Seed Research | GR-RL Released: A Breakthrough in High-Precision Manipulation for VLA Models, Applying Real-World Reinforcement Learning to Shoe Lacing for the First Time
Embodied AI is approaching a critical turning point, driven by advances in scaling laws. Vision-Language-Action (VLA) models, pre-trained on extensive datasets, have demonstrated impressive generalization capabilities.
However, when robotic applications transition from ideal laboratory conditions to complex home environments, even state-of-the-art (SOTA) models struggle with tasks such as shoe lacing—seemingly trivial yet requiring high-precision, robust manipulation of deformable objects.
For humans, "shoe lacing" is about muscle memory; for robots, however, it remains one of the most challenging dexterous manipulation tasks.
Why do robots with "general-purpose brains" still struggle with this seemingly simple task?
Research from the ByteDance Seed team identifies two fundamental flaws in the dominant imitation learning paradigms: suboptimal human demonstrations and a mismatch between training and inference. To overcome this bottleneck, the team bypassed simulation learning, which is difficult to model, and opted for a more demanding approach: real-world reinforcement learning.
Based on this approach, the ByteDance Seed team has released its latest breakthrough, GR-RL. This framework aims to expand the capability boundaries of VLA models in long-horizon dexterous and precise manipulation.
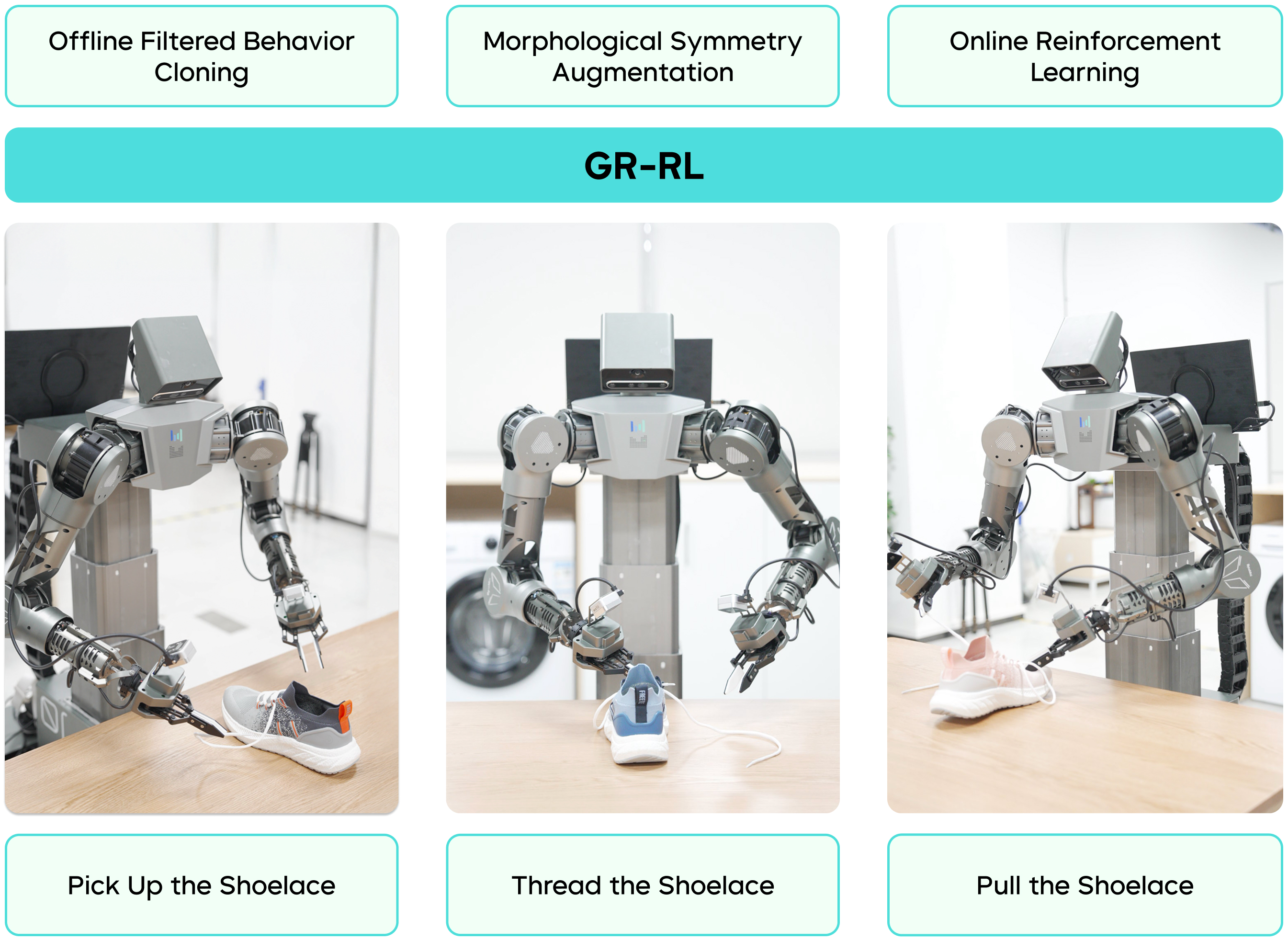
GR-RL's Multi-Stage Reinforcement Learning Approach for Show Lacing
GR-RL introduces a reinforcement learning framework that spans from offline data filtering to online real-world fine-tuning, enabling a robot to continuously lace an entire shoe for the first time in the industry. Compared to the previous supervised learning model GR-3, GR-RL boosts the shoe-lacing success rate from 45.7% to 83.3%, reducing failures by nearly 70%.
This article examines how GR-RL addresses the challenge of deformable object manipulation by using a multi-stage training approach that enables autonomous learning from experience.
Tech Report:
https://arxiv.org/abs/2512.01801
Homepage:
https://seed.bytedance.com/gr_rl
From General-Purpose Foundation Models to High-Precision Manipulation
Bringing VLA Models into Practical Use
While pre-training equips VLA models with general perception and decision-making capabilities, it doesn't guarantee they can perform reliably in specific, real-world applications right out of the box.
To explore this boundary, the team selected "shoe lacing" as a benchmark task, which presents three major challenges in robotic manipulation:
Deformable Object Interaction: The shape of a shoelace changes dynamically with every force applied, making its behavior difficult to predict.
