Seed2.1 Officially Released: Advancing AI Productivity
Seed2.1 Officially Released: Advancing AI Productivity
Date
2026-06-23
Category
Models
The Seed model family has always been committed to uncovering users' real needs and unlocking their creativity. Since the launch of Seed2.0, we have tracked ongoing user feedback and observed growing expectations for more reliable responses and consistent model delivery.
Against this backdrop, we are pleased to introduce the Seed2.1 model family — a new generation of agent-capable models built for real-world productivity. Designed to solve complex needs across daily life, professional work, and frontier exploration, Seed2.1 was built with continuous input from internal and external users and developers, with optimizations calibrated against real-world use cases. For evaluation, we prioritize model performance in live workflows over static benchmark scores alone.
Below, we outline Seed2.1's core capabilities across three key dimensions:
More reliable general agent capabilities: Seed2.1 delivers significantly improved general agent performance, with enhanced cross-tool, cross-environment task delivery. For high-value office tasks and complex personal life queries, it reliably executes multi-step workflows including project planning, document processing, and tool use to deliver actionable outcomes.
More stable end-to-end coding delivery: Seed2.1 delivers upgraded end-to-end coding capabilities, supporting full-cycle tasks in enterprise-grade development scenarios: requirement analysis, feature implementation, bug fixing, environment setup, and result validation for consistent, reliable delivery.
Stronger multimodal and foundational capabilities: Seed2.1 builds on core foundational strengths in knowledge, reasoning, and multimodal understanding, delivering higher accuracy in processing complex visual inputs and video content. This underpins agentic use cases, software engineering workflows, and frontier exploration.
Doubao and Volcano Engine users can now start to access Doubao Seed 2.1.
General agent capabilities significantly enhanced for reliable complex task execution
As models are deployed in real-world productivity scenarios, users need more than a one-off answer — they need models that can carry tasks through end-to-end toward a defined goal and deliver usable outcomes. Building on this priority, Seed2.1 further strengthens its general agent capabilities, delivering consistent, reliable performance across both high-value professional tasks and complex personal-life consultations.
For high-value professional work, users previously relied on external consultants and specialized service teams to get work done. Today, the model can support information analysis, solution design, content planning, and results consolidation, helping users advance work that once required dedicated professional support to reduce costs and boost efficiency.
