Seedance 1.0 视频生成模型技术报告公开
Seedance 1.0 视频生成模型技术报告公开
日期
2025-06-11
分类
模型发布
字节跳动 Seed 团队正式发布视频生成基础模型 Seedance 1.0。
Seedance 1.0 支持文字与图片输入,可生成多镜头无缝切换的 1080p 高品质视频,且主体运动稳定性与画面自然度较高。
相较 Seed 此前发布的视频生成模型,Seedance 1.0 核心亮点如下:
- 原生多镜头叙事能力:支持 2-3 个镜头切换的 10 秒视频生成,可进行远中近景画面切换,叙事能力大幅提升;
Prompt:女孩弹钢琴,多镜头切换,电影质感(I2V)。
Prompt:多个镜头。一名侦探进入一间光线昏暗的房间。他检查桌上的线索,手里拿起桌上的某个物品。镜头转向他正在思索。
- 更强运动生成效果:画面与主体动态效果更自然,结构稳定性与细节把控更好,生成崩坏率更低;
Prompt:滑雪者在滑雪,他转弯时扬起大片雪雾,沿着山坡逐渐加速,镜头平稳地移动着。
Prompt:一位身着黑色露背礼服的模特优雅地走在鲜艳的红色 T 台上。光线展现出面料的流动感。观众席间的目光追随模特,最后灯光渐暗。
- 支持高美感的多种风格创作:可精准响应指令生成写实、动漫、影视、广告等不同风格的高品质视频内容,画质更真实,且美感更强;
