Sound and Vision, All in One Take | The Official Release of Seedance 1.5 pro
Sound and Vision, All in One Take | The Official Release of Seedance 1.5 pro
Date
2025-12-16
Category
Models
Under a spotlight, a character on center stage sings in the soaring style of a female Peking opera role while executing a sequence of spear movements in time with a drumbeat. This scene wasn't performed by an actor, but is a creative clip generated by Seedance 1.5 pro in a single take. Though its performance is not yet on par with professional opera, its grasp of vocal prosody shows clear potential.
Note: The character's vocal delivery, makeup, costumes, movements, and postures in the generated video still deviate significantly from the standards of traditional opera standards. The dialogue is also not based on traditional librettos. This clip serves only as a tentative exploration of how AI technology can engage with the aesthetic realm of Chinese opera.
Seedance 1.5 pro features joint audio-visual generation, capable of executing a range of tasks, including synthesizing audio-video content from text prompts and generating it through image-driven processes. This evolves Seedance models beyond the purely visual, allowing them to seamlessly integrate sound into video generation.

While Seedance 1.0 focuses on improving the "performance floor" of model performance by enhancing the stability of motion generation, Seedance 1.5 pro now aims higher. Beyond its new audio-synchronized generation capability, it also strives to elevate the "performance ceiling" of visual impact and motion effects. By adopting more audacious technical approaches, Seedance 1.5 pro has achieved breakthroughs in audio-visual synergy, visual impact, and narrative coherence.
- Precise Audio-Visual Synchronization and Multi-Language and Dialect Support: The model demonstrates high audio-visual consistency during generation, significantly improving the alignment accuracy of lip movements, intonation, and performance rhythm. With native support for multiple languages and regional dialects, it accurately captures their unique vocal prosody and emotional tension.
- Cinematic Camera Control and Dynamic Tension: The model possesses autonomous cinematography capabilities, enabling the execution of complex movements such as continuous long takes and dolly zooms (Hitchcock zoom). Additionally, it achieves cinematic scene transitions and professional color grading, substantially enhancing the dynamic tension of the video.
- Enhanced Semantic Understanding and Narrative Coherence: Through strengthened semantic understanding, the model achieves precise analysis of narrative contexts. It significantly improves the overall narrative coordination of audio-visual segments, providing strong support for professional-grade content creation.
Seedance 1.5 pro has demonstrated leading performance in comprehensive benchmarks, placing its key capabilities among the best in the industry. It is now publicly available. Feel free to try it out and share your feedback.
Model Card: https://arxiv.org/pdf/2512.13507
Model Homepage: https://seed.bytedance.com/seedance1_5_pro
Beyond Audio-Visuals, Embracing Narrative Storytelling
Evolving from Content Generation to Artistic Expression
Seedance 1.5 pro advances beyond generating simple content clips, treating video and audio as one integrated whole to serve diverse creative needs. With its strengths in audio-visual synergy, dynamic control, and cultural awareness, it achieves compelling narrative expression and seamless audio-visual fusion across scenarios such as film and television production, short-form drama generation, advertising content creation, and opera performances.
Next, we will break down how Seedance 1.5 pro facilitates professional creation through specific use cases.
1. Enabling Cinematic Creation with Detailed and Continuous Storytelling
Seedance 1.5 pro has achieved significant improvements in semantic understanding, enabling it to decipher nuanced and complex human emotions and translate them into expressive artistic representations. With high-precision audio-visual synergy, the model can deeply integrate speech, imagery, and contextual atmosphere to generate finely detailed and coherent outputs, thereby enhancing the narrative impact of the content.
In close-up shots, the model demonstrates a refined ability to capture subtle emotions. Even without dialogue, it can sustain emotional buildup through delicate facial expressions. For example, in the generated cinematic-style cyberpunk video below, the model can infer the story context based on the prompt and precisely portray the character's emotional journey, ensuring the emotional transitions are natural, multi-layered, and in harmony with the environment and musical ambiance.
Note for viewing demo: Turn up the volume for a better experience.
Text-to-video prompt: A cyberpunk scene set in ruins, featuring an interplay of cool and warm light. A handheld shot tracks a young East Asian woman. A close-up on her repressed grief and tear-filled eyes transitions to a micro-expression of gentle resolve as her face is bathed in the golden light of sunrise. The character's skin should have an authentic film grain texture, with a shallow depth of field creating a soft-focus background.
