Seed LiveInterpret 2.0 Released: An End-to-End Simultaneous Interpretation Model Featuring Ultra-High Accuracy Close to Human Interpreters, Low Latency of 3 Seconds, and Real-Time Voice Cloning
Seed LiveInterpret 2.0 Released: An End-to-End Simultaneous Interpretation Model Featuring Ultra-High Accuracy Close to Human Interpreters, Low Latency of 3 Seconds, and Real-Time Voice Cloning
Date
2025-07-24
Category
Models
Simultaneous interpretation (SI) is considered one of the most challenging sectors in the translation industry. It requires interpreters to provide high-quality speech-to-speech interpretation within a very short period of time. Therefore, SI stands as the most demanding task for researchers in translation technology.
Today, we released Seed LiveInterpret 2.0, an end-to-end SI model.
Seed LiveInterpret 2.0 is the first product-level SI solution that covers both Chinese-to-English and English-to-Chinese interpretation, achieving near-human accuracy and ultra-low latency. This model delivers state-of-the-art (SOTA) interpretation quality with ultra-low latency.
This is enabled by a full-duplex speech understanding and generation framework, which supports both Chinese-to-English and English-to-Chinese interpretation. Like human simultaneous interpreters, it is capable of processing multi-speaker input, and receiving audio input while providing interpreted speech simultaneously with ultra-low latency. In addition, Seed LiveInterpret 2.0 supports zero-shot voice cloning, enabling smoother and more natural communication.
Test results reveal that Seed LiveInterpret 2.0 can fluently output interpreted speech in English in the original speaker's voice when challenged to process a 40-second long-form Chinese speech.
Seed LiveInterpret 2.0 can quickly imitate voices, such as Pigsy in Journey to the West, Lin Daiyu in Dream of the Red Chamber, or even other "unheard" voices of characters, to fluently communicate in real time.
Seed LiveInterpret 2.0 offers the following advantages over traditional SI systems:
High-accuracy interpretation close to human simultaneous interpreters
The excellent speech understanding capabilities of Seed LiveInterpret 2.0 ensure high interpretation accuracy. In complex scenarios such as multi-speaker conferences, the interpretation accuracy of Seed LiveInterpret 2.0 in both Chinese-to-English and English-to-Chinese tasks exceeds 70%. The interpretation accuracy on discourses given by a single speaker exceeds 80%, which is close to the level of professional human simultaneous interpreters.
Speech-to-speech interpretation with ultra-low latency
The full-duplex speech understanding and generation framework enables Seed LiveInterpret 2.0 to interpret with a latency of just 2 to 3 seconds, which is over 60% lower than traditional SI systems. It achieves true simultaneous speech-to-speech interpretation.
Zero-shot voice cloning to ensure high-fidelity and natural speech generation
By simply sampling real-time voice signals, Seed LiveInterpret 2.0 can extract voice features and output speech across languages in the speaker's own voice, creating a more natural and engaging communication experience.
Intelligent balance among interpretation quality, latency, and speech output pace
Seed LiveInterpret 2.0 can automatically adjust the output pace based on speech clarity, fluency, and complexity, and adapt to different languages. It delivers natural, fluent, and well-paced interpretation even when processing long-form speech.
Currently, the tech report of Seed LiveInterpret 2.0 has been released. This model is now publicly available on Volcano Engine. Feel free to try it out. In addition, Seed LiveInterpret 2.0 will be integrated into our Ola Friend earbuds at the end of August, making Ola Friend the first smart hardware to support this model.
Tech Report: http://arxiv.org/pdf/2507.17527
Model Homepage: https://seed.bytedance.com/seed_liveinterpret
Link: To try it out, log on to Volcano Engine and select the speech model "Doubao - Simultaneous Interpretation 2.0". https://console.volcengine.com/ark/region:ark+cn-beijing/experience/voice?type=SI
End-to-End SI Model, Balance Between Interpretation Quality and Latency
SI often faces challenges such as overlapping speech in multi-speaker conversations, unclear audio input, disfluent expressions, and incoherent logic. Due to limited capabilities in speech understanding and interpretation, traditional SI systems often provide low-accuracy, high-latency interpretation in complex scenarios, resulting in an unsatisfactory user experience.