- 40+ 秒高速推理,更低成本:通过对模型结构的精细设计和极致的推理加速,可在更短时间完成视频创作,对于 5 秒 1080p 分辨率的视频生成任务,实测推理耗时 41.4 秒(基于 L20 测试)。
在第三方评测榜单 Artificial Analysis上,Seedance 1.0文生视频、图生视频两个任务的表现均位居首位。
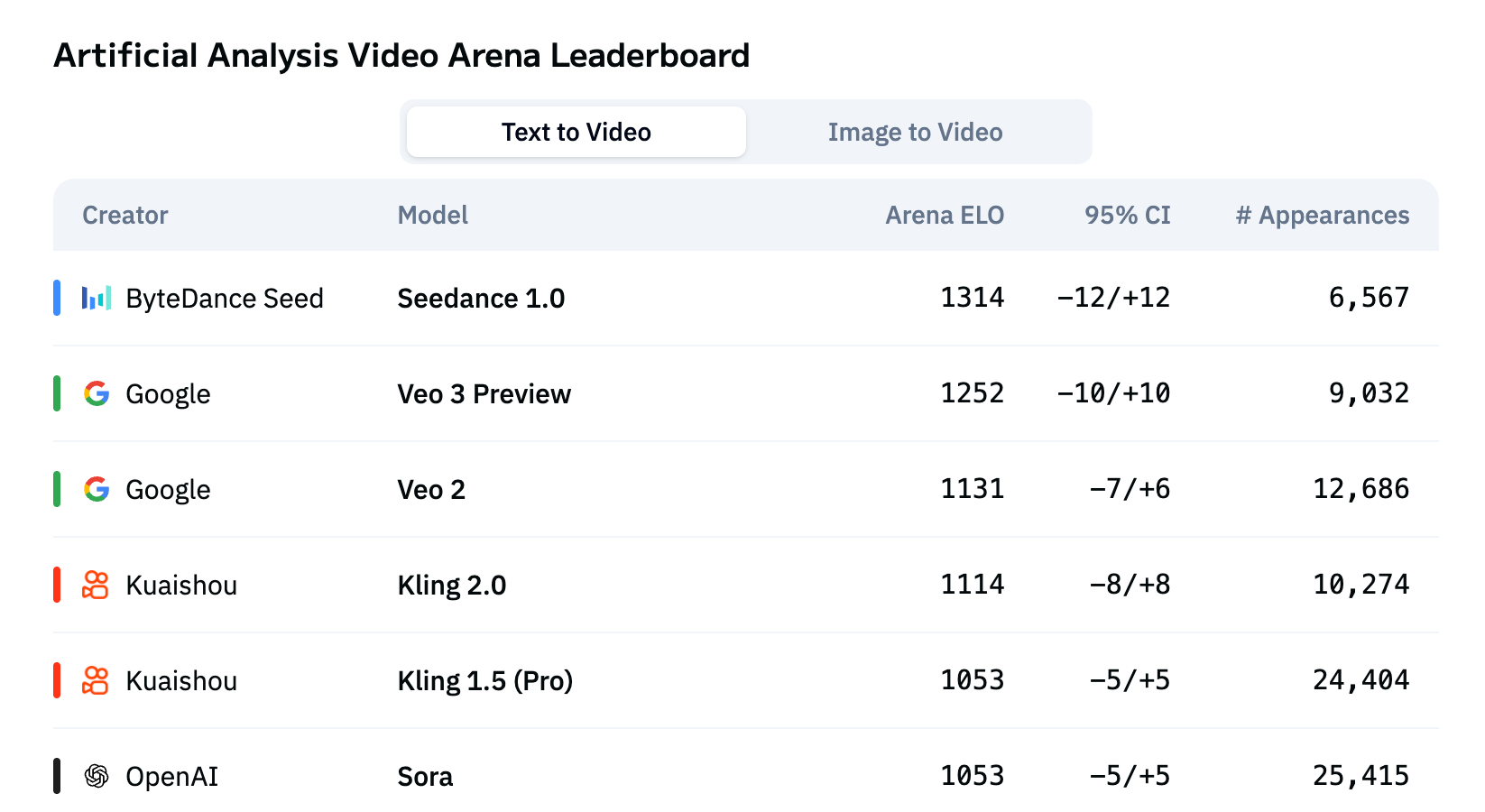
Artificial Analysis 文生视频榜单
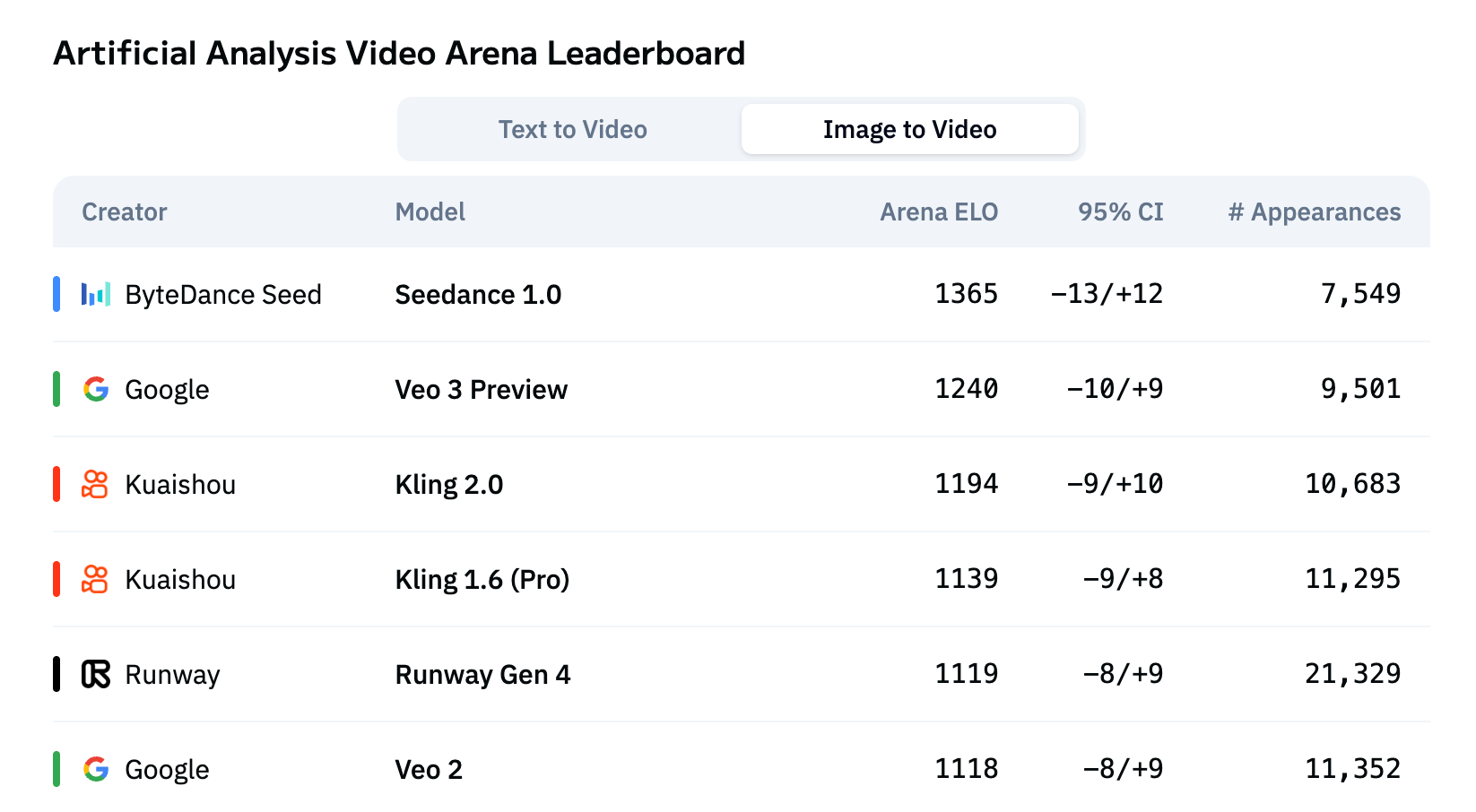
Artificial Analysis 图生视频榜单
(注:为实现评估上的统一,Artificial Analysis 将 Veo 3 Preview 生成视频去掉声音后参与上述榜单评测。)
团队还建立了一个综合基准,依靠人工对 Seedance 1.0 表现进行评估。该测试集包含 300 条文生视频、图生视频 Prompt,并邀请影视导演、业内专家联合制定评估标准,涵盖主体生成、动作稳定性、镜头切换和表达、美感、指令遵循等维度。
可以看到,在动态图像生成的各维度上,Seedance 1.0 有较好的综合表现,尤其动作生成、指令遵循等关键能力处于业界前列。此外,Seedance 1.0 在推理速度、用户好评度等方面表现也比较突出。
