Seed 2.0 Official Launch
Seed 2.0 Official Launch
Date
2026-02-14
Category
Models
Products powered by large language models have been deeply integrated into our lives. In the past year or so, the LLM model series developed by Seed has supported C-end products with hundreds of millions of users, such as Doubao. Meanwhile, we've also noticed that with the arrival of the Agent era, LLMs will play an even more significant role in complex real-world tasks. For example, it can participate in scientific research, support complex software development, and even autonomously learn from context to complete various tasks with economic value.
At this pivotal moment, we are honored to introduce the latest Seed2.0 series. It has been systematically optimized to meet the requirements of large-scale production deployment, aiming to help tackle complex real-world tasks.
By analyzing how the Seed general-purpose model is invoked in the MaaS service, we discovered that the highest proportion of requests is to process knowledge-intensive content from unstructured sources, like complex charts and documents. Companies usually expect the model to start with tasks that require "heavy reading and deep thinking" before engaging in complex and professional workflows. This places increasingly high demands on the model's ability to understand long content and execute multi-step tasks.
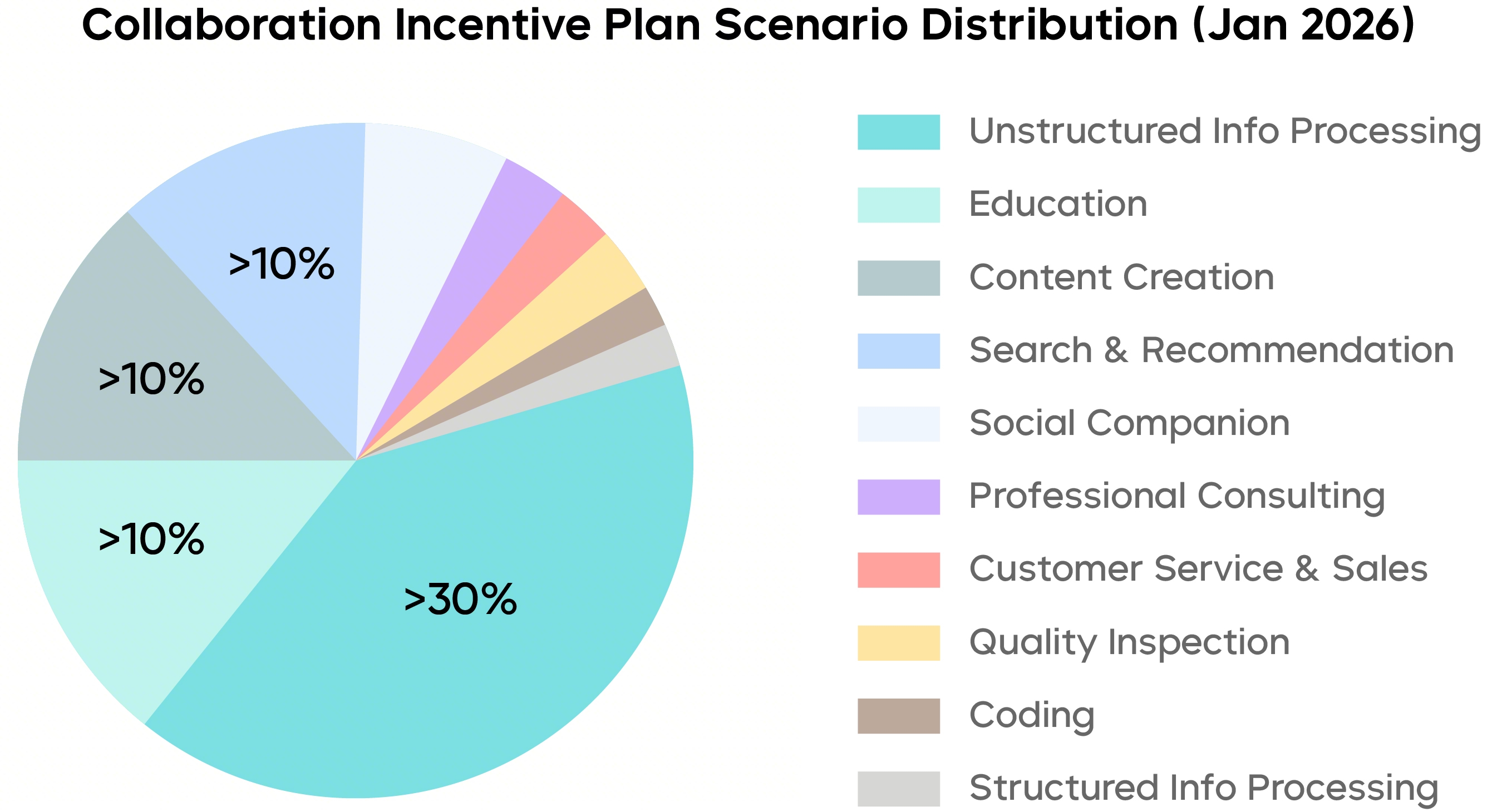
The distribution of Seed general-purpose model MaaS service usage scenarios in China's mainland, with data sourced from the " Volcano Ark Collaboration Incentive Program," and relevant users have signed authorization agreements.
Based on real-world usage scenarios, the Seed2.0 series has been optimized in the following aspects:
More robust visual and multi-modal understanding: Seed2.0 has enhanced its visual perception and reasoning capabilities. It can now parse complex documents, tables, graphs, and video content with significantly improved accuracy, processing visual information more precisely.
More reliable execution of complex instructions: Seed2.0 has improved its instruction-following and reasoning performance and strengthened its capability to understand and execute tasks with multiple constraints, multiple steps, and long chains. It has now laid a foundation for supporting high-value tasks.
Faster and more flexible inference options: Seed2.0 offers three general-purpose Agent models of different sizes - Pro, Lite, and Mini, along with a dedicated Code model, covering requirements under different scenarios for companies and developers to choose from.
Seed2.0 prioritizes user experience under large-scale online deployment, as evidenced by strong results on the LMSYS Chatbot Arena, a public human preference benchmark. Seed ranks 6th on the LMSYS Chatbot Arena — Text Arena (Overall) leaderboard and 3rd on the Vision Arena leaderboard as of Feb 16, 2026.