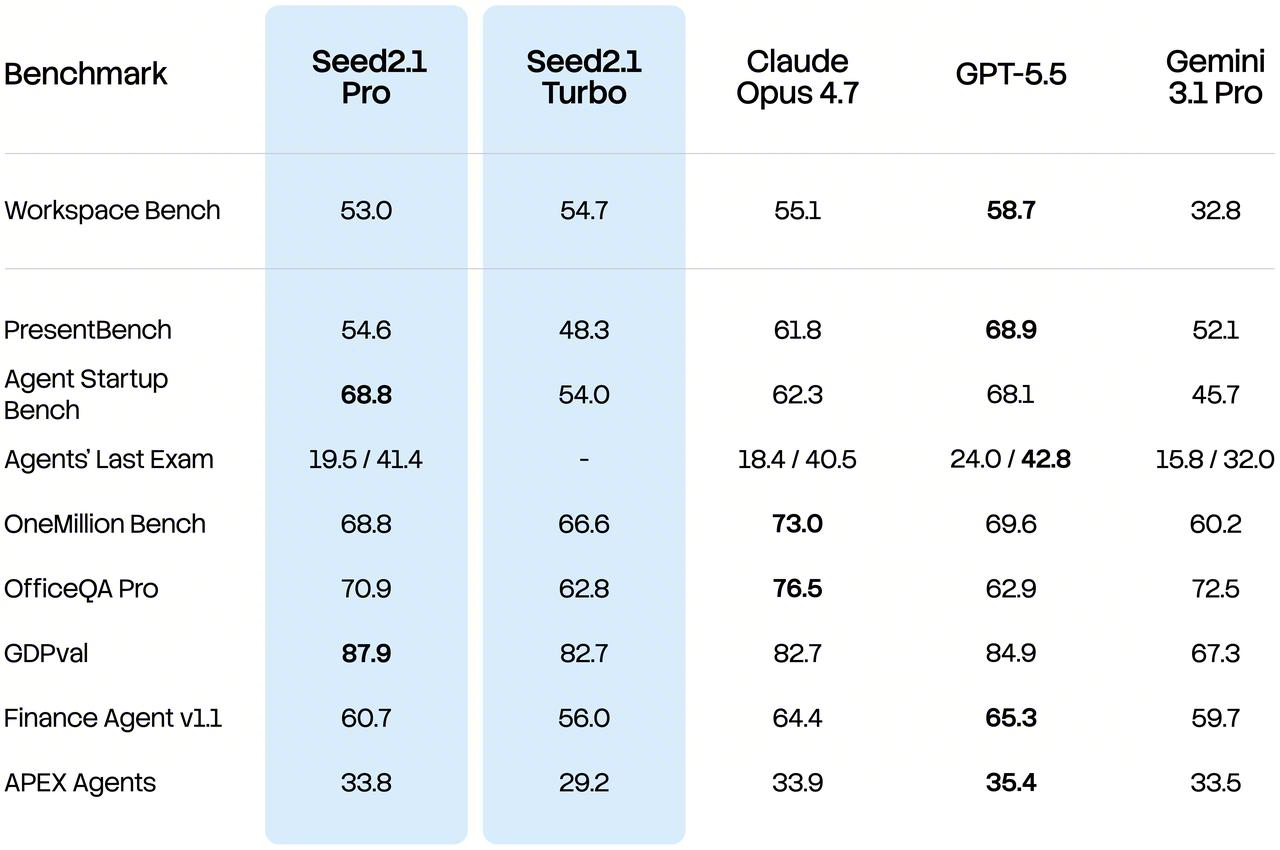
Seed2.1 delivers consistent performance on the Workspace Bench and Agent Startup Bench benchmarks, while Seed2.1 Pro achieves the highest score on GDPVal. Workspace Bench evaluates information retrieval, contextual understanding, and result generation for complex workplace documents. Agent Startup Bench comprehensively assesses response quality through research and interviews with real AI-native startups, combined with expert review. GDPVal measures the completion quality and economic value of models on real-world work tasks. These results demonstrate that Seed2.1 can connect complex source materials to task objectives and generate economically valuable deliverables in AI workflows that closely mirror real workplace tasks.
Furthermore, Seed2.1 performs well on more difficult, specialized tasks. Seed2.1 Pro ranks among the top tier of participating models on the Agents’ Last Exam (ALE) benchmark, reflecting strong competitiveness on complex professional tasks. Notably, this benchmark was released only recently, making it difficult for models to undergo sufficient task-specific optimization in the short term, and thus allowing it to more faithfully measure their generalization ability in new task scenarios. This result indicates that Seed2.1’s general agent capabilities — including task planning, tool use, long-horizon execution, information integration, and result delivery — can transfer effectively to previously unseen, high-barrier professional workflows.
In the Agents' Last Exam benchmark evaluation, the left side shows the full pass rate, and the right side shows the average overall score.
For complex consultation scenarios in personal life, the Seed2.1 model family delivers further improvements in response quality and reliability.
These use cases go far beyond simple question answering. Users typically provide multiple inputs — background context, historical records, industry reports and more — with information scattered across documents, PDFs, and images. This creates a complex consultation context that demands holistic reasoning, judgment, and tailored recommendations.
Seed2.1 achieves steady performance on benchmarks such as xDailyBench and Doubao Multi-Turn Bench, and remains competitive on Toolathlon and ClawBench. Across more than 30 vertical scenarios including daily life and academic research, the model demonstrates a deeper understanding of real user needs, delivers high-quality recommendations aligned with user preferences, and can leverage different tools and relevant skills as needed to produce reliable responses.
