Official Release of Seed1.8: A Generalized Agentic Model
As the range of tasks for large foundation models continues to expand, we have observed that user demands are shifting from seeking advice and querying information to having models directly execute complex workflows. This means that generalized models must possess broader capabilities beyond the existing scope of language generation.
In this context, we are officially launching Seed1.8, our new generalized agentic model that features robust multimodal capabilities and supports text and image input. It can efficiently and accurately accomplish tasks in scenarios such as information retrieval, code generation, GUI interaction, and complex workflows, meeting increasingly diverse technical needs.
Seed1.8 provides the following three core features:
Generalized Agentic Model: Seed1.8 integrates search, code, and GUI Agent capabilities, and its native foundational vision capabilities enable it to "see" and directly interact with interfaces.
Low-latency, High-efficiency Responses: Seed1.8 supports three thinking modes, allowing it to automatically adjust its processing methods based on task complexity. It also optimizes the token count required for image encoding, significantly improving inference efficiency without compromising intelligence.
Addressing Real-world Needs: Seed1.8 has undergone rigorous evaluation and testing in simulated real-world workflows, demonstrating strong performance across wide-ranging scenarios such as information retrieval, intent recognition, and complex instruction following.
We have conducted comprehensive and systematic capability testing on Seed1.8, using both established public benchmarks and our internal evaluation system oriented toward real-world applications. The complete results are detailed in the Model Card. The sections below break down Seed1.8's performance across key capabilities as a generalized agent, large language model (LLM), and vision–language model (VLM).
Project Homepage(with Model Card):
https://seed.bytedance.com/seed1_8
Try Now:
On the Volcano Engine official website, go to: Large Models > Doubao Large Models > Doubao1.8 > Try Now.
Seed1.8's Generalized Agentic Capabilities
Proven Performance in Diverse Real-World Tasks
Seed1.8 has shown significant promise as a generalized agentic model in a wide range of benchmarks, achieving impressive scores in tasks such as GUI Agent, search, and industry-specific applications.
The challenges in agentic capabilities are manifested in the following aspects:
Seed1.8 has achieved breakthroughs in addressing the above challenges. Evaluation results indicate that it possesses industry-leading GUI Agent capabilities, showing further improvement over Seed1.5-VL. It has consistently demonstrated reliability in executing multi-step tasks on various systems and interfaces across desktop, web, and mobile environments.
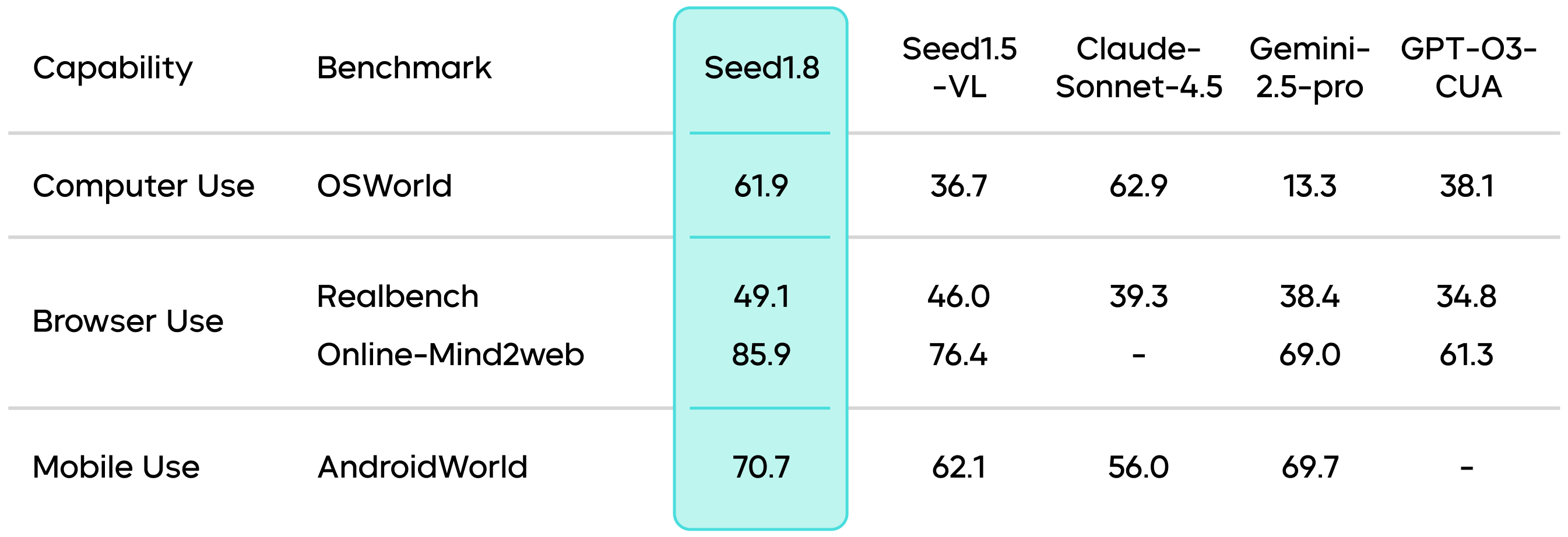
Seed1.8 also excels in search tasks, maintaining top-tier performance in the industry across multiple public agentic search evaluation benchmarks. For example, it achieves a high score of 67.6 in the BrowseComp-en benchmark, surpassing other leading models such as Gemini-3-Pro.