ByteDance Seed released Seed LiveInterpret 1.0 (also known as CLASI) in 2024 to address the key challenges in speech-to-text translation: accuracy, domain expertise, and latency. However, this model does not support speech-to-speech interpretation.
A year later, ByteDance Seed released Seed LiveInterpret 2.0 to deliver high-quality simultaneous interpretation with low latency.。
Seed LiveInterpret 2.0 is powered by end-to-end speech understanding and generation technology. During the continual training (CT) process, ByteDance Seed used both parallel and non-parallel speech data to achieve modality alignment between speech and text. The team also used data collected from diverse multimodal tasks, including speech-only, text-only, speech-to-speech, and text-to-text processing tasks in different languages, to continuously train the model, aiming to improve its accuracy in speech understanding and voice cloning capability.
Following continual training, ByteDance Seed conducted supervised fine-tuning (SFT) on high-quality, human-annotated data to activate crucial capabilities in terms of timing and accuracy for simultaneous speech interpretation.
After CT and SFT, the fine-tuned model is ready to deliver high-quality interpretation and clone voices. However, the latency is not as low as professional human simultaneous interpreters.
To further reduce the latency of speech output and boost interpretation performance, ByteDance Seed introduced reinforcement learning and built process reward and outcome reward models based on factors such as interpretation quality and latency. Compared with the SFT model, reinforcement learning reduces the latency by more than 20% and further improves the interpretation quality.
With the preceding efforts, Seed LiveInterpret 2.0 comes with the following features:
Accurate speech understanding in complex scenarios
Built upon long-standing expertise in speech understanding, Seed LiveInterpret 2.0 can consistently deliver high-quality interpretation and correct potential mistakes in complex scenarios, such as multi-speaker conversations, mixed Chinese-English input, unclear speech, and scrambled word order.
Seed LiveInterpret 2.0 can accurately interpret speech with mixed Chinese and English input
Seed LiveInterpret 2.0 can simultaneously interpret Chinese tongue twisters and corny jokes
Truly simultaneous speech-to-speech interpretation
Powered by a full-duplex speech understanding and generation framework, Seed LiveInterpret 2.0 can continuously perform simultaneous interpretation.
The model can understand speech input while outputting interpreted speech and providing text output (source speech or interpreted speech). Traditional cascaded SI systems can only synthesize speech after the text is generated, resulting in high latency.
Simultaneous interpretation in workplace settings: Bidirectional Chinese-English communication with high accuracy and low latency
Zero-shot real-time voice cloning
Benefiting from its unified speech understanding and generation framework, Seed LiveInterpret 2.0 can accurately imitate the voice of the speaker without any pre-recorded voice samples. With input from live conversations only, it can clone the speaker's voice and synthesize the speech.
In addition, the model can imitate the acoustic features and talking style of the speaker to ensure that the speech is consistent in voice, tone, and rhythm.
Seed LiveInterpret 2.0 supports zero-shot voice cloning to produce speech that closely matches the speaker's voice and sounds natural
Intelligent balance between translation accuracy and latency
Seed LiveInterpret 2.0 can automatically tune hyperparameters to balance interpretation quality and latency.
When the input speech is fluent, clear, and standard, the model responds with minimal latency. When the input speech is disfluent or contains restarts/repetitions, the model waits for appropriate content before starting interpretation to ensure higher interpretation accuracy.
Seed LiveInterpret 2.0 can respond within a short response time when processing fluent and clear speech input in workplace settings
When processing long-form speech input, such as discourses, Seed LiveInterpret 2.0 ensures that the interpreted speech mirrors the pacing of the original speech. This helps avoid lengthy output and keeps the interpretation in sync with the speaker.
