Seed Research|GR-RL 发布:突破VLA精细操作瓶颈,首次实现真机强化学习穿鞋带
Seed Research|GR-RL 发布:突破VLA精细操作瓶颈,首次实现真机强化学习穿鞋带
Date
2025-12-02
Category
Research
在 Scaling Law 的推动下,具身智能正迎来关键突破,基于海量数据预训练的视觉-语言-动作(VLA)模型已展现出不错的通用泛化能力。
然而,当我们将机器人的应用场景从理想的实验室环境搬进复杂的家庭环境中,面对诸如“穿鞋带”这类看似琐碎,实则要求高精度、高鲁棒、柔性物体操作的任务时,现有的 SOTA 模型往往表现得力不从心。
对人类而言,“穿鞋带”是肌肉记忆;但对机器人而言,这是操作领域最难的灵巧任务之一。
为何拥有“通用大脑”的机器人,却依然做不好这件小事?
字节跳动 Seed 团队研究发现,症结在于主流模仿学习(Imitation Learning)范式存在两大内生缺陷——人类演示数据的“次优性”以及训练与推理之间的“执行错位” 。为了突破这一瓶颈,团队并未依赖难以建模的仿真学习,而是选择探索一条更具挑战性的路径:真机强化学习(Real-world Reinforcement Learning)。
基于此,字节跳动 Seed 团队发布最新研究成果 GR-RL,着力于拓展 VLA 模型在长时程精细灵巧操作方面的能力边界。
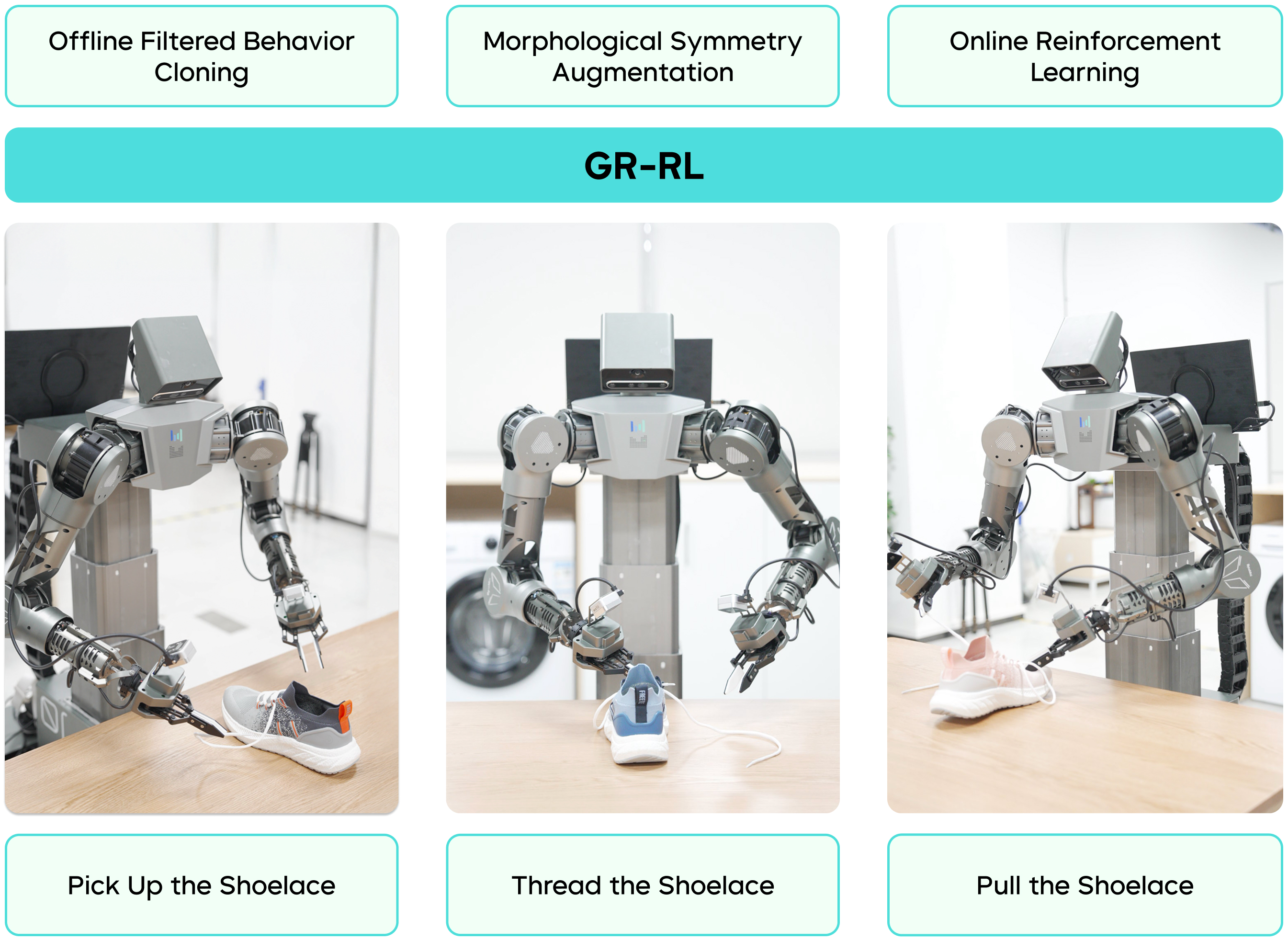