In addition to better supporting production-level requirements, Seed2.0 is dedicated to striving for maximum model intelligence. It has now advanced from solving Olympiad-level problems to handling research-level reasoning tasks. For example, Seed2.0 can explore Erdős-level math problems and also perform programming tasks related to some scientific tasks, further expanding the boundaries of machine intelligence.
The Seed2.0 Pro and Code models have been launched on the Doubao App and TRAE, and the model API for the Seed2.0 full series is available on Volcano Engine. We welcome everyone to try it out and offer feedback.
Homepage (including Model Card):
https://seed.bytedance.com/seed2
Comprehensive Upgrade to Multimodal Understanding
SOTA Performance Across Most Benchmarks
Seed2.0 delivers a comprehensive upgrade to multimodal capabilities, reaching industry-leading performance across a wide range of visual understanding tasks. It shows especially strong performance in visual reasoning, perception, spatial reasoning, and long-context understanding. Seed2.0 Pro achieves top scores on most major benchmarks.
In math and visual reasoning, Seed2.0 Pro reaches state-of-the-art results on benchmarks such as MathVista, MathVision, MathKangaroo, and MathCanvas. It also delivers significantly higher scores than Seed1.8 on visual puzzle and logical reasoning benchmarks, including LogicVista and VisuLogic.
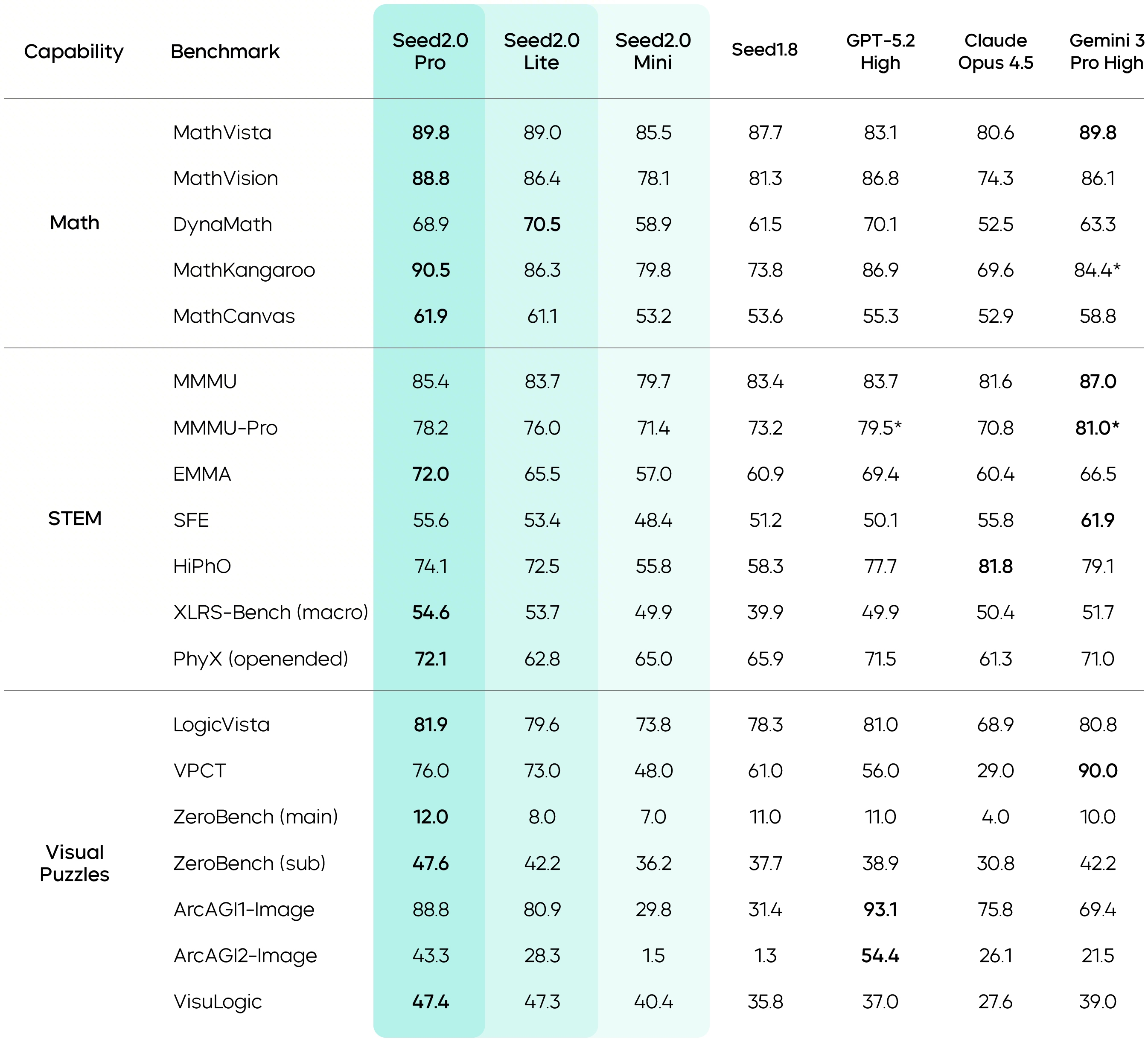
Data marked with * comes from publicly available technical reports.
Seed2.0's visual perception capabilities have been further enhanced. It achieves industry-leading scores on benchmarks such as VLMsAreBiased, VLMsAreBlind, and BabyVision, demonstrating accurate and reliable perception and judgment ability across diverse types of visual inputs.
