Seedance 2.0 Official Launch
Seedance 2.0 Official Launch
Date
2026-02-12
Category
Models
We recently launched Seedance 2.0, our next-generation video creation model.
Built with a unified multimodal audio-video joint generation architecture, Seedance 2.0 supports four input modalities: text, image, audio, and video. It integrates the industry's most comprehensive set of multimodal content references and editing capabilities available today.
Compared with Version 1.5, Seedance 2.0 delivers a substantial leap in generation quality. It achieves a higher usability rate for complex interaction and motion scenes, with significant improvements in physical accuracy, visual realism, and controllability, making it well-suited for high-quality creation scenarios.
Key highlights
Higher Usability in Complex Scenarios: With outstanding motion stability and physical restoration capabilities, the model performs excellently in multi-subject interaction and complex motion scenes, reaching industry-leading SOTA levels in generation usability.
Greatly Enhanced Multimodal Capabilities: Trained on the unified multimodal audio-video joint architecture, supporting mixed-modality input. Users can simultaneously input up to 9 images, 3 video clips, 3 audio clips, plus natural language instructions. The model can reference composition, motion, camera movement, visual effects, audio and other elements from input assets, breaking the material boundaries of conventional video generation.
Drastically Improved Video Generation Controllability: The model's instruction-following and consistency performance are fully upgraded. It supports stable and controllable video extension and editing, enabling regular users to command the video creation process.
Advanced Content Creation: The model supports 15-second high-quality multi-shot audio-video output and features dual-channel audio for ultra-realistic audio-visual experiences.
Home Page:
https://seed.bytedance.com/seedance2_0
Photorealistic Audio-Visual Experience
Let Audio-Video Generation Turn Imagination into Reality
Powered by major upgrades in foundational capabilities and multimodal performance, Seedance 2.0 brings users an entirely new creative experience.
Seedance 2.0 can generate multi-participant competitive sports scenes — a challenge that previous models struggled to accomplish. Audio effects are more natural and immersive, and input is no longer restricted to text or images alone. The creative workflow becomes more intuitive, allowing users to direct and realize their imagination. Now, we take a closer look at its key capabilities.
1. Stable Rendering of Complex Motions & Interactions, True to Physical Laws
Seedance 2.0 delivers a remarkable leap in generation quality, achieving unprecedented naturalness, smoothness and physical plausibility in human motion modeling.
It can synthesize high-fidelity and precisely timed complex interactive scenes. For instance, in pair figure skating scenarios, the model reliably performs a sequence of high-difficulty movements — including synchronized takeoffs, mid-air spins and precise ice landings — while strictly following real-world physical laws. This eliminates the physical glitches and inconsistencies commonly seen in earlier AI-generated videos.
T2V prompt: Competitive figure skating live performance. Opening with a low-angle shot following the skate blades gliding on ice, with clear details of ice shavings and light reflections. Entering the spin sequence: the male skater makes a minor error due to slight axis deviation, causing a brief disruption in spin rhythm. The female skater quickly adjusts her center of gravity, keeps a calm gaze, and signals "Stay with me" with eye contact, guiding the male skater to regain alignment. This transitions seamlessly into clean, stable lift movements with sharp, consistent body posture. The climax is a synchronized jump combination: upright aerial posture, decisive ice landings, with perfect audio-visual alignment. The female skater wears a deep-blue figure skating dress; the male skater is in competitive athletic attire. The full sequence delivers a complete narrative from tense mistake to calm, successful execution, highlighting the technical skill and mental strength of elite pair figure skating.
In more delicate close-up shots, the visuals generated by the model demonstrate highly realistic details and rigorous physical logic, whether in the subtle shifts of light and shadow refraction, the sense of gravity conveyed as clothing flutters naturally with movement, or the smooth, organic interactions between characters and their environment, making the footage indistinguishable from actual real-world shooting.
I2V prompt: A girl hangs laundry gracefully. After finishing, she takes another piece of clothing from the bucket and shakes it vigorously.
2. Supports Multimodal "All-Round Reference" for Greatly Enhanced Creative Freedom
Seedance 2.0 supports multimodal all-round reference, allowing combined input of various texts, images, videos, and audio. The model can accurately understand multimodal input content and generate output as instructed by referencing elements including visual composition, camera language, motion rhythm, and sound characteristics from the inputs. It can even directly reference text-based storyboards, significantly boosting creative freedom.
R2V Prompt: Refer to the shooting script in @Image 1, and draw on the storyboard, shot scale, camera movement, visuals and copy in @Image 1. The character is from @Image 2, the scene is from @Image 3, and the props are from @Image 4. Create a 15-second healing short film.