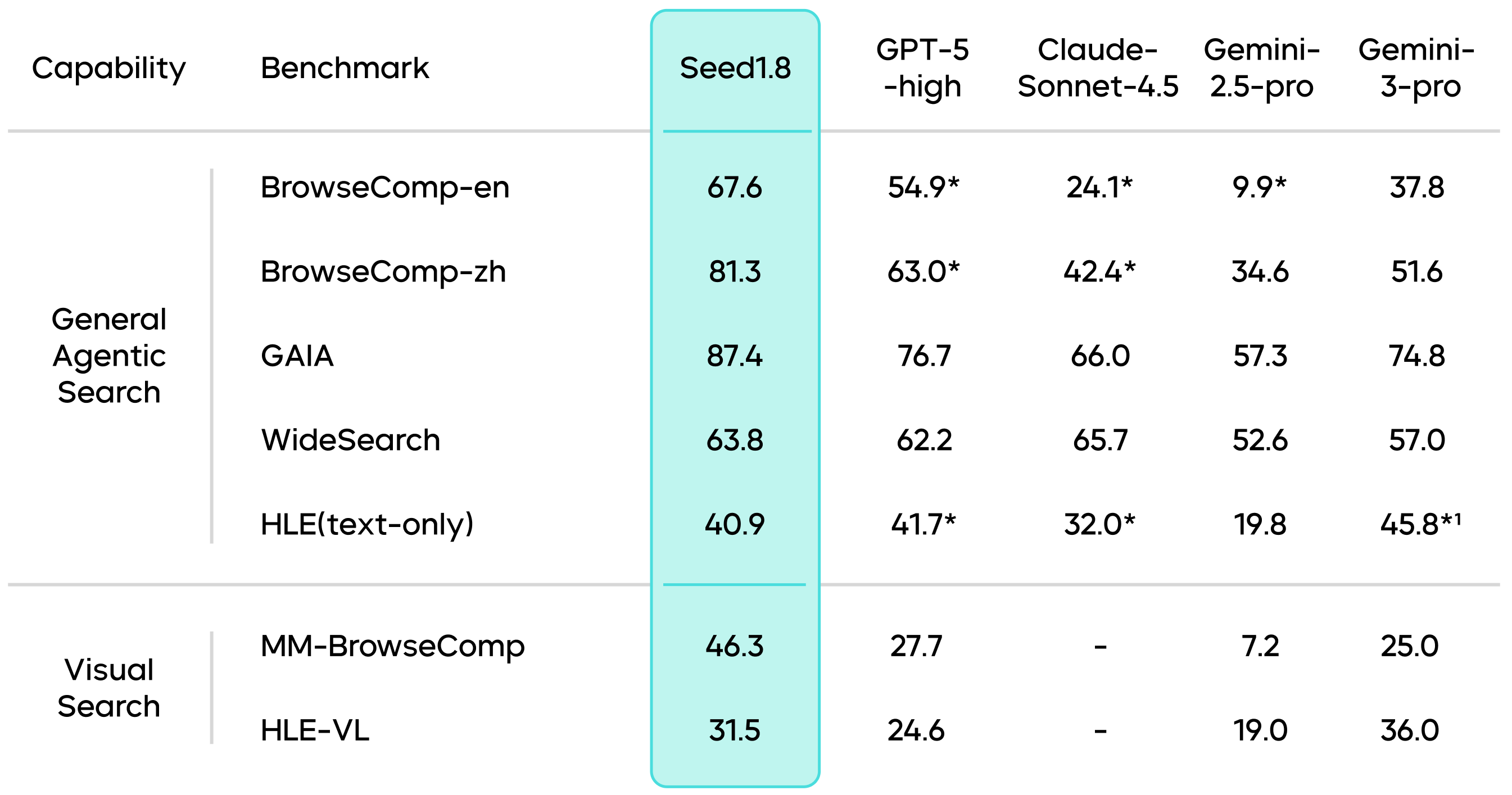
Results marked with an * are sourced from public technical reports. Results marked with a 1 are sourced from official full-set scores.
In benchmarks related to agentic coding, Seed1.8 has demonstrated robust capabilities for real-world software engineering scenarios. This indicates that Seed1.8 is not limited to code generation but possesses agentic programming capabilities to continuously advance tasks in actual development environments, laying the foundation for applications in complex engineering scenarios.
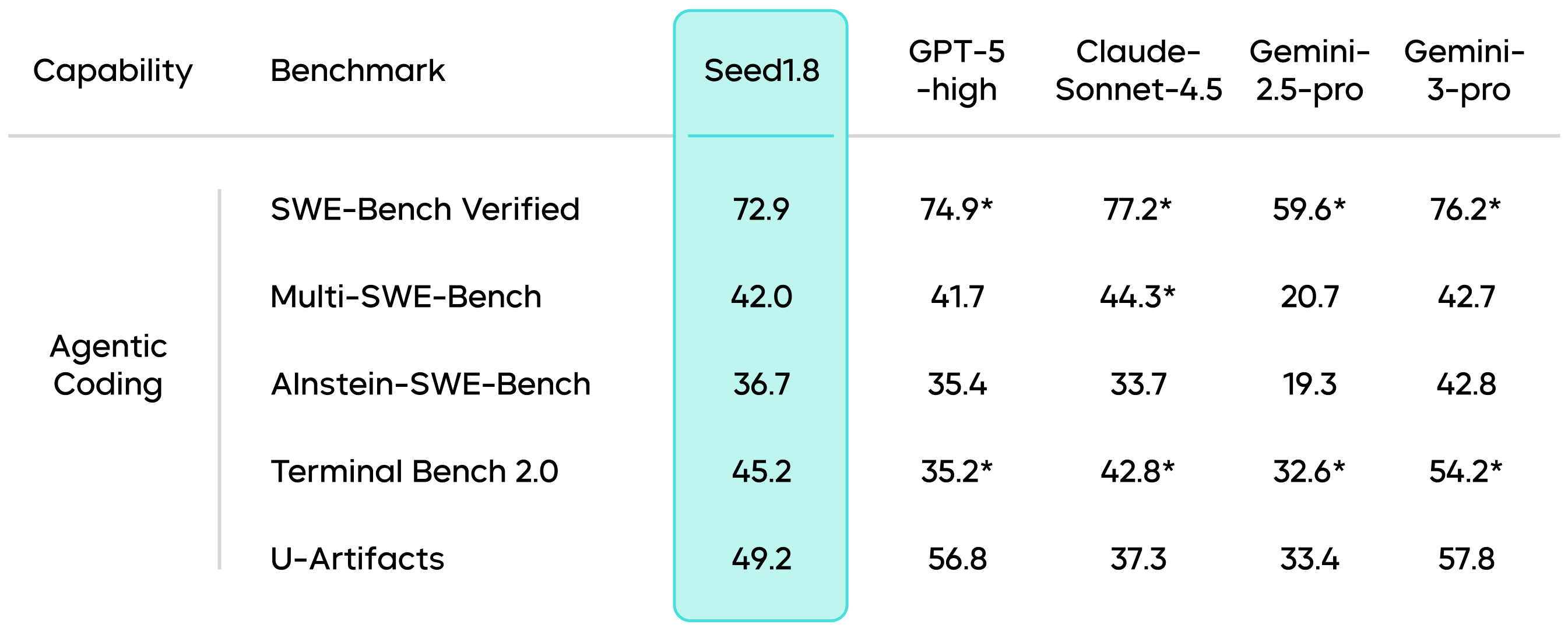
Results marked with an * are sourced from public technical reports.
