2024年9月18日
嗨,Seed-Music
我们的统一框架能够生成富有表现力的多语言人声音乐,允许用户对模型输出进行精确的音符级调整。用户也可以将自己的声音融入到音乐创作中,更有其他各种玩法。
阅读技术报告
概览
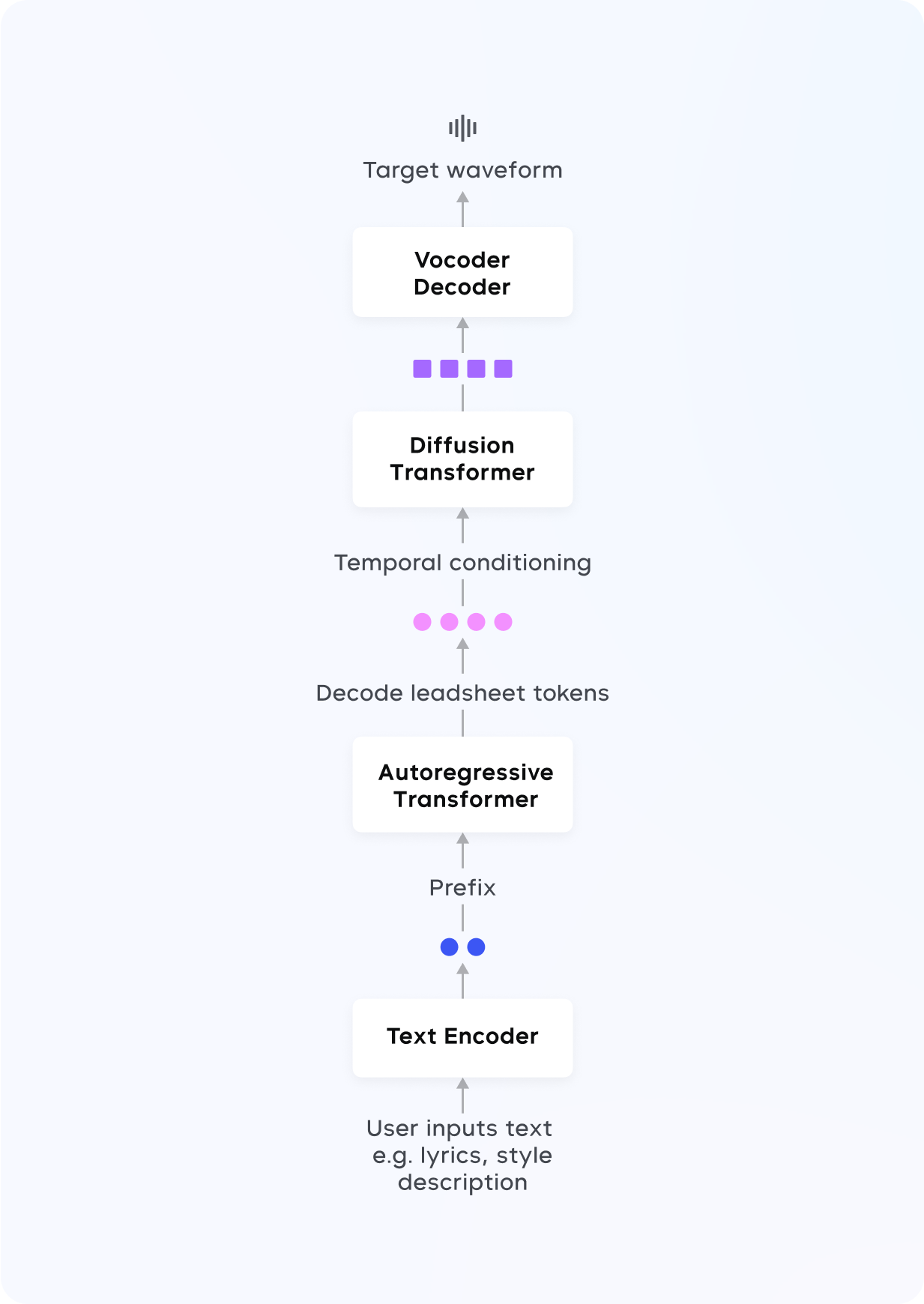
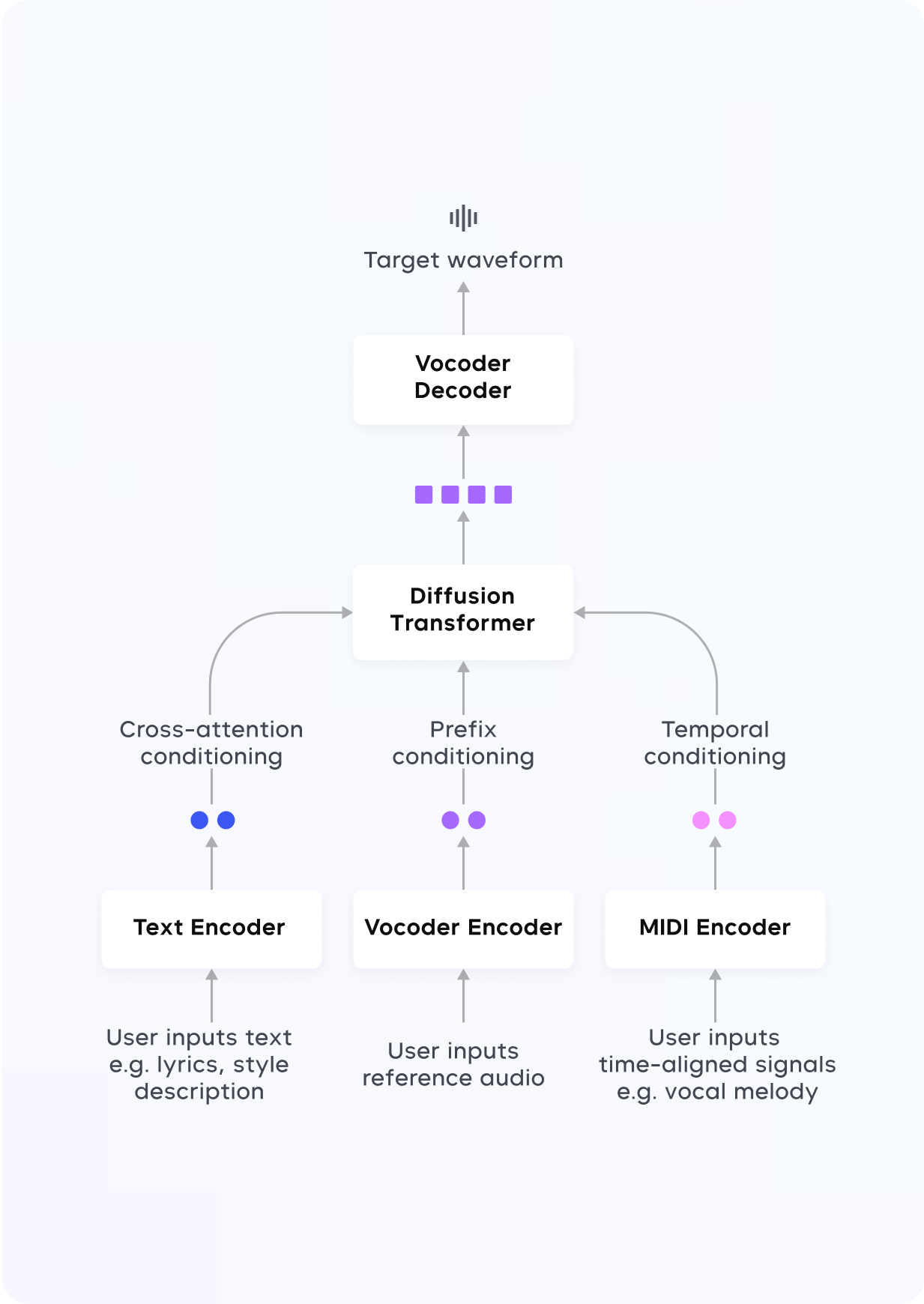