Extreme Precision: The task demands millimeter-level control to reliably thread the lace through designated eyelets.
Long-Horizon Robustness: The system must remain reliable over several minutes of continuous action, despite potential disturbances.
The team found that even a general-purpose model with strong generalization capabilities, such as GR-3 (which is trained on robot trajectories, human demonstrations, and public image-text data), could not yield a usable policy through fine-tuning alone when confronted with such tasks.
Why does mainstream imitation learning fall short in this context? The team pinpoints two core technical challenges:
"Suboptimal Segments" in Human Demonstrations: When performing highly dexterous and precise manipulation tasks, human demonstrators instinctively slow down, hesitate, or even fail and recover multiple times. If imitation learning is applied directly, the model memorizes these inefficient or even incorrect actions, resulting in a policy that is neither decisive nor precise.
Mismatch Between Training and Inference: To ensure smooth inference and control, the industry commonly applies post-processing techniques—such as temporal ensembling or receding horizon control—to predicted action sequences. While these optimizations improve motion smoothness, they also create a mismatch between the actions learned during training (Predicted Actions) and those actually executed during inference (Final Actions). In manipulation tasks requiring millimeter-level precision, this discrepancy severs the critical causal link between actions and environmental feedback, ultimately leading to task failure.
To overcome the bottleneck of high-precision manipulation for VLA models, a new approach is needed, one that can distill high-quality actions from imperfect demonstration data while also enabling the model to practice and learn from its own experience, allowing it to truly adapt to its deployment environment.
Offline and Online Multi-Stage Reinforcement Learning
Enabling Robots to Learn Continuously from trial and Error
To tackle the challenges of "suboptimal human demonstrations" and "mismatch between training and inference," the Seed team developed GR-RL, a model suitable for long-horizon, high-precision dexterous manipulation tasks.
GR-RL extends the base VLA architecture by introducing an additional discriminator network (Critic Transformer) that evaluates the quality of the robot's actions, assigning a score to each action at every timestep in the sequence. Specifically, GR-RL employs value distribution reinforcement learning, which models the critic's output as a discrete probability distribution. This allows the model to more robustly capture the noise present in real-world environments.