Seed1.8's performance in real-world application tasks with high economic value is also noteworthy.
The evaluations on FinSearchComp and XpertBench show that the model delivers relatively consistent and efficient performance on financial and business-related tasks. Additionally, Seed1.8 achieves a score of 47.2 on the WorldTravel multimodal application task, indicating its reliability in addressing real-world needs such as travel planning and user requirement analysis.

Scores related to WorldTravel are based on the best of five attempts.
As shown in the figure below, Seed1.8 creates an itinerary for a family with a limited budget to visit Berlin. It integrates information from various sources, such as travel platforms, booking websites, and restaurant menus, and leverages excellent reasoning and visual interpretation capabilities to quickly generate a travel plan that adheres to all user constraints.
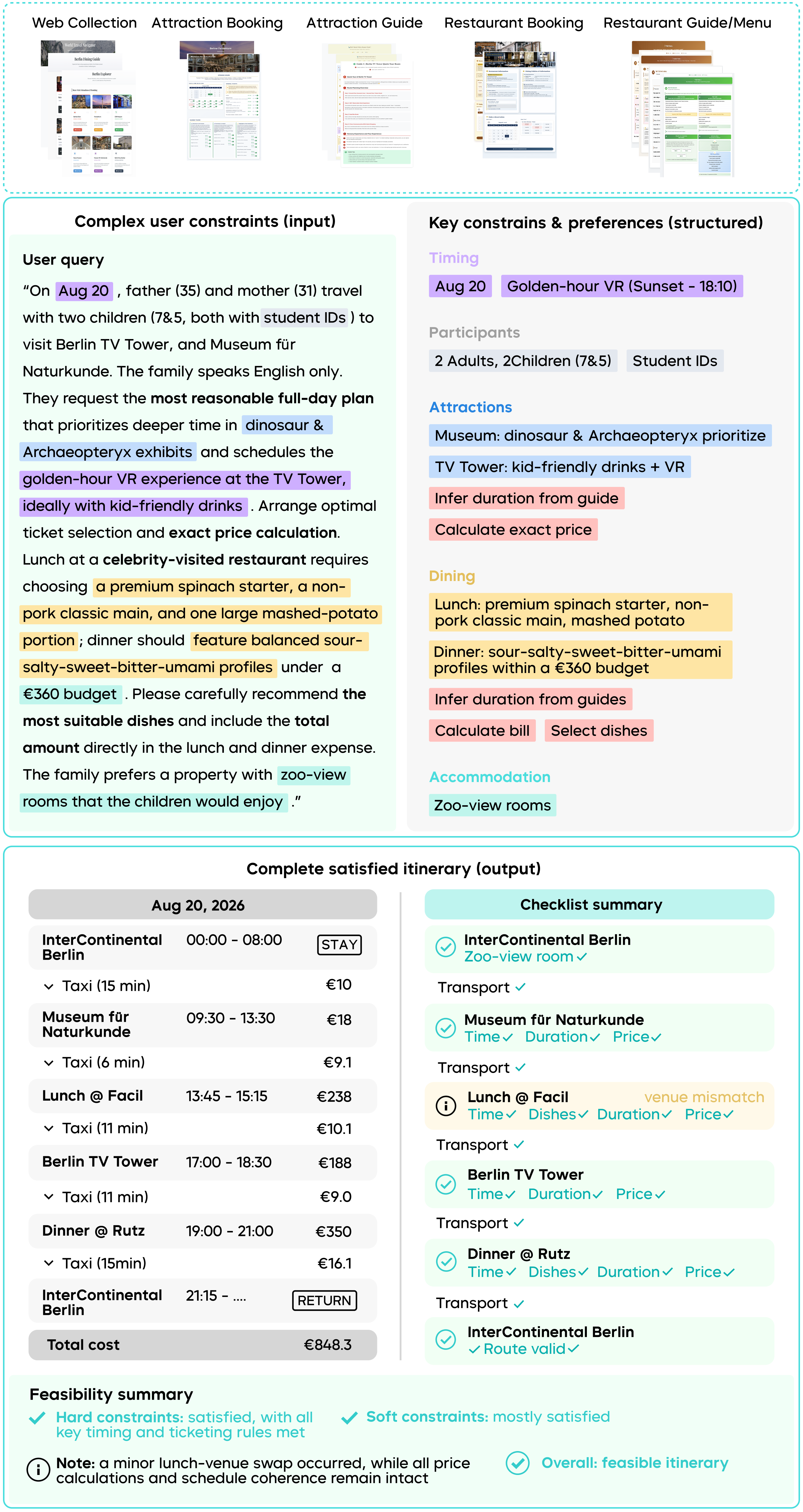
In the case above, Seed1.8 not only makes recommendations based on basic conditions like budget and time but also precisely arranges the itinerary according to the users' specific preferences (e.g., dietary tastes, accommodation environment). Through intelligent reasoning and constraint optimization, the model automatically synthesizes information across multiple dimensions to produce a complete and practical travel plan, demonstrating its proficiency in complex decision-making and personalized customization.
Evaluation Results for LLM Capabilities
On Par with Leading Generalized Models
Seed1.8 has demonstrated consistent and competitive performance on multiple public LLM benchmarks, ranking among the top tier in the industry.
Its overall performance in core fundamental capabilities such as mathematics, reasoning, and knowledge understanding is comparable to the industry's leading generalized models.
