Seedream 4.0 Officially Released: Beyond Drawing, Into Imagination
Seedream 4.0 Officially Released: Beyond Drawing, Into Imagination
Date
2025-09-09
Category
Models
Seedream 4.0, a new-gen image creation model developed by the ByteDance Seed team, is now officially available.

Seedream 4.0 features a unified architecture that enables both text-to-image generation and general-purpose editing, integrating commonsense knowledge and reasoning capabilities. Compared to its predecessors, Seedream 3.0 and SeedEdit 3.0, it represents a significant breakthrough in multimodal performance, speed, and usability:
Expanded multimodal capabilities: It accepts text, images, or any combination as input, supporting diverse modes including text-to-image generation, image-to-image translation, single-image editing, multi-image editing, and image composition for creative ideation.
Optimized aesthetic styling: It allows seamless switching between artistic styles—from Baroque to Cyberpunk—and supports the blending of different styles to create entirely new ones with striking visual impact.
-
Enhanced logical understanding: Leveraging world knowledge, it enhances the understanding of multimodal inputs. It doesn't just "draw"—it "thinks" first. The model demonstrates impressive reasoning generation capabilities in tasks involving physical and temporal constraints, such as solving puzzles, completing crosswords, and continuing comic strips.
-
Self-adaptation and 4K generation: It can generate images in the optimal aspect ratio based on instructions or reference images, while also supporting custom sizing. The maximum resolution has been increased from 2K to 4K ultra-high definition.
-
Increased reasoning speed: It features a novel, efficient architecture and employs excellent distillation acceleration techniques, enabling its Diffusion Transformer (DiT) image generation model to achieve a reasoning speed more than 10 times faster than that of Seedream 3.0.
In comprehensive evaluations, Seedream 4.0 achieved outstanding results, with its core capabilities ranking among the best in the industry. Seedream 4.0 is now officially available on our platforms. Feel free to try it out!
Model Homepage: https://seed.bytedance.com/seedream4_0
From an Image Generator to a Creative Engine
Unlocking a Whole New Experience in Visual Creation
Seedream 4.0 is more than just an image generation model—it's an all-around multimodal creative engine. Leveraging the latest capabilities of Seedream 4.0, we have rolled out eight basic features, unlocking its potential in derivative creation, reasoning generation, and specialized applications on top of standard image generation and editing.
1. Precise Editing
Seedream 4.0 excels in image editing, requiring only text prompts for high-quality modifications. It adds, removes, modifies, and replaces elements with precision. When tackling complex tasks like background replacement and portrait retouching, it can keep images cohesive and intact while producing realistic and detailed outputs.
This feature is essential for scenarios such as advertising design, e-commerce retouching, and film post-production, greatly cutting down on the cost of manual adjustments.
Whether it's realistic photography, pop art, cyberpunk, or traditional Chinese style, Seedream 4.0 delivers high-quality images with aesthetic appeal. As shown in the video, Seedream 4.0 freely switches between over 30 distinct artistic styles and scenes, effortlessly changing backgrounds, outfits, and accessories while keeping the female protagonist's facial features consistent.
2. Flexible Reference
Unlike editing, the challenge of reference generation lies in how to strike a trade-off between preservation and creation. Seedream 4.0 can extract key information from reference images, such as character identities, artistic styles, or structural features, and then recreate them in entirely new scenes.
For example, Seedream 4.0 can generate character images in different styles from a single portrait or convert a 2D sketch into a 3D drawing. This feature makes it highly promising in virtual avatar generation, derivative design, and secondary creation.

Prompt: Create an anime character figurine based on this image, and place it on a desk; behind the figurine, add a birthday gift box featuring the character's image; put a book under the box and add a circular plastic base in front to stand the figurine; set the scene indoors and make it as realistic as possible; generate the image with the same dimensions as the current one; position the figurine on the left side of the output image; ensure the overall style of the image matches the original.