Beyond generating single, impactful shots, Seedance 1.5 pro can also construct a narrative sequence of multiple camera shots based on a single prompt. For example, when creating an anime scene, the model can produce a continuous sequence showing fireworks, a couple confessing their feelings in Japanese, and an emotive vocal performance, all woven together with fluid narrative logic.
Text-to-video prompt: Anime-style summer fireworks festival, with fireworks casting a gentle contour light. The shot pushes in from a wide view of the fireworks to the male and female leads in yukata among the crowd, then cuts to a close-up capturing the girl steeling herself to confess. The boy bashfully starts, "実は... (Actually...)" but the girl beats him to it, confessing, "大好きです (I love you)." As they express their feelings, they share a close embrace. The sounds of fireworks, crowd ambiance, and Japanese dialogue blend together, creating a romantic and cohesive narrative atmosphere.
2. Catering to Demanding Scenes with Professional Camera Control and Dynamic Tension
With enhanced camera control and dynamic tension, Seedance 1.5 pro is now better equipped to generate visually complex and challenging scenes.
The model can more smoothly render high-dynamic, high-impact motion scenes. In the skiing video below, through the synergy of sound and visual motion, Seedance 1.5 pro creates a strong sense of immersion: The camera makes fast lateral cuts closely following the skier's trajectory and captures the moment of snow bursting into the air with fine detail, authentically recreating the speed and power of the extreme sport.
Image-to-video prompt: A skier, clad in professional gear, demonstrates agile techniques against a backdrop of snowy mountains. The shot follows the skier down the slope with a long, low-angle take, capturing the carving turn and the instant when snow bursts into the air. It then quickly cuts to a slow-motion close-up before tracking the skier as they exit the turn. The background music features upbeat Future Bass, complemented by whooshing wind sounds, creating an overall vibrant and energetic atmosphere.
The model also features autonomous camera scheduling capabilities, enabling the execution of complex movements for generation scenarios demanding high precision. For example, when simulating a red carpet premiere scene, the model can generate rapid panning shots that convey the scene's hustle and bustle. Coupled with the female subject's clear narration, this effectively recreates the ambiance of the event.
Text-to-video prompt: An Asian fashion blogger in an evening gown appears on the red carpet, exclaiming excitedly, "The air is thick with the scent of perfume and ambition! The red carpet tonight is like a live show of fashion history. Follow me, and let's go capture that show-stopping moment!"
In the generated promotional video for a robotic vacuum cleaner, the camera slowly pushes forward in a commercial style and closely tracks the movement of the robot, maintaining strong focus on the product itself.
Text-to-video prompt: In a modern, minimalist mansion, the reflection of the setting sun glimmers on a marble floor. A premium black floor washer machine works autonomously, its soft blue light scanning for dust. Camera work involves a low-angle tracking shot that follows the machine closely at floor level, highlighting its sleek, streamlined contours. The audio includes a female AI narration: "It's the dust you can't see that triggers allergies. With laser dust detection and intelligent power adjustment, we give you back the freedom of walking barefoot on your floors."
3. Enhancing Comedy and Other Stylized Performances with Support for Multiple Languages and Dialects
Seedance 1.5 pro supports multilingual speech generation, capable of rendering the vocal prosody of languages such as Chinese, English, Japanese, Korean, Spanish, and Indonesian with relative naturalness. Particularly in Chinese contexts, the model can also simulate various regional accents, including Sichuanese and Cantonese, providing more authentic performance quality for short dramas and other entertainment content.
For example, if a panda is munching on bamboo and suddenly turns to the camera to complain in a Sichuan dialect, the model can align its facial expressions with the dialect's unique prosody, breathing vivid life into the video.
Text-to-video prompt: Realistic, high-end footage. In a bamboo grove, a real panda is munching on bamboo, but abruptly stops to complain in Sichuanese: "今天的竹子咋有点老哦!啷个的喃?有点造孽哦~ (This bamboo is a bit tough today! What's up with that? This is a raw deal!)" Then, the camera does a quick push-in to a tight close-up as the panda tilts its head, gives a sly grin, and leans in to whisper: "喂,摄像的大哥,帮我点个外卖要得不!要微辣的哈!(Hey, Mr. Cameraman, can you order me some delivery? Make it just a little spicy!)".
4. Boosting Immersion in Gaming and Other Audio-Visual Content with Precise Sound Effect Generation
Beyond human voices, Seedance 1.5 pro demonstrates a solid understanding of ambient sound effects and musical atmosphere. It can layer ambient sounds based on the on-screen visuals to create spatial awareness, achieving a "what you see is what you hear" effect.