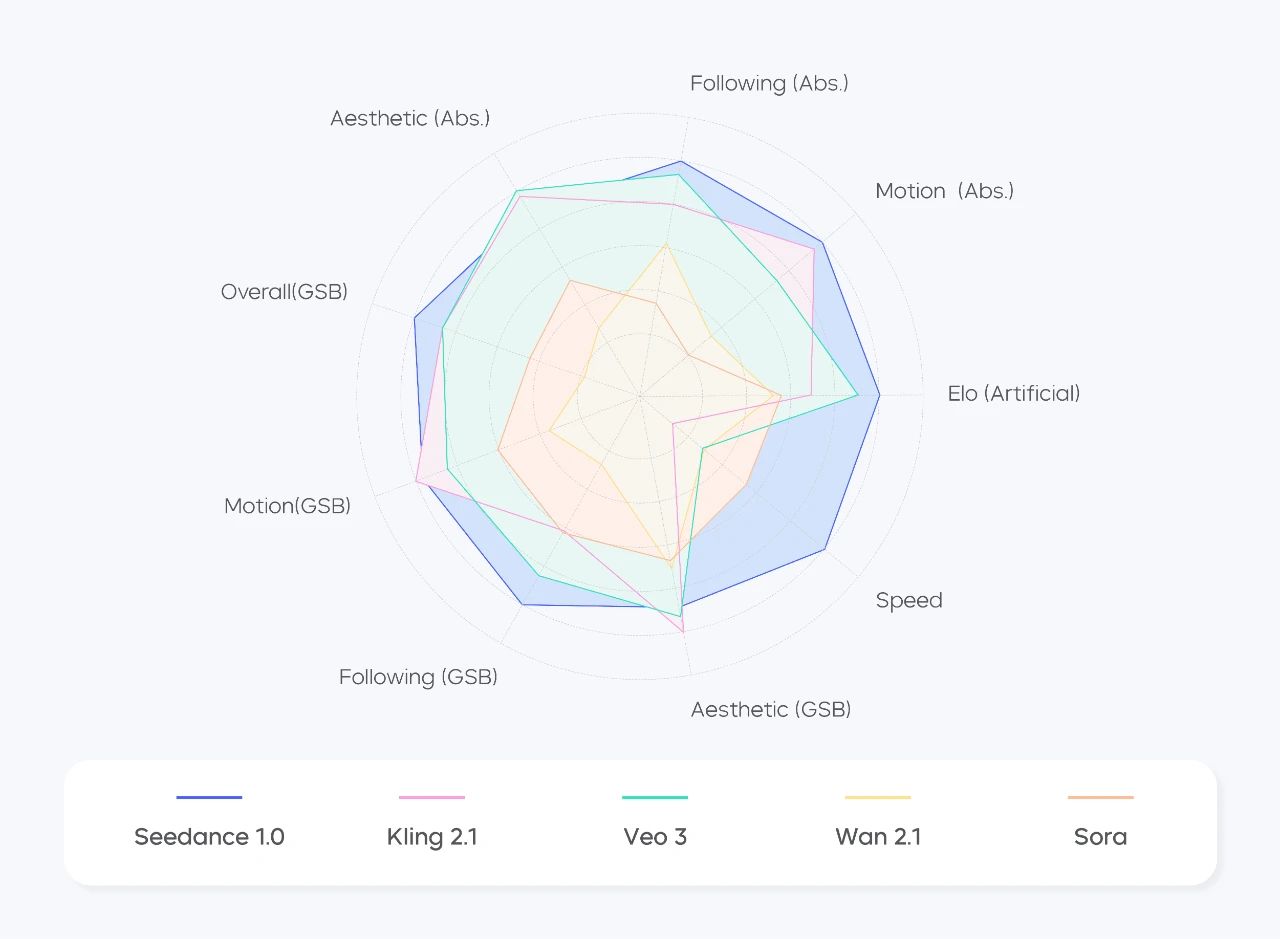
文生视频任务综合评测
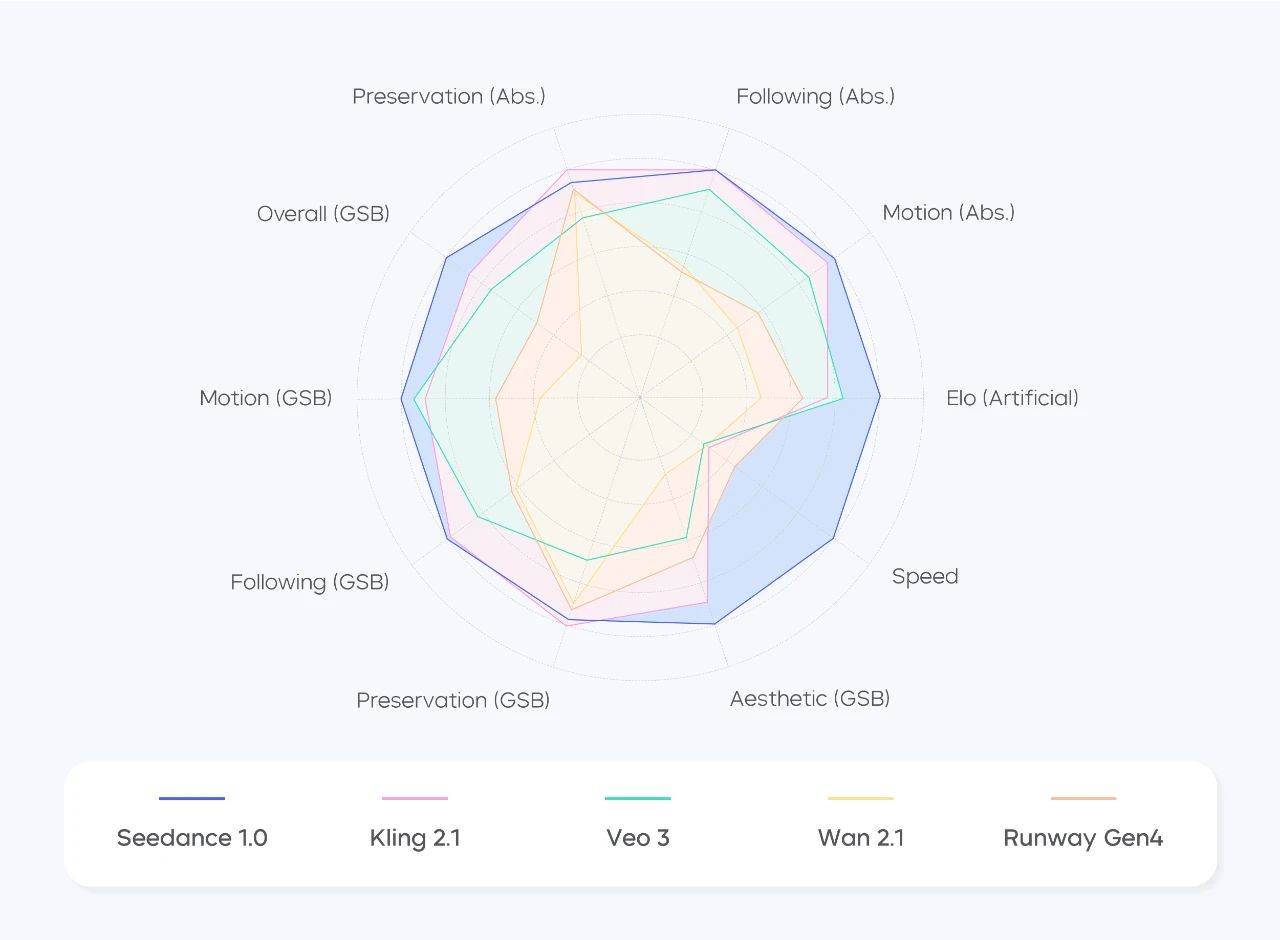
图生视频任务综合评测
Seedance 1.0 已公开技术报告,并通过即梦、豆包及火山引擎 API 接口开放使用,欢迎体验交流。
项目主页(可查看完整技术报告):https://seed.bytedance.com/seedance
引入精准描述模型,提升数据多样性与可用性
Seedance 1.0 研发过程中,团队通过调研影视创作者等群体的真实需求,不仅将指令遵循、运动稳定性、画面质量等行业共识性指标纳入攻坚方向,同时,我们也将挑战多任务生成统一、极速高清视频生成等课题纳入研发目标。
在数据构建上,团队主要聚焦于视频多源采集与描述说明(Caption)获取,通过多阶段的筛选和均衡,我们提升了模型对动态视频中的主体、动作、场景、风格以及 Prompt 的理解力,令模型在生成上更加细致和精准。
Seedance 1.0 的数据处理流程
- 多样数据源&精准预处理,提升训练数据的可用性和多样性
我们构建了多种类型、风格、来源的大规模视频数据集,采集视频的时长、分辨率、主题、场景、艺术风格、镜头运动等关键维度,使模型能够充分提取不同场景、风格、主题、镜头画面、尺寸下的主体轮廓与动作特征。