Seed LiveInterpret 2.0 can consistently deliver accurate, natural, and well-paced interpretation for vivid, detailed expressions in specific domains
Outstanding Performance in Human Evaluations, Approaching the Level of Human Simultaneous Interpreters
To evaluate Seed LiveInterpret 2.0, ByteDance Seed invited a group of professional interpreters to strictly assess the model's performance.
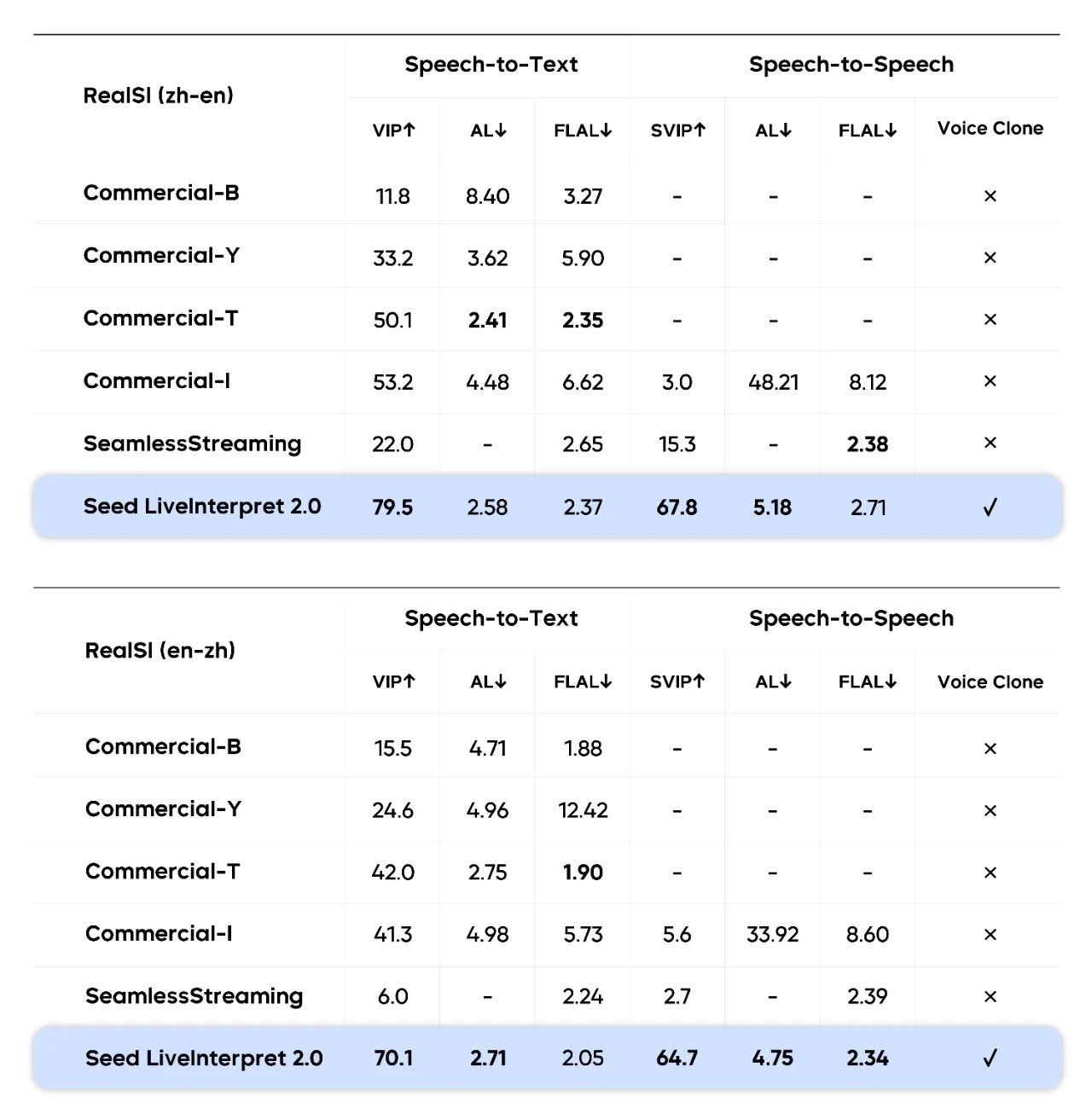
The evaluations use the RealSI dataset, which consists of public test sets encompassing both English-to-Chinese and Chinese-to-English directions across 10 domains. The evaluation team relies on the Valid Information Proportion metric to benchmark Seed LiveInterpret 2.0 and other industry-leading SI systems in the Chinese-to-English direction.
