Tech Report of Seedance 1.0 Is Now Publicly Available
Tech Report of Seedance 1.0 Is Now Publicly Available
Date
2025-06-11
Category
Models
The ByteDance Seed team has officially released Seedance 1.0, its foundation model for video generation
Seedance 1.0 can generate high-quality 1080p videos from text and image inputs, with seamless multi-shot transitions, excellent motion stability, and high visual naturalness.
Compared to other video generation models released by ByteDance Seed, Seedance 1.0 excels in the following aspects:
• Native multi-shot storytelling: generates a 10-second video with 2-3 shot transitions and allows for seamless changes between wide, medium, and close-up shots for more coherent storytelling.
Prompt: A girl is playing the piano, with multi-shot transitions and a cinematic look (I2V)
Prompt: Multiple shots. A detective enters a dimly lit room. He inspects the clues on the table and picks up an item. The shot shifts to capture him thinking.
- Enhanced motion generation: ensures more natural motions for scenes and subjects, more stable structures, better control over details, and less distortion in outputs.
Prompt: A skier is gliding down the slope, kicking up a large cloud of snow as he turns, and gradually speeding up along the hillside, with the camera moving smoothly.
Prompt: A model in a black backless dress elegantly walks on a striking red runway. Light brings out the flowing texture of the fabric. The audience watches the model intently, and the lights gradually fade away.
- Multi-style generation with high aesthetic quality: accurately responds to instructions to generate high-quality videos in a wide range of styles, such as realism, animation, film, and advertising, with more realistic visuals and stronger aesthetic appeal.
• Fast inference at lower costs: creates videos in a shorter time by using a carefully designed model architecture and effective inference acceleration techniques. It can generate a 5-second video at 1080p resolution in only 41.4 seconds (NVIDIA-L20).
According to the results from Artificial Analysis, a third-party benchmarking platform, Seedance 1.0 ranks first on both the text-to-video (T2V) and image-to-video (I2V) leaderboards.
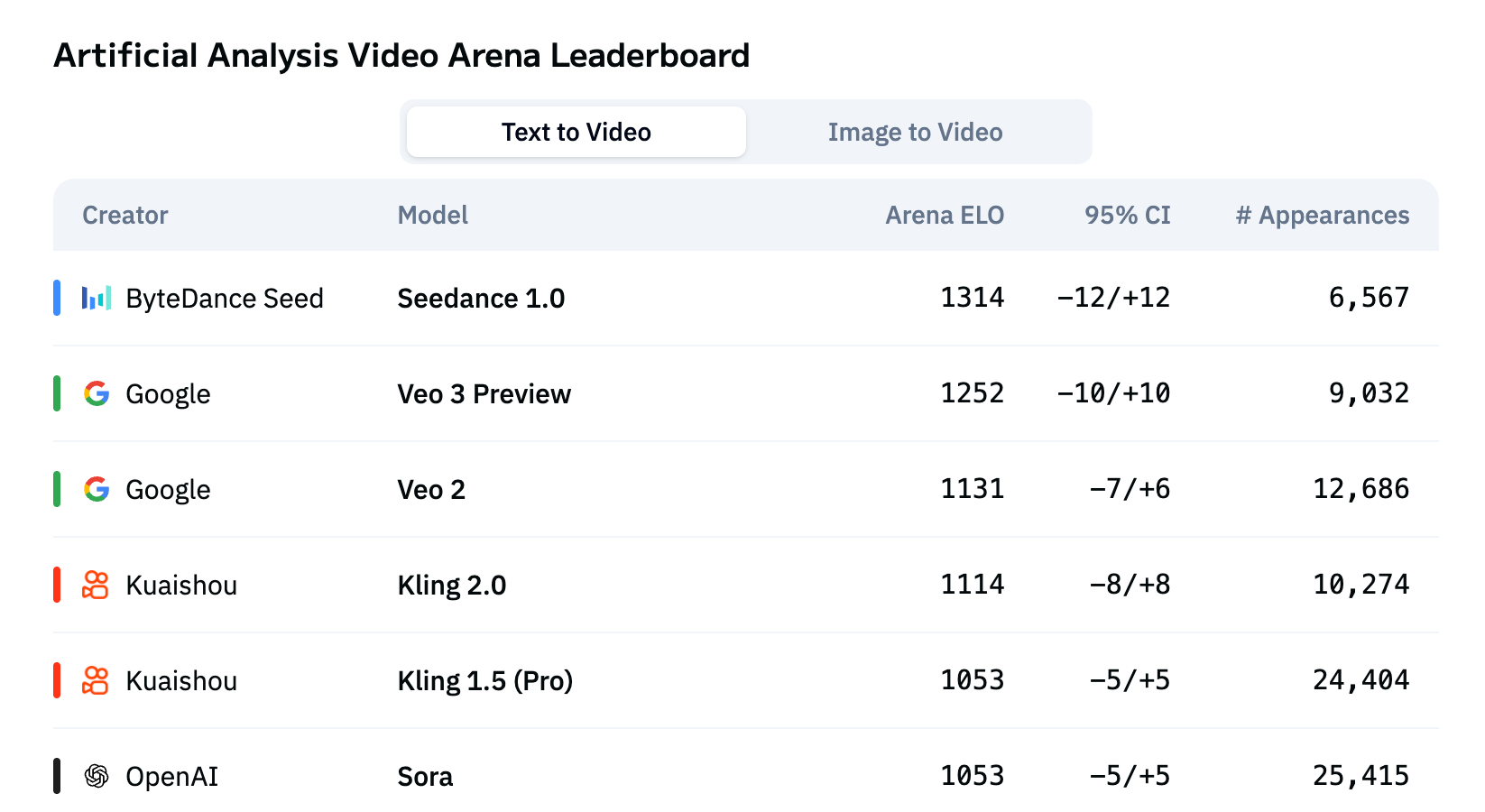
Artificial Analysis video arena leaderboard (T2V)
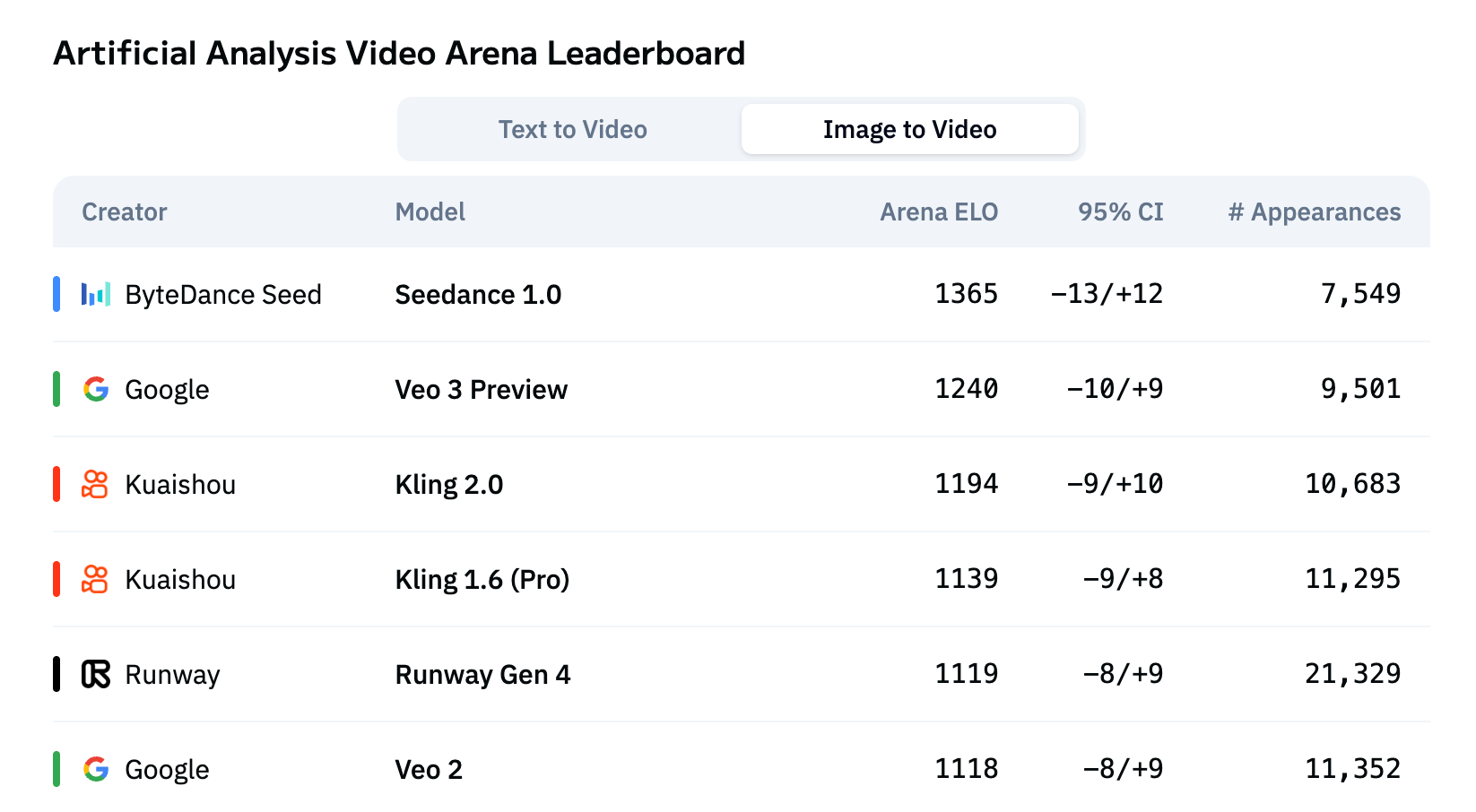
Artificial Analysis video arena leaderboard (I2V)
(Note: For consistent and fair evaluation, Artificial Analysis muted the audio from the videos generated by Veo 3 Preview before evaluating them.)