GR-RL 以多阶段强化学习实现穿鞋带
GR-RL 提出了一套从离线数据筛选到在线真机微调的强化学习框架,在业界首次实现“让机器人给整只鞋连续穿鞋带”。相较前作监督学习模型 GR-3,GR-RL 在穿鞋带任务上将成功率从 45.7% 提升至 83.3%,减少了近 70% 的失败情况。
本文将深度解读 GR-RL 如何通过一套从经验中自主学习的多阶段训练方法,攻克柔性物体操作难题。
论文链接:
https://arxiv.org/abs/2512.01801
项目主页:
https://seed.bytedance.com/gr_rl
从通用基座到精细操作
让 VLA 模型走向真正可用
预训练为 VLA 模型提供了通用的感知与决策能力,但这并不意味着它们能直接在特定应用场景中可靠地运行。
-
柔性交互:鞋带形态随受力实时变化,难以预测;
-
极致精度:需达到毫米级控制精度才能准确将鞋带穿过鞋孔;
-
长时程鲁棒性:需在数分钟的连续操作中应对各类突发状况。
团队发现,即便是拥有出色泛化能力的通用机器人模型 GR-3(基于机器人轨迹、人类演示数据及公开图文数据训练),在面对此类任务时也无法直接通过微调获得可用策略。
为何主流的模仿学习在此失效?团队总结了两大核心技术难点:
-
人类演示数据存在“次优片段”:在极高精度的灵巧操作场景下,人类演示者会不自觉地放慢动作、出现犹豫,甚至多次中途失败再修正。如果直接进行模仿学习,模型会记住无效甚至错误的动作,导致策略不够果断和精准。
