Seed 端到端同声传译大模型发布:准确率接近真人,3s 延迟,实时声音复刻
Seed 端到端同声传译大模型发布:准确率接近真人,3s 延迟,实时声音复刻
日期
2025-07-24
分类
模型发布
同声传译,被视为“翻译界的巅峰技能”。它需要译者在数秒的极短时间内转换语言,边“听”边“说”,要求极高。因此,对翻译技术研究者来说,同传一直是最具挑战的方向。
今天,字节跳动 Seed 团队正式发布端到端同声传译模型 Seed LiveInterpret 2.0。
Seed LiveInterpret 2.0 是首个延迟&准确率接近人类水平的产品级中英语音同传系统,在中英同传翻译质量达到业界 SOTA 的同时,实现了极低的语音延迟水平。
它基于全双工端到端语音生成理解框架,支持中英互译,可实时处理多人语音输入,像人类同传译员一样以极低的延迟 “边听边说”,一边接收源语言语音输入,一边直接输出目标语言的翻译语音。同时,Seed LiveInterpret 2.0 还支持 0 样本声音复刻,让沟通更加流畅自然。
在测试中,可以观察到,Seed LiveInterpret 2.0 面对 40 秒的大段中文表达,能够低延迟地丝滑输出同款音色的英语翻译。
Seed LiveInterpret 2.0 还能快速学习音色,无论是西游记里的猪八戒,还是红楼梦中的林妹妹,即便此前未“听”过角色的声音,依然能通过实时交互进行现场演绎。
相比传统机器同传系统,Seed LiveInterpret 2.0 模型具备以下优势:
接近真人同传的翻译准确率
精准的语音理解能力保障了翻译准确度,在多人会议等复杂场景中英双向翻译准确率超 70%,单人演讲翻译准确率超 80%,接近真人专业同传水平。
极低延迟的 “边听边说” 能力
采用全双工语音理解生成框架,翻译延迟可低至 2-3 秒,较传统机器同传系统降低超 60%,实现了真正的 “边听边说” 翻译。
零样本声音复刻,音色真实自然
只需采样实时语音信号,便能提取声音特征,用说话人的音色特质实时 “说出” 外语,提升交流的沉浸感和亲和力。