为了提高数据的利用率,Seedance 1.0 还引入自动镜头边界检测技术,通过帧间差异分析,精准分割视频片段。
此外,我们还基于启发式规则与物体检测自适应裁剪帧,最大化保留主体内容,并进行精准数据筛选,同步提升数据量级与多样性。
- 引入“精准描述模型”,提升模型对动态静态信息的理解力
精准细致的视频描述数据,可以确保模型准确响应用户指令并生成复杂内容,但在实际训练中,此类数据较为缺失。为此,我们在研发中,专门训练了“精准描述模型”来生成视频描述(Caption),作为 Seedance 1.0 的训练数据。
该模型采用动静态特征融合的密集描述架构,既关注视频中主要的动作变化与镜头运动,同时也强调画面主要元素的性质特点与场景信息。其中,动态侧用于精细刻画视频的动作变化与镜头运动,静态侧则负责深度解析特定一帧的核心主体与场景信息。
统一高效的预训练框架,实现多镜头切换与多模态输入
通过高效的模型结构设计、多模态交织的位置编码和多任务统一建模,Seedance 1.0 实现了无缝支持多镜头视频创作,并且作为单个模型,可同时支持文生视频(T2V)和图生视频(I2V)等任务。
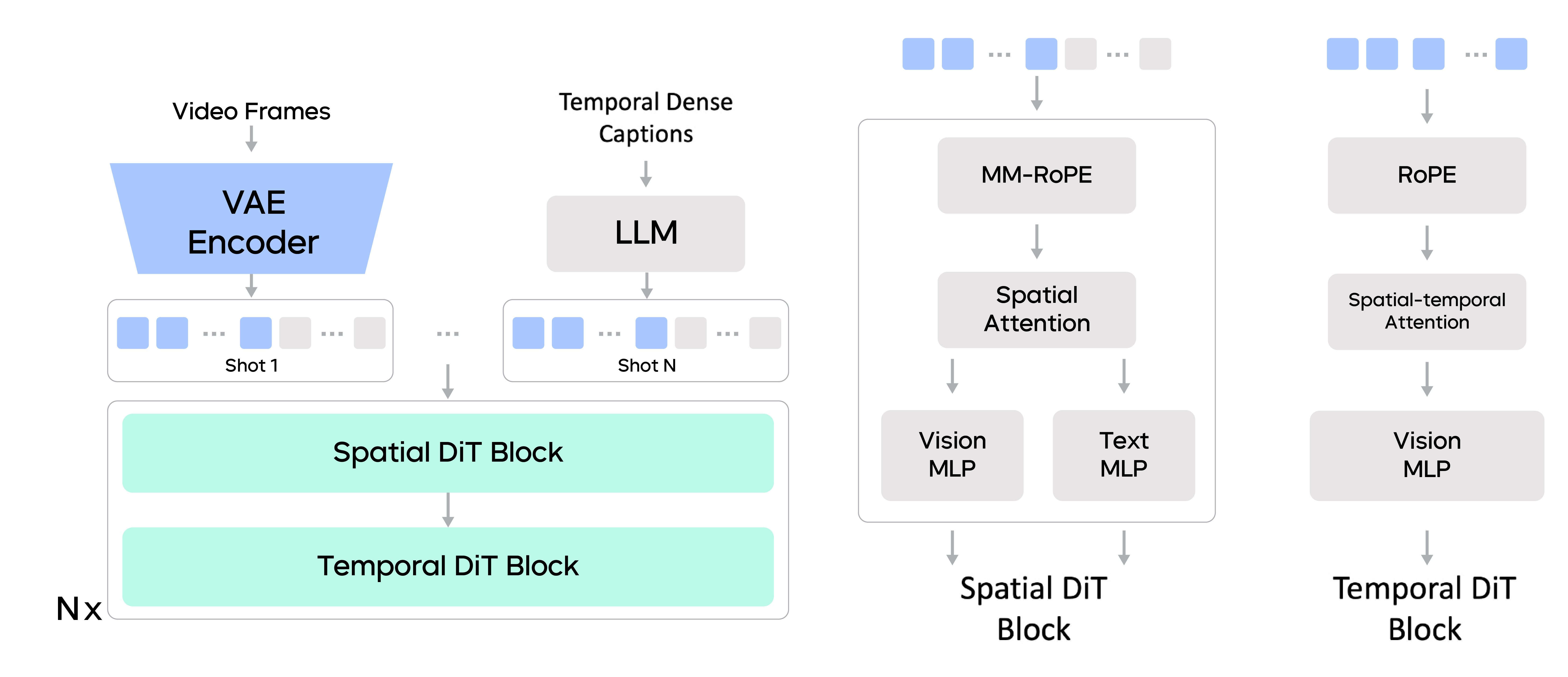
Seedance 1.0 预训练框架