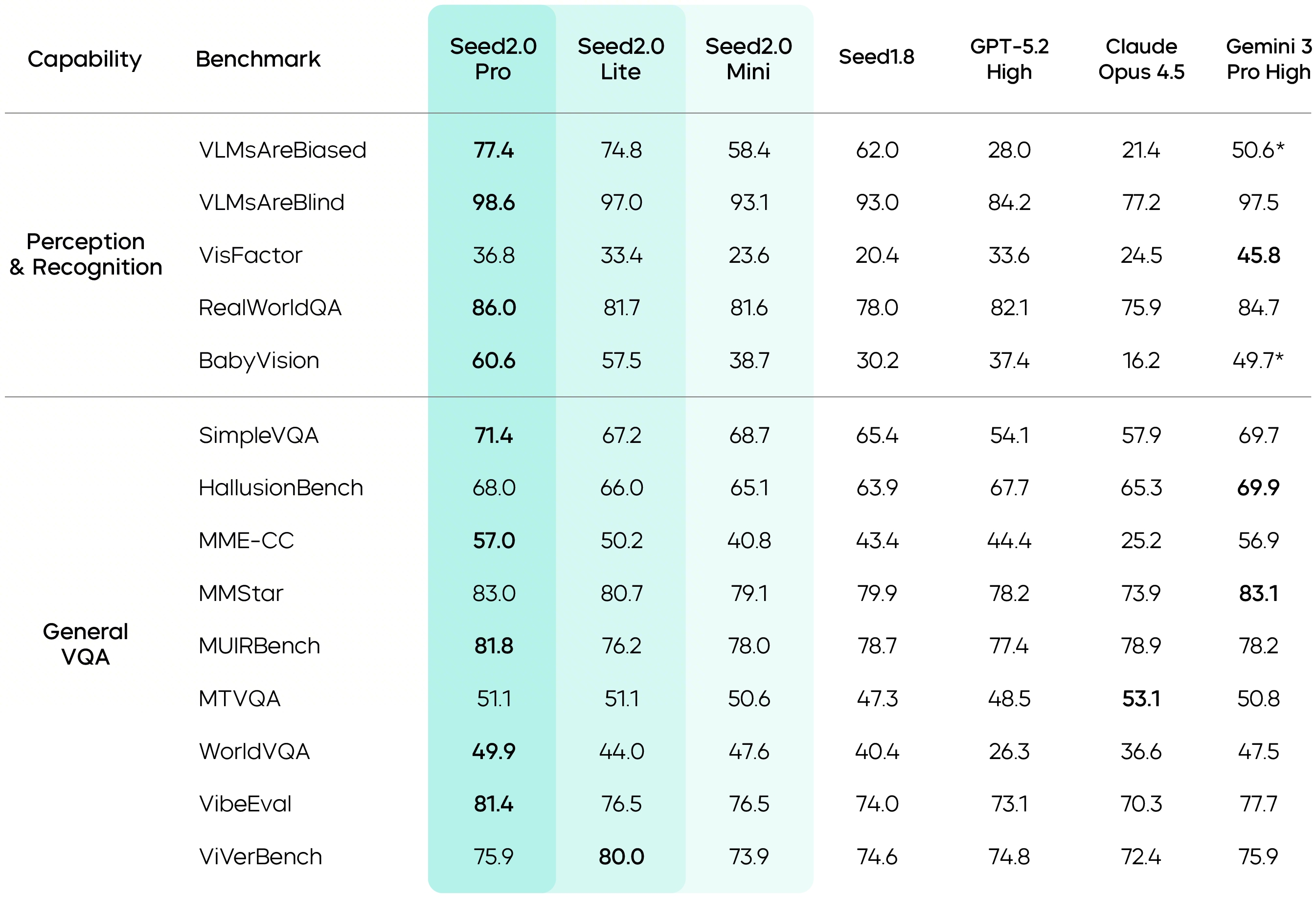
Data marked with * comes from publicly available technical reports.
The progress in core visual understanding significantly boosts Seed2.0's performance in real-world scenarios. In document understanding tasks, models often receive raw materials with complex layouts rather than standardized inputs. Compared with Seed1.8, Seed2.0 shows markedly stronger capabilities in handling unstructured information, reaching top-tier performance on ChartQAPro and OmniDocBench 1.5.
In long-context understanding, Seed2.0 achieves industry-best results on DUDE, MMLongBench, and MMLongBench-Doc.
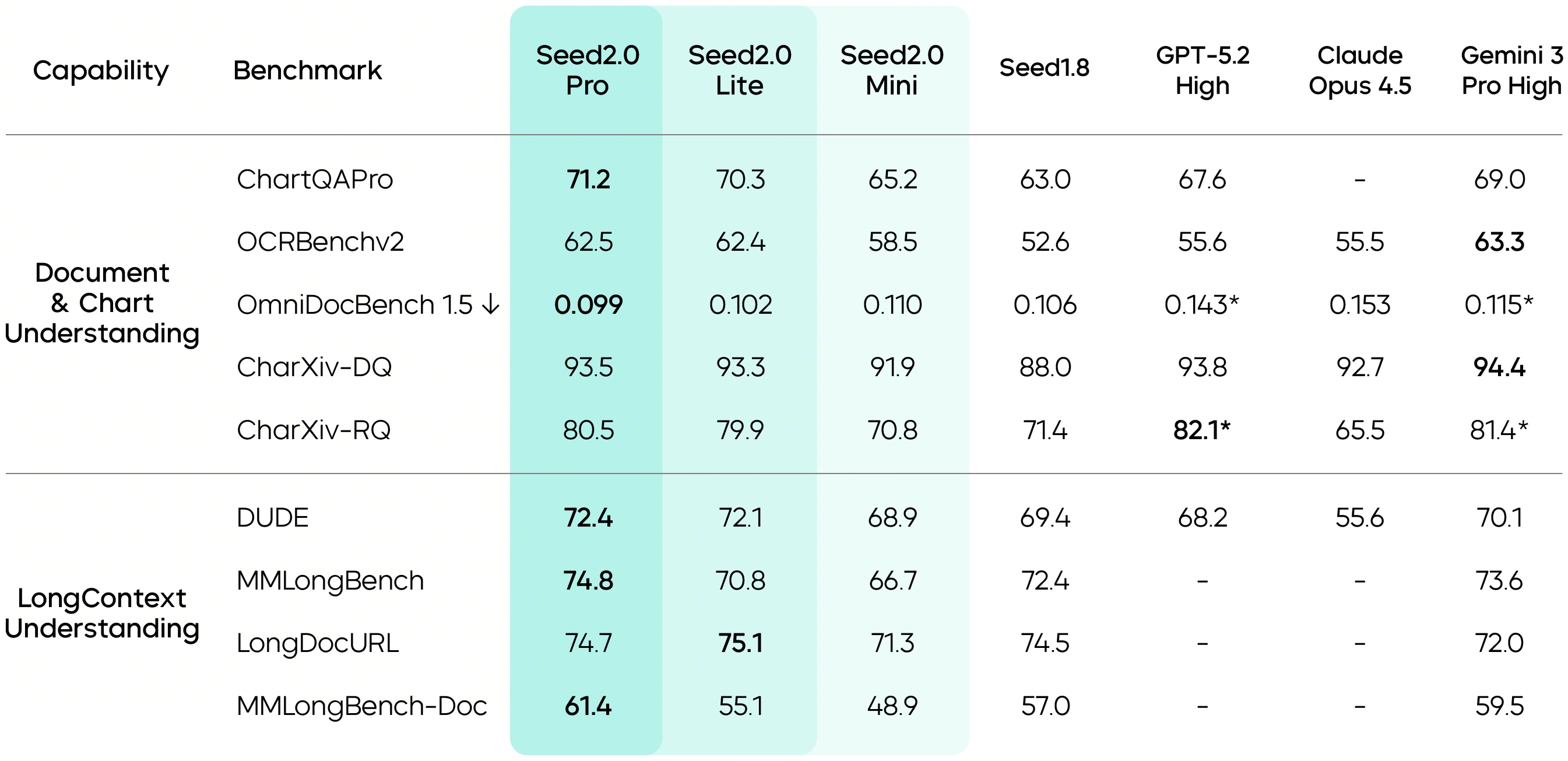
Data marked with * comes from publicly available technical reports.