3. Visual Signal Controllable Generation
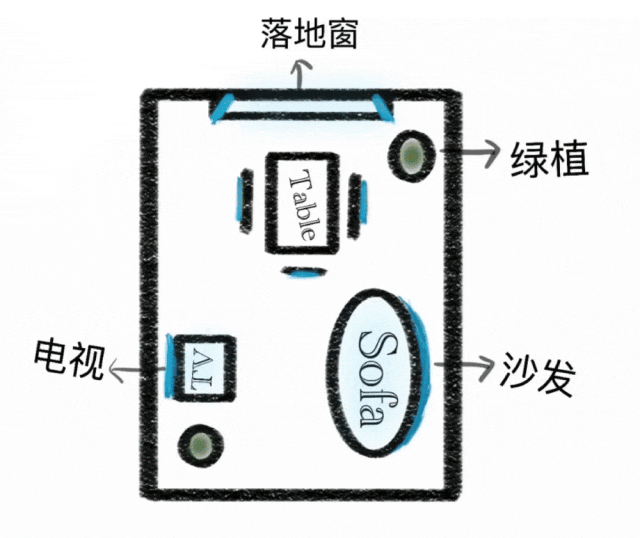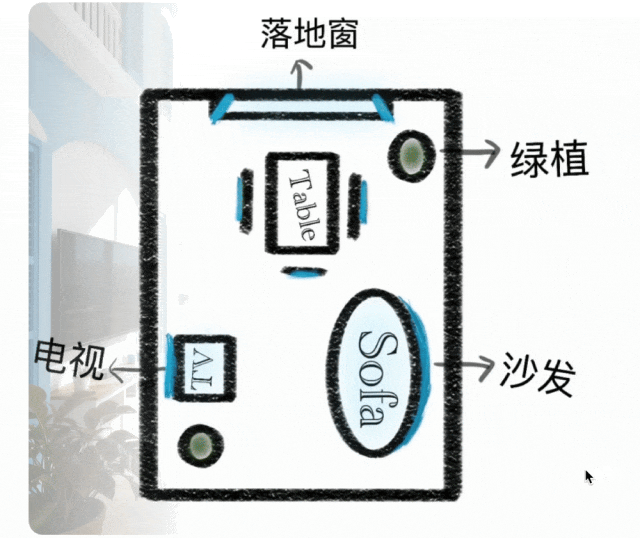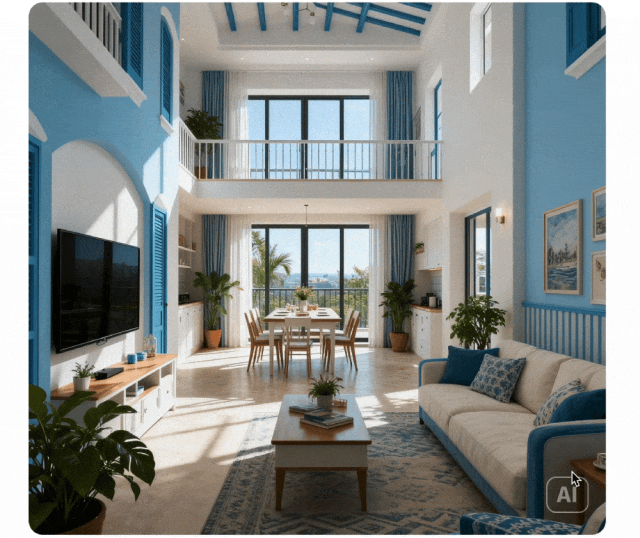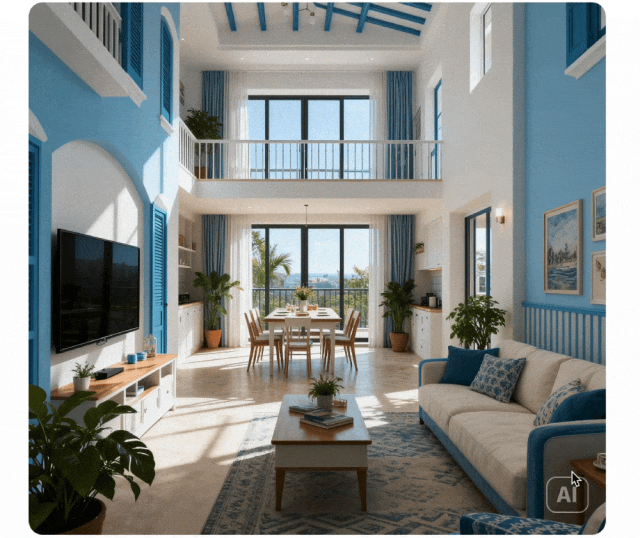
Prompt: Generate a photorealistic image depicting a modern minimalist hardcover living room and an open dining area from this floor plan; the room layout and furniture placement must exactly match the floor plan. Use a Mediterranean-style color scheme, ensuring the spatial structure and orientation remain consistent with the floor plan. The room should appear three-dimensional, spacious, and with high ceilings. Sunlight should illuminate the dining table area. From near to far, the scene should include a sofa and green plants, a TV, a dining table and chairs, and