-
训练与推理存在“执行错位”:为实现平滑的推理与控制,业界通常会对预测的动作块进行后处理,例如时序集成(Temporal Ensembling) 、滚动时域控制(Receding Horizon Control)等。这些优化方法虽保证了动作的平滑性,但也导致模型训练时学习的动作(Predicted Action)与推理时执行的动作(Final Action)出现不对齐。在毫米级精度操作中,这种错误切断了动作与环境反馈的真实因果链条,导致任务失败。
为了攻克 VLA 精细操作的瓶颈,我们需要一套新方法:既能从质量良莠不齐的演示数据中抽取出高质量的行为,又能让模型在环境中尝试和练习,利用自身经验数据使模型真正适应部署的环境。
离线 + 在线多阶段强化
让机器人在试错中持续学习
针对前述提到的数据次优性与执行错误难题,Seed 团队提出适用于长时程、高精度灵巧操作的 GR-RL 模型。
在原有的 VLA 基础上,GR-RL 引入了一个额外的判别器网络(Critic Transformer),用于衡量机器人动作的质量,对动作序列中每个时刻的动作都进行一次打分。具体而言,GR-RL 采用了值分布强化学习,将判别器输出假设为一个离散概率分布,以更鲁棒地捕捉真实环境中存在的噪声。
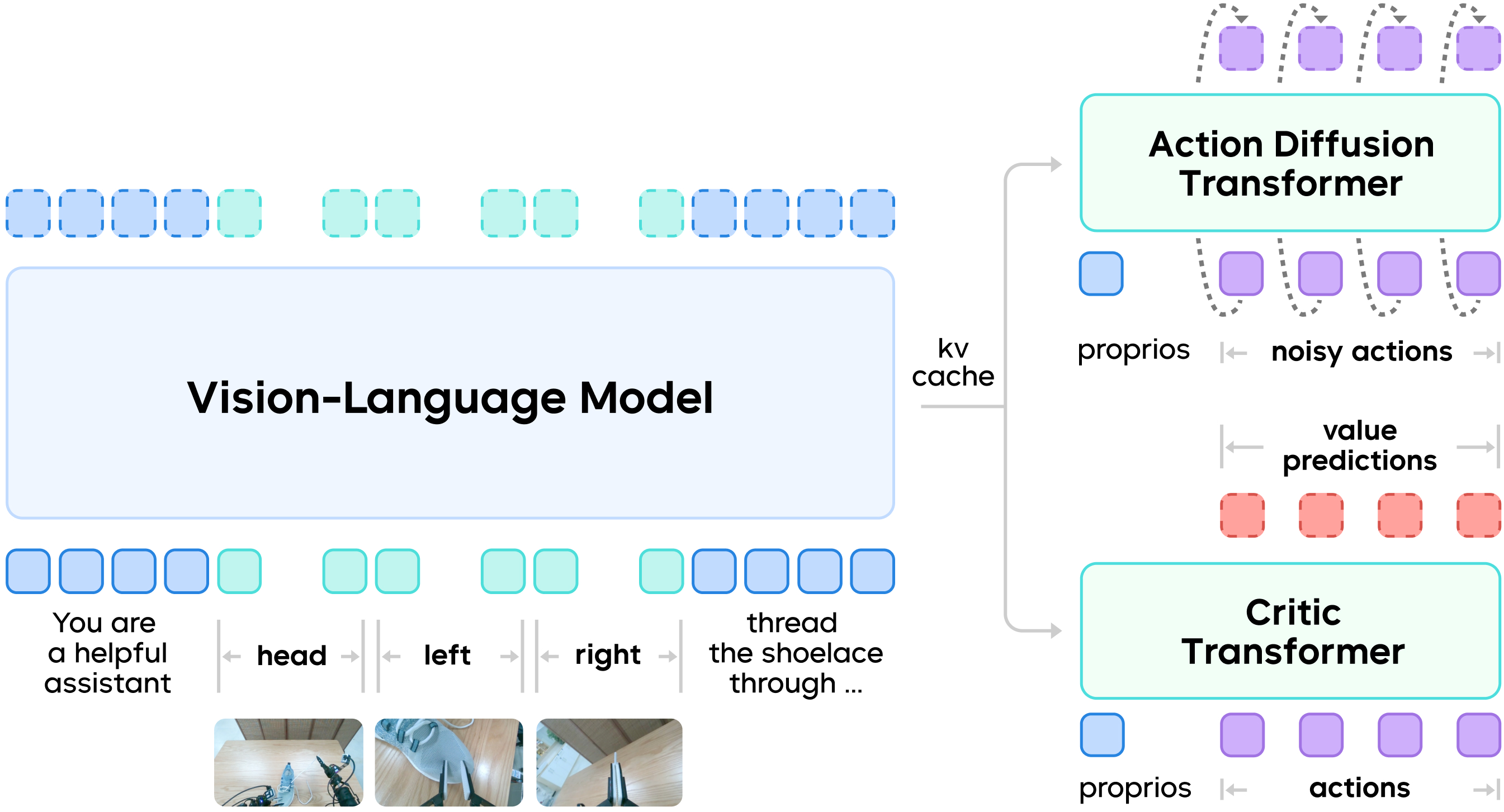
GR-RL 的模型架构