智能平衡翻译质量、延迟和语音输出节奏
可根据语音清晰度、流畅度、复杂程度,调整输出节奏,并适配不同语言特性。面对超长信息,依然能保证传译语音节奏的自然流畅。
目前,Seed LiveInterpret 2.0 技术报告已公布,模型基于火山引擎对外开放,欢迎体验。此外,Ola Friend 耳机也将在 8 月底接入 Seed LiveInterpret 2.0,成为首个支持该模型的智能硬件设备。
技术报告:http://arxiv.org/pdf/2507.17527
项目主页:https://seed.bytedance.com/seed_liveinterpret
体验链接:登录火山引擎后,选择语音模型“Doubao-同声传译 2.0”https://console.volcengine.com/ark/region:ark+cn-beijing/experience/voice?type=SI
端到端语音同传模型,平衡翻译质量与延迟
常见同传场景往往存在多人对话声音交叠、语音输入不清晰、表达不流畅、逻辑混乱等挑战。由于语音理解和翻译能力不足,传统机器同传系统在复杂场景中翻译准确率低、延迟高,用户体验有待提升。
字节跳动 2024 年发布 Seed LiveInterpret 1.0 模型(又名:CLASI),在相当程度上解决了语音转文本翻译的准确度、专业性及时延问题,但并不支持语音输出。
时隔一年,团队发布 Seed LiveInterpret 2.0,实现了 “边听边说” 的低延迟高质量语音同传能力。
Seed LiveInterpret 2.0 依靠端到端语音理解生成技术,团队在 CT(Continual Training)过程中,利用平行和非平行语音数据促使语音和文本信息对齐,并使用不同语言的语音、文本、语音到语音、文本到文本等多任务翻译数据进行持续训练,以提升模型的语音理解准确度以及语音复刻等生成能力。
此后,团队使用高质量人工标注数据进行监督微调(SFT,Supervised Fine-tuning),让模型学会了更准确的翻译时机和翻译准确性,显著提升了同传效果。