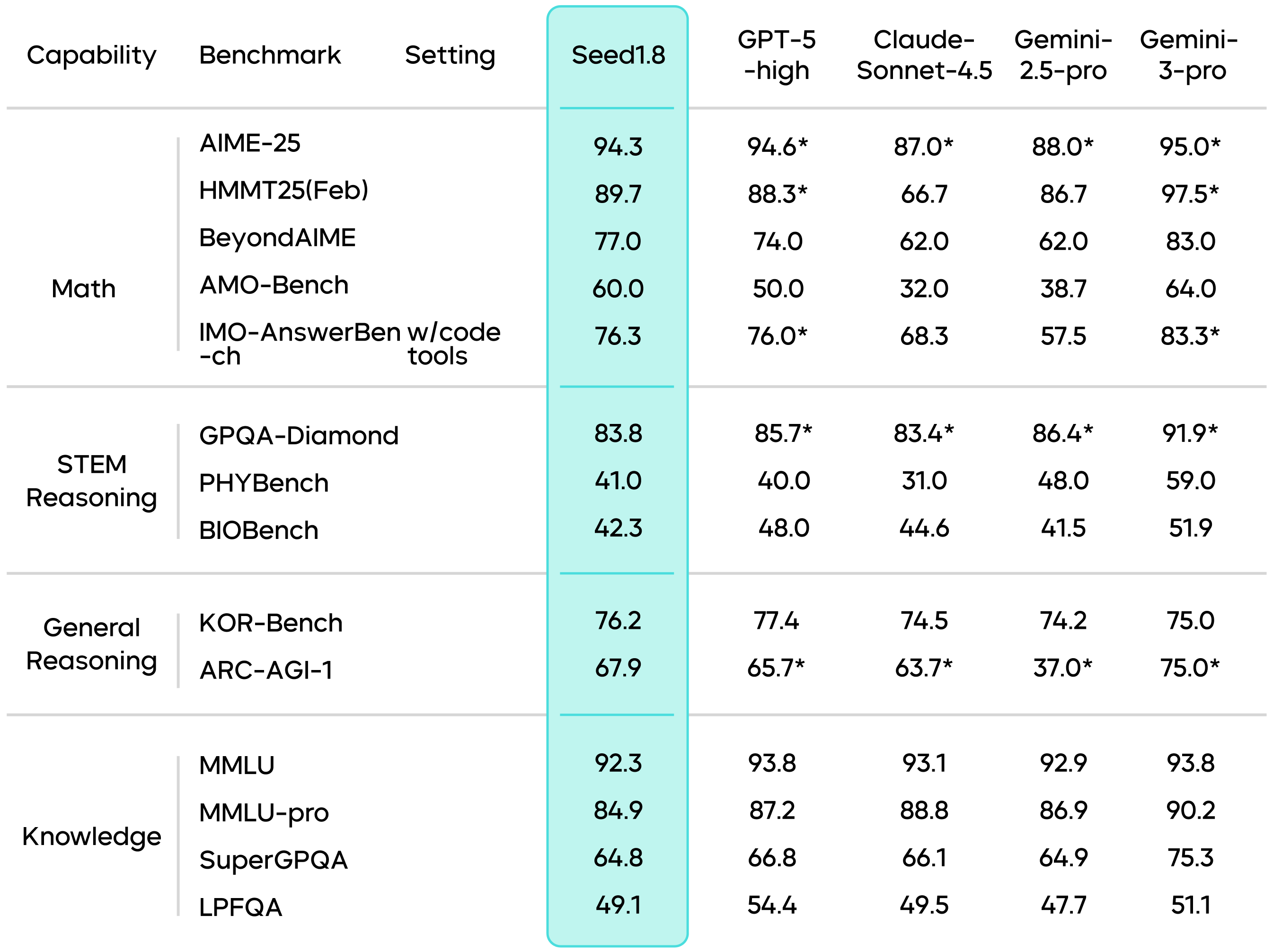
Results marked with an * are sourced from public technical reports.
In benchmarks related to complex instruction following, Seed1.8 exhibits consistent execution capabilities. Such tasks often involve multiple constraints, reverse conditions, or long-chain reasoning, requiring the model to maintain an accurate understanding of instructional goals throughout multi-step processes. The results indicate that Seed1.8 performs comparably to leading models across various complex instruction benchmarks.
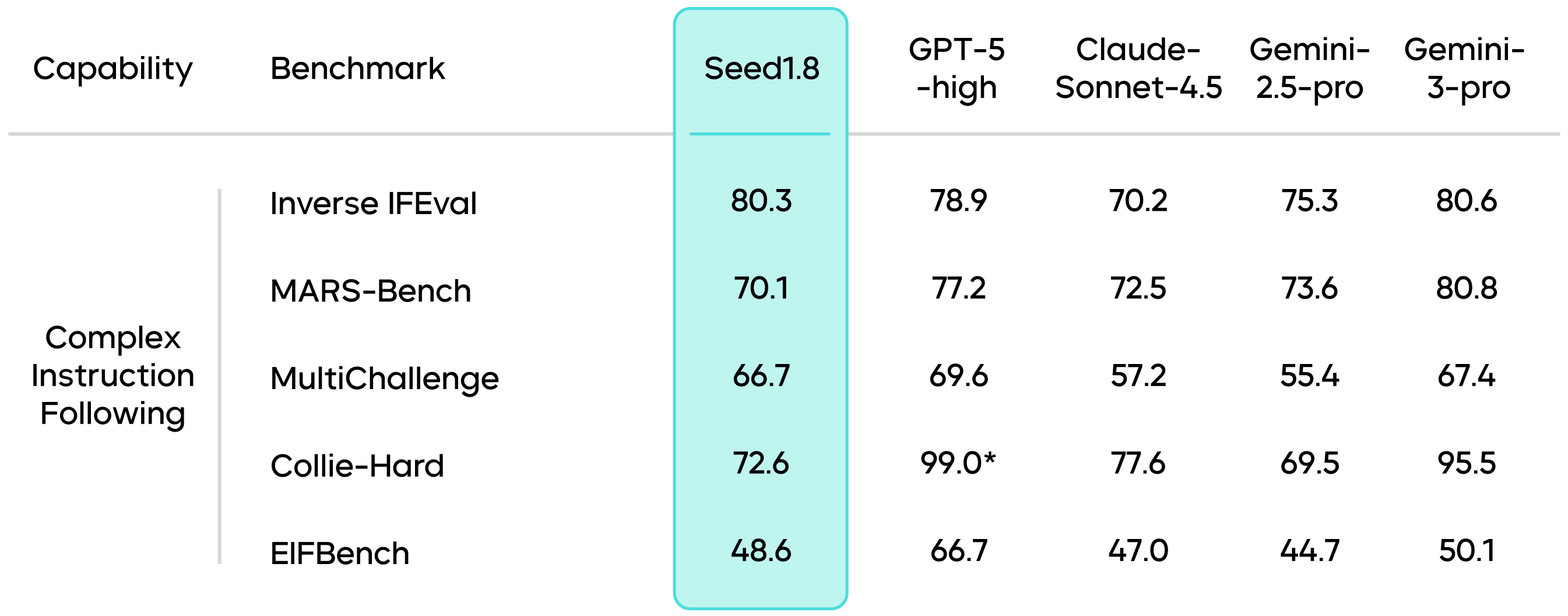
Results marked with an * are sourced from public technical reports.
