Seed Research│GR-3 Released: A Generalist Robot Model for Generalization, Long-Horizon Tasks, and Bi-Manual Deformable Object Manipulation
Seed Research│GR-3 Released: A Generalist Robot Model for Generalization, Long-Horizon Tasks, and Bi-Manual Deformable Object Manipulation
Date
2025-07-22
Category
Models

Seed GR-3 is a new vision-language-action (VLA) model provided by ByteDance Seed. It excels in generalizing to novel objects and environments, understanding instructions with abstract concepts, and manipulating deformable objects dexterously.
ArXiv: http://arxiv.org/abs/2507.15493
Model Homepage: https://seed.bytedance.com/GR3
Unlike previous VLA models that must be trained on large amounts of robot trajectory data, GR-3 can be efficiently fine-tuned with minimal human trajectory data, enabling rapid and cost-effective adaptation to novel tasks and objects.
In addition, benefiting from the optimized model architecture, GR-3 can efficiently handle long-horizon and dexterous tasks, including bi-manual manipulation, deformable object manipulation, and whole-body control (WBC) based on mobile base movement.
These capabilities are achieved through a multi-faceted training recipe that includes co-training with web-scale vision-language data, efficient fine-tuning with human trajectory data constructed by lab members based on VR devices, and effective imitation learning with robot trajectory data. The diversity of training data is one of the advantages that distinguish GR-3 from other VLA models.
Meanwhile, ByteDance Seed also introduced ByteMini, a versatile bi-manual mobile robot with high flexibility and reliability. It has 22 degrees of freedom (DoFs) and uses a unique sphere wrist design to achieve human-like dexterity and complete delicate tasks in confined spaces. ByteMini, powered by GR-3 that serves as the brain of the robot, can efficiently handle challenging tasks in real-world environments.
GR-3 demonstrates the following capabilities across a wide array of tasks:
Intelligence: GR-3 excels in handling a long-horizon table bussing task with 10 or more sub-tasks, demonstrating exceptionally high robustness and a high success rate. During the process, it strictly follows the given instructions to perform sub-tasks.
Dexterity: GR-3 controls two robotic arms to co-manipulate deformable objects in complex, dexterous cloth hanging tasks, and even robustly recognizes and organizes clothes in different layouts.
Generalization: In pick-and-place tasks, GR-3 showcases capabilities in generalizing to unseen objects and understanding instructions that include complex abstract concepts.
Thousands of systematic experiments show that GR-3 outperforms the state-of-the-art baseline VLA model, π0. Looking ahead, we hope that GR-3 can serve as a significant step towards building the "brain" of generalist robots.

ByteMini, using GR-3 as its brain, can efficiently complete a wide range of generalizable household tasks.
Why is it easy for robots to clean the floor, but difficult for them to hang clothes or clean up a table?
Technically, developing a robot that can flexibly handle complex household tasks like humans—to understand instructions, learn quickly, and perform well—is harder than we thought. This is one of the most challenging bottlenecks in giving a generalist brain to robots. The challenges are as follows:
Understand complex semantics: Natural language is often too vague. We may tell the robot to put the book on the left to the top shelf or put the largest object in the box. In these instructions, "left" and "largest" are abstract concepts. The robot must understand these complex instructions before it can act upon them. Previous robots are usually inflexible in understanding. They cannot understand the instructions once you rephrase them.
Adapt to changes: The real world is constantly changing. Today, the cup is placed in the center of the table. Tomorrow, it may be left at the edge of the table. After you visit the shopping mall today, more cups may appear on your table or more clothes may appear in your closet by tomorrow. These are unseen objects and environments for robots. Due to the diversity and ever-changing nature of generalizable scenarios, robots must have powerful generalization and learning capabilities to easily adapt to unseen environments and objects each day.
Handle long-horizon tasks: Most household tasks are long-horizon tasks. For example, to clean up a dining table, the robot needs to pack the food into the to-go box, put all the utensils into the bussing box, and put all the trash into the rubbish bin. A mistake in any step could lead to the failure of the entire task. Traditional robots usually mess things up halfway through the task. They might even struggle with impossible instructions, such as trying to put a spoon that does not exist into a bowl.