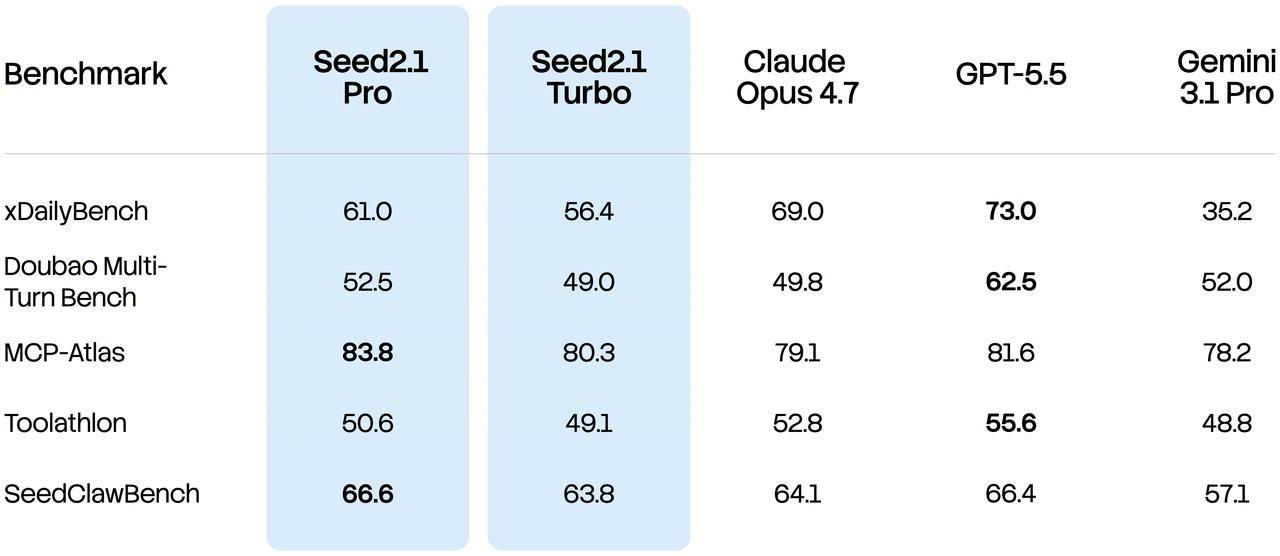
SeedClawBench is an internal benchmark developed by Seed to evaluate an agent’s ability to provide practical assistance in user-facing, OpenClaw-style scenarios.
Generate lesson-plan slides, analyze complex spreadsheets, and produce industry reports across teaching, office, and research scenarios.
In addition, building on robust visual understanding capabilities, Seed2.1 better processes visual information, comprehends user goals, and drives subsequent execution and delivery in complex tasks. It delivers strong overall competitiveness on Visual Agent benchmarks including Claw-Eval (MM). This means the model can not only understand complex visual information such as documents, videos, images, and spatial structures, but also organize and analyze visual information around task objectives to produce interactive, deliverable Agent outputs — for example, generating 2D floor plans from multi-view images, or completing tasks such as information retrieval, content generation, and coding based on visual inputs.
Image2FloorPlan is an internally developed evaluation set for assessing the task of understanding multiple real-world photos and drawing a floor plan.
In our exploration of professional productivity scenarios, we found that real-world workflows do not play out within a single fixed interface. Instead, they require switching between chat, search, browsers, code repositories, files, and external tools. For this reason, Seed2.1 has been further optimized for general-purpose computer-use agent capabilities, enabling more consistent task progression across environments, tools, and interaction paradigms.
For mobile GUI tasks, where the model must understand screen content, determine the next action, and execute sequential operations such as tapping, typing, and switching between apps, Seed2.1 achieves the highest score on the MobileWorld benchmark, demonstrating more reliable operation progression for mobile tasks. Meanwhile, the model remains competitive on OSWorld. Through reinforcement learning, it guides the agent to naturally select the optimal action across GUI and non-GUI action spaces, reducing the average number of steps required to complete tasks by 16% and further improving task execution efficiency.
Seed2.1 also delivers standout results on the CreativeWork benchmark, which covers three representative environments: Notion, Canva, and Figma. This means across use cases such as document management, visual design, and interface editing, the model can comprehend complex goals, decompose them into actionable steps, switch autonomously between tool use and GUI interaction, and complete tasks reliably.
CreativeWork is an in-house Seed benchmark designed to evaluate agents' ability to coordinate GUI and MCP tool usage in real-world productivity scenarios.
End-to-end coding capabilities significantly enhanced for reliable delivery in enterprise production scenarios
Focusing on the Coding Agent capabilities, Seed2.1 is evaluated through a combination of public benchmarks, crowdsourced developer feedback, and internal assessments. Public benchmarks mainly capture the model’s capability boundaries on general coding tasks, while crowdsourced developer feedback better reflects its practical value in real-world engineering scenarios.
On public benchmarks, Seed2.1 Pro remains competitive on ProgramBench, demonstrating its ability to deliver system-level engineering from scratch, including independent software architecture design and full code implementation.