Beyond benchmark evaluations, Seed1.8's capabilities have also been validated in high-value, real-world application scenarios defined by industry experts. This validation covers tasks like educational tutoring, customer service Q&A, information processing, intent recognition, information extraction, and complex multi-step workflows, proving the model's applicability in real-world usage.
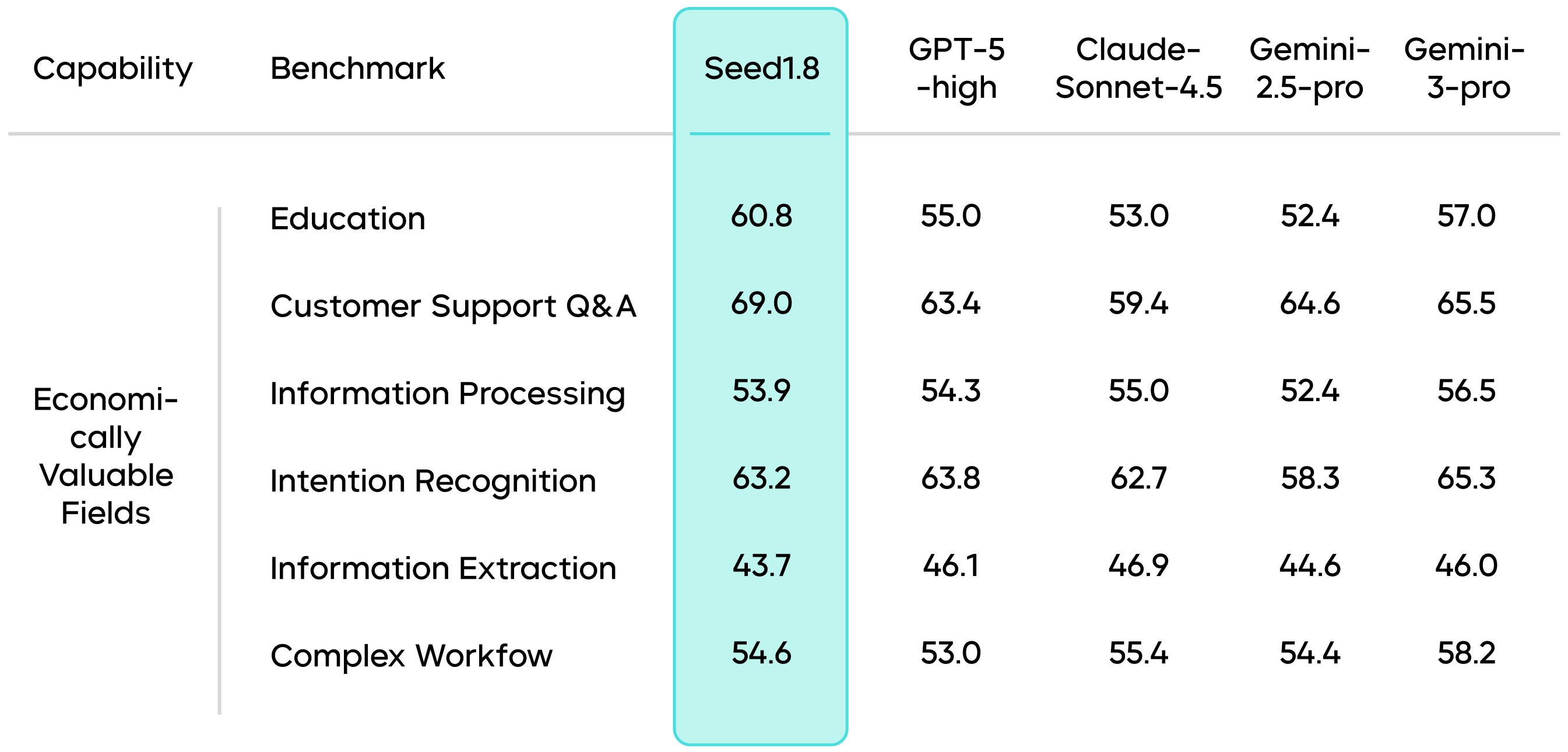
Evaluation Results for VLM Multimodal Capabilities
Outstanding Performance with a Notable Leap in Scores
Seed1.8 demonstrates outstanding performance across multiple vision-language benchmarks. It surpasses its predecessor Seed1.5-VL in multimodal reasoning tasks and approaches the state-of-the-art Gemini-3-Pro on most tasks.
Image Understanding Capabilities
Seed1.8 exhibits excellent performance in image-based visual understanding tasks. In multimodal reasoning tasks, Seed1.8 achieves a top score of 11.0 on the highly challenging visual reasoning benchmark ZeroBench, significantly increasing the number of correctly answered questions compared to its predecessor Seed1.5-VL.

Results marked with an * are sourced from public technical reports.
In general-purpose visual Q&A tasks, Seed1.8 achieves a score of 62.0 on the VLMsAreBiased benchmark, substantially outperforming other models.