We developed a comprehensive benchmark for video generation, which comprises 300 prompts each for T2V and I2V, for manually evaluating the performance of Seedance 1.0. We then collaborated with film directors and industry experts to co-develop evaluation criteria across dimensions such as subject generation, motion stability, shot transitions and expressions, aesthetic quality, and instruction following.
As shown in the following figures, Seedance 1.0 demonstrates strong performance across these dimensions, particularly in key capabilities such as generating motions and following instructions, ranking among the top in the industry. Seedance 1.0 also stands out in terms of inference speed and user satisfaction.
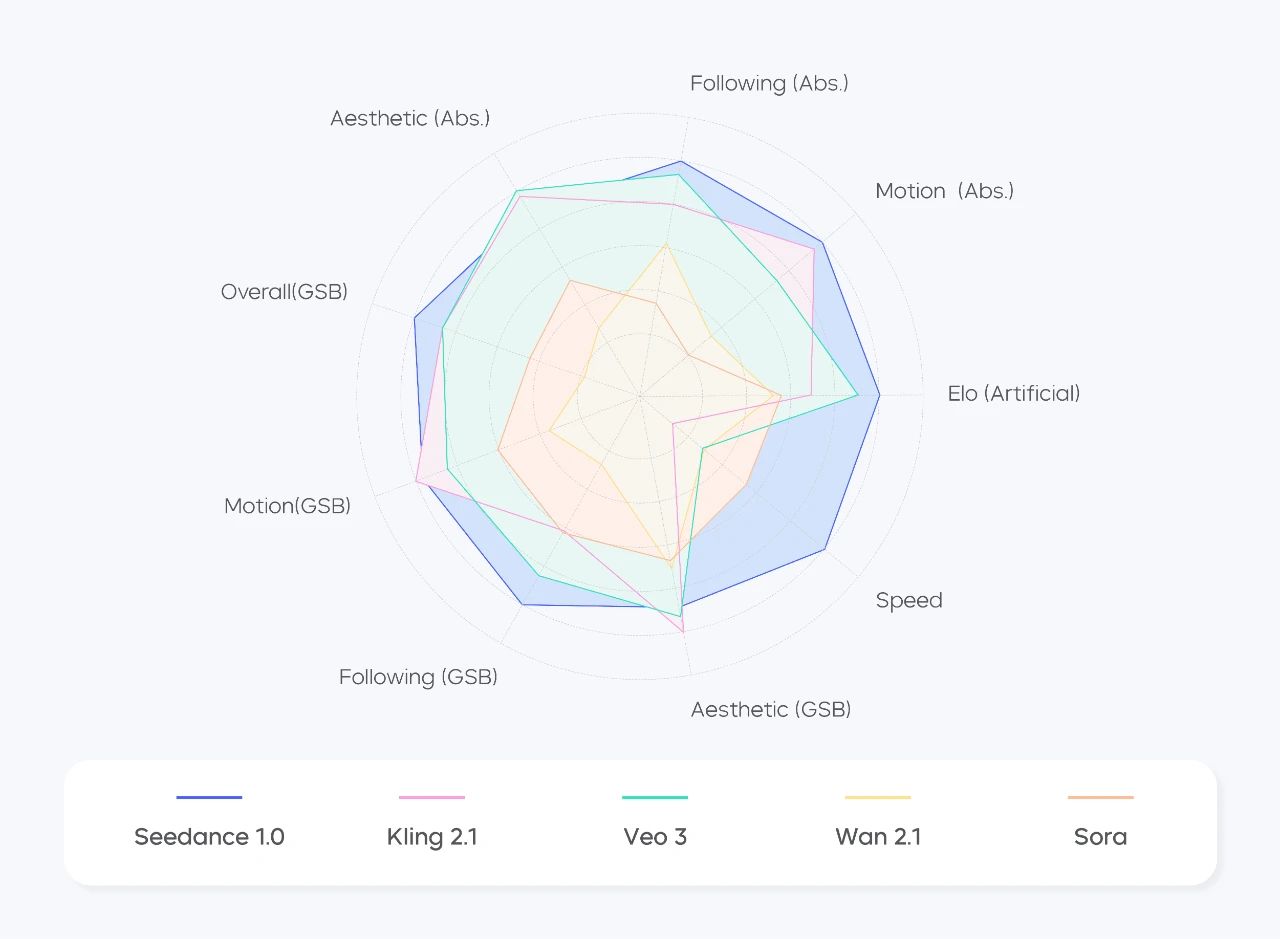
Text-to-video evaluation
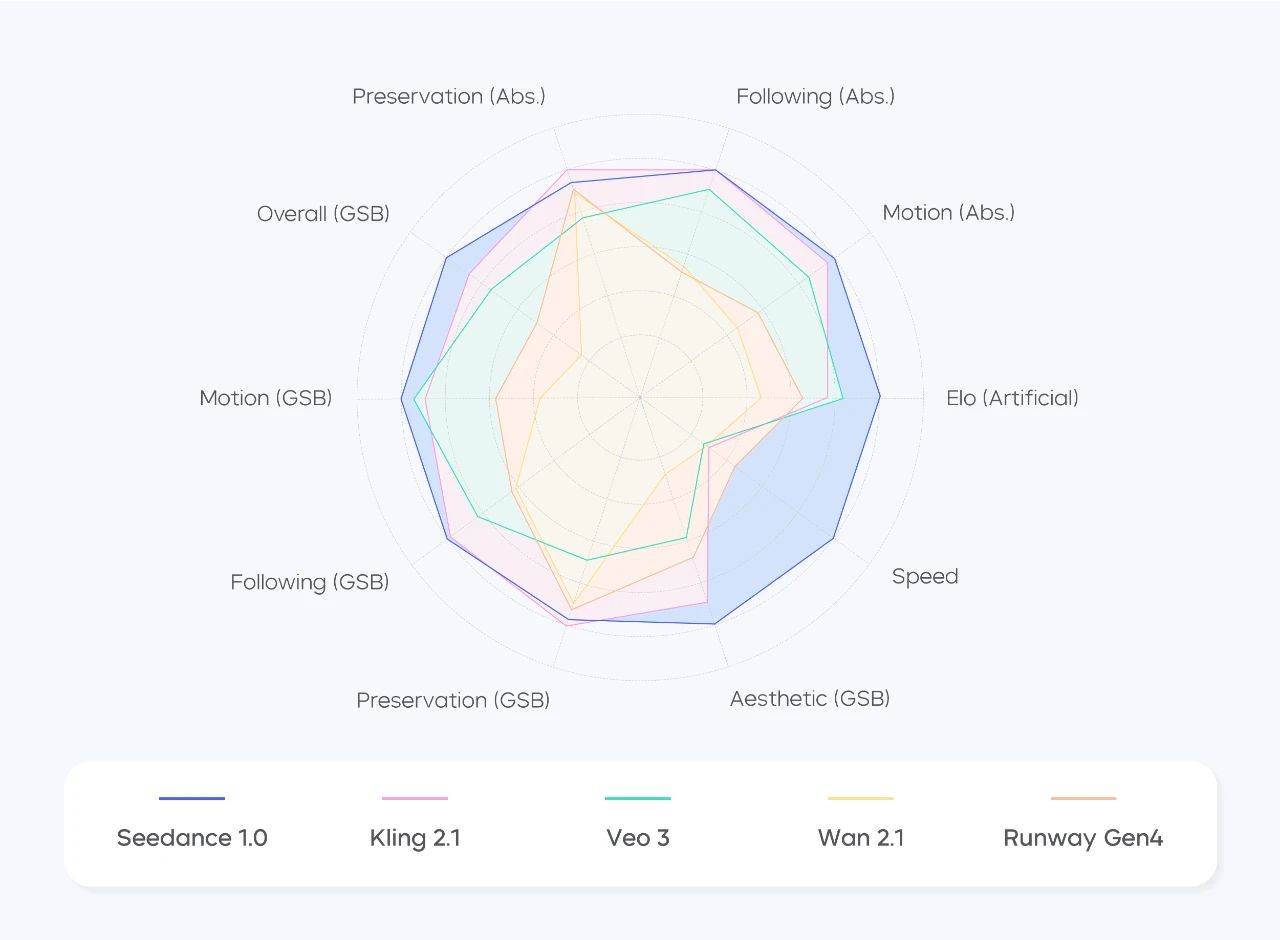
Image-to-video evaluation
The tech report of Seedance 1.0 is now publicly available. Feel free to try it out and share your feedback.
Model Homepage (where you can view the full tech report): https://seed.bytedance.com/seedance
Introduce a Precise Caption Model to Enhance Data Diversity and Usability
During the R&D of Seedance 1.0, we surveyed filmmakers to collect real-world needs. This led us to focus not only on common metrics—such as instruction following, motion stability, and visual quality—but also on more demanding challenges like unified multi-task generation and ultra-fast HD video generation.