基于此架构,GR-RL 设计了一套从经验中筛选、在实践中进化的多阶段训练框架。该框架包含三个核心环节:离线强化学习、数据增强以及在线强化学习。
离线阶段:基于评估模型对数据“去伪存真”
人类演示数据中混杂着次优片段,GR-RL 的第一步是利用离线强化学习训练上述的判别器网络(即 Critic 价值评估模型),让模型先学会“什么是错误的动作”。
-
构造“反事实”负样本:由于遥操作收集到的轨迹大多是成功的,缺乏负样本,因此团队在每条轨迹中标记开始重试的关键帧,构造出更多失败轨迹:假设一条成功的原始轨迹为
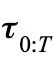 ,团队在其中标记出开始重试的关键帧
,团队在其中标记出开始重试的关键帧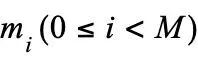 ,除原始成功轨迹外,系统将截取重试前的片段
,除原始成功轨迹外,系统将截取重试前的片段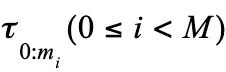 并将其标记为失败轨迹。这种方法在不增加额外采集成本的情况下,大幅扩充了负样本空间。
并将其标记为失败轨迹。这种方法在不增加额外采集成本的情况下,大幅扩充了负样本空间。
-
训练价值判别器:在混合了成功与失败的轨迹集上,团队利用时序差分学习(TD Learning)训练 Critic 价值评估模型。下图展示了评估模型在一条采集轨迹上的预测情况:当操作员失误导致鞋带从孔中滑出时,Critic 预测值(Q-value)骤降;而当操作员第二次尝试并成功穿孔时,预测值会马上恢复并稳定上升。基于此,团队剔除了 Q 值突降的低价值片段,仅保留高质量数据用于监督学习,从而获得了更纯粹的基础策略。