经过 CT 和 SFT 后,模型已具备较好的翻译质量与音色复刻能力,但延迟依然有提升空间,相较专业人类同传译者有一定差距。
为此,我们采用强化学习方法,基于翻译质量与延迟等要素,构建了过程奖励模型与结果奖励模型, 进一步降低模型语音输出的延迟,提升翻译效果。相比 SFT 模型,强化学习算法降低了 20% 以上的延迟,并进一步提升了翻译质量。
通过上述工作,Seed LiveInterpret 2.0 实现下述特点:
复杂场景下的精准理解
Seed LiveInterpret 2.0 依托团队在语音理解能力上的长期积累,在多人对话、中英混杂、说话不清晰、语序混乱等复杂场景中仍能实现高质量的理解传译,还能纠正潜在错误。
面向中英混杂表述,Seed LiveInterpret 2.0 能够准确完整地翻译
Seed LiveInterpret 2.0 可同传翻译中文绕口令与冷笑话
真正实现“边听边说”
Seed LiveInterpret 2.0 的全双工语音理解和生成框架,让其可以持续 “边听边说”。
模型能一边理解语音输入,一边输出传译音频,还能同步输出文字(可选择原文或译文)。而传统级联同传系统必须等待文本完全生成后,再进行语音合成,导致语音延迟问题突出。
工作场合中英交流能够高准确度、低时延地进行同传翻译
零样本实时声音复刻
同样得益于统一的语音理解生成框架,模型实现了精准还原说话者音色,无需提前采集声音样本,仅通过实时对话即可合成“原声”语音翻译。
同时,模型可以学习说话人声学特征和说话风格,确保输出语音在音色、语调和韵律上相对一致。
Seed LiveInterpret 2.0 支持 0 样本声音复刻,音色还原度高,口音地道
智能平衡实时性与准确性
Seed LiveInterpret 2.0 能够自动寻找翻译质量和延迟之间超参数的最佳值。
当输入语音流畅、清晰、标准,模型会以极快的响应速度传译。当输入语音不流畅,出现改口、重复表达时,模型会选择听到合适内容后再开始传译,保证更高的翻译准确率。
面对流畅、清晰的工作表达,Seed LiveInterpret 2.0 将在较短时间内输出语音