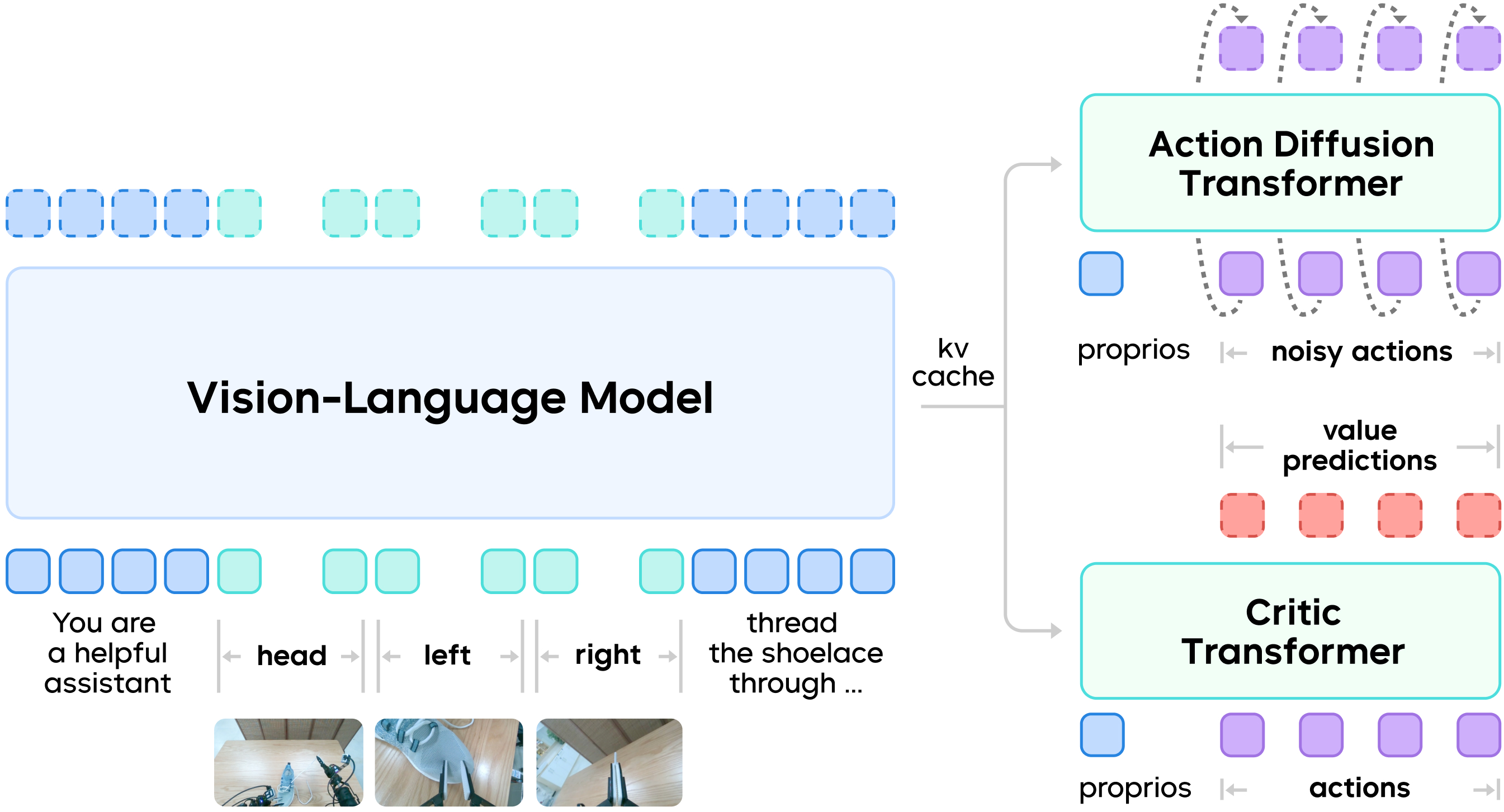
A architecture of GR-R
Building on this architecture, GR-RL implements a multi-stage training framework designed to filter from experience and evolve in practice. This framework consists of three core components: offline reinforcement learning (RL), data augmentation, and online RL.