我们推出了 Seed-Music,一套全新的音乐生成系统,能够生成高质量音乐,并实现细粒度的风格控制。针对各类应用场景,我们设计了不同的方法论、实验和解决方案,没有依赖自回归(AR)或扩散等单一建模方法,而是提出了统一框架,以适应音乐人不断演变的工作流程。主要贡献体现在以下三个方面:
 引入基于自回归语言模型(LM)的方法,在多样、多模态的用户输入条件下,生成高质量人声音乐。提出一种基于扩散的方法,实现对音乐音频在音符级别的精细编辑。提出一种零样本歌声转换的新方法,用户仅需提供一段 10 秒的歌唱或语音录音。
引入基于自回归语言模型(LM)的方法,在多样、多模态的用户输入条件下,生成高质量人声音乐。提出一种基于扩散的方法,实现对音乐音频在音符级别的精细编辑。提出一种零样本歌声转换的新方法,用户仅需提供一段 10 秒的歌唱或语音录音。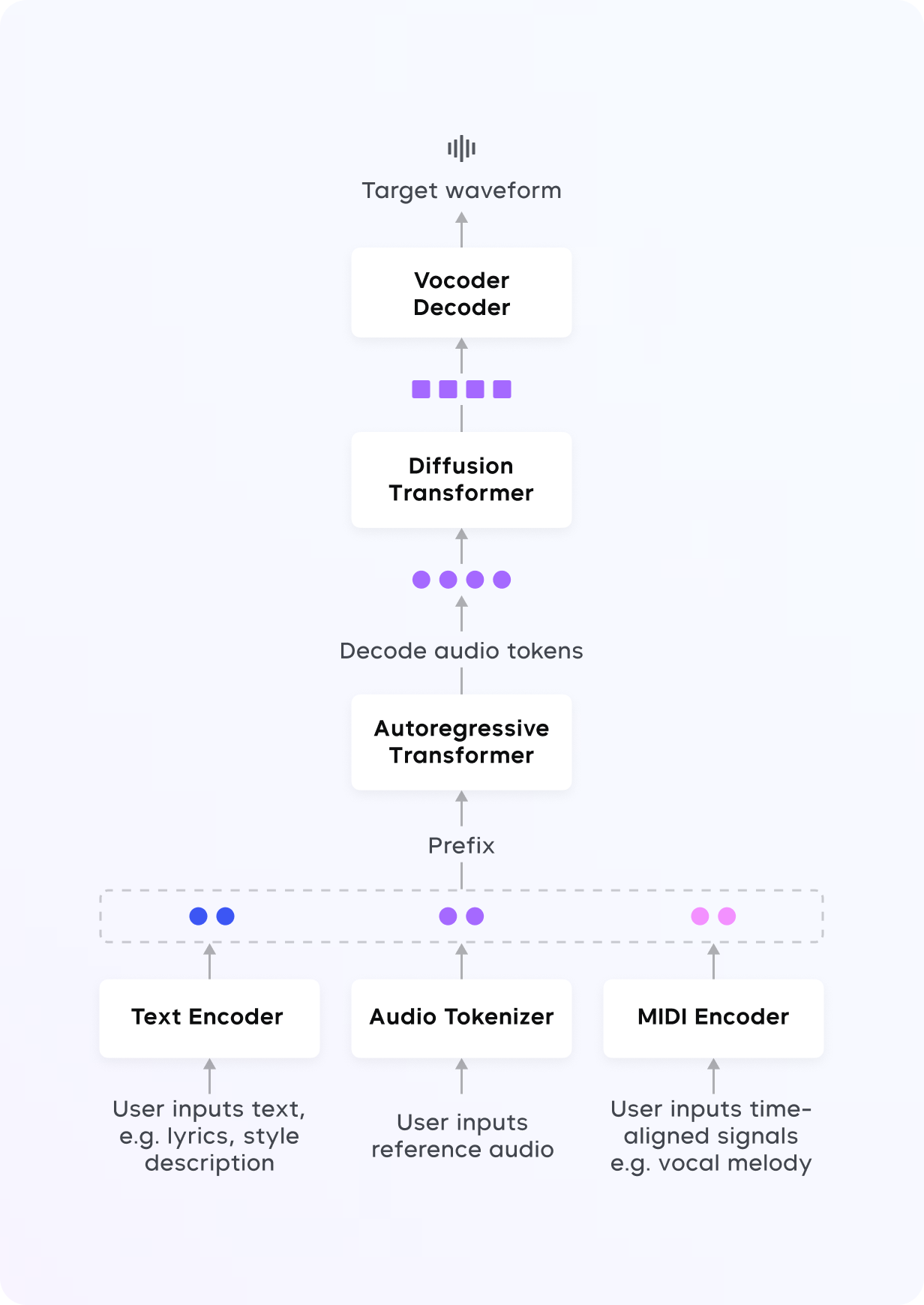
试听示例
以下展示的所有音频样本均由 Seed-Music 生成。这些样本的呈现顺序与我们技术论文中的一致。