面向长时间的大段语音输入(例如演讲),Seed LiveInterpret 2.0 则 “懂得” 保持传译音频和输入音频节奏一致,避免生成语音过长,跟不上讲者节奏,导致演讲传译不同步。
针对特定领域生动、细节化的表达,模型依然可以完整准确地翻译,并保持输出节奏自然合理
专业人工评测表现突出,接近真人同声传译水平
为准确评估 Seed LiveInterpret 2.0,团队邀请了专业同传译者团队对模型翻译表现进行严格的人工评测。
评测基于 RealSI 数据集,这是一个包含中英双向各 10 个领域的公开测试集,人工评测团队以传达有效信息的占比(Valid Information Proportion)为指标,在中英方向上测试了包括 Seed LiveInterpret 2.0 在内多个业界领先的同传系统。
人工评测翻译准确率超 74%,平均延迟低至 3 秒内
评测结果显示,在语音到文本的同传任务中,Seed LiveInterpret 2.0 中英互译平均翻译质量的人类评分达到 74.8(满分 100,评估译文准确率),较排名第二的基准系统(47.3 分)超出 58%。
在语音到语音中英同传任务中,仅 3 个测评的翻译系统支持该能力,其中 Seed LiveInterpret 2.0 中英互译平均翻译质量达到 66.3 分(满分 100,除评估译文准确率,还评估语音输出时延、语速、发音、流畅性等指标),远超其他基准系统,达到接近专业真人同传的水平。同时,大部分基准系统也不支持声音复刻功能。
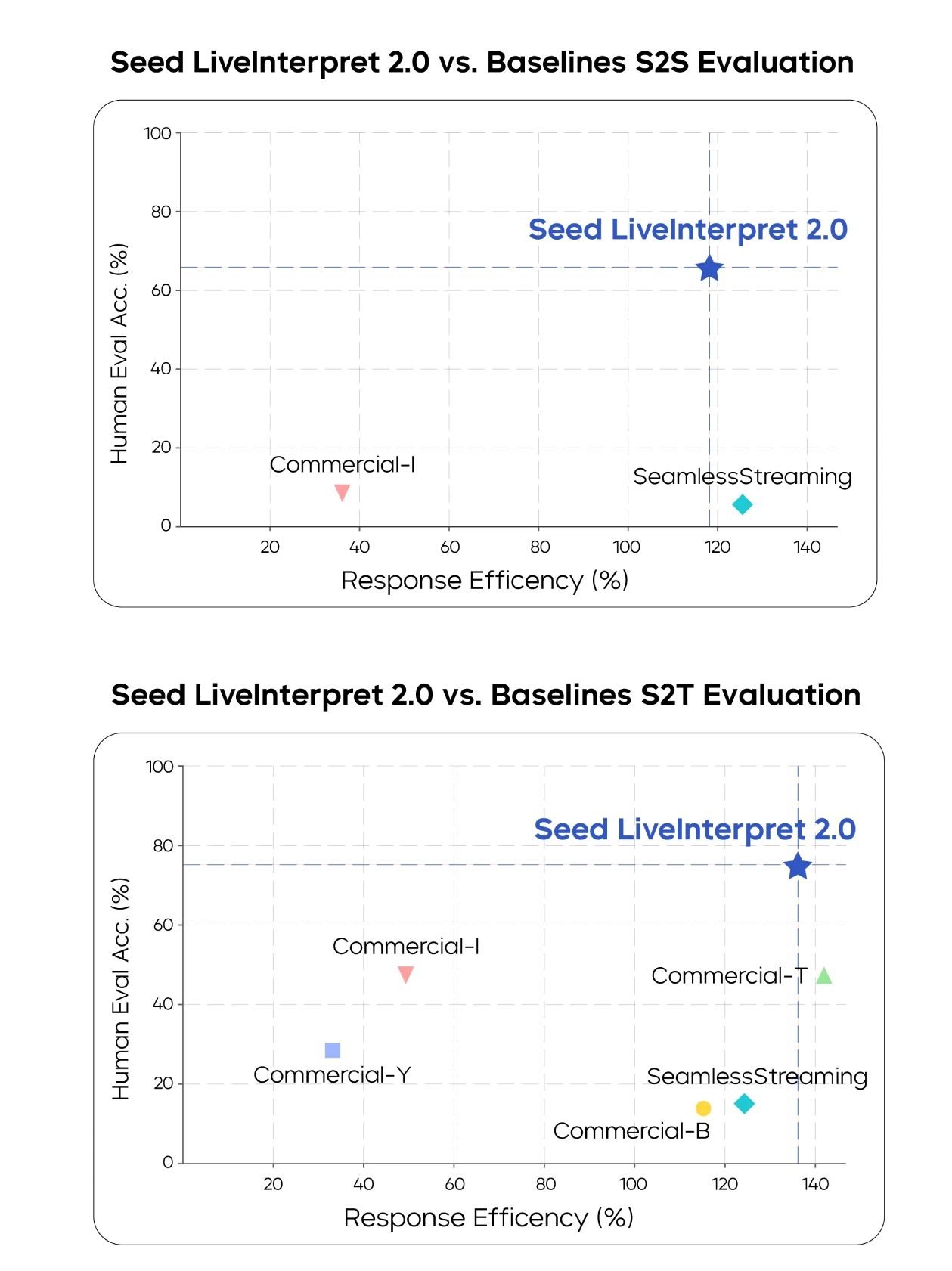
在语音到文本 (S2T) 以及语音到语音 (S2S) 任务中,人工评测的翻译质量和响应效率(部分商业翻译系统以字母指代)
在延迟表现上,Seed LiveInterpret 2.0 在语音到文本场景中,输出首字平均延迟仅 2.21 秒,在语音到语音场景中,输出延时仅 2.53 秒,做到了对翻译质量以及时延的均衡。
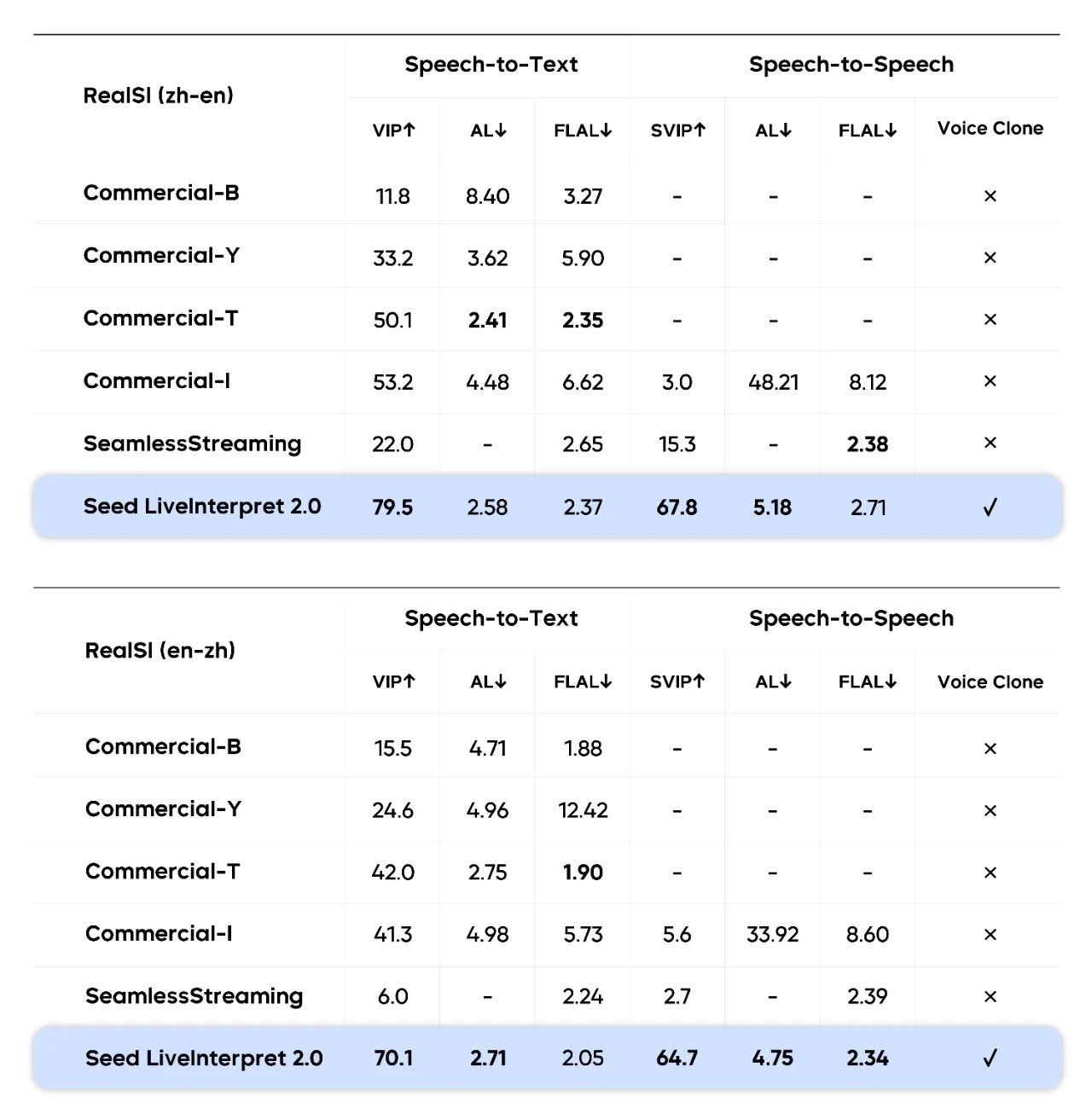