In a pixel-art game clip, the model not only provides fluid camera work that follows the character's running and jumping but also generates 8-bit sound effects in sync with the scene, demonstrating its audio-visual synergy in fast-paced action.
Text-to-video prompt: 8-bit pixel art style. A hero is running and jumping against the sunset, complete with a scanline effect and a retro video game soundtrack.
In a 3D-style game clip, the model generates a richly detailed open world. As the character moves, footsteps and breathing sounds are precisely synchronized, complemented by the distant, low cawing of crows, enhancing the immersive experience of audio-visual interaction.
Image-to-video prompt: A 3D game CG video. A man in a leather jacket explores the ruins of an abandoned church. He pauses cautiously, then dashes forward after ensuring the coast is clear, stopping abruptly at an archway to survey his surroundings. The shot uses backlighting from a high window on the left, presented in warm sepia tones. The audio precisely layers footsteps, heartbeat sounds, and owl calls, complementing the tense background music to create a suspenseful atmosphere.
Leveraging these capabilities, Seedance 1.5 pro provides powerful support for genre-specific creation such as films, ads, short dramas, and anime. Especially in image-to-video tasks, the model demonstrates robust style consistency, effectively maintaining stable character features during multi-shot transitions and complex movements, thereby improving the coherence from raw footage to final production.
Seedance 1.5 pro Performance Evaluations
Excellent Prompt Adherence and Audio Performance
For an objective assessment of the model's comprehensive capabilities, we created the SeedVideoBench 1.5 benchmark. Its evaluation standards, co-developed by film directors and technical experts, place a strong emphasis on various visual evaluation metrics (prompt following, motion stability and vividness, and aesthetic quality) and audio evaluation metrics (audio prompt following, audio-visual synchronization, audio quality, and audio expressiveness).
Regarding video generation, compared to other models in the comparative evaluation, Seedance 1.5 pro shows a more precise understanding of complex instructions for actions, camera work, etc. It can better match the narrative and visual style set by the prompt. The evaluation reveals that Seedance 1.5 pro demonstrates relatively rich and lively motion, vivid facial expressions in close-ups, and complex camera movements that are relatively smooth and naturally unified with the style of reference images, resulting in an overall visual texture that is closer to live-action footage. However, there is still potential for improvement in motion stability.
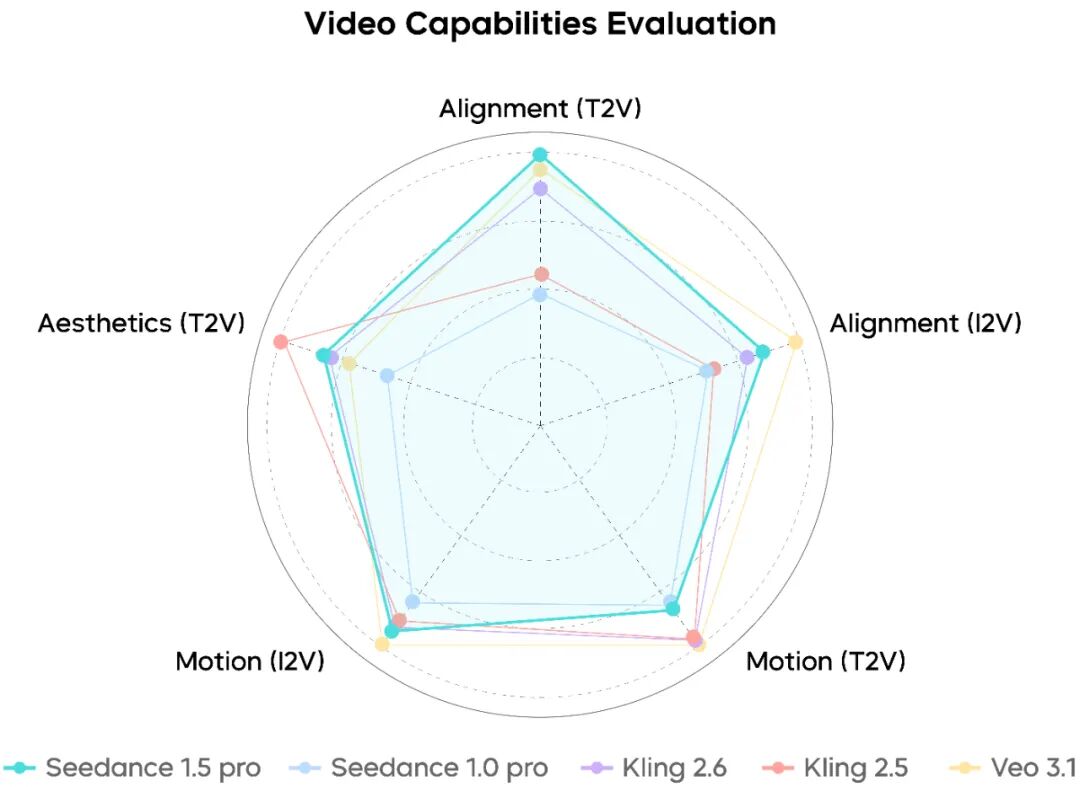
Performance Evaluation: Video Generation Capabilities of Seedance 1.5 pro
Regarding audio generation, Seedance 1.5 pro ranks among the top-tier industry models. It demonstrates stable and well-rounded performance across key dimensions such as audio prompt following, audio-visual synchronization, audio quality, and audio expressiveness. The model can relatively accurately generate appropriate human voices and specified sound effects, particularly excelling in Chinese dialogue scenarios with high completeness and clear pronunciation, while also being capable of responding to various dialect-based prompts.