In terms of data curation, we collected video data from diverse sources and generated video captions. Through multi-stage filtering and balancing, we improved the model's ability to understand subjects, actions, scenes, and styles in videos, as well as prompts, helping it generate more detailed and accurate outputs.
Data processing in Seedance 1.0
- Collect data from diverse data sources and perform precise data pre-processing to improve the usability and diversity of training data
We curated a large-scale video dataset spanning diverse types, styles, and sources, which covers critical dimensions such as clip durations, resolutions, subject matters, scene types, artistic styles, and camera movements. This allows the model to effectively extract subject contours and motion features across varying scenes, styles, subject matters, camera shots, and sizes.
To improve data usability, Seedance 1.0 employs automated shot boundary detection techniques to precisely segment videos into shorter clips by analyzing inter-frame visual dissimilarities.
In addition, we adopted a hybrid approach of heuristic rule-based systems and specialized object detection models. Frames are adaptively cropped to maximize the retention of the primary visual content, and data is precisely filtered to increase the data scale and diversity.
- Introduce a precise caption model to boost the model's ability in understanding dynamic and static information
Precise and detailed video captions enable a model to accurately respond to user prompts and generate complex content. However, in real-world training, access to this type of data is often limited. Therefore, during R&D, we trained a precise caption model to generate video captions as the training data of Seedance 1.0.
This model adopts a dense caption style integrating dynamic and static features. For dynamic features, we meticulously describe actions and camera movements of a video clip, highlighting changing elements. For static features, we elaborate on the characteristics of core characters or scenes in video frames.
Employ a Unified, Efficient Pre-Training Framework to Support Multi-Shot Transitions and Multimodal Inputs
Through efficient architecture design, interleaved multimodal positional encoding, and multi-task unified modeling, Seedance 1.0 natively supports multi-shot video generation and can handle both T2V and I2V tasks in a single model.