3. Greater Controllability, with Precise Adherence to Generation and Editing Instructions
Seedance 2.0 also delivers a substantial upgrade in the controllability of video generation. It excels in instruction following, enabling precise reproduction and stable subject consistency even for complex stories with rich character interactions and detailed action descriptions. Meanwhile, the model features prompt-driven camera planning, allowing it to automatically plan camera language and design visual presentation templates.
T2V prompt: Year of the Horse Spring Festival family footage. The camera quickly pans across a row of solo portraits of family members like flipping through an album, and each photo "comes to life" the moment the camera passes over it: grandpa, grandma, parents, and the kid perform a set of exclusive moves with subtle expressions (such as handing out red envelopes, holding up a plush toy, a cat ringing a bell). Characters are connected smoothly by quick panning like page-turning. As red lanterns and Spring Festival couplets in the background light up dynamically, the scene finally converges into a lively family group photo. All people shout in unison: "Year of the Horse reunion, blessings arrive right away". Sound effects are synchronized with laughter, the atmosphere shifts from warm to jubilant, with natural and flowing light and shadow.
Meanwhile, Seedance 2.0 introduces new video editing capabilities, supporting targeted modifications to specified clips, characters, actions, and storylines. The model also features video extension functionality that can generate continuous shots based on user prompts. It excels not only at video generation but also at "continuing the shoot".
R2V Prompt: Extend the video length. The camera follows a man in orange riding a brown horse. He speeds up and gallops to a large tree with orange flowers ahead, breaks off two blossoms from the branch. Then others ride into the frame one after another. The camera pushes in to shoot the man in orange clothes dismounting from the horse, then the camera quickly circles around him. He turns to walk toward a woman in white riding a white horse and presents the flowers to her. Style: Chinese classical lady painting, 3D, cheerful folk music, shadow puppet style, with black, white, and orange as the main color palette.
4. Two-channel Audio Capabilities with Synchronized High-fidelity, Immersive Sound Generation
Seedance 2.0 has also enhanced its audio capabilities by integrating two-channel stereo technology, enabling high-fidelity, immersive sound generation. The model supports multi-track parallel output for background music, ambient sound effects, and character voiceovers, all seamlessly aligned with the visual rhythm.
T2V Prompt: A Wuxia-style audiovisual blockbuster. A white-clad swordsman and a straw-caped blademaster face off in a bamboo forest. The camera slowly pushes in between them, shifting focus between raindrops and sword hilts. The atmosphere is extremely oppressive; only the sound of rain can be heard. Suddenly, a crack of thunder flashes, and both charge simultaneously. A fast-panning profile shot captures their mud-splattering footsteps. The precise moment their weapons clash, the footage switches to ultra-slow motion, clearly displaying the ring-shaped shockwaves of rainwater blasted away by the blades, along with bamboo leaves sliced by sword aura. Normal speed resumes as they land back-to-back. The straw-caped blademaster's bamboo hat splits open, and the scene cuts abruptly.
Moreover, the model's sound design is highly natural, capturing subtle foley nuances — from the scratch of frosted glass and rustling of plush fabric to gentle tapping on acrylic, or the popping of bubble wrap — making scenes more immersive. Paired with audio-visual timing control, the model achieves seamless alignment between sound and motion, better supporting professional-grade audiovisual content creation.
T2V prompt: Immersive first-person hand ASMR video. Close-up shot, under warm, soft lighting. A pair of slender hands gently triggers different objects in sequence: the light scratching of frosted glass, rubbing of plush fabric, gentle tapping on an acrylic board, light pinching of bubble wrap, and lightly running fingers across a wooden comb's teeth. Finger movements are slow and gentle. Pure, natural trigger sounds with no background music; the visual atmosphere is relaxing and healing.
5. Broad Scenario Adaptability: Lower the Barrier to Content Production
Addressing the diverse needs of video production, Seedance 2.0 demonstrates immense scenario adaptability. Whether it's commercial advertising, or explainer videos, the model delivers high-quality generation results.
I2V Prompt: The character in the painting looks guilty, darting glances left and right before leaning out of the picture frame. Very swiftly, they extend a hand outside the frame, grab a cola, take a sip, and reveal a look of deep satisfaction. Hearing footsteps approach, the character hastily puts the cola back just as a Western cowboy walks by and picks it up. The ending shot pushes in on a top-lit close-up of the cola against a pure black background, with artistic subtitles and a voiceover appearing at the bottom: "Yikou Cola, an absolute must-try!"