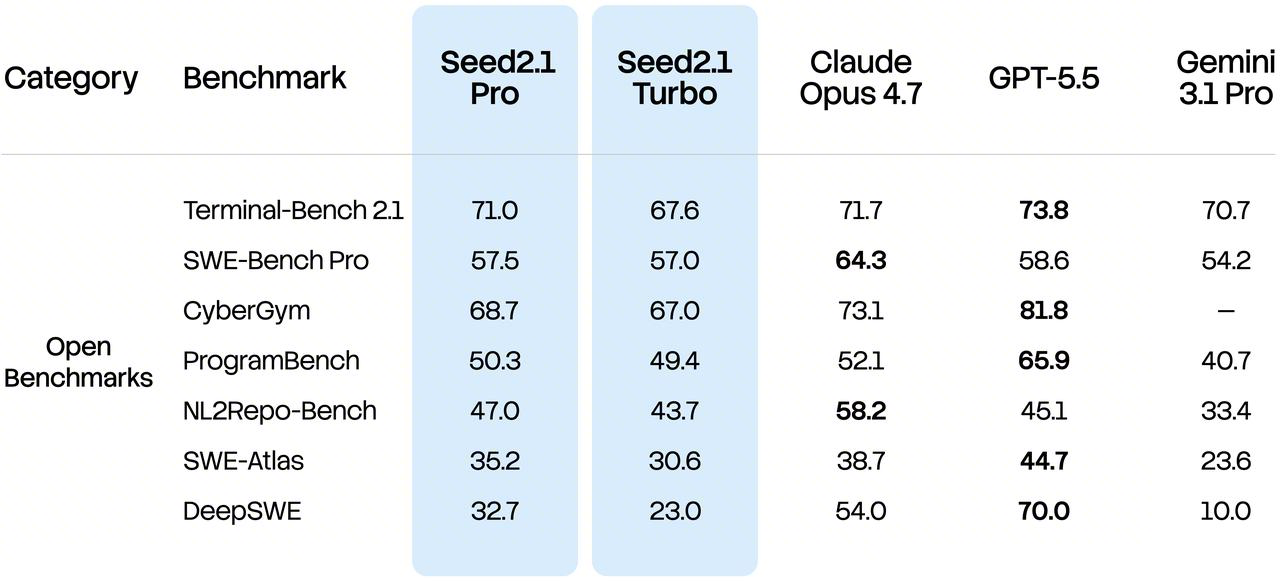
In the crowdsourced developer evaluation, developers submit engineering tasks based on real code repositories and compare the outputs of anonymized models.Results show that Seed2.1 can comprehend the architecture, dependencies, and business logic of an entire codebase, make coordinated modifications across multiple files, and ultimately deliver maintainable, production-ready engineering code.
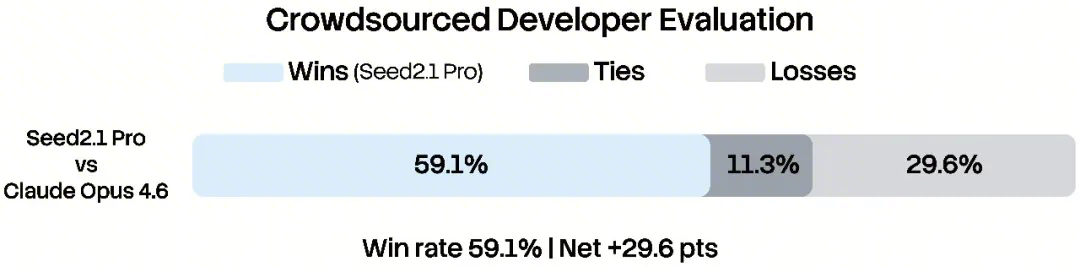
The Seed2.1 Preview recently participated in a human preference evaluation for frontend development scenarios. On the Code Arena: Frontend leaderboard, it ranks 8th with a score of 1539, and secures a top-10 position in 5 out of 7 frontend subcategories.
Foundational capabilities including multimodal understanding maintain industry leadership, further empowering agentic scenarios
Seed2.1 continues to advance its multimodal capabilities, achieving SOTA results across multiple visual and video understanding benchmarks. This maintains its industry-leading standing while further empowering agentic use cases.
For visual understanding tasks, Seed2.1 Pro achieves the highest scores on multiple benchmarks including CharXiv-RQ and MeasureBench, marking further advances in complex document understanding, chart interpretation, numerical recognition, and fine-grained visual reasoning. These improvements reduce interpretation errors when processing PDFs, reports, charts, and multi-page documents, while boosting the reliability of downstream analysis and task execution.