Compared to the competing models, Seedance 1.5 pro produces more natural and less robotic-sounding voices. Its sound effects exhibit a realistic quality and spatial reverb that closely resemble real-world scenarios, alongside a notable reduction in audio-visual misalignment. Although further improvements are needed for multi-character dialogues and singing scenarios, the model's overall capabilities already make it suitable for certain applications in narrative contexts such as short dramas, stage performances, and cinematic storytelling driven by Chinese or dialect-based dialogue.
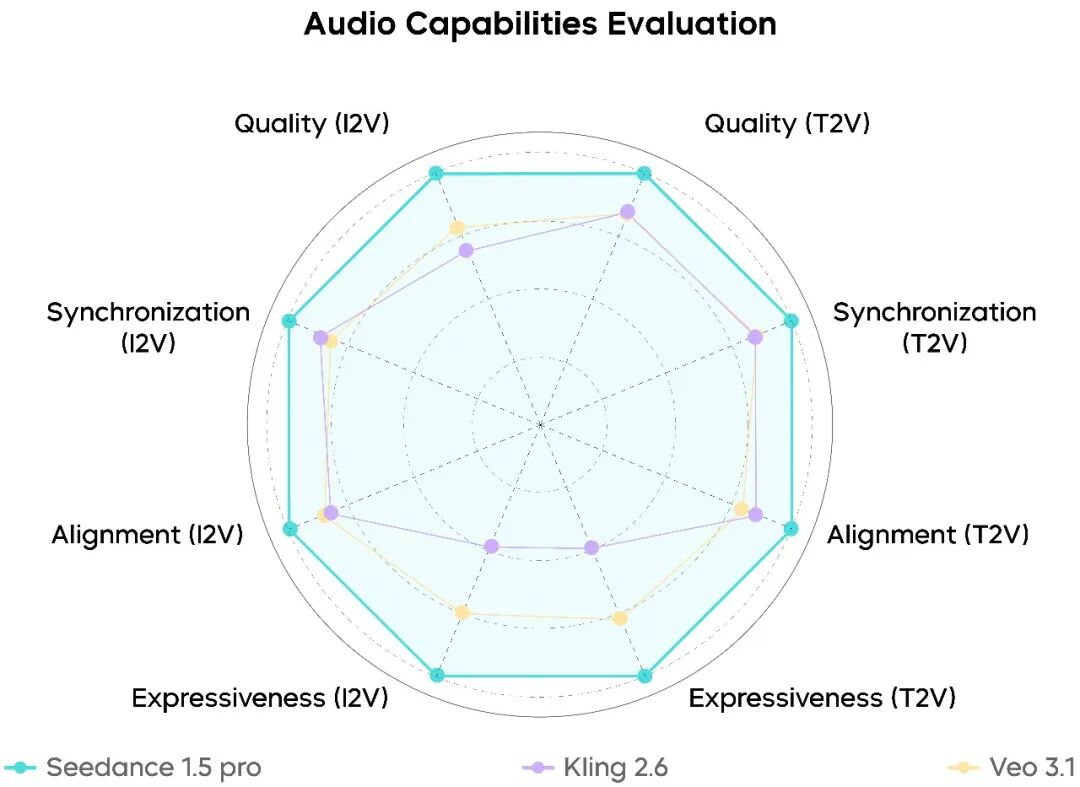
Performance Evaluation: Audio Generation Capabilities of Seedance 1.5 pro
Unified Multimodal Joint Generation Architecture
Enabling Precise Aduio-Visual Stream Synergy
Seedance 1.5 pro is built on a foundation model designed for joint audio-visual generation. Through a comprehensive restructuring of the underlying architecture, data pipeline, post‑training stage, and inference stage, the model's generalization capability across a wide range of complex tasks has been significantly enhanced.