在语音到文本 (S2T) 以及语音到语音 (S2S) 任务中,人工评测的中译英及英译中翻译准确率和时延
客观评测同样表现更优
我们也基于句子级别的测试集,针对 Seed LiveInterpret 2.0 中译英和英译中两个方向的表现进行了客观评估,与其他翻译系统在翻译质量(BLEURT/ COMET)和延迟(AL/ LAAL/FLAL)等指标上进行对比。
结果显示,Seed LiveInterpret 2.0 在两个数据集上均表现出最高的翻译质量。在延迟方面,Seed LiveInterpret 2.0 在英到中方向上实现了语音到语音翻译的最低平均滞后(AL),在中到英方向上也表现出竞争力,展现了速度与准确度的良好平衡。
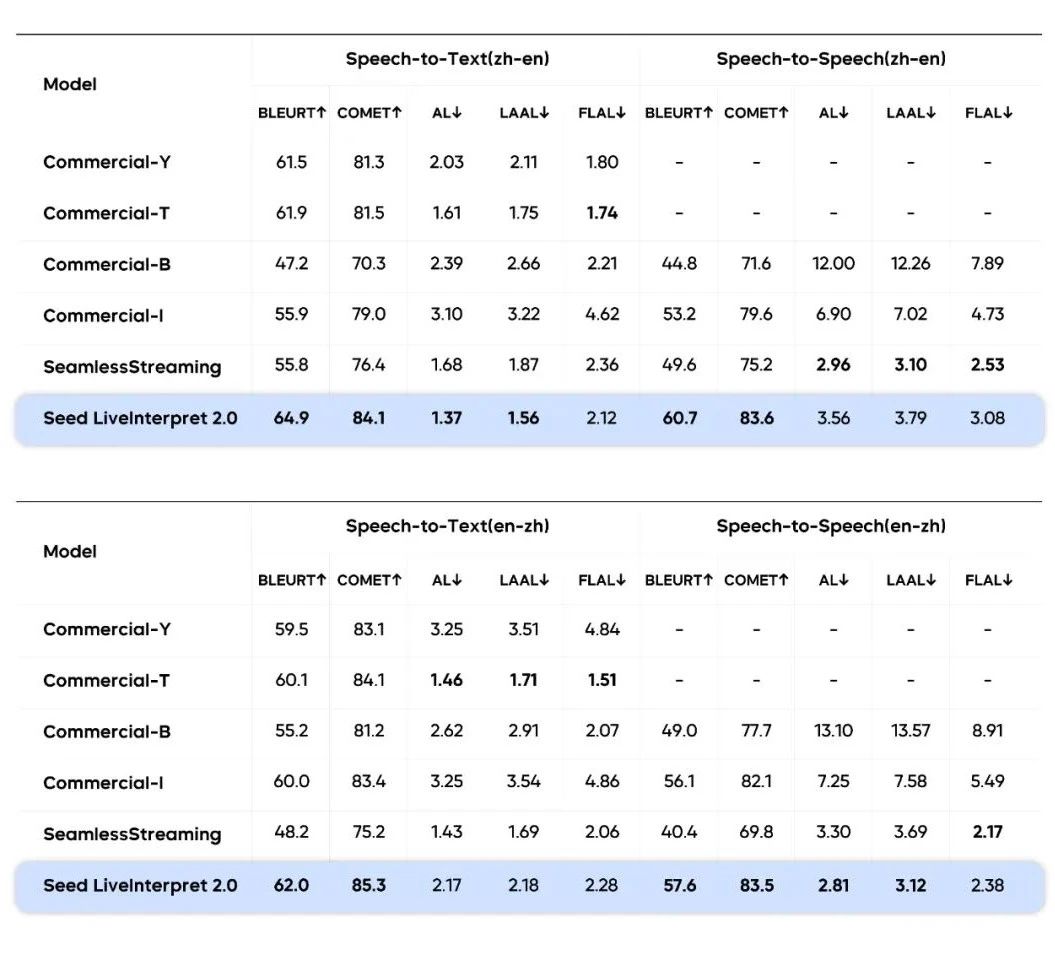
由于业界适合同传场景的高质量公开测试数据较少,我们整合了公开数据与内部数据集进行测试
总体来看,Seed LiveInterpret 2.0 在句子级基准测试中,有效平衡了翻译质量与延迟。这不仅缓解了传统同传中 “译得准则慢,译得快则偏” 的痛点,配合音色复刻能力,让中英跨语言交流首次具备自然对话般的流畅感。
总结与展望
在本研究中,团队进一步认识到数据对模型训练的重要性。模型经过数十万小时语音数据的训练,数据质量中的任何瑕疵都可能在最终效果中被显著放大,这些潜在问题包括口音差异、准确读音、时间戳的准确预测,以及句子衔接的流畅度等关键要素。Seed LiveInterpret 2.0 良好的性能正是建立在海量优质训练数据之上。
同时,尽管 Seed LiveInterpret 2.0 已初步展现出一定优势,其边界仍有拓展空间。比如,在语言覆盖方面,目前模型主要支持中英互译,其他语种尚未较好支持。此外,其声音复刻的稳定性、语音表现力、情绪复刻能力、极复杂情况下的翻译准确性等仍有进步空间。
在未来研究中,我们希望进一步挖掘模型潜力,通过优化算法、增强数据及改进训练策略等方式,逐步拓展同传模型的能力边界,提升其在复杂场景下的适应性和性能表现。