相比业界已披露的方法,Seedance 1.0 在模型架构和训练策略上的优化包括:
- 解耦的空间与时间层
团队构建了解耦空间层和时间层的扩散 Transformer 模型,以提升训练和推理的效率。
其中,空间层在单帧内部执行注意力聚合,而时间层则专注于跨帧的注意力计算。在时间层中,团队在每帧内进行窗口划分,从而在时间维度上,实现了全局感受野。此外,文本 token 仅参与空间层中的跨模态交互。这些改进整体上提升了计算效率,为高效的模型研发打下基础。
- 多镜头多模态旋转位置编码
在 Seedance 1.0 中,除了按业内常规的策略对视觉 token 使用 3D 旋转位置编码,团队还为文本 token 添加了额外的一维位置编码,并在拼接后的序列中,引入了 3D 多模态旋转位置编码(MM-RoPE)。
MM-RoPE 方法支持视觉 token 与文本 token 的交错序列,且可以扩展到多镜头视频的训练。过程中,用于训练的镜头数据按照动作的时间顺序组织,每个镜头都配有精准描述模型提供的详细描述(Caption),通过这一训练方法, Seedance 1.0 多镜头生成能力和多模态理解力得以加强。
- 统一的任务框架
为了实现图像到视频的生成能力,团队使用二元掩码来指示哪些帧应遵循生成中的控制条件。在训练过程中,团队将这些任务混合训练,并通过控制条件输入来调整它们的影响比例。