The preceding challenges involve complex, abstract, and hard-to-model real-world scenarios that cannot be exhaustively covered by traditional rule-based methods.
To address these challenges, ByteDance Seed introduced GR-3, a large-scale robot manipulation model designed based on large model and robot technologies. This model helps develop generalist robots that can understand instructions, learn quickly, and execute well—bringing us one step closer to a truly versatile robot assistant.
Three Key Innovations in GR-3's DesignIntegrated Brain + Diverse Training Data + Dexterous Body Manipulation
GR-3 is built upon the following technical breakthroughs:
Vision-Language-Action Integration in the "Brain"
GR-3 adopts the mixture-of-transformers (MoT) architecture. It integrates the vision-language module and action generation module into a 4B end-to-end model.
The action generation module is a diffusion transformer (DiT) that generates actions via flow-matching. In addition, GR-3 adds RMSNorm inside both attention and feed-forward networks (FFNs) within the DiT blocks. This design drastically enhances the dynamic instruction following capability of GR-3.
Just as people first take in information through their eyes and ears and then use their brains to guide hands and feet, GR-3 can directly determine its next move based on what it "sees" through its camera and hears in voice instructions. For example, when it sees a "dining table" and hears "clean up the table", it will directly perform a sequence of actions: Pack the food into the to-go box > Put all the utensils into the bussing box > Put all the trash into the rubbish bin.
Training GR-3 on Three Types of Data
Unlike traditional robots that learn only from robot data, GR-3 is trained on the following types of data:
Robot trajectory data collected via teleoperation: GR-3 is trained on robot trajectory data of picking up cups and hanging clothes collected with teleoperated robots. This type of data ensures a solid foundation for the basic manipulation capabilities of robots.
Human trajectory data collected with VR devices: GR-3 also learns from human trajectory data collected with VR devices. This method is a breakthrough in VLA model training, allowing robots to quickly adapt to novel tasks with extremely low costs. In addition, we observed that human trajectories can be efficiently collected with VR devices at a rate of approximately 450 trajectories per hour, substantially outpacing the teleoperated robot trajectory collection, which collects about 250 trajectories per hour.
Publicly accessible vision-language data: GR-3 can recognize objects (such as grapes and chopsticks) in publicly accessible vision-language data and learn abstract concepts (such as large, small, left, and right). This type of data greatly enhances the generalization capability of GR-3.
A Tailored "Body"
The ByteMini robot serves as a dexterous "body" tailored for the "brain" GR-3.
Mobile movement: A WBC system is built into the ByteMini robot to make its actions fast, stable, and gentle. During teleoperated robot trajectory collection, the system can generate seamless trajectories rather than stiffly grabbing objects like traditional robots. For example, the system can automatically adjust the strength when grabbing a paper cup to avoid crushing it.
Delicate operations: ByteMini is designed with 22 DoFs and 7-DoF unbiased robotic arms, featuring a unique sphere wrist joint configuration. This design allows the arms to move flexibly like human wrists and execute delicate operations in confined spaces such as storage boxes and drawers.
Perception: ByteMini comes with multiple cameras. The two wrist cameras enable close-up observation for delicate manipulation, such as the angle at which the cup is grabbed. The head camera provides a global view, such as a view of the objects on the table.