Offline RL: Using Critic Models to Refine Data
Since human demonstration data often contains suboptimal segments, GR-RL's first step is to use offline RL to train the discriminator network (i.e., the critic value evaluation model). This initially teaches the model to identify "what constitutes a wrong action."
Constructing "Counterfactual" Negative Samples: Trajectories collected from teleoperation are mostly successful, leading to a shortage of negative samples. To address this issue, the team marks the key frames where retries are initiated within each trajectory to construct more failed trajectories. For example, given a successful original trajectory , the team identifies the key frame that marks the start of a retry. Besides the original successful trajectory, the system also extracts the segment before the retry and labels it as a failure. This approach substantially expands the negative sample space without incurring additional collection costs.
Training the Value Discriminator: On a dataset containing both successful and failed trajectories, the team trains the critic value evaluation model using Temporal Difference (TD) Learning. The figure below shows the critic model's predictions on a collected trajectory: When an operator's mistake causes the shoelace to slip out of the eyelet, the critic model's predicted value (Q-value) plummets. Conversely, when the operator's second attempt is successful, the predicted value immediately bounces back and rises steadily. Based on this signal, low-value segments with sharply declining Q-values are filtered out. Only high-quality data is retained for supervised learning, resulting in a refined base policy.
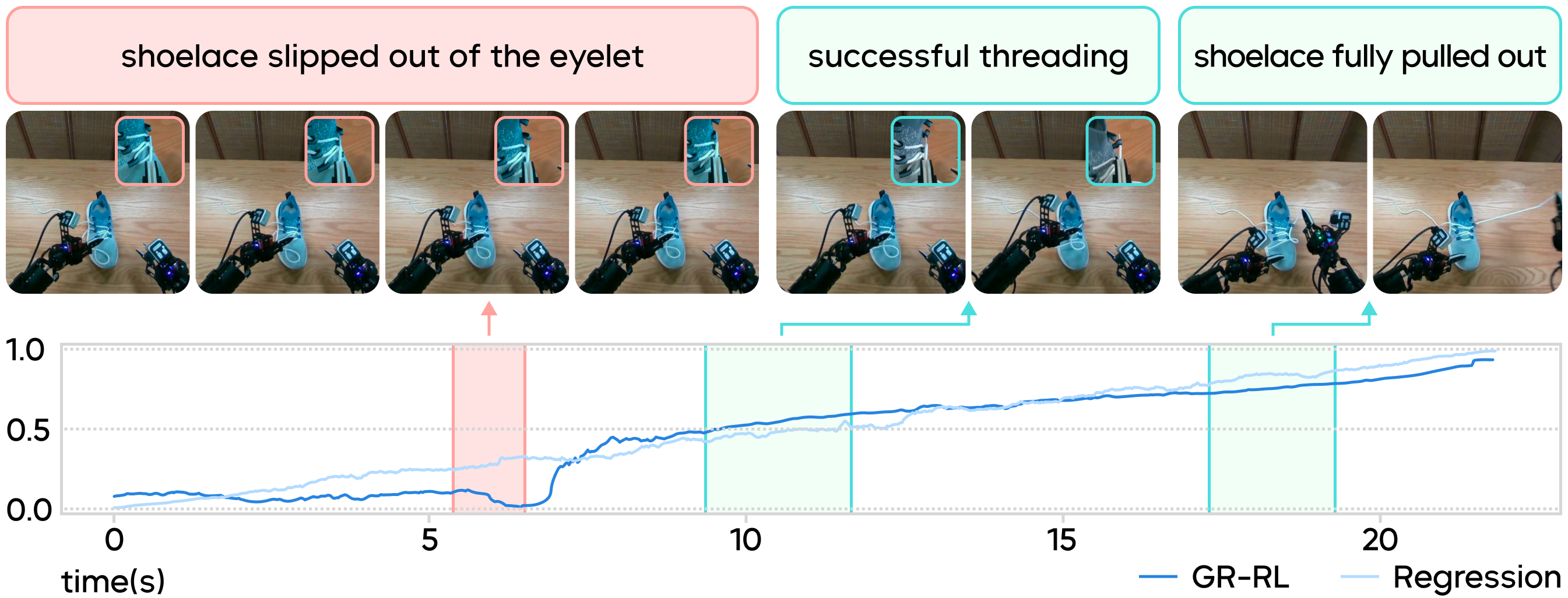
How the Critic Model Assesses the Quality of Segments in a Collected Trajectory
Data Augmentation: Using Physical "Symmetry" to Reinforce Generalized Understanding
The team designed a comprehensive data augmentation strategy by exploiting the mirror symmetry inherent in dual-arm collaborative tasks. This involves performing left-right mirror flips on images, proprioceptive states, action trajectories, and language instructions. This approach not only doubles the volume of data but also significantly enhances the model's generalized understanding of spatial relationships.