For video scenarios, Seed2.0 strengthens its understanding of temporal sequences and motion perception. It ranks among the leading players on key benchmarks, including TVBench, TempCompass, and MotionBench, and surpasses human-level performance on EgoTempo. This reflects more stable and precise capture of changes, actions, and rhythm, translating into stronger engineering robustness and real-world readiness.
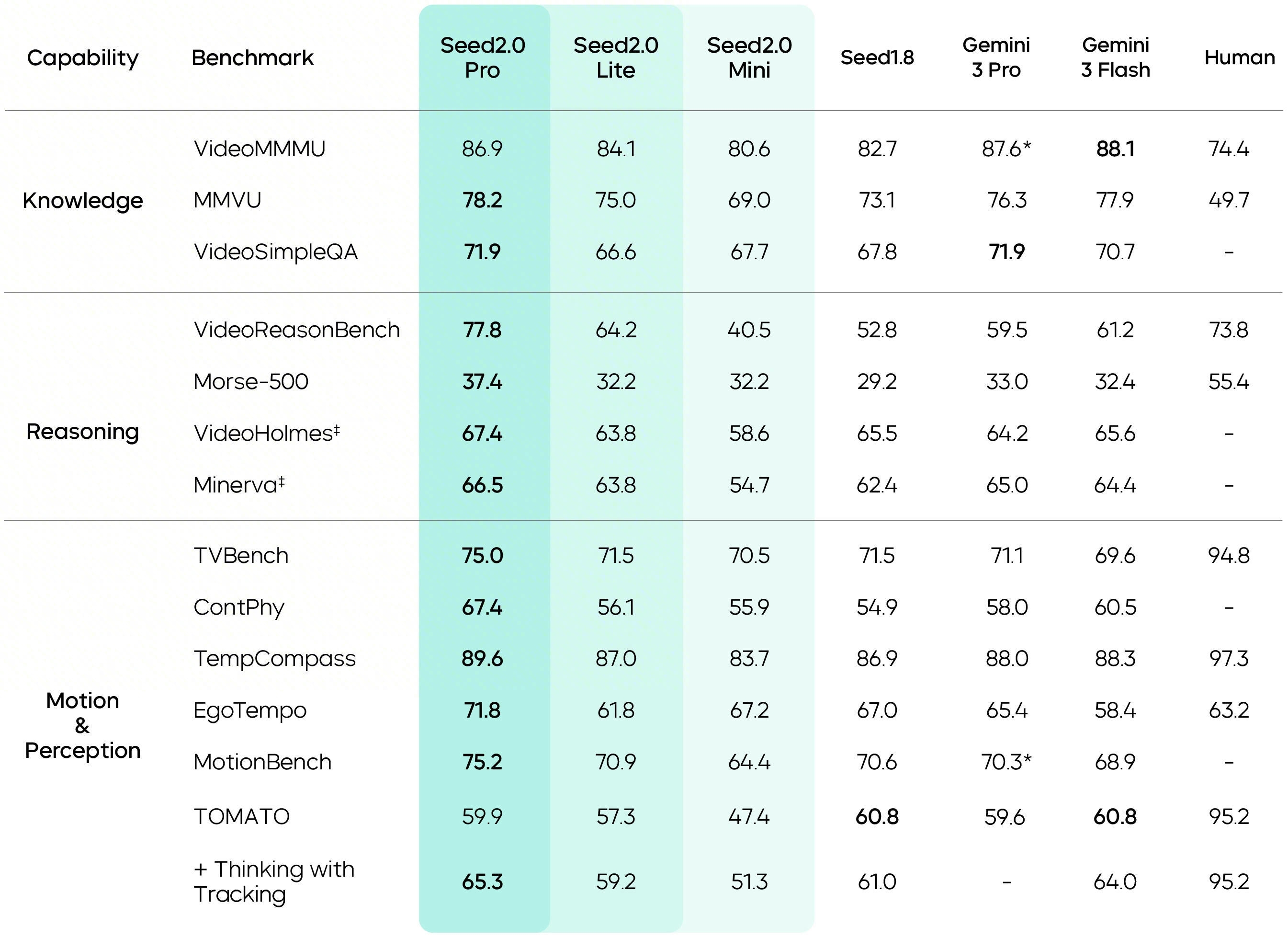
Data marked with * comes from publicly available technical reports
In long-video scenarios, Seed2.0 outperforms other leading models across most evaluations. It efficiently and accurately handles hour-long videos. Additionally, the VideoCut tool further extends the duration range for processing long videos and improves inference accuracy. In real-world enterprise deployments with lengthy and information-dense videos, Seed2.0 can quickly capture key video information and generate accurate conclusions for downstream decision-making.