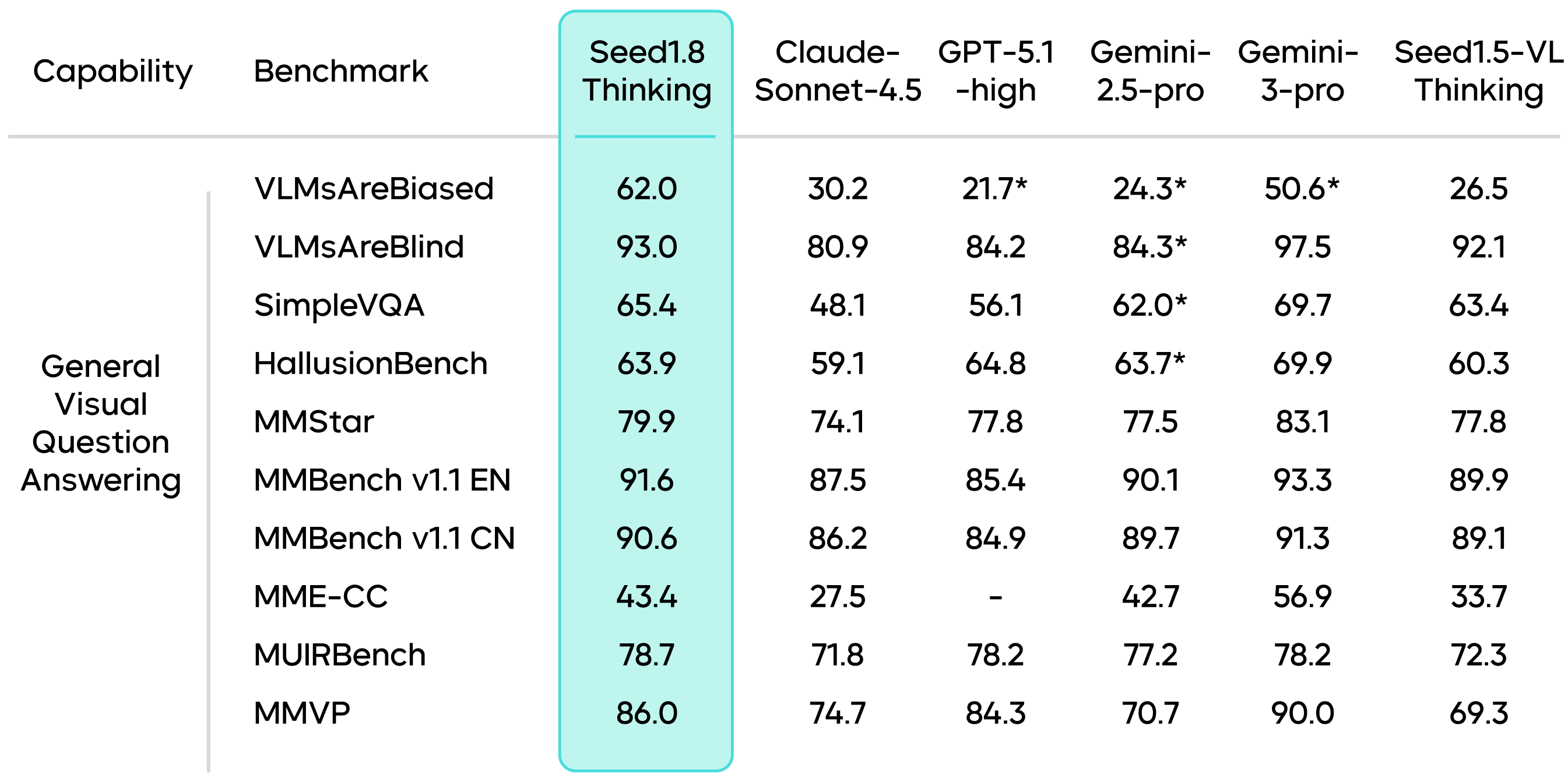
Results marked with an * are sourced from public technical reports.
Seed1.8 excels in multiple benchmarks for 2D and 3D spatial understanding. When handling 3D spatial understanding and complex tasks, especially on dynamic and intricate datasets, it demonstrates remarkable adaptability and reasoning capabilities.
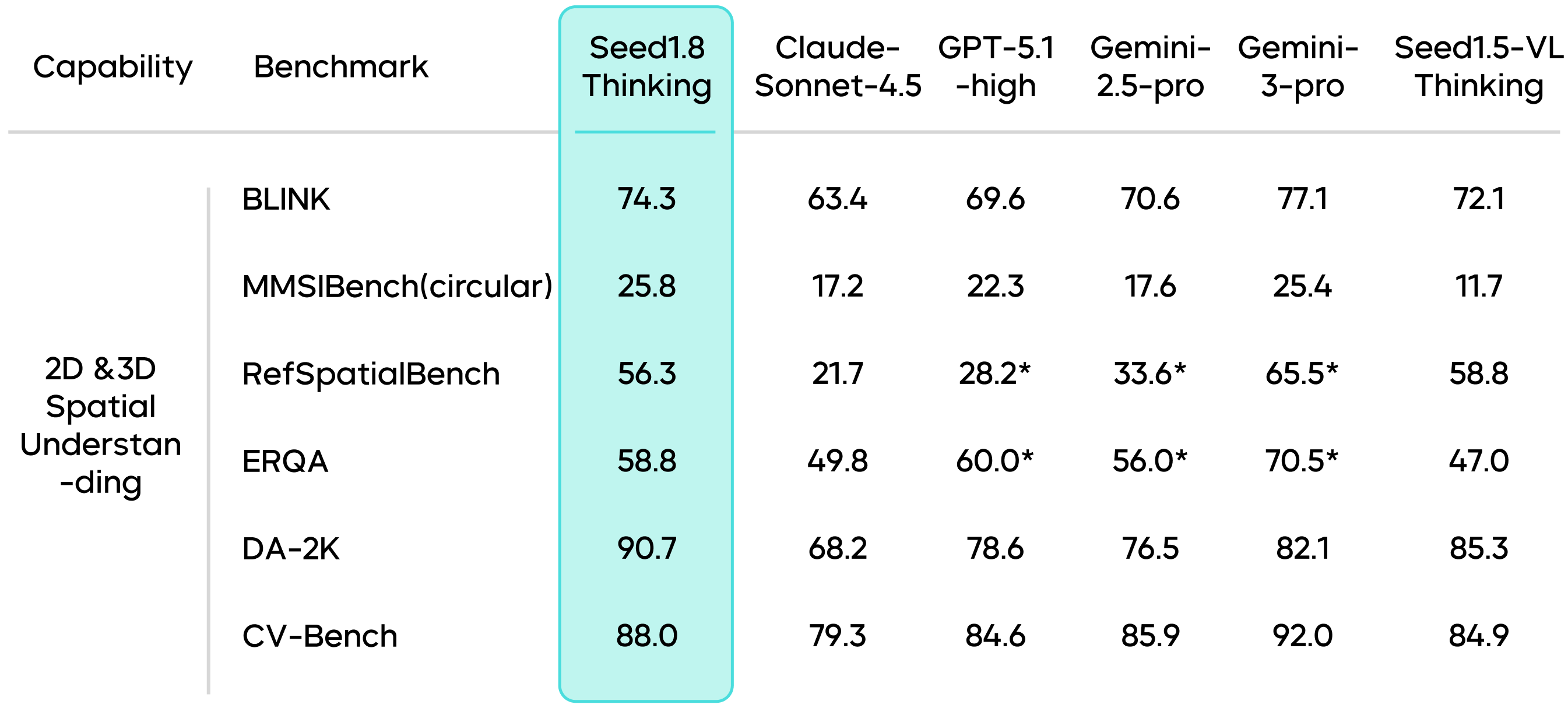
Results marked with an * are sourced from public technical reports.