Online RL: Using Steering RL for Fine-Grained Training
The team recognized that the model must incorporate system-level optimizations into the reinforcement learning environment, enabling exploration and self-optimization through closed-loop online interaction. This is crucial for high-precision manipulation. To achieve this, the team employed a steering reinforcement learning (steering RL) method to fine-tune the denoising process of the flow model, directing the robot's actions toward high-reward regions identified by the critic model.
- Latent Space Exploration: The task's requirements for millimeter-level precision control make it nearly impossible to find successful trajectories using the conventional exploration method that adds random noise to the original action space (e.g., to wrist poses or joint positions). Therefore, the team shifted to structured exploration in a latent space by tuning the input noise of the flow model policy, enabling the policy to predict different trajectories. Specifically, the team introduced a lightweight noise predictor with only 51.5M parameters after the VLM backbone. This predictor adjusts the flow model's input noise to steer the generated trajectories toward the high-score regions defined by the critic model.
Dual-Buffer Strategy: To strike a balance between sample efficiency and distribution shift, the team maintains two replay buffers: an off-policy buffer storing interaction data generated from historical checkpoints for warming up the critic model, and an on-policy buffer storing only trajectories generated from the most recent two checkpoints. During training, the system samples uniformly from both buffers at a 1:1 ratio. This strategy ensures efficient sample utilization while mitigating distribution shifts caused by rapid model updates, guaranteeing robust and efficient online fine-tuning.