通过这一框架,我们实现了统一框架下,不同生成任务(如文本到图像、文本生视频和图像生视频)之间相互学习,同时,部署侧只需一个模型就可实现多种任务,降低了模型应用门槛。
后训练构建复合奖励系统,提升画面生动性、稳定性和美感
通过在后训练阶段使用高质量的精调数据集、多维度的奖励模型和反馈学习算法,Seedance 1.0 在运动生动性、结构稳定性、画面质量等维度上取得提升。
此外,团队还采用了为视频生成定制的 RLHF 算法,从而大幅提升 Seedance 1.0 在文生视频、图片生成视频两个任务中的综合效果。
- 依靠高质量数据监督微调
在 SFT 阶段,团队精细地筛选了高质量视频-文本对数据集,让 Seedance 1.0 在该集合上进行有效训练。这些数据广泛覆盖各类风格和场景,并配有高质量且精准的视频描述(Caption),从而使模型能生成美学效果更佳、运动动态更一致的视频。
在微调过程中,团队基于精选数据子集上训练出多个独立模型,再将这些模型融合,以整合它们的优势。
- 三个维度奖励模型构成的复合奖励系统
考虑到图文对齐、结构稳定性、运动生成能力、美感是评判视频生成模型的核心,团队构建了一整套复合奖励系统,包括:
基础奖励模型:聚焦基础能力(如图文对齐与结构稳定性)增强,采用视觉语言模型(VLM)架构;