floor-to-ceiling windows. Do not include any text or hand-drawn edges. Ensure the image orientation matches the floor plan without mirroring. Note that the shorter side of the dining table should face the floor-to-ceiling windows. The placement of the green plants must exactly match the original floor plan.
4. In-Context Reasoning Generation

Prompt: As 11 hours and 15 minutes pass, the time on the clock and the lighting in the room change accordingly.
5. Multi-Image Reference Generation

Prompt: A supermodel wearing a white gown and a plain silver wide-band bracelet stands with one hand holding a silver bag and the other holding binoculars to her eyes; her chin is slightly lifted as she leans against a silver, futuristic motorcycle; in the background, a desert scene unfolds, with a few silver parachutes floating in the sky.
6. Multi-Image Output

Prompt: Refer to this logo to create a set of visual designs for an outdoor sports brand named "GREEN." The collection should include items like packaging bags, hats, cards, wristbands, paper boxes, and lanyards. The primary visual tone should be green, featuring a minimalist and modern style.
7. Advanced Text Rendering

When receiving the same prompt to generate a hand-drawn sketch of a delivery robot, Seedream 4.0 delivers finer text rendering and layout than Seedream 3.0.
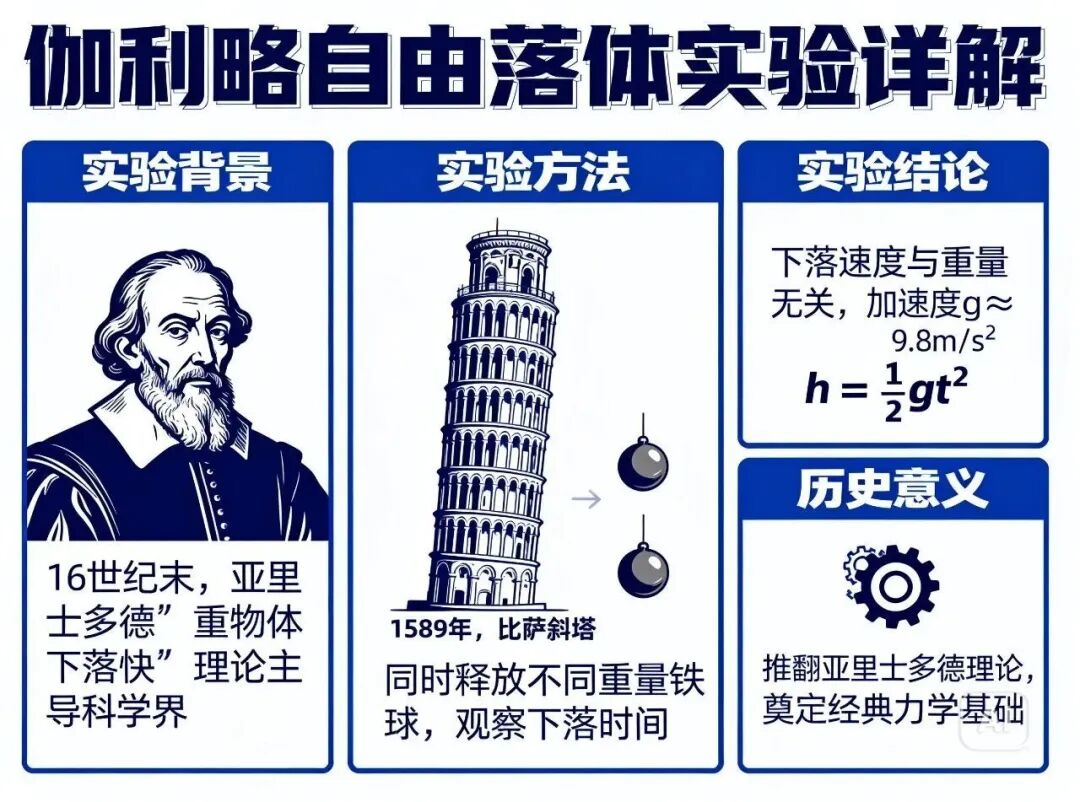
An infographic generated by Seedream 4.0, depicting Galileo's gravity experiment. It features scientific text, diagrams, and basic physics formulas, all arranged in a neat column-based layout.