Real-World Experimental Validation of GR-RL
From Doubled Success Rate to Emergent "Error Correction" Intelligence
On the dual-armed wheeled robot ByteMini-v2, the team conducted a full-process validation of GR-RL using the "shoe-lacing" task. This robot is equipped with a unique spherical wrist joint design, allowing flexible rotation similar to a human wrist, giving it distinct advantages in highly dexterous and precise tasks.
The team established rigorous experimental standards: A sparse reward function was employed, meaning the model only receives a reward of 1 upon reaching the final state where the shoelace is successfully threaded through the designated eyelet and placed back on the table, and receives 0 reward in all other scenarios. The model's observations are composed of RGB images from three views (including head and wrists), proprioception states, and language instructions.
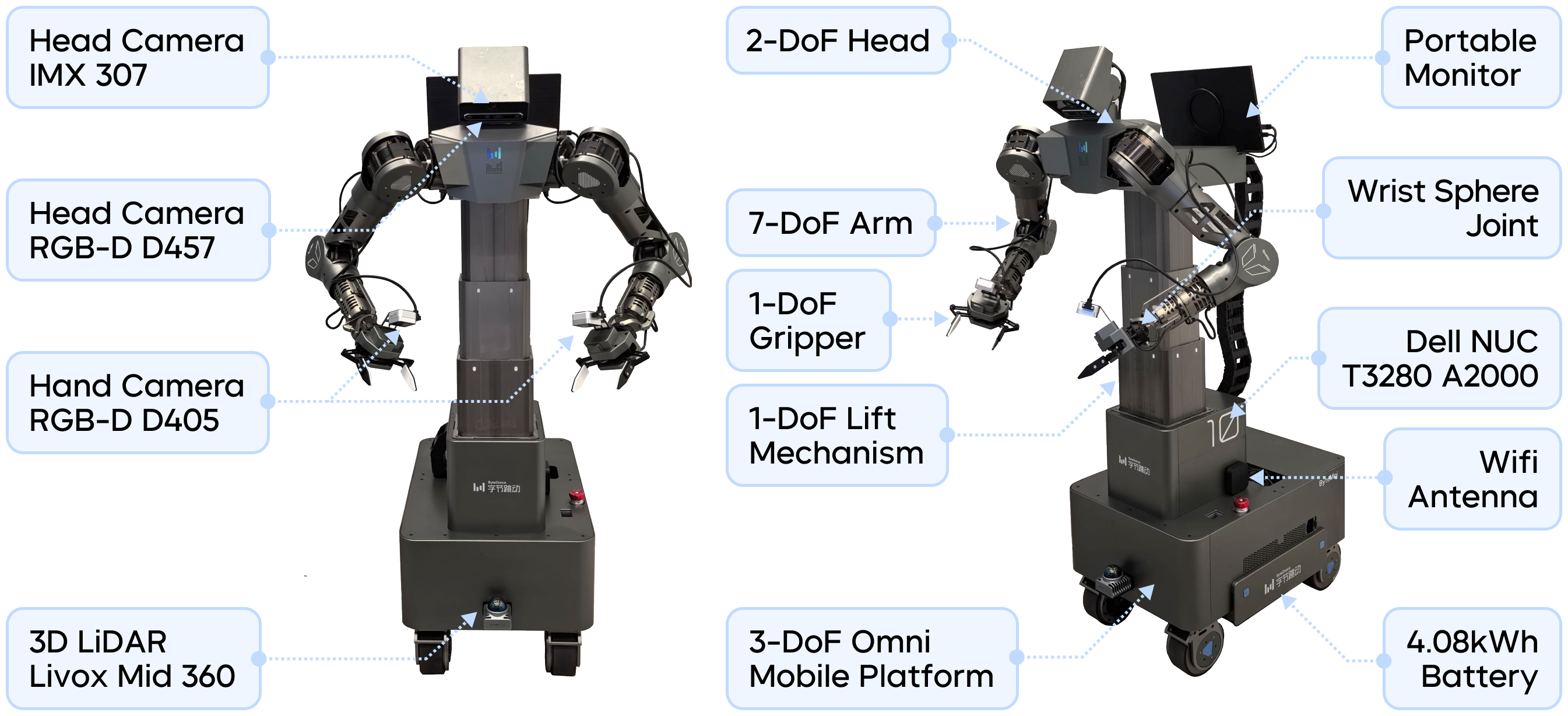
ByteMini-v2 Robot
The experimental results indicate that the baseline model using pure imitation learning (GR-3) achieved a success rate of only 45.7%, struggling with high-precision manipulation tasks. In contrast, GR-RL delivered a significant, step-wise performance leap thanks to its multi-stage training framework, with each of its three core components contributing substantially to the increased success rate:
Data Filtering: After removing suboptimal data, offline data filtering raised the success rate to 61.6%.
Data Augmentation: Augmenting the dataset with mirrored data further increased the success rate to 72.7%.
Online Reinforcement Learning: Starting with the augmented offline learning model, GR-RL underwent approximately 150 episodes of real-world closed-loop exploration and refinement, ultimately boosting the final success rate to 83.3%.