At the same time, Seed2.0 performs strongly across multiple real-time streaming video QA benchmarks. As an AI assistant, it can handle many tasks, such as real-time video streaming analysis, environment awareness and active error correction—upgrading interaction from passive Q&A to proactive guidance, with applications in fitness, styling, and other scenarios.
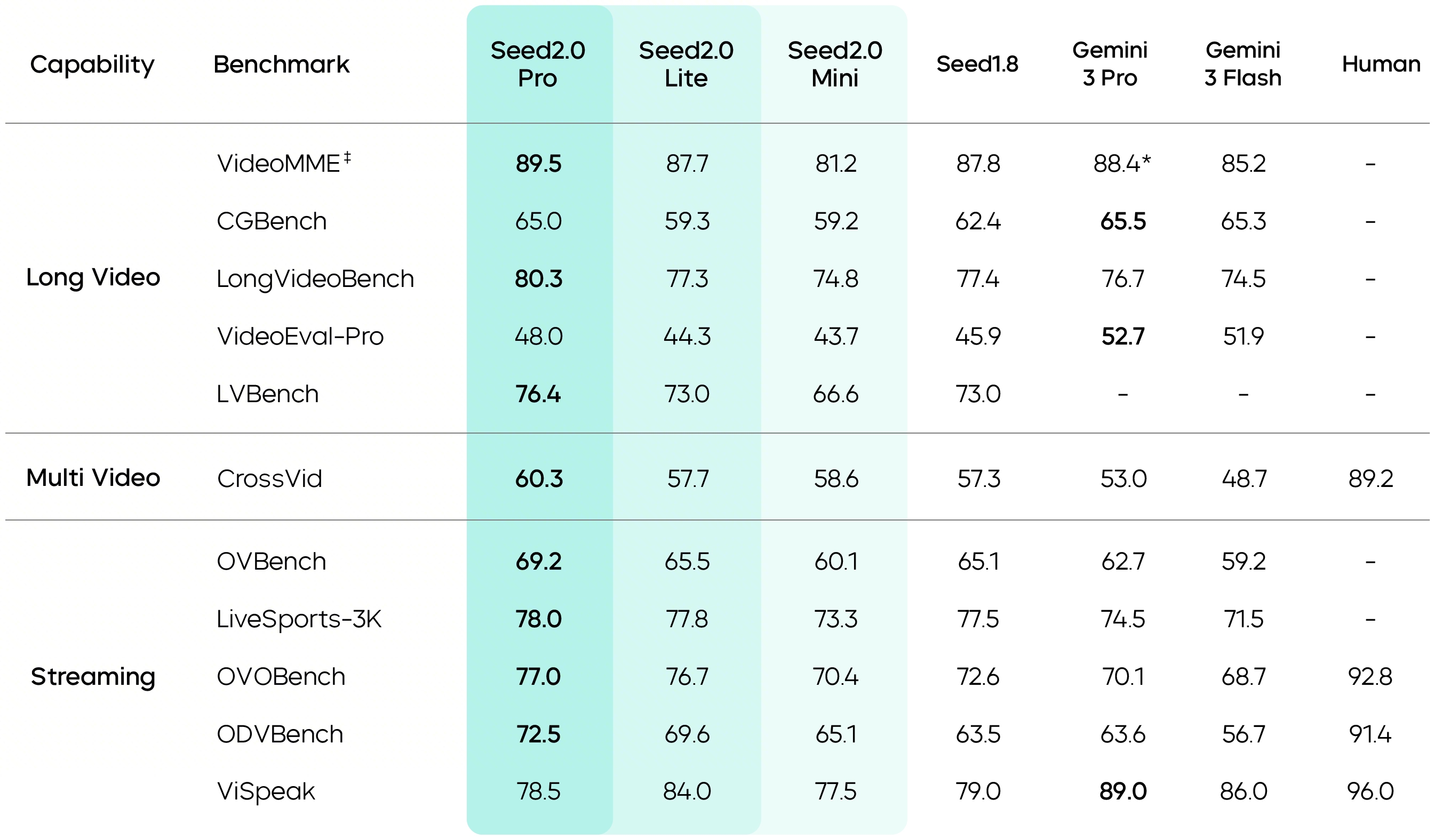
Data marked with * comes from publicly available technical reports
Substantial Enhancements in LLM and Agent Performance
Elevated Capabilities to Execute Real-World Long-Horizon Tasks
The Seed team observed a notable capability gap: While language models have demonstrated high proficiency in solving complex contest problems, they still struggle with end-to-end tasks in the real world—such as building a well-designed, fully functional mini-app in a single pass.
Why do LLMs and Agents often hit a wall when handling real-world tasks? We believe the reasons are mainly twofold:
Real-world tasks usually span longer time frames and involve multiple stages. Existing LLM Agents struggle to independently construct efficient workflows and gain experience over extended periods.
Real-world knowledge has significant domain barriers and follows a long-tail distribution. Industry-specific knowledge typically lies in the long tail of the training corpus. Therefore, even models that excel in math and code fall short in specialized settings.
