exhibition Location: West Exhibition Hall B2-B3 #W-115
This paper systematically describes the challenges of multimodal protein language models on protein structural modeling and provides a solution to overcome the limitations.
Specifically, we identify the following major bottlenecks of multimodal protein language models on structural modeling: substantial loss of fine-grained structural details and geometric correlations due to the tokenization of 3D structures into discrete tokens. For multimodal protein language models, discrete structure tokens are not optimal for learning.
To address the preceding limitations, this paper studied DPLM-2, a multimodal diffusion protein language model, and proposed design methods that cover improved generative modeling, geometric modules and representation learning, and data exploration to efficiently boost the performance of multimodal protein language models.
1. We employed an improved generative modeling method to improve the accuracy of protein structure predictions.
- Residual generation via a diffusion model: recover information that is lost during tokenization.
- Bit-level structural feature modeling: introduce more fine-grained supervision signals to reduce the difficulty of predictions and capture local structural feature correlations more accurately.
- Direct sampling in coordinate space: conduct direct atomic-coordinate generation in the continuous coordinate space to improve the precision of structure generation.
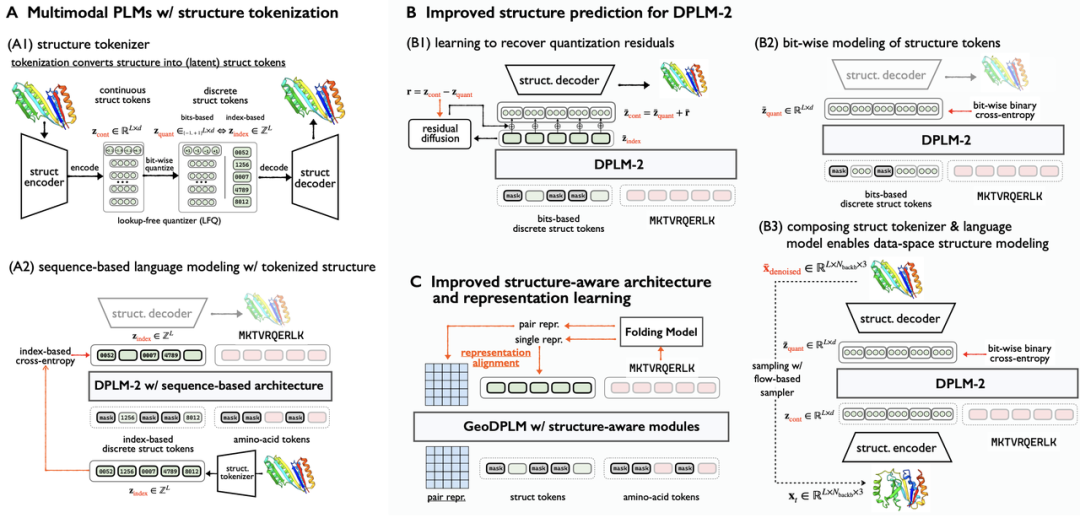
(A) Multimodal protein language models based on the joint modeling of discrete structure tokens and amino acid sequences. (B) Improved generative modeling methods, including residual generation via a diffusion model, bit-level structural feature modeling, and direct sampling in coordinate space. (C) Improved structure-aware model architecture (with geometric modules introduced) and representation learning (aligning to structure representations from folding models).
2. We applied representation alignment (REPA) learning structure representations from folding models to capture complex residue-residue interactions. We introduced an innovative geometric module architecture and representation alignment to improve geometric correlation modeling and the diversity of protein structure generation.
3. We found that multimer and monomer modeling are deeply interconnected and leveraging multimer data advances the structural modeling for both single and multi-chain proteins.
Experiment results show that the solution proposed in this paper can significantly improve the structure generation of multimodal protein language models.
In protein folding, the new method reduces the RMSD (a structure prediction deviation metric) from 5.52 to 2.36, on par with the specialized protein structure prediction model ESMFold. Additionally, fewer parameters (0.65B vs. 3B) are used. In unconditional protein generation, the sampling diversity is improved by approximately 30%, effectively addressing the issue of low diversity while ensuring high quality of samples.

ShadowKV: KV Cache in Shadows for High-Throughput Long-Context LLM Inference
arXiv: https://arxiv.org/pdf/2410.21465
Project Page: https://github.com/ByteDance-Seed/ShadowKV
Exhibition Location: East Exhibition Hall A-B #E-2805
With the widespread deployment of long-context LLMs, there has been a growing demand for high-throughput inference. However, as key-value (KV) cache scales with sequence length, its growing memory footprint and the need to access it for each token generation lead to low throughput during long-context LLM inference. While various dynamic sparse attention methods have been proposed to speed up inference while maintaining generation quality, they either fail to sufficiently reduce GPU memory consumption or introduce significant decoding latency by offloading the KV cache to the CPU.