8. Adaptive Aspect Ratio & 4K Generation

When receiving the same prompt to generate a poster with visual imagery, Seedream 4.0 outputs a 4K image, delivering richer and finer details than Seedream 3.0.
Comprehensive Evaluation Results of Seedream 4.0
Leading in Aesthetics, Text Rendering, and Other Core Metrics
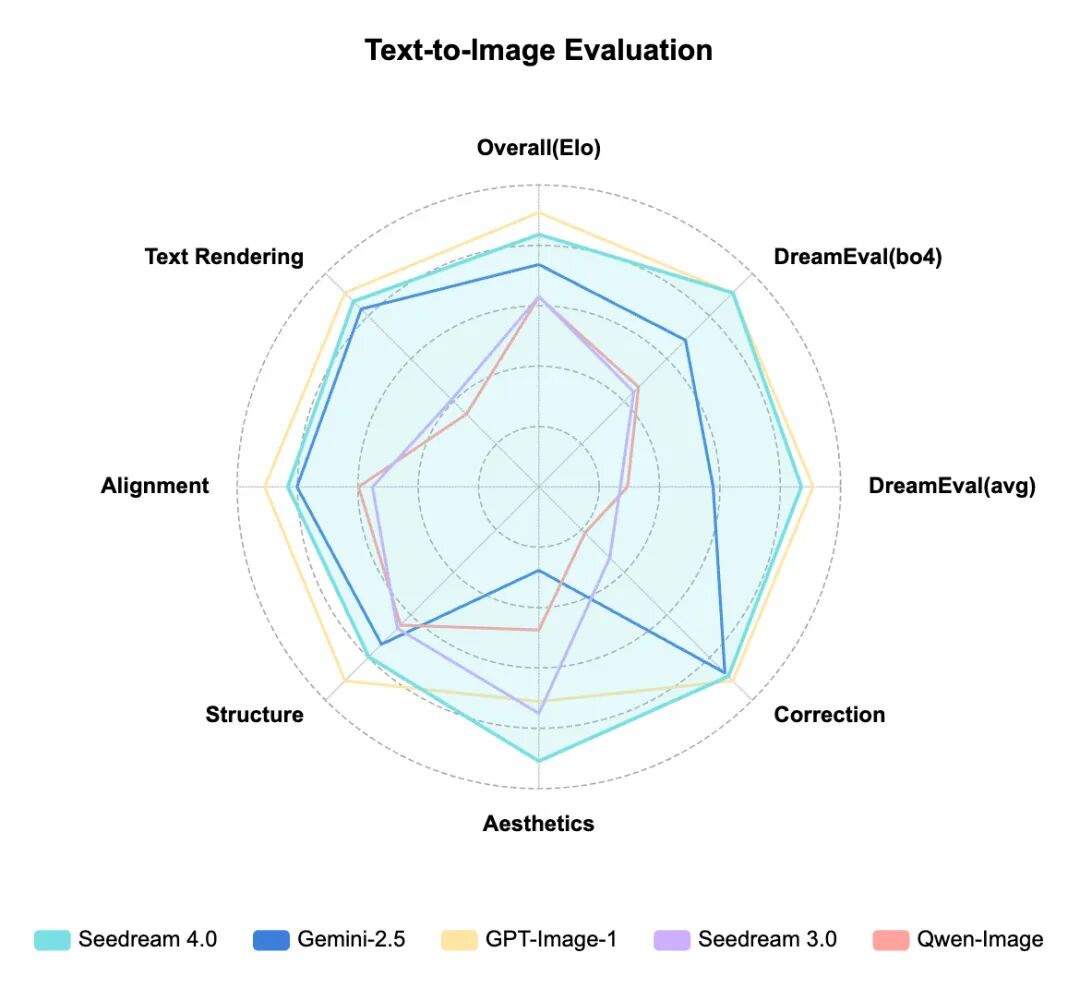
Comprehensive Evaluation of Text-to-Image Generation
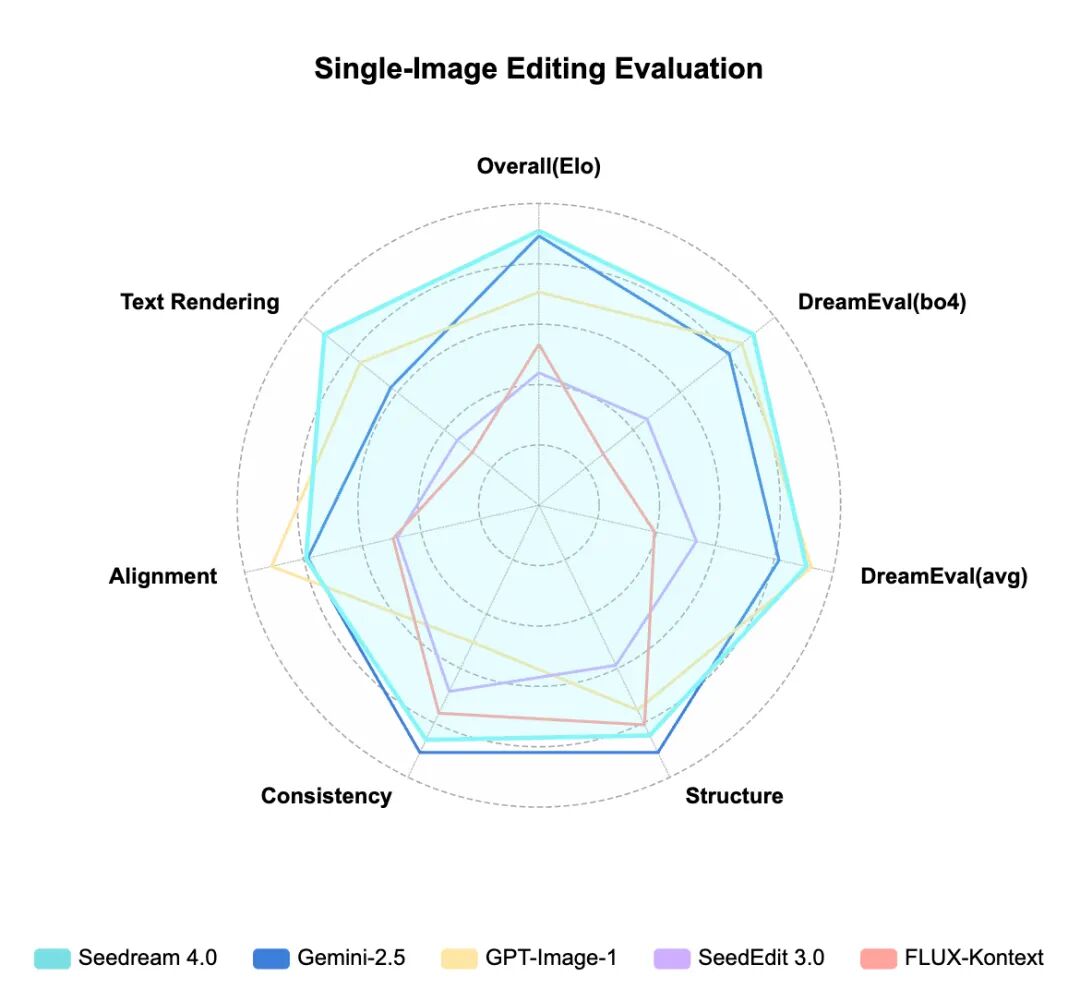
Comprehensive Evaluation of Image Editing
Joint Training of Generation and Editing
Boosting Generalization for Complex Tasks
In terms of multimodality, Seedream 4.0 achieves the integration of text-to-image generation and editing within a unified architecture, enabling mutual enhancements through joint training.