T2V Prompt: 1920s jazz club-style Charleston dance. A female dancer in a gold fringe dress and a male dancer in a striped suit perform a high-intensity routine. Moves include hyper-fast syncopated footwork, aerial catches, and exaggerated arm swings. The camera uses dynamic tracking, interspersed with close-ups of footwork. Emphasis is on physical details: the fringe swinging wildly with every kick, the sheen of sweat on their skin, and the smoky, vintage film grain cinematic texture. A background jazz band and cheering audience amplify the frenzied party atmosphere.
*Note: The generated videos featuring character references in the above demos are solely for the purpose of demonstrating model capabilities; the referenced subjects are either AI-generated or properly licensed. If you wish to use real human portraits as subject references for video generation, identity verification or prior legal authorization is required.
Seedance 2.0 Evaluation Results
Industry-Leading Overall Performance
To objectively and comprehensively evaluate Seedance 2.0's overall capabilities across multimodal scenarios, the team worked with experts to build an evaluation dataset and standards covering audio/video generation, referencing, and editing. This evaluation mainly examines the model's performance in multimodal reference generation, complex audio/video instruction following, complex motion stability, natural language, audio/visual expressiveness, and audio-visual synergy.
1. Text-to-Video and Image-to-Video Evaluation
In the video dimension, Seedance 2.0 is at the forefront of the industry. It shows significant improvements in motion stability, instruction following, and visual aesthetics, effectively addressing structural inaccuracies and visual artifact (breakdown) issues, while rendering complex movements smoothly and delicately. The model accurately captures high-tension, large-scale action alongside subtle micro-expressions, and supports professional-grade combinations of camera movements and narrative pacing