Human evaluations: translation accuracy higher than 74% and average latency lower than 3 seconds
The evaluation results show that in speech-to-text SI tasks, the average human evaluation score for Seed LiveInterpret 2.0's bidirectional Chinese-English translation quality reached 74.8 (measuring translation accuracy, out of 100), outperforming the second-ranked baseline system (47.3) by 58%.
In speech-to-speech tasks, only 3 evaluated translation systems in the industry support this capability. Among them, Seed LiveInterpret 2.0's average bidirectional Chinese-English translation quality reached a score of 66.3 (measuring not only translation accuracy but also metrics such as speech output latency, speech rate, pronunciation, and fluency, out of 100), significantly higher than other baseline systems and reaching a level close to that of professional human simultaneous interpreters. Meanwhile, most baseline systems do not support voice cloning.
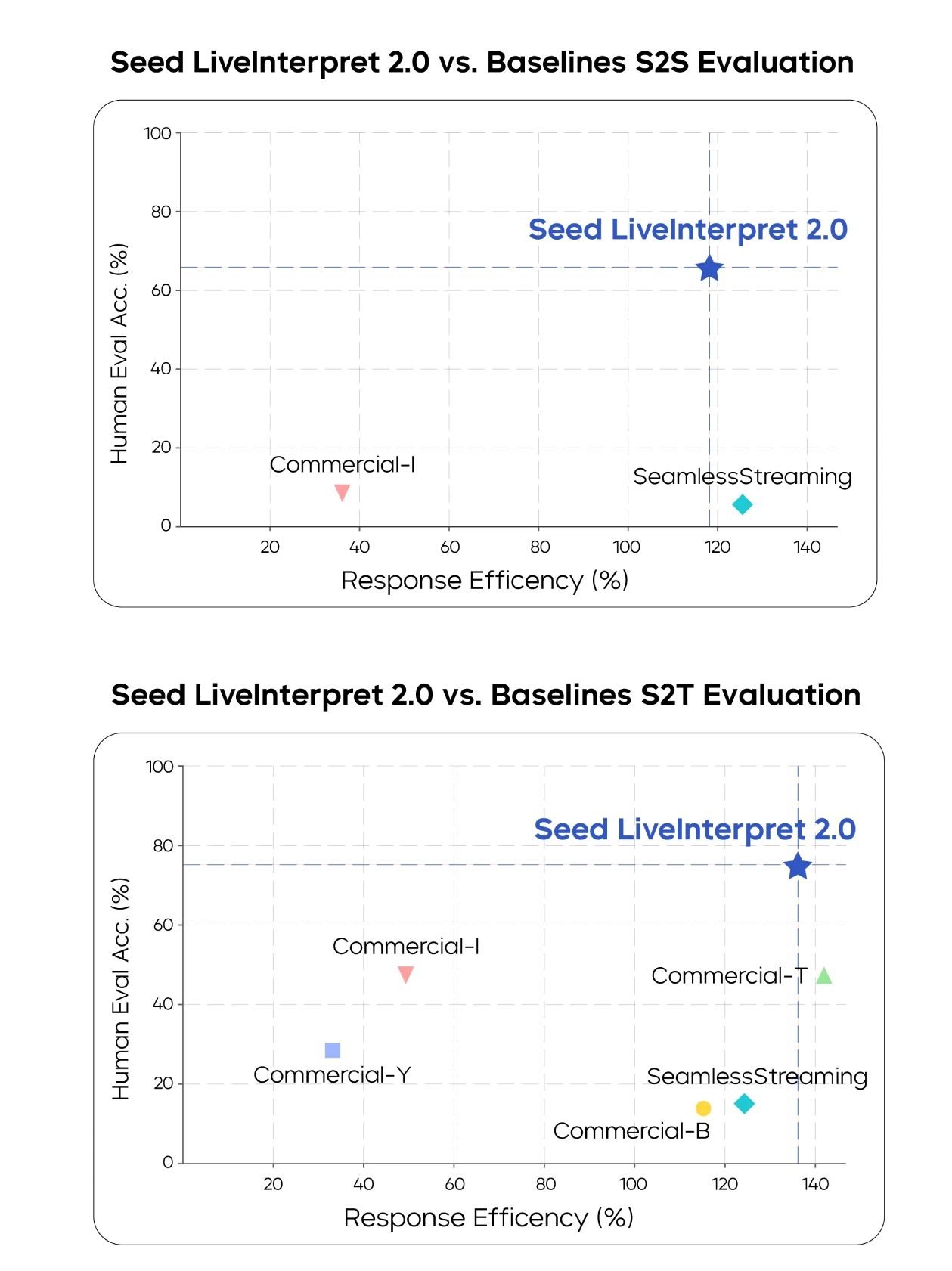
Human-rated quality and responsiveness in speech-to-text and speech-to-speech tasks (Note: Some commercial systems are anonymized by letters)
In terms of latency, Seed LiveInterpret 2.0's average first-word output latency is only 2.21 seconds in speech-to-text scenarios, and the output latency is only 2.53 seconds in speech-to-speech scenarios, achieving a balance between translation quality and latency.
Human-rated translation accuracy and latency in speech-to-text and speech-to-speech tasks in both English-to-Chinese and Chinese-to-English directions
Outperform other translation systems in objective evaluations
ByteDance Seed also evaluated and compared the performance of Seed LiveInterpret 2.0 in both English-to-Chinese and Chinese-to-English directions with other translation systems in terms of translation quality (BLEURT/COMET) and latency (AL/LAAL/FLAL) based on sentence-level SI datasets.
The results reveal that Seed LiveInterpret 2.0 achieves the highest translation quality across both datasets. In the English-to-Chinese direction, speech-to-speech interpretation provided by Seed LiveInterpret 2.0 has the lowest average latency (AL). Seed LiveInterpret 2.0 also shows competitive advantages in the Chinese-to-English direction, showcasing a balance between speed and accuracy.