Seed2.1 also delivers top results on the ERQA benchmark, with enhanced spatial understanding capabilities that better support agent tasks in real-world environments. Additionally, the model delivers standout performance on the MMLongBench-128K long-context benchmark, enabling it to process lengthy documents, multi-page materials, and extended task information chains, helping agents advance complex tasks reliably with fuller contextual awareness.
For video understanding, Seed2.1 Pro scores at industry-leading levels on TVBench and TOMATO, demonstrating more accurate comprehension of temporal changes, actions, and physical motion dynamics.
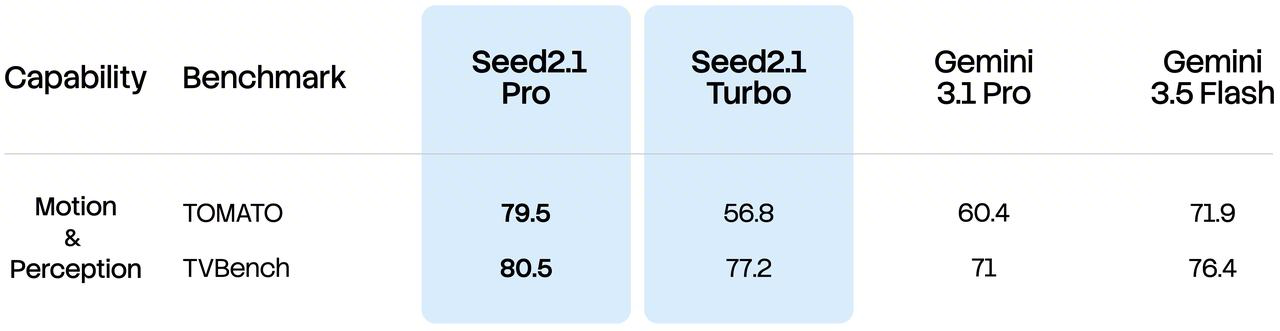
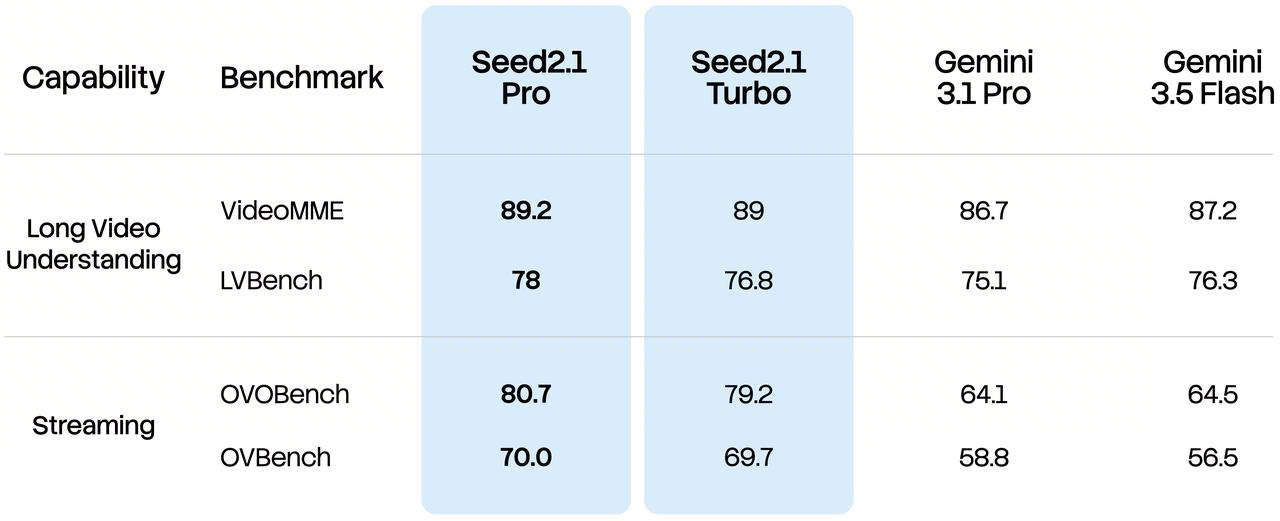
Seed2.1 also continues to enhance its long-form video processing capabilities, with further improvements in recognition and comprehension accuracy. It delivers strong performance on benchmarks including Video MME and LVBench, establishing a robust foundation for use cases such as long-video retrieval and film and video editing. Its streaming video capabilities have also been upgraded, with standout results on OVBench, enabling more efficient content comprehension in scenarios including real-time video calls, meeting recording playback, and video analysis.