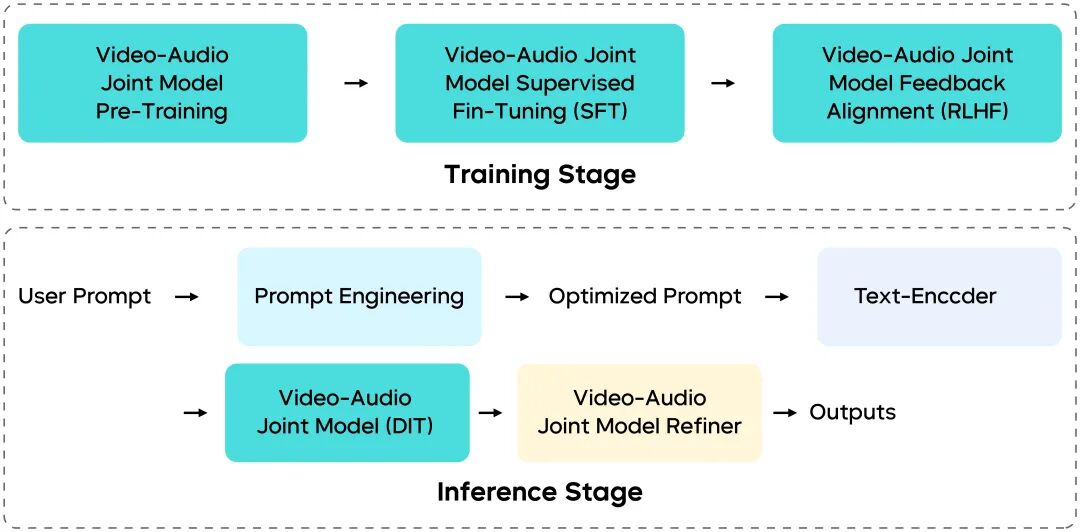
Overview of Training and Inference Pipeline of Seedance 1.5 Pro
- Unified Multimodal Architecture: We proposed a unified framework for joint audio-visual generation based on the MMDiT architecture. This design facilitates deep cross-modal interaction, ensuring precise temporal synchronization and semantic consistency between visual and auditory streams. By leveraging multi-task pre-training on large-scale mixed-modality datasets, our model achieves robust generalization across diverse downstream tasks.
- Multi-Stage Data Pipeline: We presented a multi-stage data pipeline that prioritizes audio-video coherence, motion expressiveness, and curriculum-based data scheduling. This approach significantly enriches the descriptiveness and professionalism of video captions, while also integrating audio descriptions, thereby providing high‑quality, diverse data support for high‑fidelity audio‑video generation tasks.
- Meticulous Post-training Optimization: We utilized high-quality audio-video datasets for Supervised Fine-Tuning (SFT), followed by a Reinforcement Learning from Human Feedback (RLHF) algorithm specifically tailored for audio-video contexts. Specifically, our multi-dimensional reward model enhances performance in text-to-video (T2V) and image-to-video (I2V) tasks, improving motion quality, visual aesthetics, and audio fidelity.
- Efficient Inference Acceleration: We further optimized a multi-stage distillation framework to substantially reduce the Number of Function Evaluations (NFE) required during generation. By integrating inference infrastructure optimizations such as quantization and parallelism, we achieved an end-to-end acceleration exceeding 10× while preserving model performance.
Summary and Outlook
Seedance 1.5 pro represents a significant leap from our previous video generation model, Seedance 1.0, particularly in delivering immersive audio-visual experiences and achieving artistic narrative expression.
Building on a joint audio-visual generation architecture and refined post-training, Seedance 1.5 pro achieves improved adherence to multimodal instructions—whether in executing film-grade high-dynamic camera movements or performing dialect-based acting that requires precise lip-sync, the model demonstrates significant potential. However, we have also observed room for improvement in areas such as physical stability in complex motion scenarios, multi-character dialogues, and singing performances.
Moving forward, we are committed to enabling longer narrative generation and more real-time on-device experiences. We will also work to deepen the model's understanding of the physical world dynamics and expand its multimodal perception. Our vision is for the Seedance series models to become more expressive, efficient, and user-aware, empowering creators to transcend sensory boundaries and bring their audio-visual ideas to life.