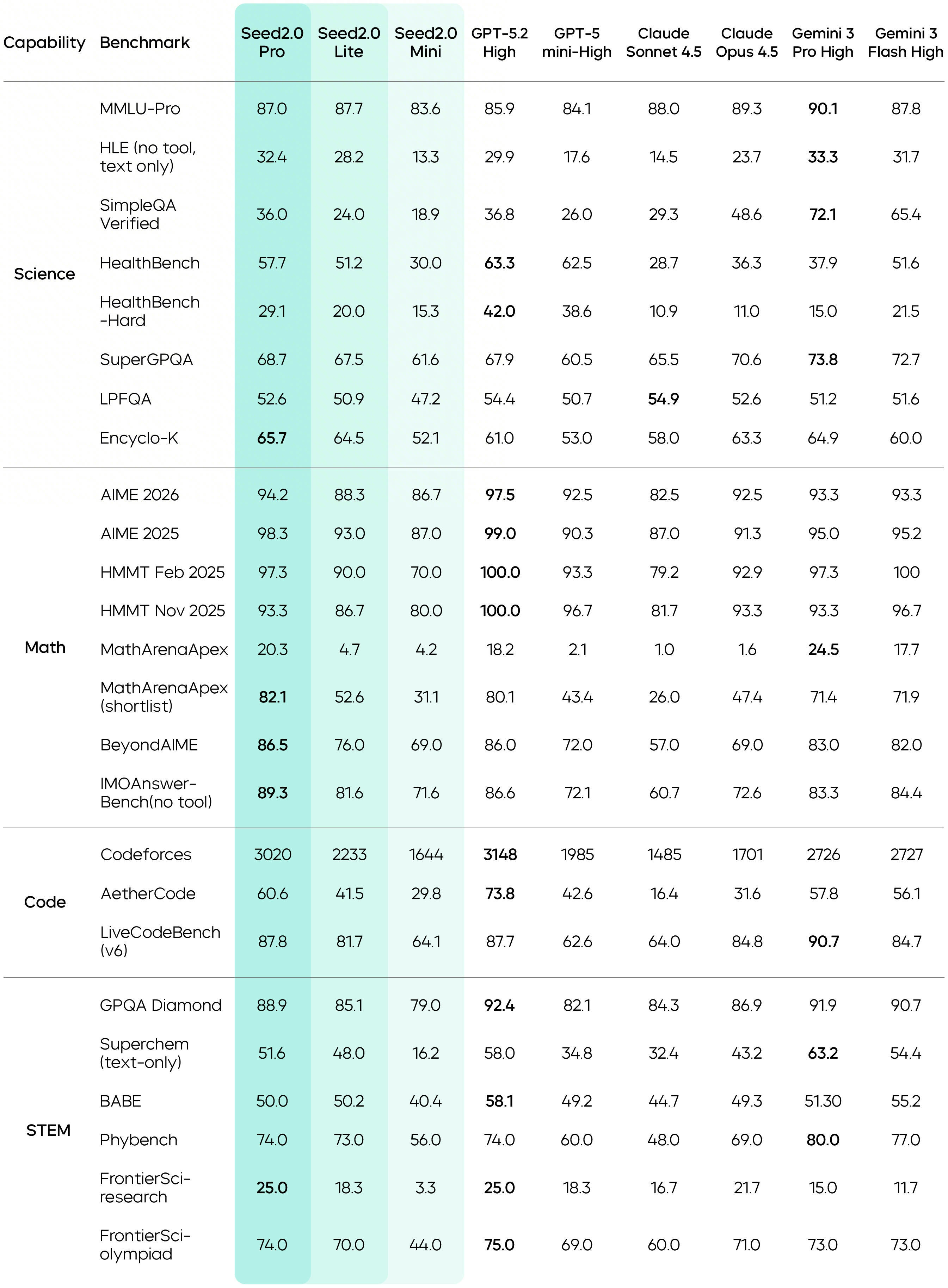
Seed2.0 first addresses this challenge by systematically strengthening knowledge in long-tail domains. Seed2.0 Pro has scored higher than GPT-5.2 on SuperGPQA. Its overall performance in the scientific field is on par with Gemini 3 Pro and GPT-5.2.
In addition, Seed2.0 Pro has significantly enhanced its capability to apply interdisciplinary knowledge. It delivered exceptional performance in STEM benchmark tests, such as FrontierSci, with scores in some scenarios exceeding GPT-5.2. Meanwhile, Seed2.0 Pro achieved gold medal results in ICPC, IMO, and CMO tests, demonstrating further improvements in the model's mathematical, coding, and reasoning intelligence capabilities.


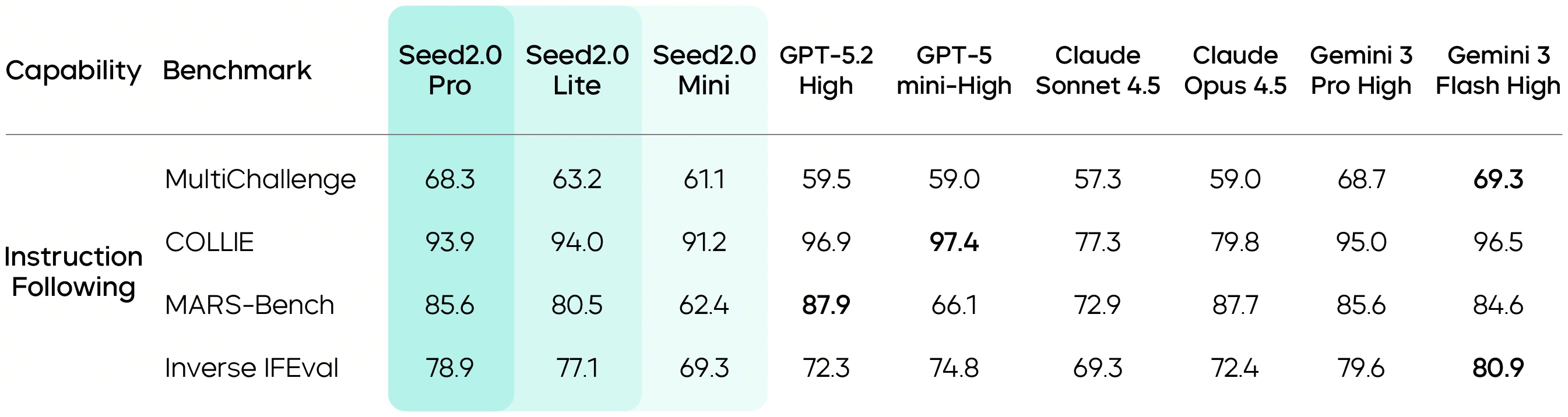
Seed2.0 has also significantly strengthened its ability to follow instructions. Relevant evaluations show that Seed2.0 can maintain strong consistency and controllability, laying a foundation for it to execute long-chain, multi-step tasks strictly in accordance with constraints as an Agent model.
As evidenced by its foundational Agent capability scores, Seed2.0 demonstrates outstanding performance in long-chain tasks. It is particularly adept at continuously executing sequential workflows such as "retrieving information, making summaries, and drawing conclusions". In search and deep research tasks, Seed2.0 achieved high scores across seven evaluations including BrowseComp-zh and HLE-text, demonstrating its advancement capabilities and stability in research tasks.