control. For long scripts and open-ended instructions, the model responds well and extrapolates logically. Furthermore, its generated videos possess a distinct aesthetic; the textures of objects, lighting, and composition. However, Seedance 2.0 still requires ongoing refinement in detail stability, hyper-realism, and dynamic vitality.
In the audio dimension, Seedance 2.0 continues its strong performance with a massive boost in audio expressiveness. Its dual-channel audio is rich and nuanced, capable of matching the scene with sound effects or melodies that best fit the prompt's context. Compared to the previous version, the unified audio-visual experience is further enhanced—dialogue, sound effects, background music, and visual content mesh far better. Meanwhile, its instruction response accuracy for Chinese dialects, traditional opera, and singing scenarios has markedly improved. That said, Seedance 2.0 still needs to address issues like occasional audio distortion.
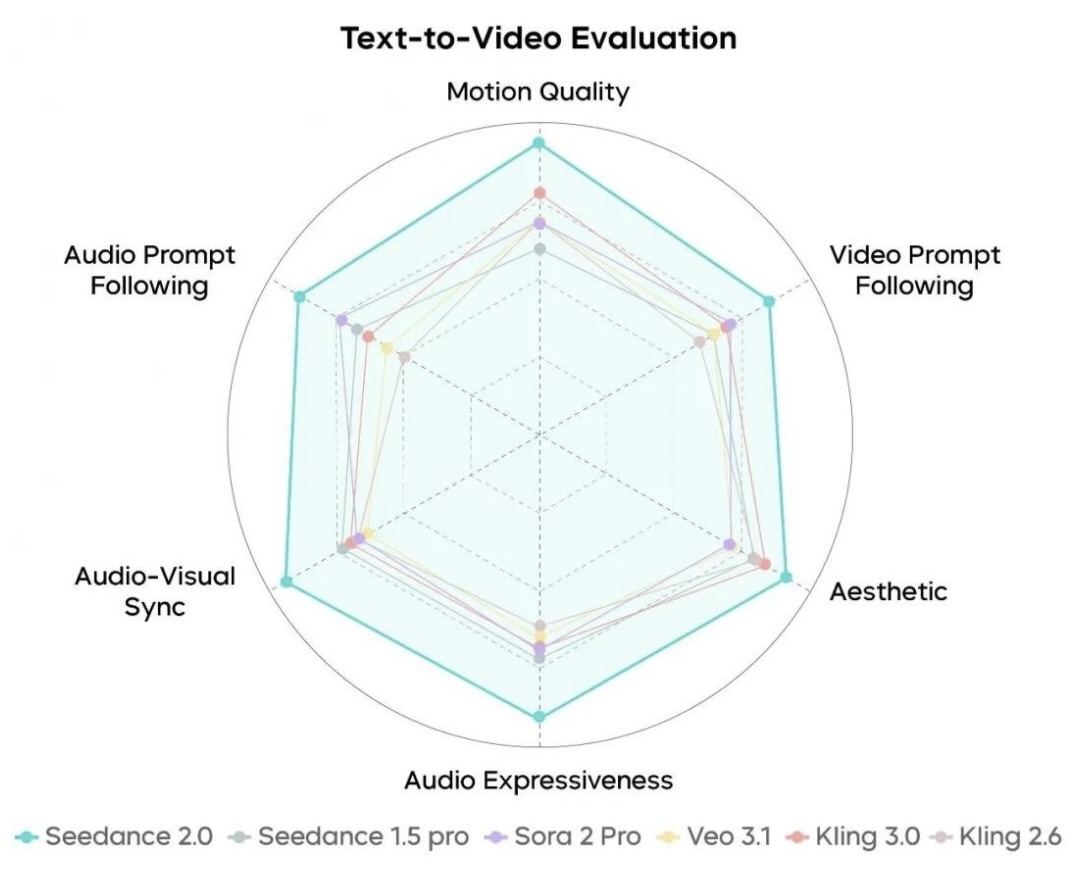
Seedance 2.0 Text-to-Video Capability Evaluation
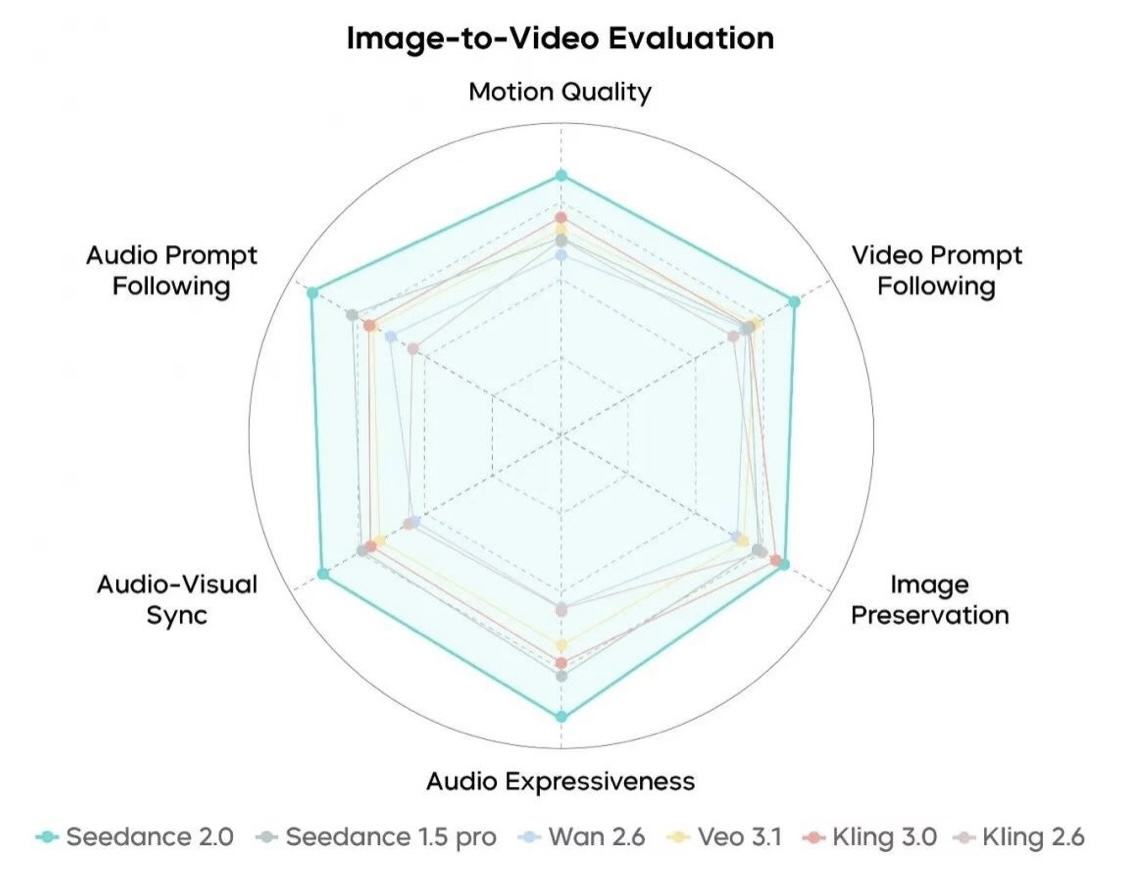
Seedance 2.0 Image-to-Video Capability Evaluation
2. Multimodal Reference Generation Evaluation
Seedance 2.0 boasts industry-leading overall performance. The model covers a broader range of reference tasks, supporting diverse creative scenarios such as multimodal reference generation, video editing, and video continuation. It holds a distinct advantage in its depth of comprehension and response accuracy toward reference content. In editing tasks, compared to other models, Seedance 2.0 executes instructions more comprehensively and generates more realistic visuals. In terms of consistency, the model performs exceptionally well in preserving subject appearance and voice, dominating particularly in maintaining the logical flow of actions, a variety of styles, and plot narratives. However, there is still room for optimization regarding multi-subject consistency, text rendering accuracy, and complex editing effects.