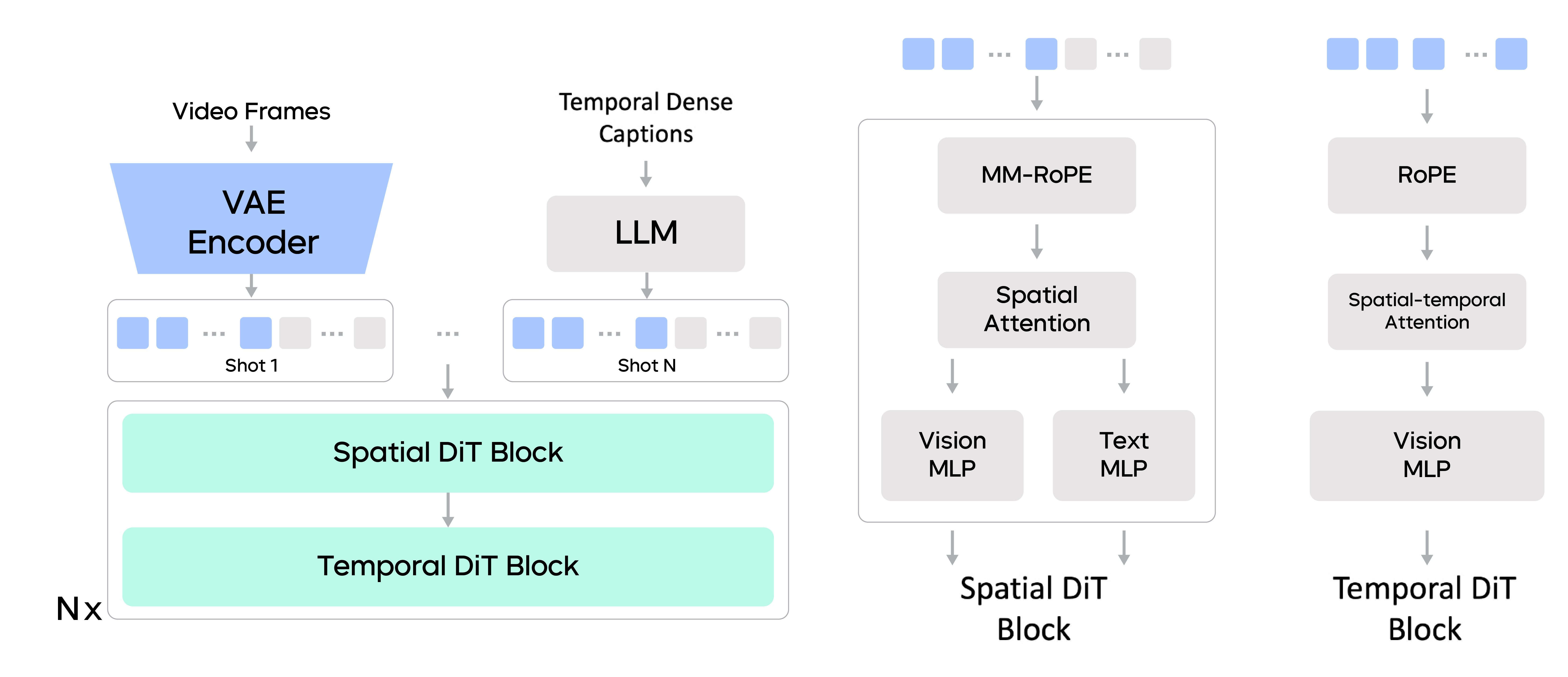
Pre-training framework of Seedance 1.0
Compared to other models unveiled in the industry, Seedance 1.0 has optimized its architecture and training strategy in the following aspects:
- Decoupled spatial and temporal layers
Considering both training and inference efficiency, we built the diffusion transformer with decoupled spatial and temporal layers.
The spatial layers perform attention aggregation within each frame, while the temporal layers focus on attention computation across frames. We perform window partitioning within each frame in the temporal layers, allowing for a global receptive field across the temporal dimension. In addition, textual tokens only participate in cross-modality interaction in spatial layers. These improvements collectively boost computational efficiency, laying a solid foundation for the R&D of an efficient model.
- Multi-shot MM-RoPE
In addition to using 3D RoPE encoding for visual tokens, a commonly used strategy in the industry, we added 3D Multi-modal RoPE (MM-RoPE) in the concatenated sequences by adding extra 1D positional encoding for textual tokens.
The MM-RoPE also supports interleaved sequences of visual tokens and textual tokens, and can be extended to training video with multiple shots, where shots are organized in the temporal order of actions and each shot has its own detailed caption offered by the precise caption model. This training approach enhances Seedance 1.0's ability to generate multi-shot videos and understand multimodal information.
- Unified Task Formulation
To achieve I2V generation, we used binary masks to indicate which frames are instructions to follow. During the training process, we mixed these tasks and adjusted the proportion by controlling the conditional inputs.