This paper presents ShadowKV, a high-throughput long-context LLM inference system that stores the low-rank key cache and offloads the value cache to reduce the memory footprint for larger batch sizes and longer sequences. To minimize decoding latency, ShadowKV employs an accurate KV selection strategy that reconstructs minimal sparse KV pairs on-the-fly.
ShadowKV enhances long-context LLM inference throughput by offloading the value cache to the CPU while maintaining a low-rank key cache, landmarks, and outliers on the GPU. During decoding, it employs landmarks for efficient sparse attention, reducing computation and data movement.
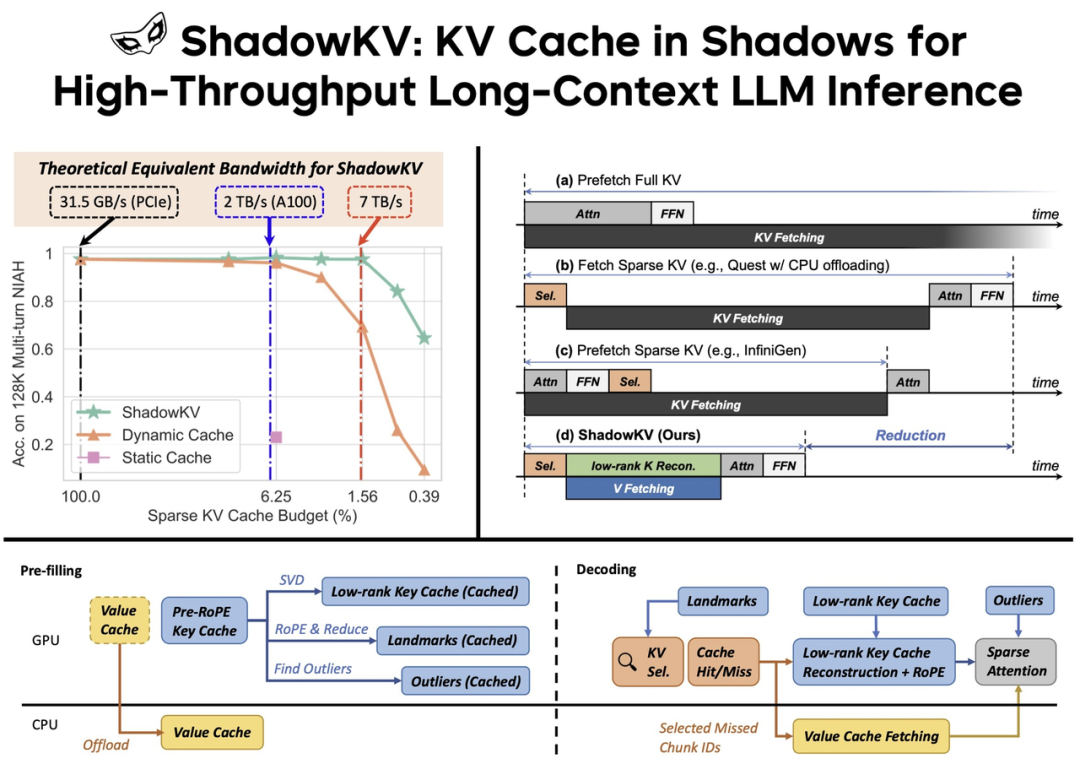
ShadowKV effectively utilizes a limited KV budget to achieve high accuracy, theoretically reaching over 7 TB/s equivalent bandwidth on an A100 GPU. The actual throughput is boosted by over 3x.
By evaluating ShadowKV on a broad range of benchmarks, including RULER, LongBench, and Needle In A Haystack, and models like Llama-3.1-8B, Llama-3-8B-1M, GLM-4-9B-1M, Yi-9B-200K, Phi-3-Mini-128K, and Qwen2-7B-128K, we demonstrate that it can support up to 6× larger batch sizes and boost throughput by up to 3.04× on an A100 GPU without sacrificing accuracy, even surpassing the performance achievable with infinite batch size under the assumption of infinite GPU memory.

How Far Is Video Generation from World Model: A Physical Law Perspective
arXiv: https://arxiv.org/pdf/2411.02385
Project Page: https://phyworld.github.io/
Exhibition Location: East Exhibition Hall A-B #E-3207
Scaling video generation models is believed to be promising in building world models that adhere to fundamental physical laws. However, whether these models can discover physical laws purely from vision can be questioned. A world model learning the true law should give predictions robust to nuances and correctly extrapolate on unseen scenarios.