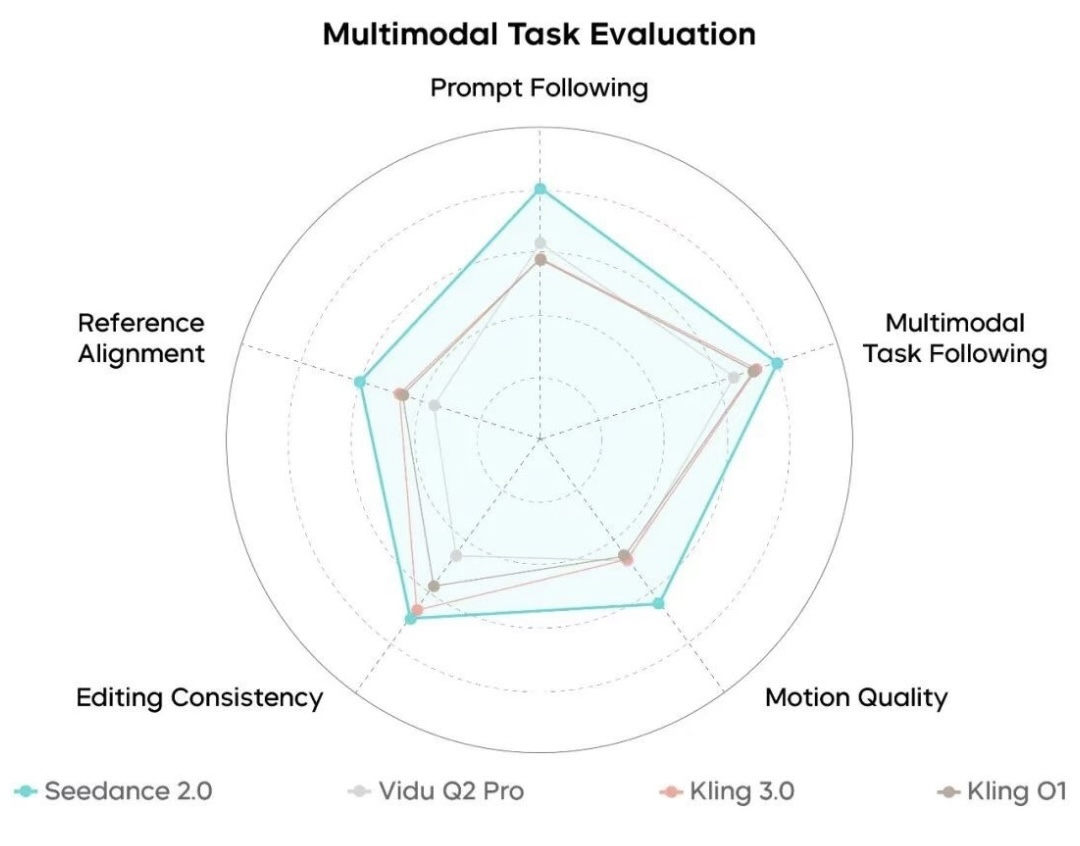
Seedance 2.0 Multimodal Task Performance Evaluation
Conclusion and Outlook
From the "synchronized audio-visual generation" in Seedance 1.5 to the "unified multimodal audio-video generation" in Seedance 2.0, the Seedance series has consistently pursued faithful real-world replication through an ultimate, unified algorithmic framework. Relying on extensive world knowledge, the efficiency of a sparse architecture, and the powerful generalization capabilities from multimodal joint training, this iteration resolves long-standing challenges in adherence to physical laws and long-term consistency. At the same time, it grants creators unprecedented freedom, elevating the quality and controllability of audio-video generation to meet top notch standards.
However, Seedance 2.0 is still far from perfect, with various flaws remaining in its generation results. We will continue to explore deep alignment between large models and human feedback, striving to deliver a more efficient, stable, and imaginative audio-video production tool to serve more creators.