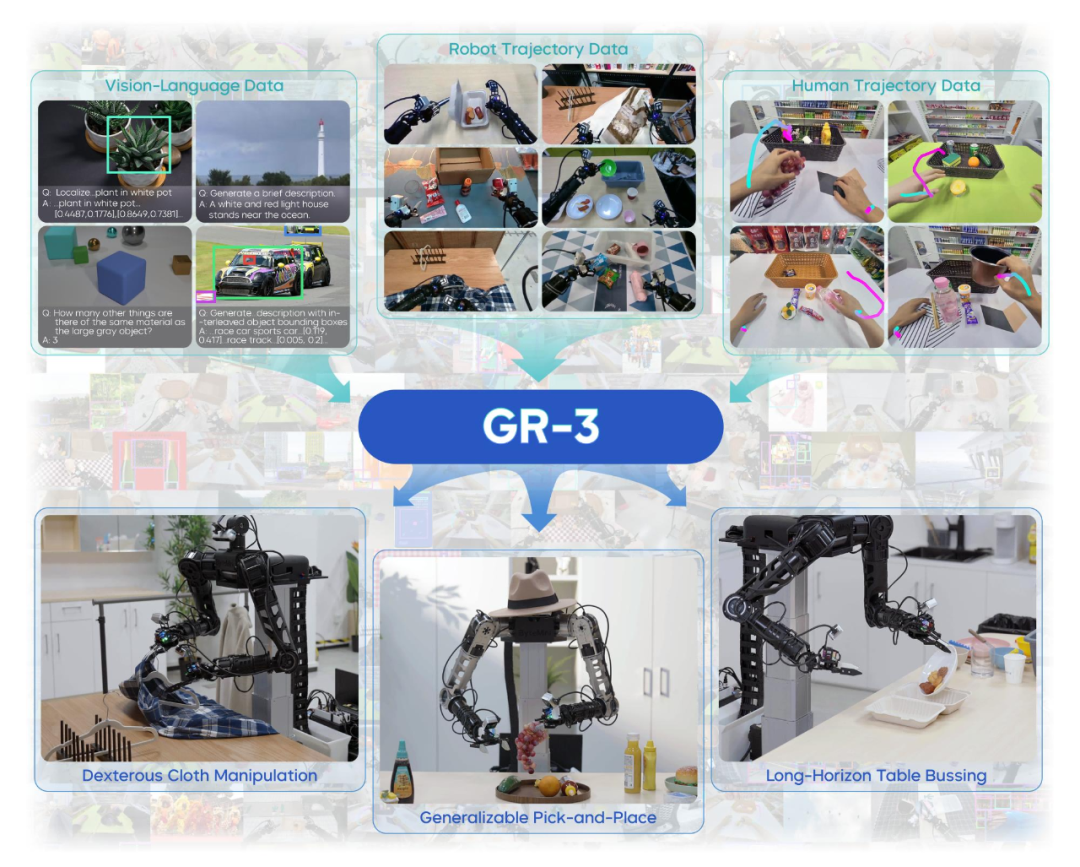
GR-3, a large-scale VLA model for robot manipulation
The preceding key innovations enable GR-3 to understand abstract concepts, quickly learn new skills, and execute delicate operations, overcoming the limitations of traditional robots—inflexible, slow in learning, and underperforming in delicate operations.
Strong Generalization Capabilities in Generalizable TasksExcellence in Handling Long-Horizon and Dexterous Tasks
ByteDance Seed tested the GR-3 model across three challenging tasks.
Generalizable Pick-and-Place Task: Strong Generalization Capabilities
ByteDance Seed prepared 99 objects to test and compare GR-3 with other two models through 861 experiments. The performance is evaluated in four different settings:
Basic: ByteDance Seed tested the capabilities of GR-3 on manipulating seen objects in seen scenarios during training. The result reveals that the instruction following rate and success rate of GR-3 are 98.1% and 96.3%, respectively. It can strictly follow simple instructions such as "put A into B".

Objects used in the generalizable pick-and-place task: The objects on the left are seen objects during training and the objects on the right are unseen objects during training.
Unseen Environments: To elevate the difficulty level of testing, ByteDance Seed switched to four unseen scenarios during training: a desk in a bedroom, a checkout counter, a meeting room, and a break room. The test results reveal that GR-3 consistently performs well, with no evident performance drop in these unseen scenarios. This highlights its robustness against environment changes and demonstrates its capability to adapt and generalize to novel environments.

Test environments for generalizable pick-and-place tasks: The Basic environment is seen during training. The others are out-of-distribution environments that are unseen during training.