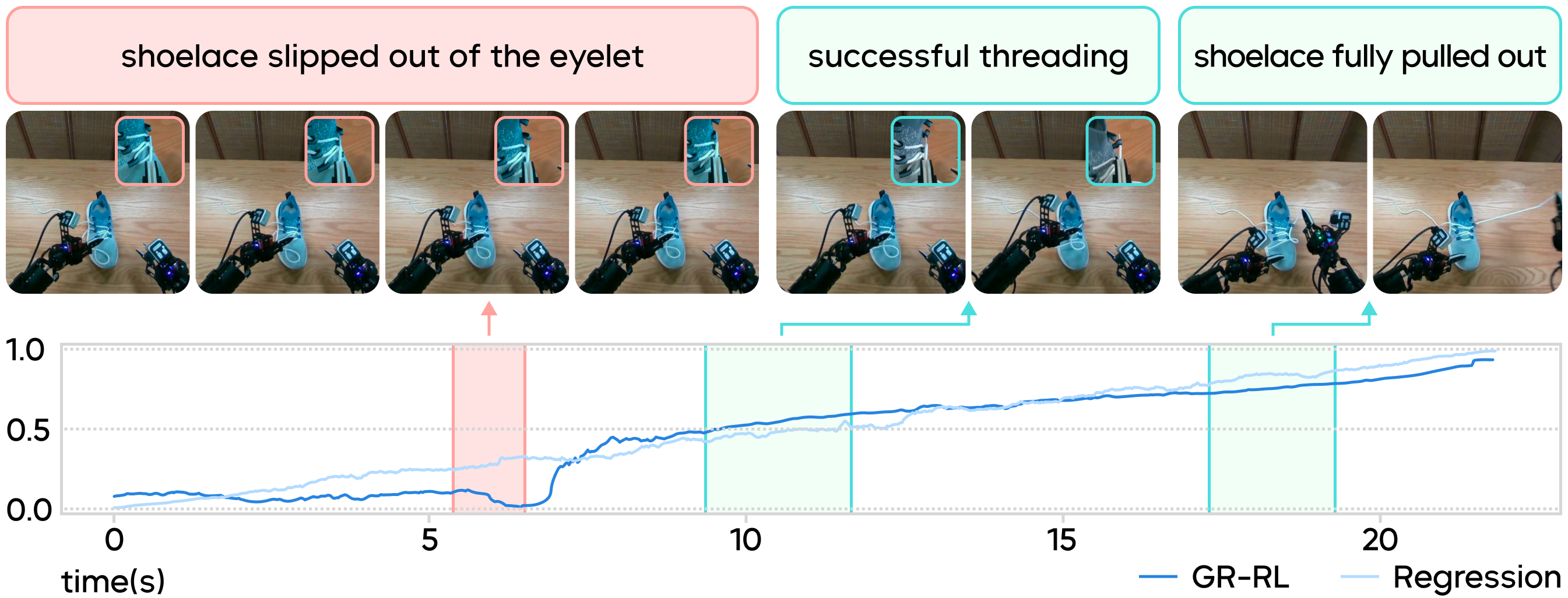
评估模型评判采集轨迹片段的好坏
数据增强:物理“对称”强化泛化理解
团队利用双臂协作任务的镜像对称性,设计了全方位的数据增强策略:对图像、本体状态、动作轨迹和语言指令进行左右镜像翻转。这不仅将数据量翻倍,更提升了模型对空间关系的泛化理解。
在线阶段:导向强化学习进行精细训练
团队发现,模型必须把系统级优化都当成强化学习环境的一部分,通过闭环在线交互进行探索与自我优化,这一点对于精细操作至关重要。团队采用导向强化学习(steering
RL)方法微调 flow
模型的去噪过程,把机器人动作导向评估模型的高回报区域。
-
隐空间探索: 由于完成任务需要毫米级的精度控制,使用在原始动作空间如手腕或关节位置添加随机噪声的常规方法,几乎无法探索出成功轨迹。团队转而在隐空间中进行结构化探索,通过调整流模型策略的输入噪声,让策略预测出不一样的轨迹。 团队在 VLM 骨干网络后引入了一个仅 51.5M 参数的噪声预测器, 它通过调整流模型的输入噪声,引导生成的轨迹向评估模型的高分区域偏移。
-