Integrated generation and editing: The ByteDance Seed team has integrated Seedream 3.0's text-to-image generation and SeedEdit's image editing into a unified architecture, allowing the model to perceive data of different modalities, such as text prompts and reference images, while maintaining superior image quality and high feature consistency.
-
Efficient model architecture: Seedream 4.0 features a carefully designed DiT architecture and a high-compression-ratio variational autoencoder (VAE). This combination allows its DiT model to achieve a more than tenfold increase in both training and reasoning speed compared to Seedream 3.0, while also demonstrating exceptional efficiency and scalability across multimodality, task coverage, and context control.
-
Enhanced multimodal understanding: Seedream 4.0 achieves high-performance multimodal understanding based on a fine-tuned SeedVLM model. Leveraging the visual-language model's extensive world knowledge, Seedream 4.0 can further expand input prompts.
-
Multimodal data pipeline: The ByteDance Seed team has developed a large-scale, extensible multimodal data processing pipeline. Incorporating techniques such as video frame extraction, HTML-based data retrieval and filtering, and data synthesis via mixture of experts (MoE) models, this pipeline enables rapid and efficient construction of large-scale, high-quality editing data pairs. This robust data foundation significantly enhances the model's editing and generation capabilities.
-
Joint training framework: The ByteDance Seed team jointly trained Seedream 4.0 on both editing tasks and text-to-image generation tasks throughout all post-training stages, such as continuing training (CT), supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF). Additionally, the team designed reward models from multiple aspects for the RLHF stage. According to the experiment data, joint training yields much better results than separate single-task training, boosting the model's performance in instruction following, image quality, and aesthetic appeal.
To facilitate the large-scale application of high-quality generation, the ByteDance Seed team has implemented multi-level optimization in the reasoning process, including thorough improvements to the algorithms and hardware.
Adversarial distillation: Through distribution alignment between student and teacher models, the small (student) model learns generation paths from the large (teacher) model to ensure stability in reasoning scenarios involving only a few steps. This effectively reduces distortion issues in diffusion models during fast sampling.
-
Distribution matching: Instead of using a fixed Kullback-Leibler (KL) divergence, the ByteDance Seed team has introduced a learnable discriminator to improve the fitting accuracy of complex distributions. This way, sampling within 10 steps yields the same results as conventional 50-step sampling.
-
Quantization and sparsification: Seedream 4.0 employs both 4-bit quantization and 8-bit quantization, coupled with offline smoothing and layer-wise search, to ensure optimal model performance across various hardware. Our self-developed operators are adaptable to various precisions, which further unlocks computational power.
-
Speculative decoding: Seedream 4.0 predicts the probabilistic trajectory of future tokens during sampling, addressing the latency caused by uncertainty in diffusion sampling. Meanwhile, the ByteDance Seed team has improved the cache reuse rate by introducing loss functions into the KV cache, greatly slashing the reasoning time.
With this suite of acceleration techniques, Seedream 4.0 can generate high-quality 4K images when needed, or produce 2K images in just a few seconds through efficient reasoning—achieving an optimal balance between quality and efficiency.