Unseen Instructions: ByteDance Seed also tested the capabilities of GR-3 in understanding complex instructions involving abstract concepts. The result reveals that GR-3 can accurately understand instructions involving spatial relationships, object sizes, and other abstract concepts (refer to the following video clips), such as "put the coke next to the sprite into the white plastic box", "put the bread into the larger plate", and "put the land animal into the plate". The baseline model in the test might be confused about these objects.
Put the coke next to the sprite into the white plastic box
Put the bread into the larger plate
Put the land animal into the plate
Unseen Objects: ByteDance Seed tested the capabilities of GR-3 on manipulating unseen objects. In the experiment, GR-3 was used to control the robot to pick up novel objects. The result shows that GR-3 outperforms the baseline model π0 by 17.8% in the success rate, benefiting from what it learns from the publicly accessible vision-language data.
Through evaluation across the above four settings and comparison against a GR-3 variant trained without publicly accessible vision-language data (marked as GR-3 w/o Co-Training in the figure), we found that:
In Basic and Unseen Environments, co-training with publicly accessible vision-language data does not lead to performance degradation. In Unseen Instructions and Unseen Objects, co-training with vision-language data helps improve the success rate of GR-3 by 42.8% and 33.4%, respectively.
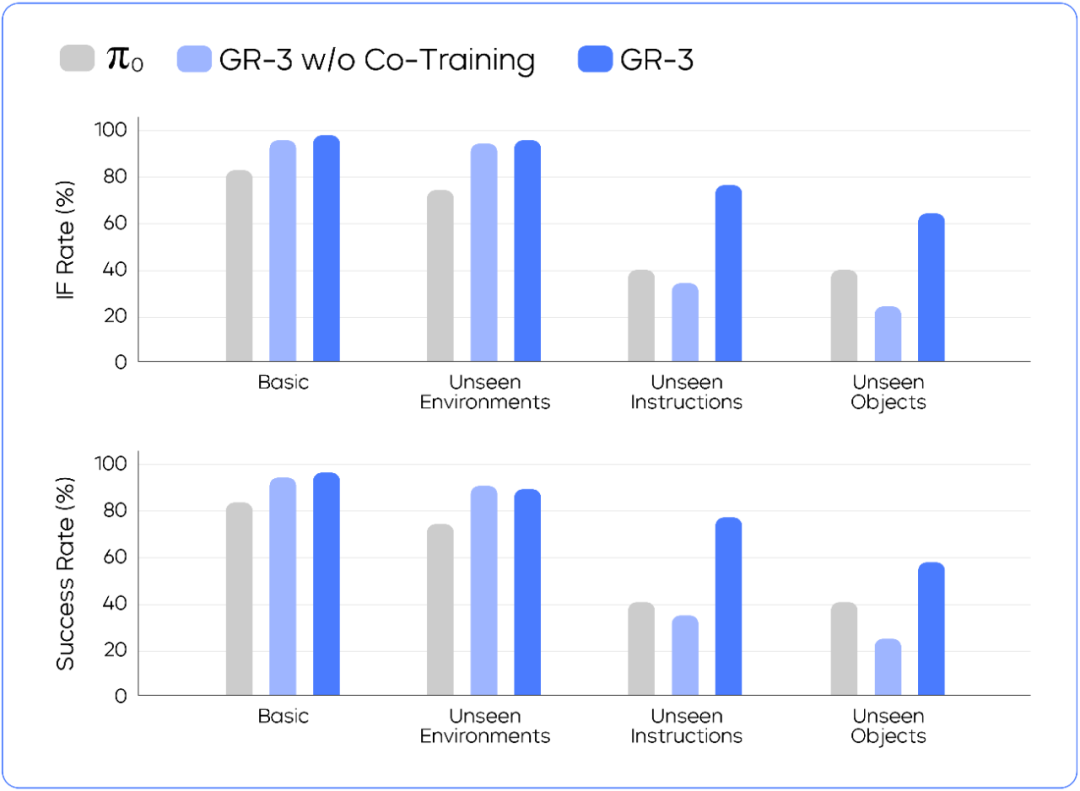
The result of the generalizable pick-and-place task shows that GR-3 outperforms the baseline model across the four test settings.