Video Understanding Capabilities
Seed1.8 delivers outstanding performance in video understanding, particularly showing strong adaptability in tasks such as video reasoning, motion and perception, and long-video understanding.
In tasks involving dynamic scenes and real-time perception, Seed1.8 ranks among the top performers. This demonstrates the model's proficiency in complex perceptual tasks, especially in efficiently processing real-time information.
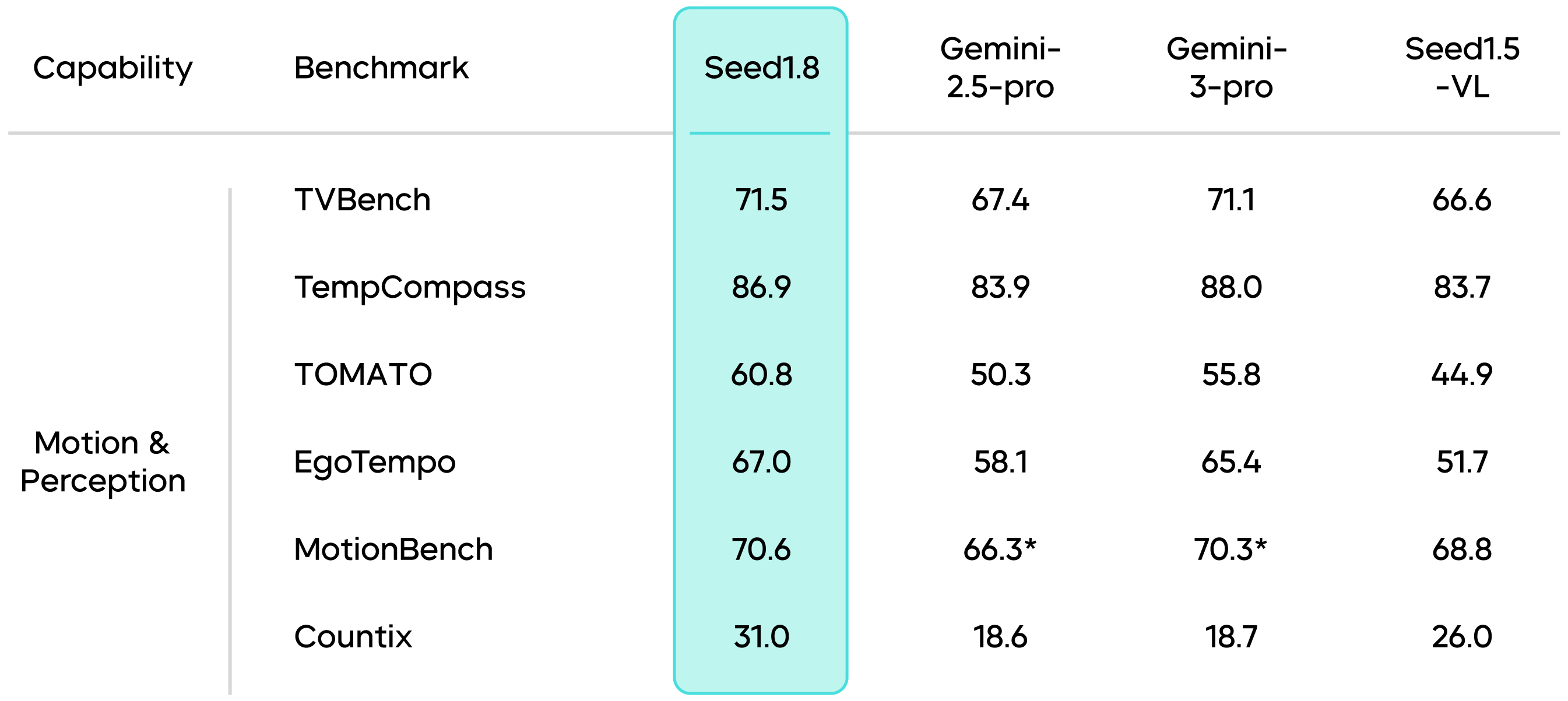
Results marked with an * are sourced from public technical reports.
Seed1.8 stands out in long-video understanding tasks, achieving a high score of 87.8 on the VideoMME benchmark. Long-video understanding typically involves complex temporal spans, contextual changes, and long-context multi-hop reasoning. In response, Seed1.8 integrates the video tool (VideoCut), enabling more precise long-video reasoning and high-frame-rate motion perception through slow-motion playback of selected segments.