With this formulation, we can unify different generation tasks such as text-to-image (T2I), T2V, and I2V for joint learning. This allows you to deploy just one model to handle different types of tasks, making it easier to use the model.
## Post-Training: Build a Composite Reward System to Improve Visual Vividness, Stability, and Aesthetic Quality
During post-training, we used high-quality, fine-tuned datasets, dimension-specific reward models, and feedback-driven learning algorithms to boost Seedance 1.0's performance in terms of motion vividness, structural stability, and visual quality.
We also employed a video-tailored reinforcement learning from human feedback (RLHF) algorithm. This allows us to considerably improve Seedance 1.0's performance on both T2V and I2V.
- Supervised fine-tuning based on high-quality data
During the supervised fine-tuning (SFT) stage, we trained Seedance 1.0 on a carefully curated set of high-quality video-text pairs. These data, with high-quality, precise video captions, span diverse styles and scenes, allowing the model to generate videos with improved aesthetics and more consistent motion dynamics.
During fine-tuning, we trained separate models on curated subsets and merged these models into a single model that integrates their respective strengths.
- Composite reward system comprising three specialized reward models
Considering that image-text alignment, structural stability, motion generation, and aesthetic quality are key metrics for evaluating video generation models, we designed a composite reward system comprising these reward models:
Foundational reward model:This model focuses on enhancing fundamental model capabilities, such as image-text alignment and structural stability. It employs a vision-language model (VLM) as its architecture.
Motion reward model:This model helps to mitigate video artifacts while enhancing motion amplitude, vividness, and stability.
Aesthetic reward model:This model is designed from image-space input, with the data source modified to use keyframes from videos. It enables the model to generate videos with film-level aesthetics.
- Video-tailored feedback-driven learning
During RLHF training, we adopted an optimization strategy that directly maximizes the composite rewards from multiple reward models (RMs). Comparative experiments against DPO/PPO/GRPO demonstrate that our reward maximization approach is the most efficient and effective approach, comprehensively improving text-video alignment, motion quality, and aesthetics.
Notably, our approach applies RLHF directly to the accelerated refiner model, effectively enhancing motion quality and visual fidelity in low-NFE (number of function evaluations) scenarios while maintaining computational efficiency.
As shown in the following figures, when the number of iterations increases, video-tailored RLHF optimization strategies, coupled with dimension-specific reward models, enable comprehensive improvements of the model's capabilities across diverse dimensions.