Understand, edit, and narrate long-form videos end to end, automatically producing narrated highlight videos.
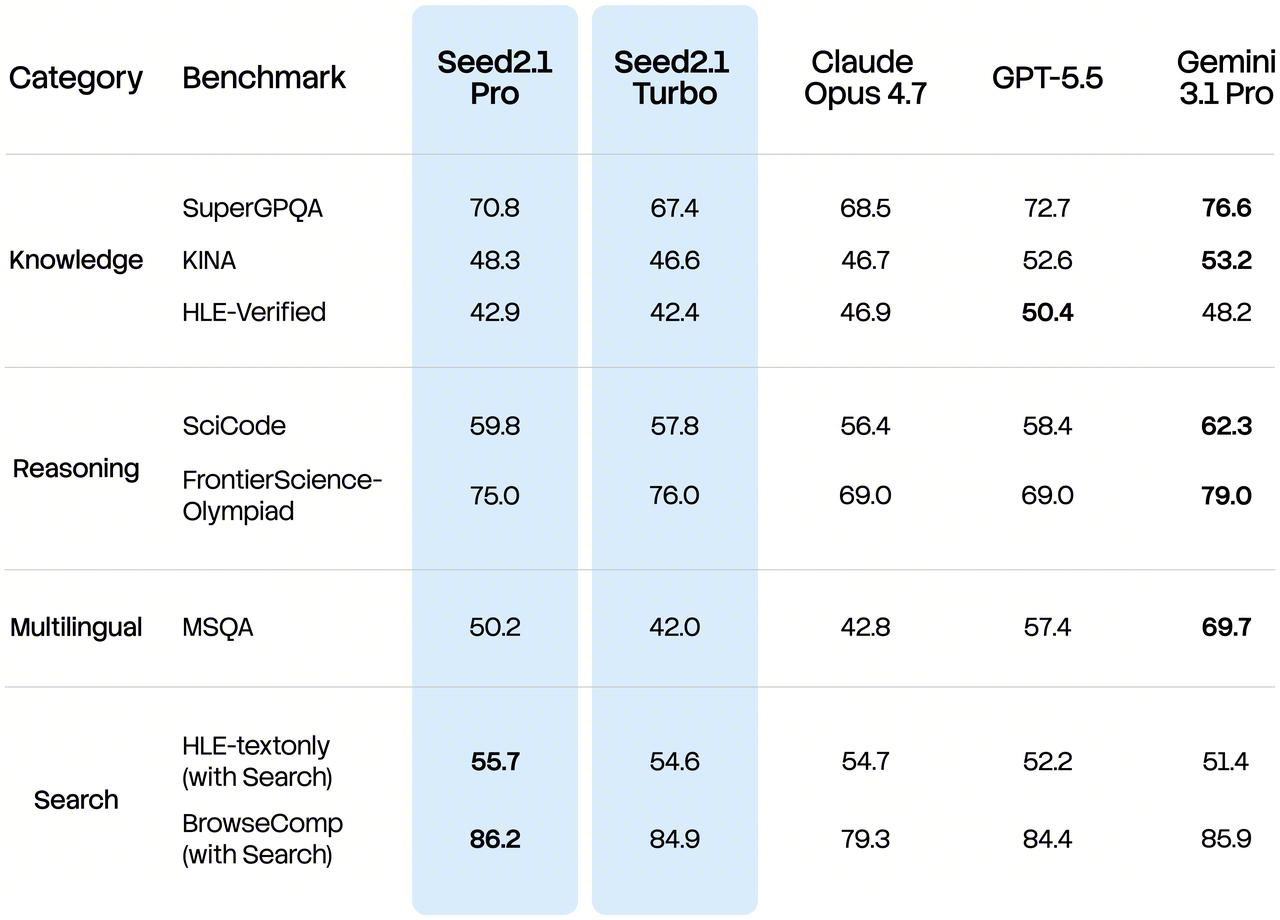
Beyond multimodal understanding, Seed2.1 delivers further improvements to core foundational capabilities including world knowledge, reasoning, and multilingual proficiency, with well-balanced overall performance. It performs well on benchmarks such as SciCode and FrontierScience-Olympiad, demonstrating consistent reasoning performance on highly demanding tasks such as scientific coding and advanced scientific problem-solving. In addition, Seed2.1 boasts enhanced multilingual capabilities, enabling more accurate comprehension of knowledge-intensive questions across diverse cultural contexts and supporting a wider array of international use cases.