In this work, we evaluate the performance across three key scenarios: in-distribution, out-of-distribution, and combinatorial generalization.
We developed a 2D simulation testbed for object movements and collisions to generate videos deterministically governed by one or more classical mechanics laws. The purpose is to evaluate the scaling effect of diffusion-based video generation models on predicting object movements.
Phyworld experiment demo
The experiments reveal sharp differences in model generalization across different scenarios: Our experiments show perfect generalization in in-distribution scenarios, measurable scaling behavior in combinatorial generalization scenarios, but failure in out-of-distribution scenarios.
Further experiments reveal two key insights about the generalization mechanisms of these models:
- The models fail to abstract general physical rules and instead exhibit "case-based" generalization behavior, i.e., mimicking the closest training example.
- When generalizing to new cases, models are observed to prioritize different factors when referencing training data: color > size > velocity > shape.
In conclusion, the study suggests that scaling alone is insufficient for video generation models to uncover fundamental physical laws, revealing the challenges and limitations in developing high-fidelity world models.

FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
arXiv: https://arxiv.org/pdf/2412.15205
Project Page: https://github.com/OliverRensu/FlowAR
Exhibition Location: East Exhibition Hall A-B #E-3109
Autoregressive (AR) modeling has achieved remarkable success in natural language processing by enabling models to generate text with coherence and contextual understanding through next token prediction. In image generation, VAR proposes scale-wise autoregressive modeling, which extends the next token prediction to the next scale prediction, preserving the 2D structure of images. However, VAR encounters two primary challenges: (1) its complex and rigid scale design limits generalization in next scale prediction, and (2) the generator's dependence on a discrete tokenizer with the same complex scale structure restricts modularity and flexibility in updating the tokenizer.
To address these limitations, this paper introduces FlowAR, a general next scale prediction method featuring a streamlined scale design, where each subsequent scale is simply double the previous one. This eliminates the need for VAR's intricate multi-scale residual tokenizer and enables the use of any off-the-shelf Variational AutoEncoder (VAE).
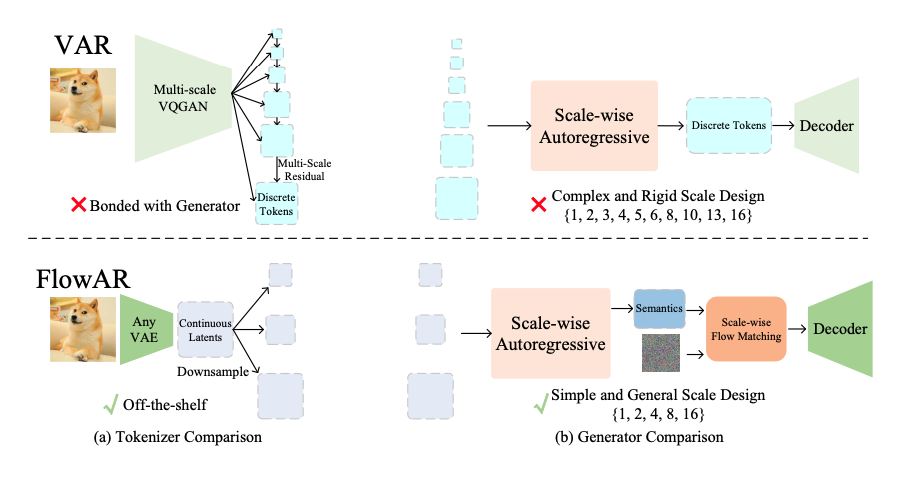
Comparison between VAR and FlowAR in (a) tokenizer and (b) generator design. (a) VAR utilizes a complex multi-scale residual VQGAN discrete tokenizer, whereas FlowAR can leverage any off-the-shelf VAE continuous tokenizer, offering greater flexibility by constructing coarse scale token maps through direct downsampling of the finest scale token map. (b) VAR's generator is constrained by the same complex and rigid scale design as its tokenizer, while FlowAR benefits from a simple and flexible scale design, enhanced by the flow matching model.
This paper proposes a simplified design that enhances generalization in next scale prediction and facilitates the integration of Flow Matching for high-quality image synthesis. We validate the effectiveness of FlowAR on the challenging ImageNet-256 benchmark, demonstrating superior generation performance compared to previous methods.