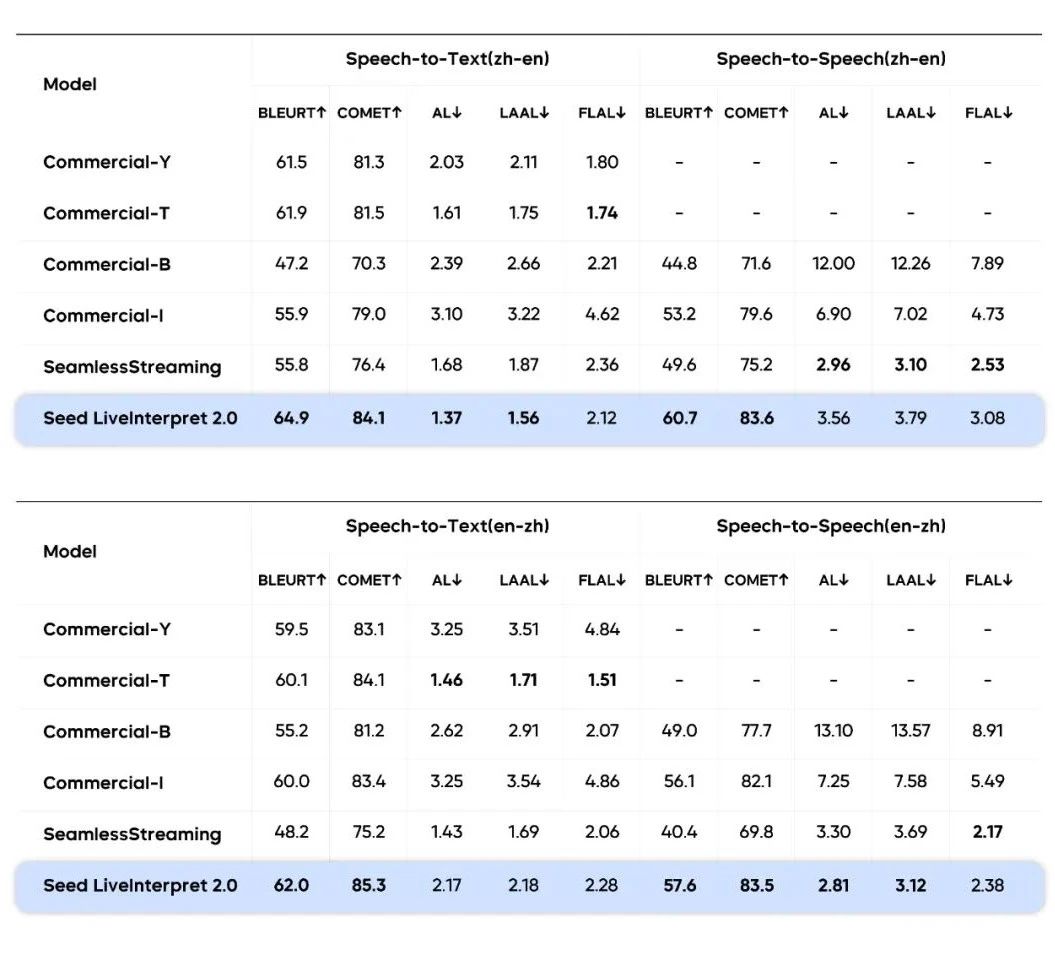
Due to the limited number of high-quality public datasets for simultaneous interpretation, ByteDance Seed used a combination of public datasets and internal datasets for evaluations
In general, Seed LiveInterpret 2.0 can effectively balance translation quality and latency in sentence-level benchmark tests. Unlike traditional SI systems that typically trade off speed for accuracy, this model achieves a strong balance between speed and accuracy. With voice cloning capabilities, it also enables fluent, natural conversations across languages (English and Chinese) for the first time.
Summary and Outlook
In this research, ByteDance Seed further recognized the importance of data in model training. Seed LiveInterpret 2.0 is trained on speech data of hundreds of thousands of hours. Any flaws in the training data might be amplified and cause potential fluency and accuracy issues, such as inconsistent accents, mispronunciations, inaccurate timestamps, and unnatural sentence flow. The strong performance of Seed LiveInterpret 2.0 is grounded in large-scale, high-quality training data.
Despite its competitive advantages, Seed LiveInterpret 2.0's potential has yet to be fully explored. For example, we will expand the model to support a broader range of languages in addition to English-to-Chinese and Chinese-to-English interpretation. We will also explore further improvements in speech stability, expressiveness, and mood replication in terms of voice cloning, as well as translation accuracy in extremely complex scenarios.
ByteDance Seed hopes to gradually unlock the full potential of this model through algorithm optimization, data enhancement, and refined training strategies to boost its adaptivity and performance in complex scenarios.