双缓冲池策略: 为了平衡样本效率与分布偏移,团队维护了两个缓冲池,其中异策略缓冲池存储历史权重生成的交互数据,用于 Critic 预热;同策略缓冲池仅存储最近两个版本模型生成的轨迹。训练时,系统从两个池中 1:1 均匀采样。这种策略既保证了样本利用率,又避免了因模型快速更新导致的分布偏移,确保在线微调稳健高效。
GR-RL 真机实验验证
从成功率翻倍到涌现“纠错”智能
在双臂轮式机器人 ByteMini-v2 上,团队基于“穿鞋带”任务对 GR-RL 进行了全流程验证。该机器人配备了独特的球形腕部关节设计,能够像人类手腕一样灵活转动,在精细灵巧任务中独具优势。
团队设计了严格的实验标准:采用稀疏奖励函数,即只有在鞋带成功穿过指定的孔并放回桌面这一最终状态,模型才能获得 1 分奖励,其他情况下均为 0 分。对模型的观测,包括头部与腕部三个视角的 RGB 图像、机器人本体状态信息以及语言指令。
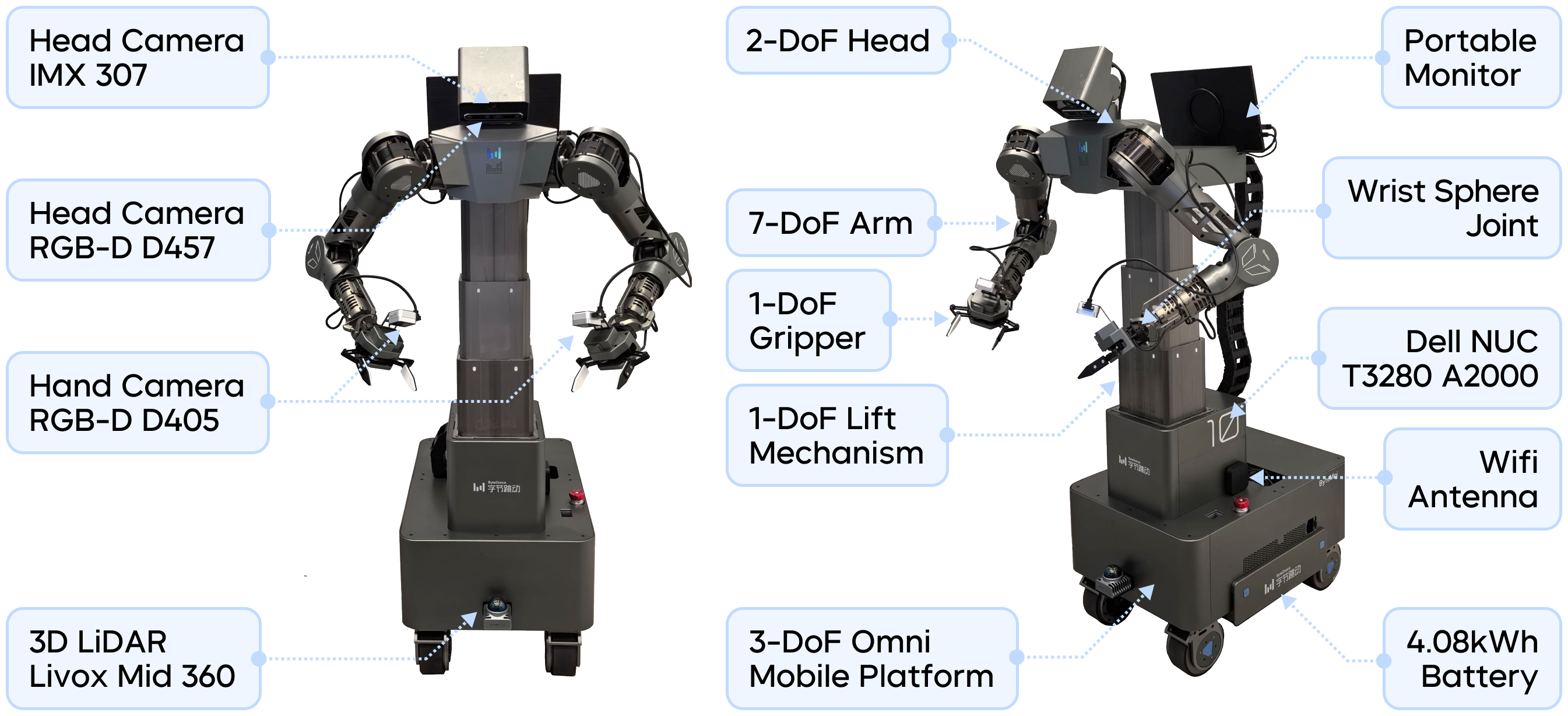
ByteMini-v2 机器人
实验结果表明,纯模仿学习基线(GR-3)的成功率仅为 45.7%,难以应对精细操作。GR-RL 通过多阶段训练框架实现了性能的阶梯式跨越,三个核心组件都对成功率的提升有重要贡献:
-
数据过滤:剔除次优数据后,离线数据过滤将成功率提升至 61.6%;
-
数据增强:引入镜像数据扩充,成功率可提升至 72.7%;
-
在线强化学习:以增强后的离线学习模型作为在线强化学习的起点,经过约 150 条轨迹的真机闭环探索与修正,GR-RL 的成功率最终上升至 83.3%。