Diffusion Adversarial Post-Training for One-Step Video Generation
arXiv: https://arxiv.org/pdf/2501.08316
Project Page: https://seaweed-apt.com/
Exhibition Location: East Exhibition Hall A-B #E-3206
Diffusion models are widely used for image and video generation, but their iterative generation process is slow because they require multi-step neural network evaluations. APT1 is the first model to demonstrate one-step text-to-video generation. It can generate a 2-second, 1280×720, 24fps video in a single step. On 8×H100 GPUs, the entire pipeline can run in real time. Additionally, the model is capable of generating 1024px images in a single step, achieving quality comparable to state-of-the-art methods.

Image generation comparison across different models: 25-step generation and 1-step generation. APT1 is significantly better in image details and is among the best in structural integrity.
This paper proposes Adversarial Post-Training (APT) against real data following diffusion pre-training for one-step video generation. To improve the training stability and quality, we introduce several improvements to the model architecture and training procedures, along with an approximated R1 regularization objective. These improvements make adversarial training possible for exceptionally large transformer models. By virtue of APT, we have trained what may be the largest generative adversarial network (GAN) ever reported to date (16B). However, we observed quality degradation in the one-step generation process, identified the root cause, and plan to optimize the model in future work.
Real-time video generation will be applied across a wider array of scenarios, emerging as a key trend shaping the future of technology. The APT series focuses on fundamental research in real-time image and video generation. Feel free to explore more on our homepage.

DiTAR: Diffusion Transformer Autoregressive Modeling for Speech Generation
arXiv: https://arxiv.org/pdf/2502.03930
Project Page: https://spicyresearch.github.io/ditar/
Exhibition Location: East Exhibition Hall A-B #E-3211
Several recent studies have attempted to autoregressively generate continuous speech representations without discrete speech tokens by combining diffusion and autoregressive models, yet they often face challenges with excessive computational loads or suboptimal outcomes.
In this work, we propose Diffusion Transformer Autoregressive Modeling (DiTAR), a patch-based autoregressive framework combining a language model with a diffusion transformer.
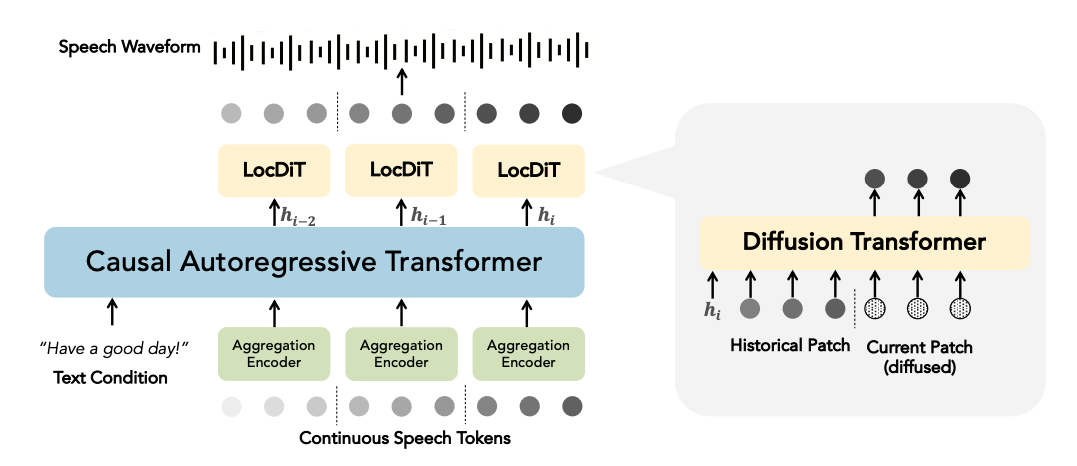
DiTAR is composed of an aggregation encoder for input, a causal language model backbone, and a diffusion decoder, LocDiT, predicting local patches of tokens.
This approach significantly enhances the efficacy of autoregressive models for continuous tokens and reduces computational demands. DiTAR utilizes a divide-and-conquer strategy for patch generation, where the aggregation encoder processes each patch of continuous tokens to produce a single vector, the language model then processes these aggregated patch embeddings, and the diffusion transformer subsequently generates the next patch based on the output of the language model. For inference, we propose defining temperature as the time point of introducing noise during the reverse diffusion ODE to balance diversity and determinism.
In voice cloning, DiTAR achieves state-of-the-art performance in robustness, speaker similarity, and naturalness. In addition, extensive experiments demonstrate that DiTAR has superb scalability.
Click for more details on Seed's ICML 2025 accepted papers and other publicly available research!