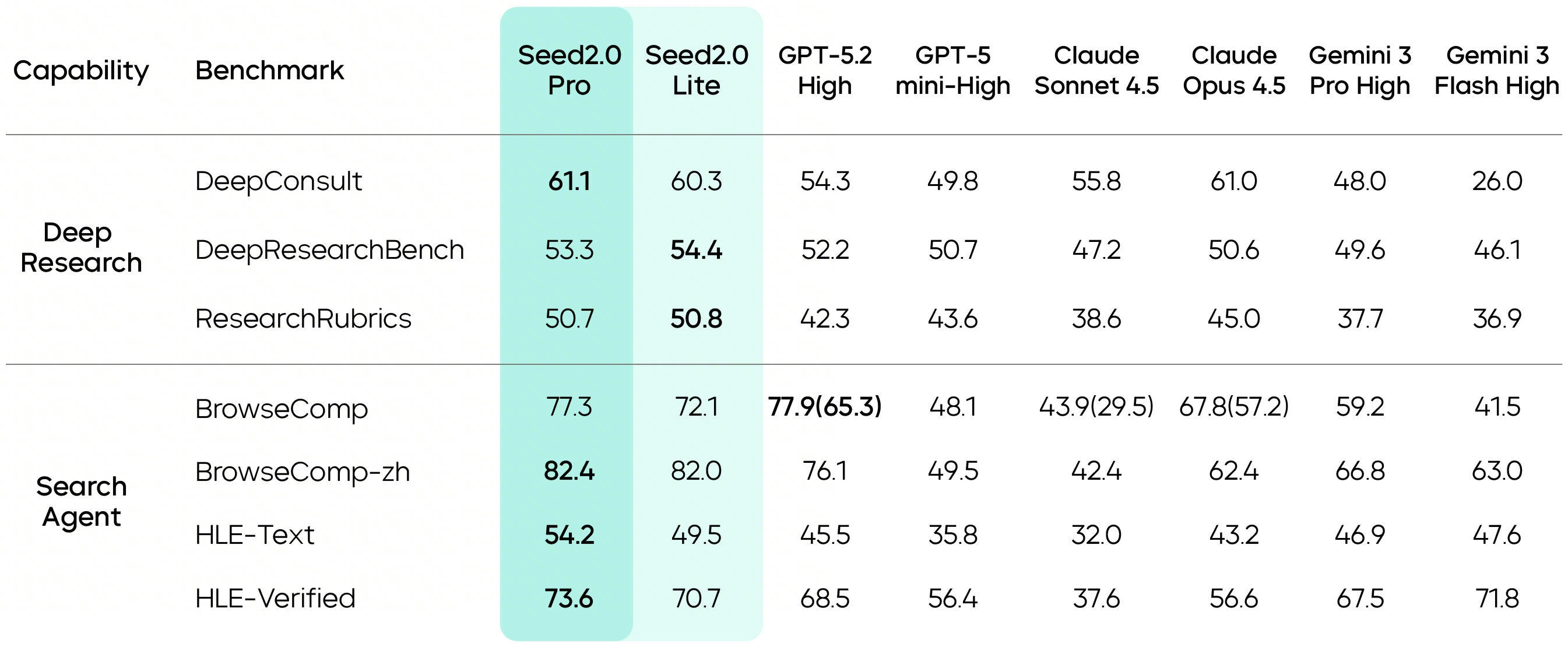
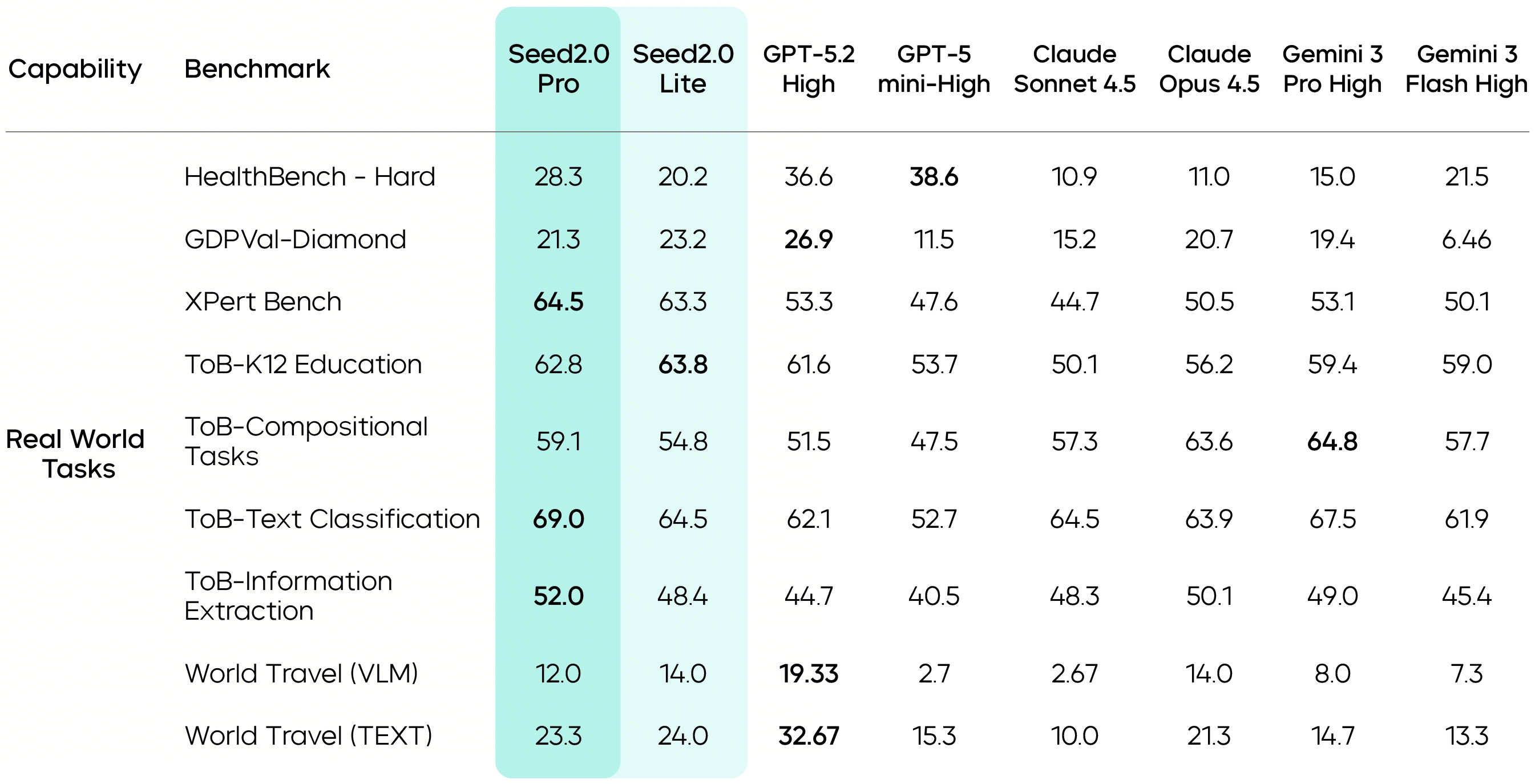
In the assessment of complex Agent capabilities, Seed2.0 achieves top-tier performance in the industry. For example, when evaluated on real-world tasks with direct economic value, Seed2.0 demonstrates consistent performance across high-frequency user scenarios, such as customer service Q&A, information extraction, intent recognition, and K-12 problem-solving. In complex professional task benchmarks such as GDPVal - Diamond and XPert Bench, the model has also achieved competitive results, suggesting it can handle long-chain, multi-constraint query tasks effectively.