MSQA is an in-house multilingual benchmark designed to assess culture-specific knowledge across 11 major languages.
Seed2.1 continues to push into more open-ended research domains, including scientific research, computer science, physics & scientific computing, and advanced mathematics. It maintains competitive on frontier research benchmarks such as FrontierScience-Research.
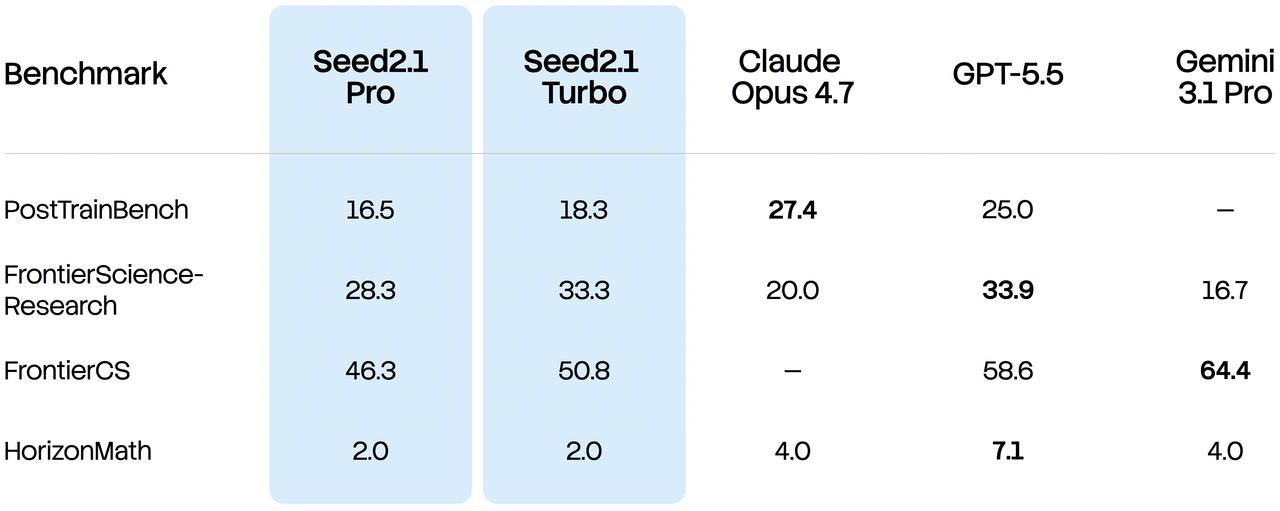
In physics and scientific computing, Seed2.1 synthesizes domain theories, numerical formulas, and data files to translate scientific questions into executable, verifiable computational workflows, with iterative refinement of results driven by validation feedback. For mathematical research, the model assists mathematicians in searching for constructions and testing proof strategies, lowering trial-and-error costs in constructive reasoning and enabling more exploratory mathematical research.
Furthermore, as agent capabilities evolve from pure dialogue to real-world workflow execution, the paradigm of model development is also shifting. Models are no longer just objects of evaluation, training, and optimization — they are now active participants in the model development process itself.
We continue to advance our Seed for Seed initiative: Seed2.1 not only powers external R&D and business scenarios, but also integrates into key stages of the development pipeline — evaluation, data, training, research, and infrastructure. It participates in real R&D tasks, and in turn accelerates model iteration by boosting R&D efficiency.
In practice, Seed2.1 operates as an agent across tasks including evaluation system development, capability diagnosis, SFT data synthesis, and RL training framework optimization. It also implements and validates key methodologies from cutting-edge research papers via code and experiments. These tasks often span hours, tens of hours, or even dozens of days. The agent must continuously ingest intermediate results, diagnose issues, leverage tools to implement modifications, and conduct repeated validation and iteration based on experimental feedback.
For more complex tasks, multiple agents can also collaborate with specialized roles — execution, evaluation, diagnosis, and optimization. This decomposes complex R&D work into sustainable, closed-loop workflows and elevates the overall efficiency of the model development pipeline.