To consistently optimize the capabilities of GR-3 in manipulating unseen objects, ByteDance Seed used VR devices to collect human trajectory data. The result reveals that:
With only 10 human trajectories collected with VR devices for each object, the success rate of GR-3 in manipulating the objects can be boosted from lower than 60% to higher than 80%.
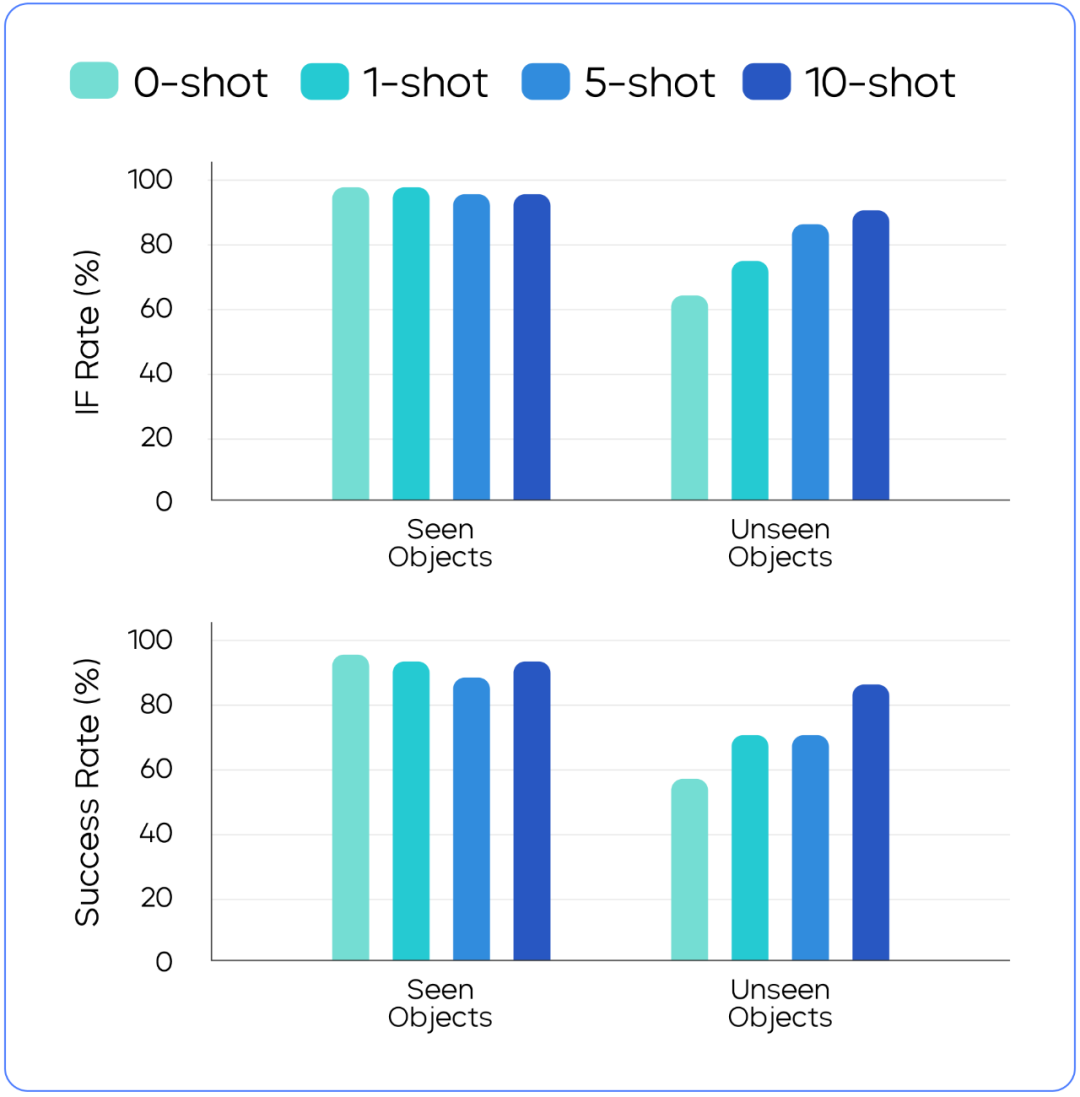
Co-training with human trajectory data allows GR-3 to learn new tasks more quickly. For unseen objects in robot data, adding more human trajectories helps GR-3 perform better. For seen objects in robot data, adding human trajectories has only a minor impact on the performance of GR-3.