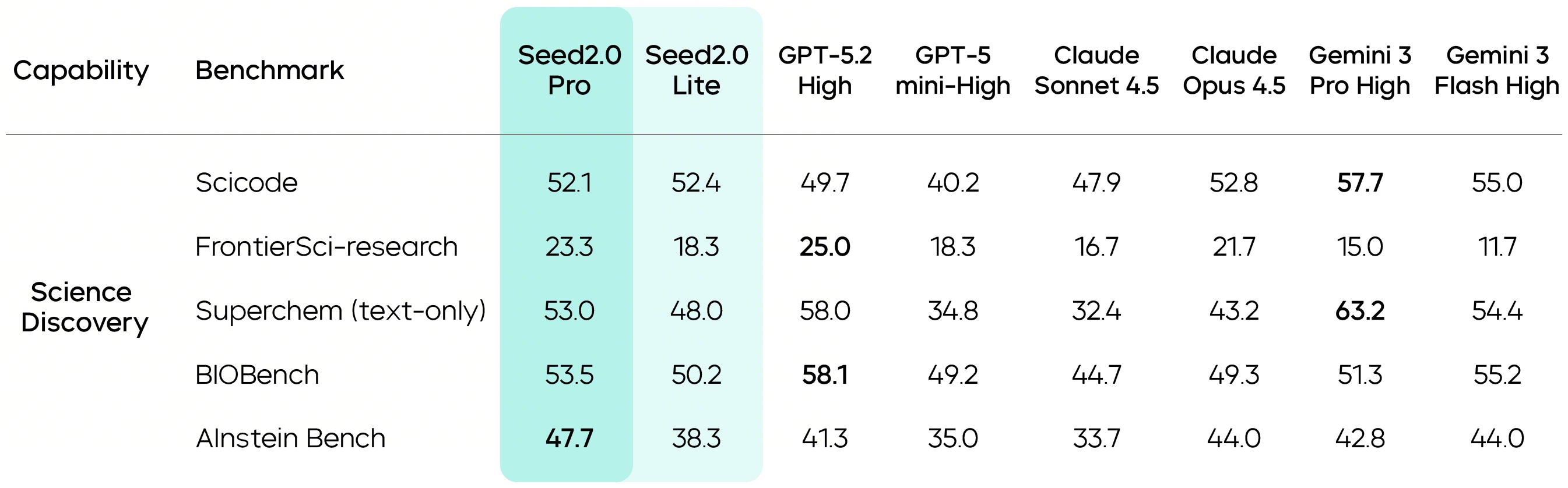
At the same time, Seed2.0 Pro delivers strong performance on frontier research benchmarks such as FrontierSci-research and leads on AInstein Bench, demonstrating strong hypothesis-driven reasoning capabilities in scientific discovery scenarios.
In addition, Seed2.0 can turn "research ideas" into "actionable experiment plans".
Taking Golgi protein analysis as an example, it not only outlines the overall experimental strategy, but also connects gene engineering, mouse model construction, subcellular fractionation, and multi-omics analysis into a coherent end-to-end workflow. It further specifies how to execute key steps, what controls to use to rule out contamination, and which metrics to apply to assess purity. Domain experts note that the plans generated by Seed2.0 exceed their expectations of large language models in terms of cross-disciplinary experimental detail and step-by-step clarity. Its responses go beyond high-level strategy, producing well-structured, scientifically sound, and executable experimental drafts.

While improving multi-step task execution capabilities, Seed2.0 further reduces inference costs. Its performance is comparable to other leading large language models in the industry, while token pricing is lowered by approximately an order of magnitude. In real-world complex tasks, where large-scale reasoning and long-chain generation consume substantial tokens, this cost advantage becomes even more critical.
*For a detailed overview of the evaluation benchmarks and additional real-world case studies of Seed2.0, please refer to the Model Card.
Summary and Outlook
In response to the real needs and use cases of companies and users, we have curated and built a series of evaluation benchmarks to create an evaluation system for large language models.
Leveraging this reliable and forward-looking evaluation system, Seed2.0 enhances multimodal understanding and reasoning capabilities, while tackling challenges such as long-tail knowledge and following complex instructions. This improves the model's reliability in complex, long-duration real-world tasks. In evaluations based on real-world application scenarios, Seed2.0 performs excellently, reaching top-tier industry levels and demonstrating potential to support scientific research tasks.
While Seed2.0 has made significant progress in end-to-end code generation and contextual learning, there is still room for improvement in some challenging and difficult benchmarks compared to top global models. Going forward, we will continue to iterate the Seed language model with real-world scenarios in mind, continuously striving for maximum intelligence.