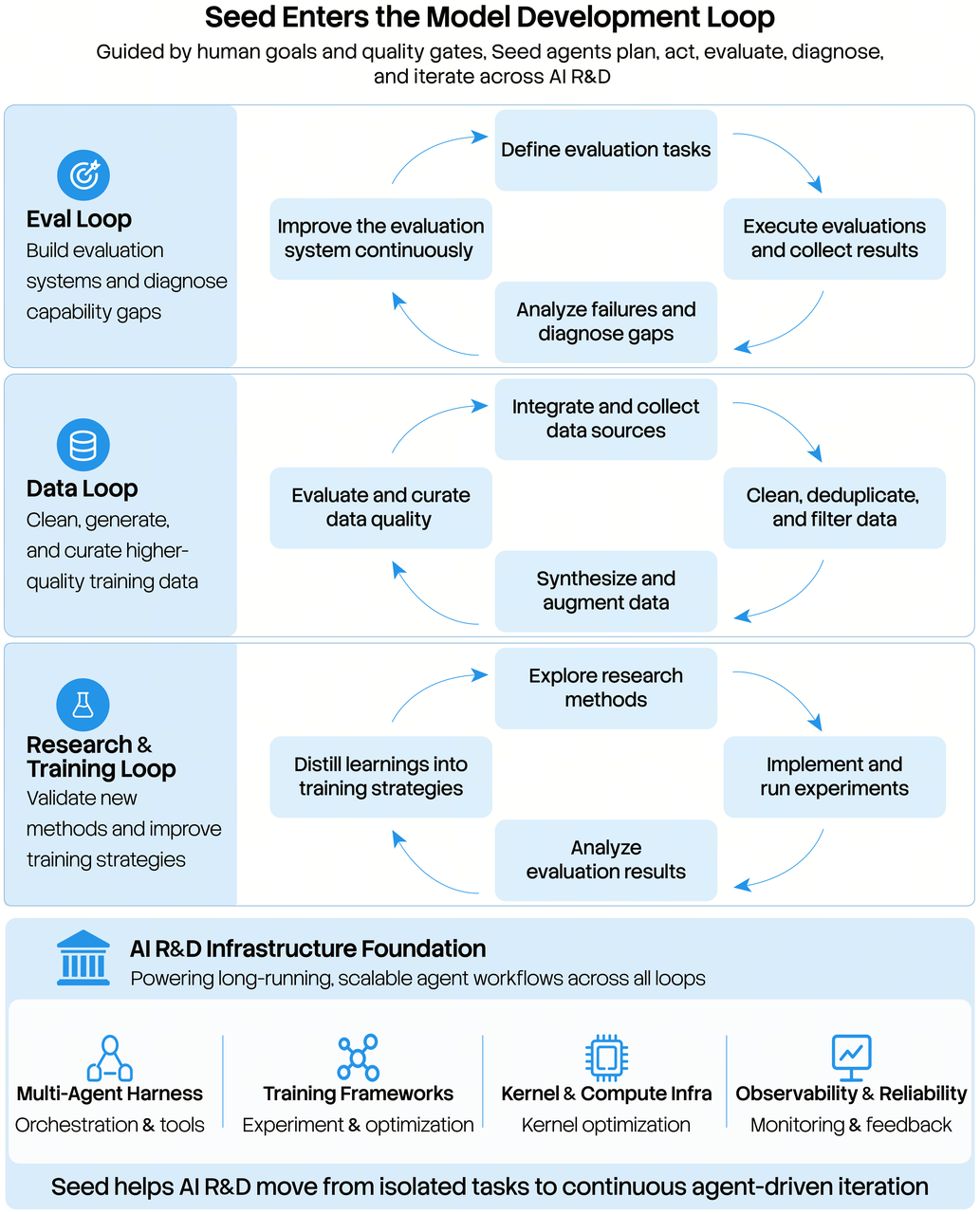
Seed for Seed R&D Workflow Diagram
Conclusion and outlook
Focused on delivering tangible productivity value in real-world scenarios, Seed2.1 delivers significant improvements in both agent task execution capabilities and coding delivery stability. That said, we acknowledge there remains room for improvement in the most challenging open-ended tasks and cutting-edge research problem-solving.
Going forward, we will continue our optimization efforts across four key areas:
Deepen our understanding of expert user needs and further expand support for professional workflows;
Refine coordination between the Harness and the model to enable reliable model performance in complex workflows;
Accelerate model iteration by integrating the model deeper into training processes and enabling autonomous research;
Continuously refine model behavior to enhance user experience.
Guided by these priorities, the Seed model family will continue to push the frontiers of intelligence while iterating continuously to serve real-world scenarios.