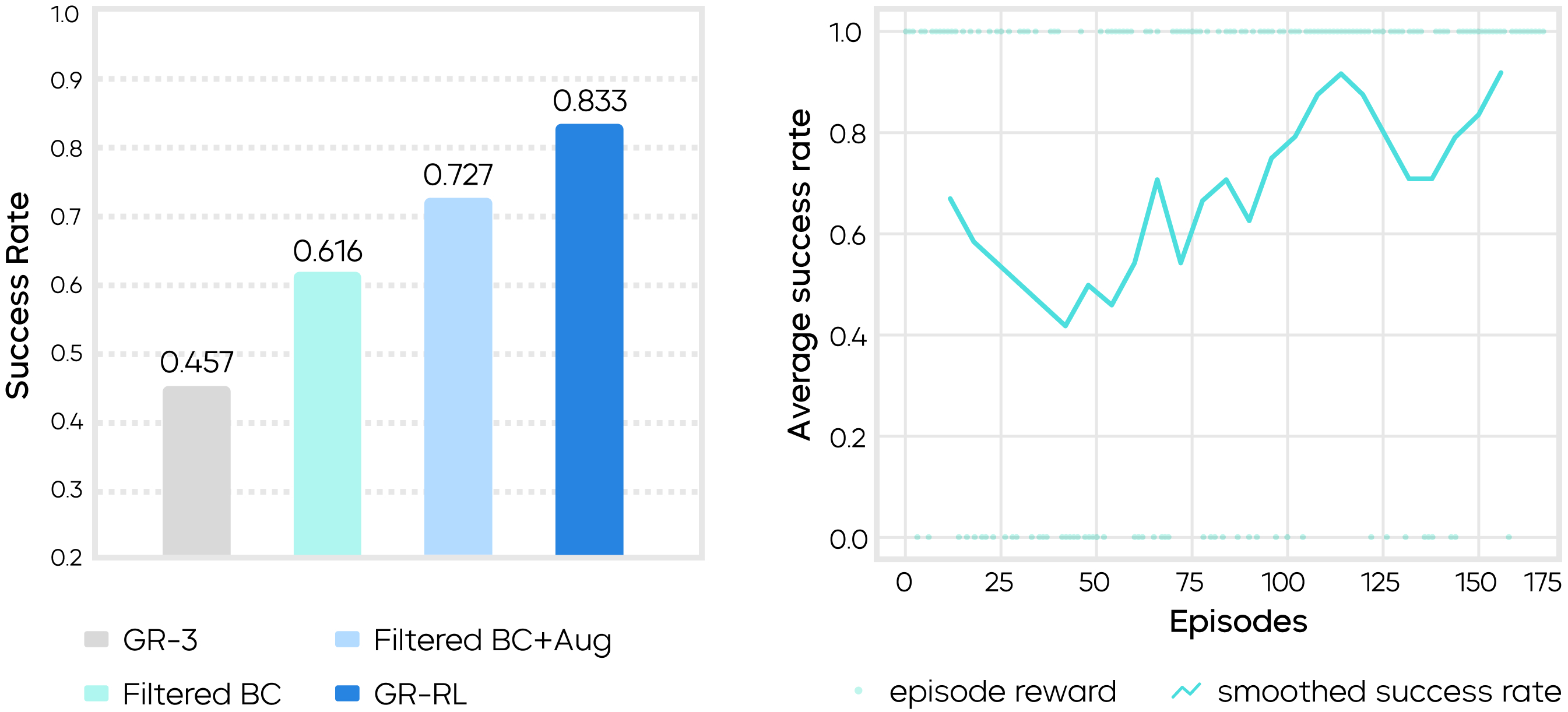
左图:多阶段训练实现阶梯式成功率提升;
右图:在线强化学习的成功率变化曲线
在实验中,团队观察到,引入强化学习后的 GR-RL 涌现出了类似人类的纠错智能。模型应对失误情况时能稳健恢复:例如当鞋带在抓取、穿孔环节意外滑落时,模型并未卡死,而是自发重试;在初始摆放位置比较困难(如鞋带被压住)时,模型能主动将场景调整到自己更熟悉的状态,再接着完成任务。
面对失误情况,GR-RL 能自发重试
摆放位置别扭时,GR-RL 会主动调整
这种“感知-决策-修正”的闭环能力,证明了模型真正理解任务的物理逻辑,而非单纯记忆轨迹。
总结与展望
GR-RL 的工作验证了一件事:对于长时程、极高精度的柔性物体操作,真机强化学习是一条行之有效的技术路径。它让我们在无法依赖仿真的情况下,依然能通过闭环交互突破模仿学习的性能天花板。
但在实际探索中,团队也发现目前的方案仍存在局限性:当前流程的主要问题之一是行为偏移。在稀疏且含噪声的奖励信号下,模型在在线强化学习阶段的行为可能出现不稳定。这可能源于轻量级噪声预测器的容量有限,也可能是在庞大的隐空间动作空间中,信用分配(Credit Assignment)本身具有挑战性。
团队认为,强化学习不应是一个孤立的微调环节。未来的关键可能在于将真机闭环交互中获得的
RL 经验,蒸馏回基础 VLA 模型中。通过这种数据反哺,我们有望构建出兼具高精度操作性能与强大泛化能力的通用策略。