运动奖励模型:致力于抑制视频伪影,提升运动幅度、生动性与稳定性;
美学奖励模型:针对视频关键帧设计 image-space 输入的美感奖励模型,给予模型影视级美感。
- 视频定制化的反馈学习
在RLHF训练中,团队采用了最大化多个奖励模型(RM)奖励值的方法,对比 DPO/PPO/GRPO,该方法针对文本-视频对齐度、运动质量及美学表现等维度的提升效率与效果更佳。
我们还将 RLHF 扩展至加速后的超分模型,在低推理步数(NFE)场景下,提升了视频的运动质量与视觉保真度,同时保持了高效的计算效率。
从下图可以看到,伴随迭代次数增加,视频定制化 RLHF 优化方案结合多维度奖励模型,可实现模型多维能力的协同进化。
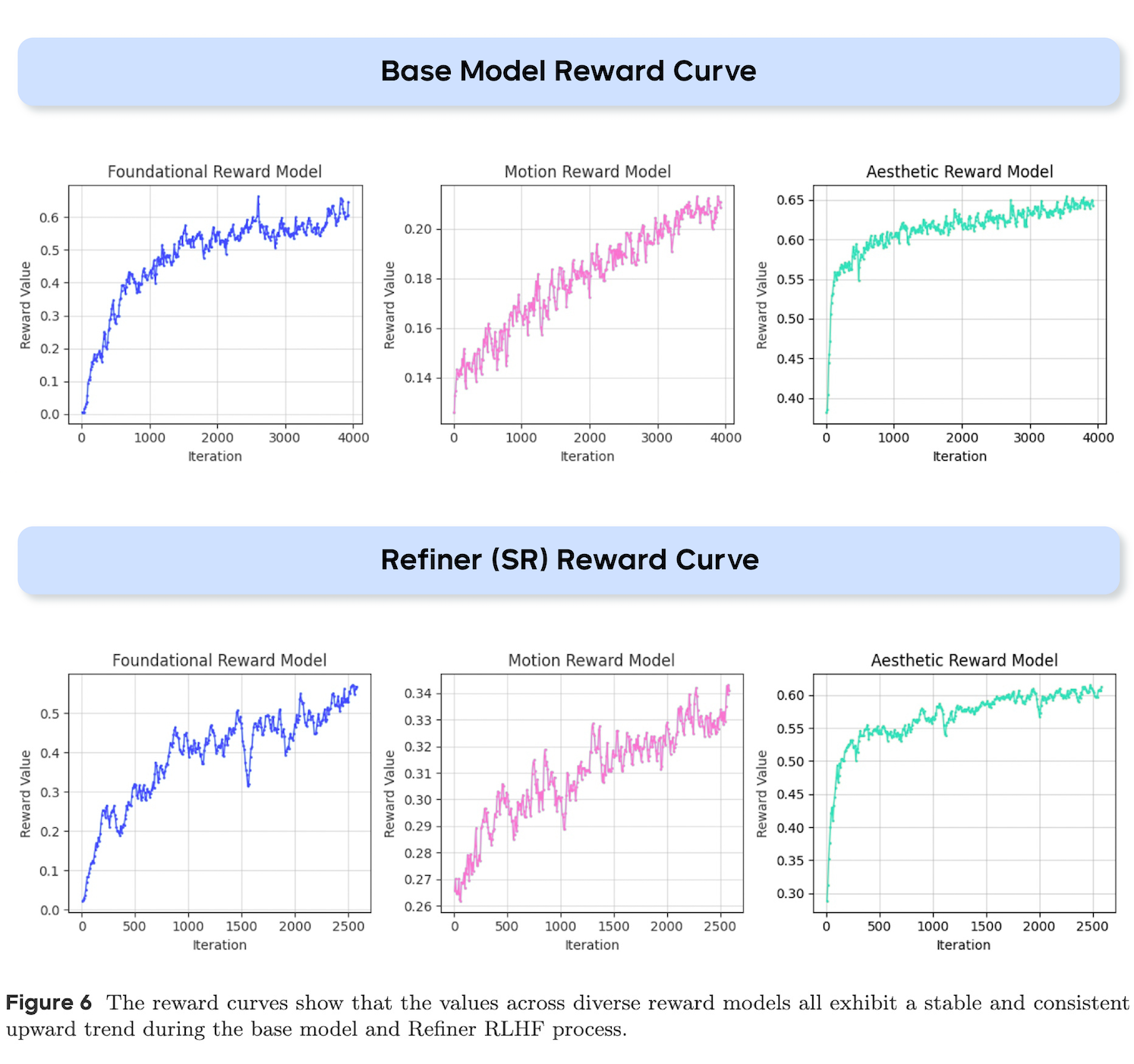
在基础模型和 Refiner RLHF 过程中,不同奖励模型曲线均呈现稳定、一致的上升趋势。
极致推理加速,最快约 40 秒生成 5 秒 1080p 视频
Seedance 1.0 采用模型算法与底层推理的协同优化技术,实现对模型的基本无损加速。在保证图文匹配、画面质量、运动质量等指标几乎不受影响的情况下,模型可以高效生成视频。对于 5 秒 1080p 分辨率的视频生成,团队使用 L20 实测推理耗时为 41.4 秒。Seedance 1.0 主要推理加速方法包括:
- 扩散模型算法加速