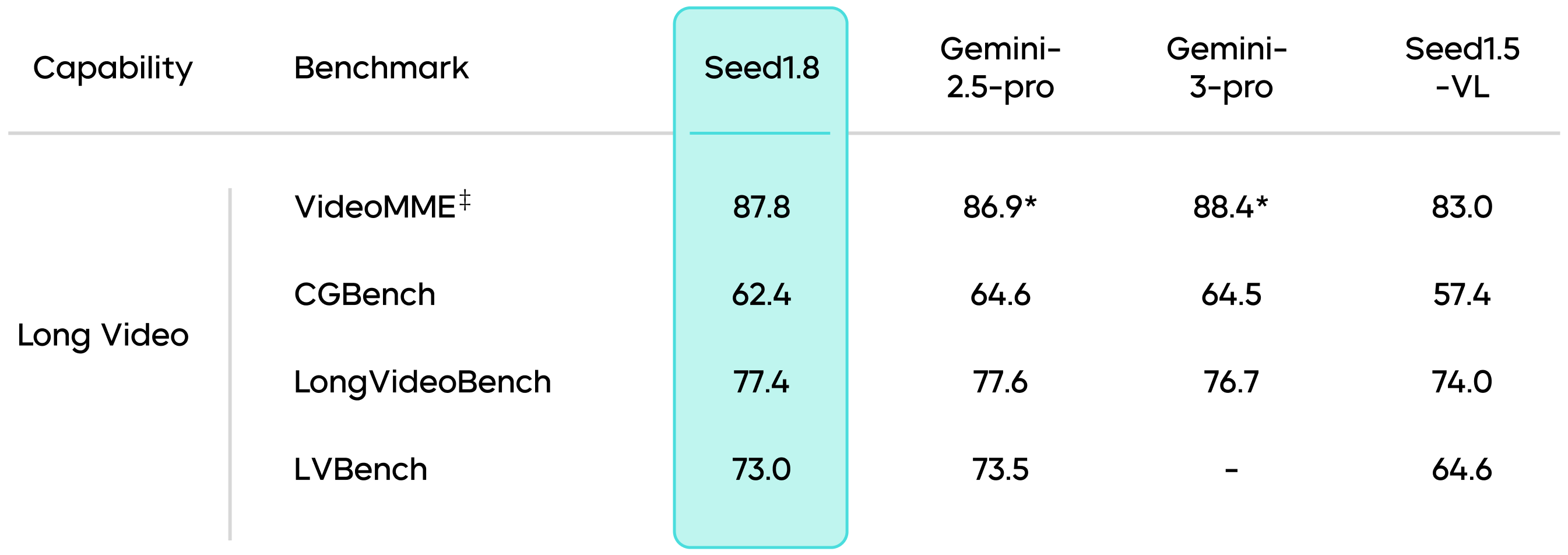
Results marked with an * are sourced from public technical reports. For benchmarks marked with a ‡, subtitles are included for evaluation.
In video processing, Seed1.8 also achieves a significant improvement in token efficiency, which not only enhances understanding capabilities but also provides users with lower-latency real-time video processing experiences.

Even when configured with fewer Max Video Tokens, Seed1.8 still outperforms Seed1.5-VL across multiple long-video benchmarks.
Furthermore, by introducing multiple thinking modes, Seed1.8 embeds the ability to dynamically adjust its reasoning depth. Users can flexibly tune the model's inference depth and computational load to suit different task requirements.
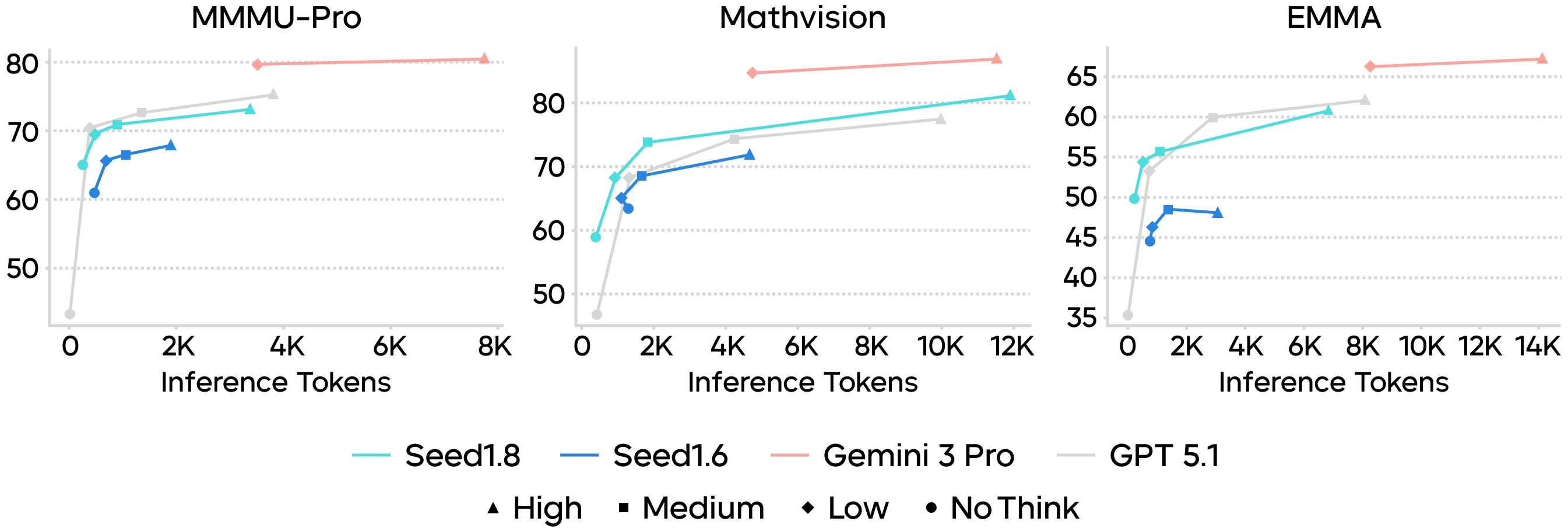
Comparison of inference cost and accuracy between Seed1.8 and other models across various multimodal reasoning benchmarks.
Future outlook
Building upon Seed1.8, we will continue to iterate toward a versatile agentic model capable of addressing challenges in real‑world complex tasks. In the future, we will focus on the following areas:
Ongoing Scaling and Performance Improvement: By leveraging enhanced computational resources, we will further advance the model's capabilities during both pre‑training and post‑training stages, thereby meeting increasingly complex task requirements.
We also believe that establishing an evaluation system oriented toward real‑world needs is crucial for enhancing the stability, generalization, and usability of agentic models. To this end, some evaluation datasets developed for Seed1.8 have been publicly available or will be open-sourced in the future, in the hope of advancing the community collectively.