Long-Horizon Table Bussing: Perform Sub-Tasks with High Stability
In the long-horizon table bussing task, after GR-3 is prompted with "clean up the table", it can autonomously complete the entire task in a single run: Pack the food into the to-go box > Put all the utensils into the bussing box > Pick up the bussing box. The average progress of the entire task exceeds 95%.
GR-3 can complete the table bussing task when different utensils are randomly placed on the table (first-person view of the robot)

Objects used in the long-horizon table bussing task
ByteDance Seed also tested the instruction following capability of GR-3 in executing sub-tasks. The result reveals that:
GR-3 outperforms the baseline model in following language instructions. When handling multiple instances of the same object category, such as multiple cups, GR-3 can strictly follow the instruction to put them into the rubbish bin. If the instruction is invalid, (for example, no blue bowl is found on the dining table but the instruction is "put the blue bowl in the basket"), GR-3 remains still while the baseline model randomly picks up an object.

GR-3 can strictly follow the given instructions to perform sub-tasks
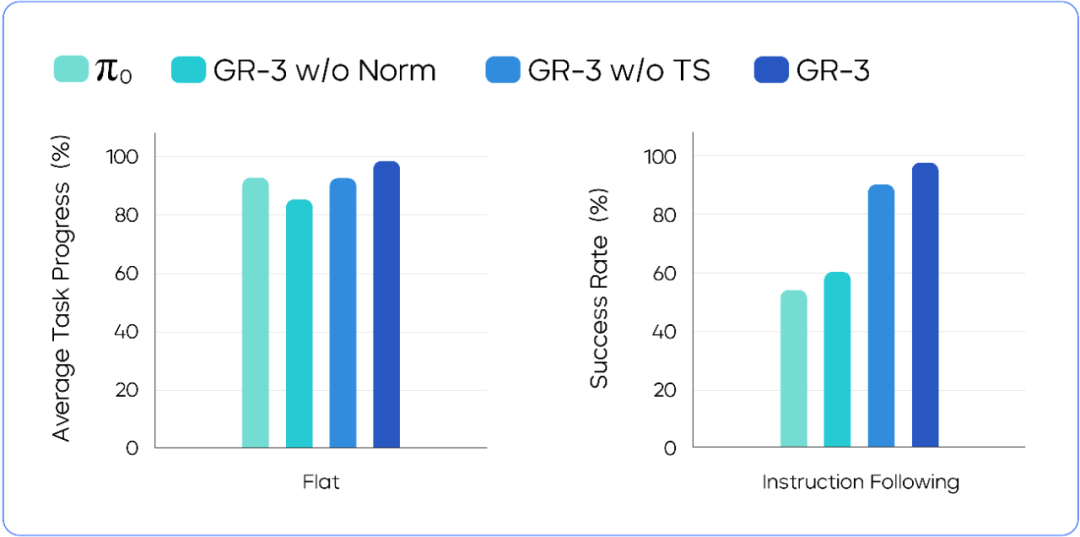
Model performance comparison in long-horizon table bussing and language instruction following
Dexterous Cloth Manipulation: Flexibility
Manipulating deformable objects has been a long-standing challenge in robot manipulation. ByteDance Seed tested GR-3 in the challenging cloth hanging task. In this task, the robot is challenged to place the clothes onto the hanger and then hang the clothes onto the drying rack.
The test reveals that GR-3 achieves an average task progress of 86.7%. Even if the clothes are placed in a messy manner, GR-3 can robustly handle the task.
GR-3 can complete the cloth hanging task when different clothes are randomly placed
In addition, GR-3 can generalize to unseen clothes in the robot training data. For example, GR-3 can effectively handle short-sleeved clothes while all clothes in the robot training data are long-sleeved.