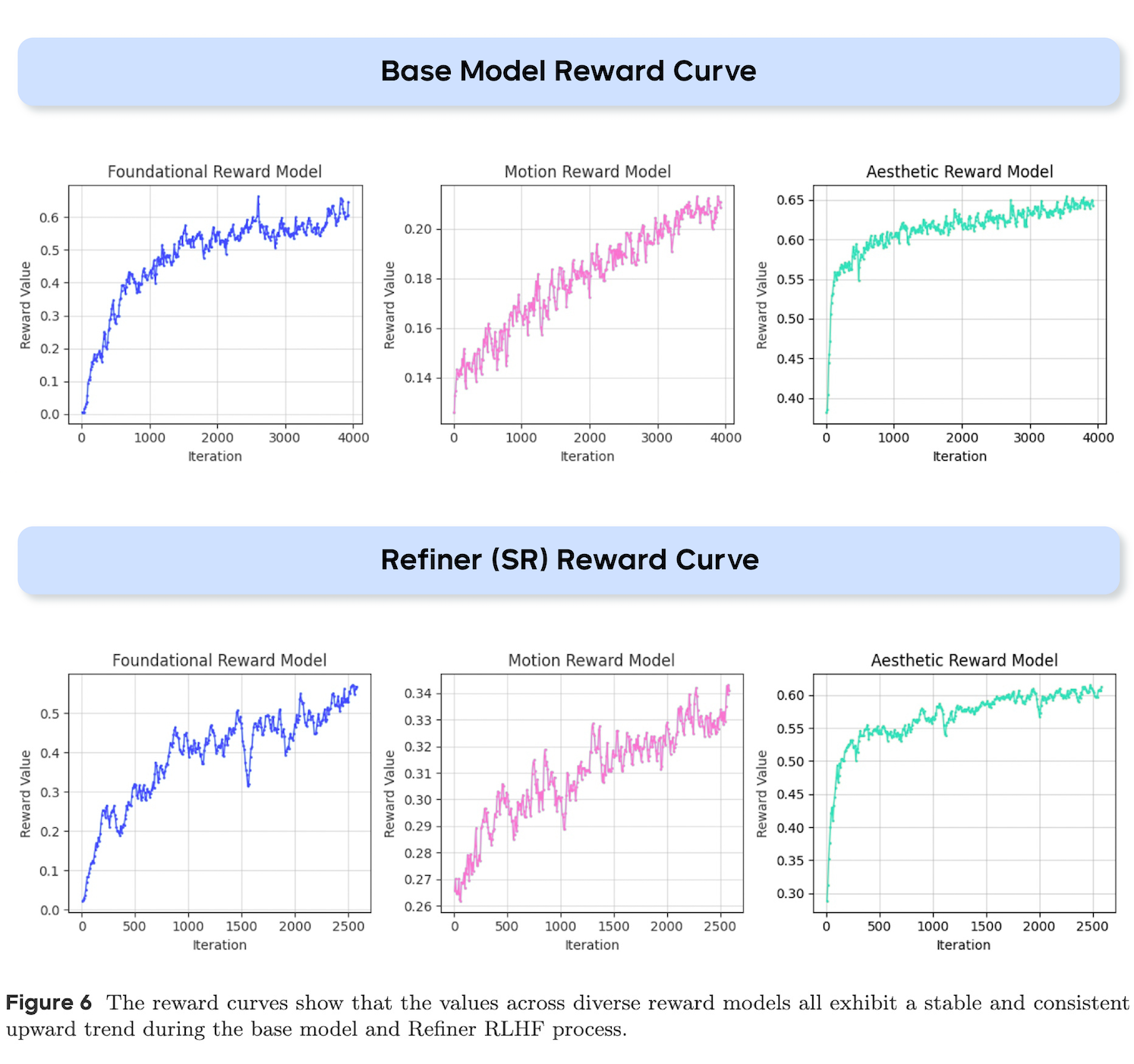
The reward curves show that the values across diverse reward models all exhibit a stable and consistent upward trend during the base model and Refiner RLHF process.
Speed up Inference for Ultra-Fast Generation: Generate a 5-second Video at 1080p Resolution Within About 40 Seconds
Seedance 1.0 has optimized both the model algorithms and the underlying inference infrastructure for near-lossless acceleration. This enables the model to generate videos at high speed without compromising metrics such as image-text alignment, visual quality, and motion quality. In our test (NVIDIA-L20), it can generate a 5-second video at 1080p resolution in only 41.4 seconds. Acceleration techniques employed by Seedance 1.0 include:
- Diffusion Model Algorithms
We introduced the trajectory segmented consistency distillation (TSCD) technique, adopted score distillation, and extended the adversarial training strategy to a multi-step distillation setting that incorporates human preference data for supervision. This helps us strike a better balance between quality and speed at an extremely low NFE. To address bottlenecks in the decoding process from latent space to pixel space, we designed a thin VAE decoder by narrowing the channel widths. This helps us achieve a 2× speedup with no loss in visual quality of the end-to-end video generation.
- Underlying Inference Infrastructure
We introduced system-level optimizations by leveraging techniques and strategies such as kernel fusion for operator optimization, heterogeneous quantization and sparsity, adaptive hybrid parallelism, async offloading, and hybrid parallelism for distributed VAE. This allows for an efficient inference pipeline for long-sequence video generation without compromising visual quality and deployability, boosting end-to-end throughput while maintaining memory efficiency.
Looking Ahead
Since 2024, video generation models have been constantly evolving. We believe, with ever-increasing vividness and naturalness and easier accessibility, video generation models will become efficient tools for content creation.
On this basis, video generation models can serve as world simulators to interact with humans in real time—and creating high-quality game content is no longer far-fetched.
Looking ahead, we will expand our research in the following aspects:
- Explore more efficient structural design and acceleration approaches:Build a better, cheaper, and faster video generation model that supports real-time interactions and fine-grained control.
- Make the model smarter:Expand its understanding of world knowledge, enhance the perceptual realism and physical plausibility of its outputs, and explore the integration of multimodal information, such as audio input and output capabilities.
- Analyze how to enhance the model performance through scaling in dimensions such as data volumes, model sizes, and reward models,Unlock more capabilities of the video generation model.