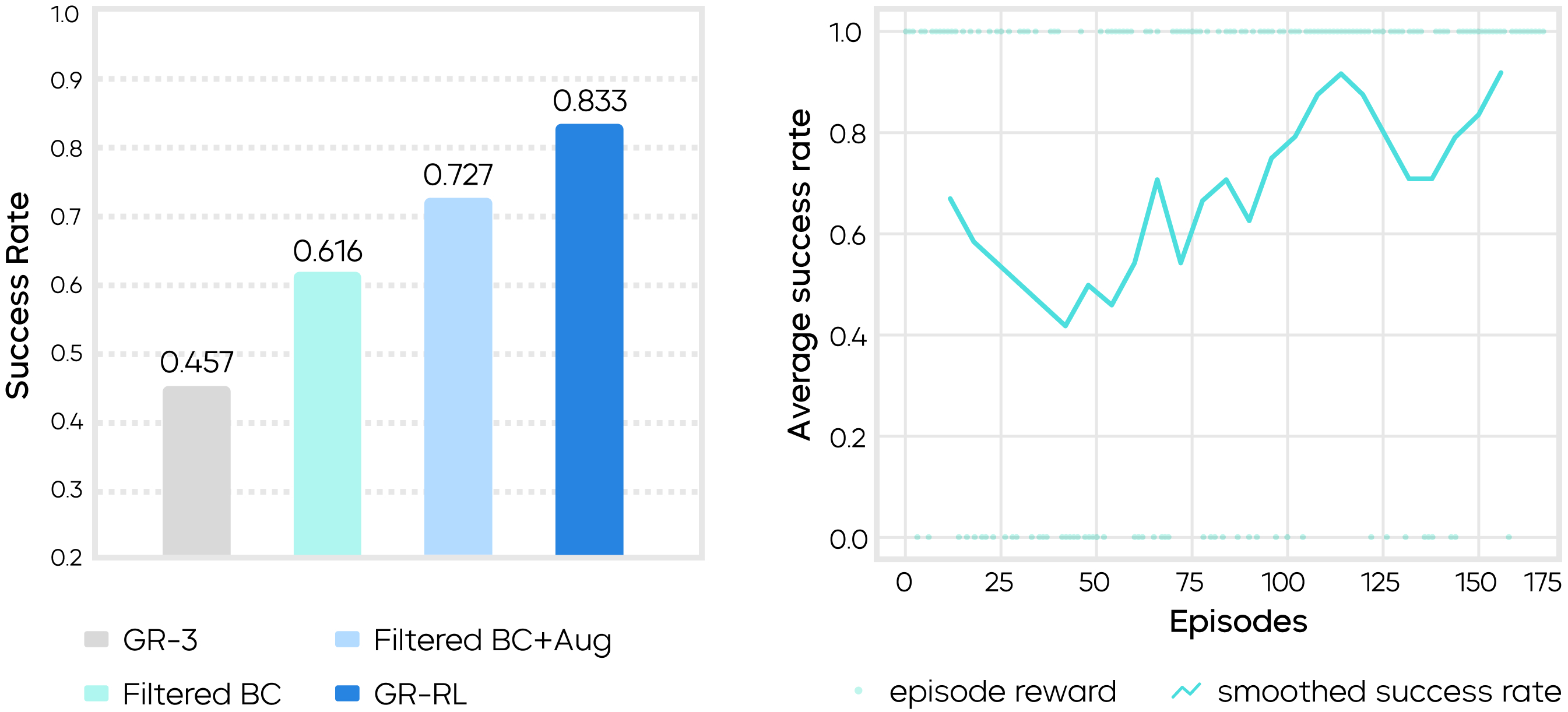
Left: Step-Wise Improvement in Success Rate via Multi-Stage Training
Right: Success Rate Curve for Online Reinforcement Learning
In the experiments, the team observed that GR-RL, after incorporating reinforcement learning, exhibited human-like error-correction intelligence. The model demonstrated robust recovery when dealing with unexpected failures. For example, when the shoelace accidentally slipped during grasping or threading, the model did not get stuck but spontaneously retried; when the shoelace started in a challenging position (e.g., trapped under the shoe), the model actively adjusted the scene to a more manageable state before proceeding with the task.
GR-RL can automatically retry in the event of a failure.
GR-RL can actively adjust the scene when faced with awkward placement.
This closed-loop capability of "perception-decision-correction" demonstrates that the model genuinely understands the physical logic of the task, rather than merely memorizing trajectories.
Summary and Outlook
The GR-RL project validates a key insight: Real‑world reinforcement learning represents a viable technical pathway for long‑horizon, high‑precision manipulation of deformable objects. It demonstrates that, even without simulation, closed‑loop interaction can surpass the performance limits of imitation learning.
However, during practical exploration, the team also identified limitations in the current approach: One of the major issues in the current pipeline is behavioral drift. Under sparse and noisy reward signals, the model's behavior may become unstable during online RL. This instability could stem from the limited capacity of the lightweight noise predictor, or from the inherent challenge of credit assignment within the large latent action space.
The team believes that reinforcement learning should extend beyond an isolated fine‑tuning step. Future progress may hinge on distilling RL experience—gained from real‑world closed‑loop interaction—back into VLA foundation models. Such a data feedback loop could ultimately yield a general‑purpose policy that combines high‑precision manipulation with robust generalization.