Seen clothes (long-sleeved) and unseen clothes (short-sleeved) in the robot training data during dexterous cloth manipulation, and different layouts of clothes
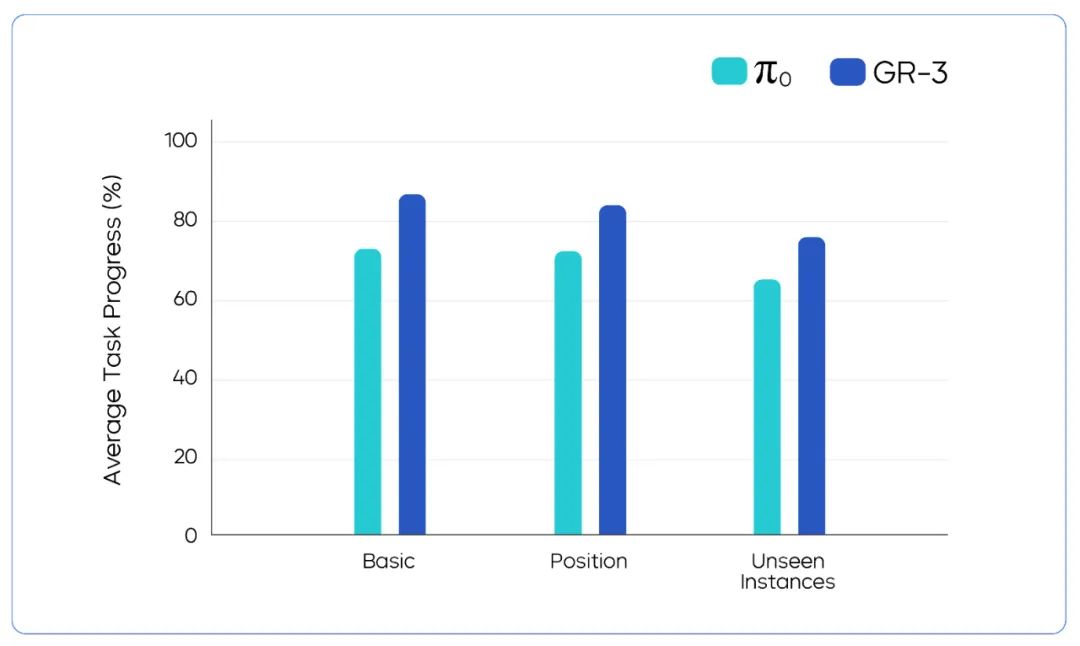
Model performance comparison in dexterous cloth manipulation
Summary and Outlook
ByteDance Seed will consistently explore technical advancements in the robot industry to make large-scale robot manipulation models more reliable, flexible, and intelligent in complex, real-world scenarios. We plan to expand the research in the following aspects:
Scale up the model and training data to further improve generalization. While GR-3 showcases strong generalization capabilities, it makes mistakes in following unseen instructions involving novel concepts and objects, and struggles with grasping objects with unseen shapes. To enhance the capability of GR-3 in generalizing to "unknown" objects and environments, we plan to improve the diversity of training data, such as vision-language data involving more objects and robot data involving more complex tasks, while scaling up model parameters.
Introduce the reinforcement learning (RL) method to overcome the limitations of imitation learning. Similar to most robot models, GR-3 imitates the actions of human experts. When it encounters out-of-distribution situations, such as unexpected object slipping or environmental changes, it may be stuck. To address this issue, we plan to introduce RL for training, allowing robots to consistently learn through trial and error in real-world tasks. By continuously adapting its actions and strategies based on successes and failures, such as quickly re-grasping a slipping object, GR-3 can gradually build stronger robustness and resilience in handling complex, delicate tasks. This approach helps GR-3 go beyond imitation and respond to unexpected changes like humans.
We hope that large-scale robot manipulation models can be widely adopted in daily life and serve as the brain of generalist robots capable of assisting humans with diverse tasks in the real world.