通过引入分段轨迹一致性、分数匹配与人类偏好引导的对抗蒸馏机制,在极低推理步数(NFE)下,我们实现了生成质量与速度的更优协同。针对像素域解码瓶颈,团队使用通道结构细化的轻量级 VAE 解码器,实现视频生成路径中感知质量无损的双倍加速。
- 底层推理加速
我们通过融合算子优化、异构量化稀疏策略、自适应混合并行、异步卸载与 VAE 并行分解等系统级改造,在不牺牲画质与可部署性的前提下,构建了面向长序列视频生成的高效推理路径,实现端到端吞吐与内存效率的更优协同。
未来规划
自 2024 年开始,视频生成类模型不断进化。团队认为,视频生成的生动性和自然度还将大幅提升,随着应用门槛降低,视频生成模型将真正成为内容创作的高效工具。
在此基础上,视频生成模型可作为世界模拟器,与人类进行实时互动,甚至能生成高质量游戏作品,也并不遥远。
未来,Seedance 团队计划在以下方向开展进一步研究:
- 探索更高效的结构设计与加速方法:构建效果更好、成本更低、生成更快的视频生成模型,并在此基础上构建可实时交互,且精准可控的视频生成模型;
- 提升模型智能化水平:拓展模型对世界知识的理解,增强生成真实感和物理规律合理性,探索多模态信息融合,如赋予模型音频输入输出能力;
- 探索数据、模型量级、奖励模型等维度的 Scaling 现象,推进视频生成模型的能力进一步涌现。